
개발하면서 아래와 같은 직원 테이블이 있었다
| 직원 |
|---|
| 국적 |
| 이름 |
| 성별 |
| 생년월일 |
| 소속 |
| 직책 |
하지만 나중에 직원이 아닌 외부인도 넣어야 하는 경우가 생겼다.
1. 하나의 테이블로 통합
처음에는 외부인은 소속,직책이 없기에 col에 직원인지 외부인이 판별하는 데이터를 추가하였고 테이블명을 사람으로 바꾸었다.
| 사람 |
|---|
| 국적 |
| 이름 |
| 성별 |
| 생년월일 |
| 소속 |
| 직책 |
| 직원여부 |
하지만, 이러한경우에는 외부인인경우 소속,직책에 데이터값이 결측치가 되버린다.
2. 여러 개의 테이블로 분리
테이블을 아예 새로만들어서 분리하는 경우도 있다.
| 외부인 |
|---|
| 국적 |
| 이름 |
| 성별 |
| 생년월일 |
이러면 결측치는 생기지 않지만, 직원테이블과 같은 연관관계를 갖는 테이블이 있어 ERD가 상당히 복잡해지는 문제가 생겼다.
3. 각각의 테이블로 분리
| 사람 |
|---|
| 국적 |
| 이름 |
| 성별 |
| 생년월일 |
| 직원 |
|---|
| 사람 테이블 KEY |
| 소속 |
| 직책 |
국적,이름,성별,생년월일 같은 공통 관심사만 따로 테이블로 나누고 직원 고유의 속성은 따로 직원테이블로 빼서 1대1 관계를 만든다. 이러면 결측치도 안생기고 ERD도 직원과 외부인이 공통으로 관계가 있는 부분은 사람 테이블과 연관관계를 형성하면 되기에 복잡해 지지 않는다.
슈퍼-서브 타입
위와 같이 공통적인 부분과 그외 부분들을 나누는 방법을 슈퍼/서브타입 데이터 모델링이라 하고 Extended ER모델이라고도 한다. 공통 관심사가 슈퍼타입 공통으로부터 상속받아 다른 엔터티와 차이가 있는 속성은 서브타입 이다.
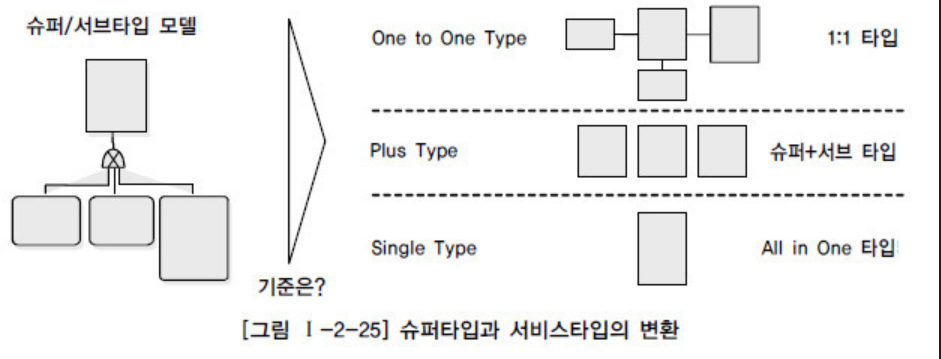
물리적인 구현방법은 크게 3가지가 있다.
위의 1번 구현방법이 All in One
2번이 Plus Type
3번이 One to One Type 이다.
각각의 구현 방법에 대해 특징이 있다.
All in one(Roll up)
서브타입의 속성이 별로 없고,서브타입과 관계를 맺은 테이블이 적을때 좋다.
장점:쿼리문이 단순하고,속도적인 측면에서 유리한 경우가 많다.
단점:결측치가 많아진다.
Plus Type(Rolldown)
슈퍼타입의 속성이 별로 없고,슈퍼타입과 관계를 맺은 테이블이 적을때 좋다.
장점:각 서브타입 별로 쿼리문을 짤 경우,조인을 할 필요가 없다.
단점: 관리가 어렵다.
One to One Type
슈퍼타입과 서브타입의 속성이 각각 적절히 있고 관계도 두 타입다 맺은 경우 좋다.
-> 일반적으로 좋다.
장점:유연한 테이블 관리가 가능하다.
단점:위의 경우같이 슈퍼타입과 서브타입이 극단적일때는 위의 구현 방법보다 성능적으로 떨어질 수 있다.
