tf.data : ML에 필요한 데이터 및 HW도 보장해줌
pipeline : ML 전 과정을 흐름에 따라 만드는 것, data가 중요함에 따라 data 자체의 흐름을 나타낸 것을 data pipelines.
왜 data pieline이 중요할까? 갈수록 data가 중요해지기 때문에. model이 크면 클수록 성능이 좋아지기 때문에, 그 성능을 좋게 하기 위해선 data를 많이 확보해야 함. data가 ML 입장에서는 항상 부족함. ML model에 입력하기 전까지의 data의 처리 과정을 data pipeline이라고 하고, NN 기반인 deep learning에 한정되어 있음.
data가 많아도 순서에 따라 model의 성능이 결정되기도 함. 따라서 data를 섞어야 함. data를 섞는 것 자체도 resource가 큰 작업임.
- 원본 자체를 Augmentaiton 방식 - 원본을 새로 저장 (이미지 파일 처리)
- 원본을 array로 바꾸고, array를 augmentation 하는 방식
요즘 들어와서 가짜 data를 생성, 내가 가지고 있는 데이터로 실제 있을 법한 data를 생성하는 방식을 많이 씀
실제 그럴듯한 data를 만들었기 때문에, general 성능을 확보할 수 있음. 이런 기법을 file 형태로 저장시켜서 원본 자체를 augmentation 을 하는 방식임.
Data Pipeline
1. Directory
2. DB : Indexing을 통한 검색 속도 효율성이 없음. 예전에는 LMDB를 사용해서 image data를 DB화를 시켰지만 요즘에는 잘 안 쓰는 추세 - 더 이상 tensorflow에서는 기능을 제공하지 않음
3. HDF : 잘 안 쓰고 있음
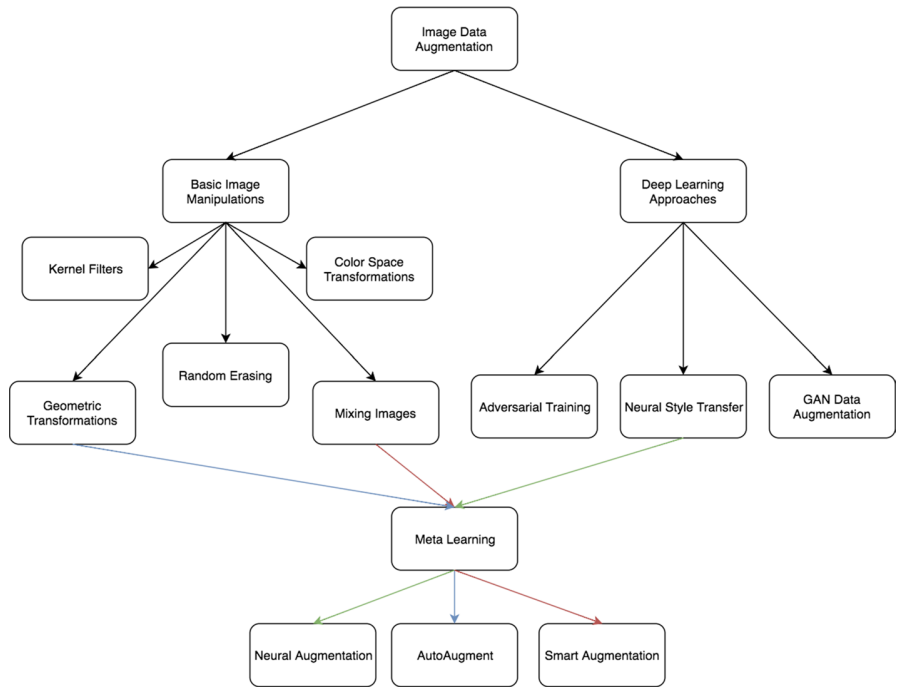
기본 image로 만든 agumentation은 발전이 끝난 technique. 현재는 deep learning을 통해서 만들고 있음
-
augmentor : 원본 자체로 저장을 다 할 수 있고, augmentator로 생성된 image도 저장 가능. 쉽게 상속하여 처리할 수 있으나 PIL 기반이라 대규모 파일처리에는 부적합함
-
tf.keras.preprocessing.image.
