6. Digression : The perceptron learning algorithm
이전 강의에서 결론을 Logistic Regression의 hypotheses 다음과 같습니다
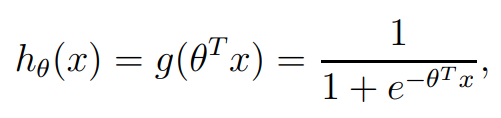 여기서, logistic function 또는 sigmoid function이라고 부르는 g(z)는 다음과 같이 정의할 수 있습니다
여기서, logistic function 또는 sigmoid function이라고 부르는 g(z)는 다음과 같이 정의할 수 있습니다
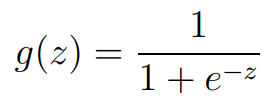 Perceptron의 g(z)는 다음과 같은 임계 함수(threshold function)으로 정의할 수 있는데, 이는 sigmoid function의 hard version이라고 생각할 수 있습니다.
Perceptron의 g(z)는 다음과 같은 임계 함수(threshold function)으로 정의할 수 있는데, 이는 sigmoid function의 hard version이라고 생각할 수 있습니다.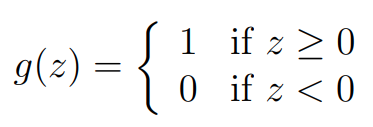
이는 역시 가설 함수로 이어지는데, 이를 update rule을 사용하게 되면, perceptron learning algorithm이 됩니다. 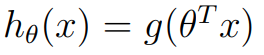
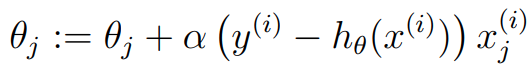
노란색 데이터와 주황색 데이터가 있을 때, 초록색 점선은 이고, 0보다 큰 곳을 class 1, 작은 부분을 class 0이라고 할 수 있습니다. 하지만, new data(노란색)이 들어오기 때 이 그래프는 misclassification이 되므로, 우리는 update를 해야 합니다. 저희는 아주 작은 learning rate 를 활용해 기존 초록색에서 파란색으로 update를 하게 됨으로써 잘 분류를 할 수 있게 됩니다.
Part III Generalized Linear Models
그동안 저희는 binary claassification(Bernoulli distribution)만을 배웠습니다. 즉, 동전이 앞면인지, 뒷면인지만 예측을 했습니다. 하지만 이를 multi classfication으로 확장을 해야 하고, 이를 위한 것이 GLM(Generalized Linear Models)입니다.
GLM의 구성 요소는 다음과 같습니다
1. 확률요소 : 확률요소는 종속변수의 확률 분포를 규정하는 성분으로, GLM에서는 종속변수의 확률 분포로 Exponential family로 확장을 해야 합니다
2. Linear predictor : 종속변수의 기대값을 정의하는 독립 변수들 간의 집합입니다
3. Link function : Linear prepdictor와 종속변수의 기대값을 연결해 주는 함수입니다
위 세 개가 GLM의 구성요소이며, 우리는 이를 위해 Exponential family를 배우게 될 예정입니다.
8. The exponential Family

저희는 Expoential family를 위와 같이 쓸 수 있습니다. 특히 는 vector가 될 수 있지만 여기선 scalar로 한정할 예정입니다. 우리가 도출한 Bernoulli와 Gaussian 외에 더 많은 exponential family가 있습니다. 하지만 이 강의에서는 Bernoulli와 Gaussian만 다루고 있습니다.
Bernoulli는 아래와 같이 expoential family의 형태로 만들 수 있습니다.
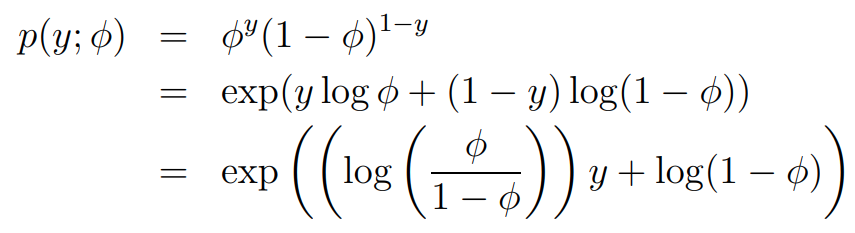
여기서 가 됩니다. 여기서 로 쓸 수 있으며, 이는 sigmoid function의 형태입니다. 즉, 우리는 logistic regression을 GLM으로 다시 한 번 도출해낼 수 있습니다. 각각의 parameter들은 다음과 같습니다
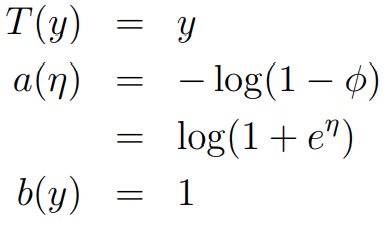
Gaussian distribution은 아래와 같습니다. 우리는 고정된 를 사용하여 추론을 할 예정입니다. 간단하게 계산하기 위해 로 고정합니다.
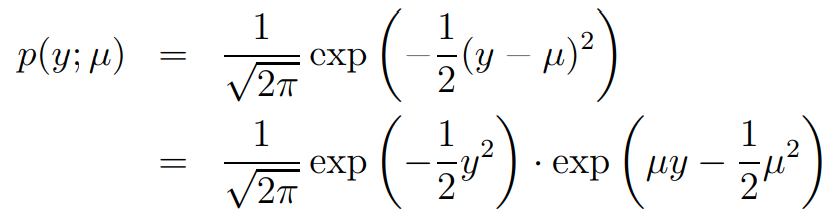
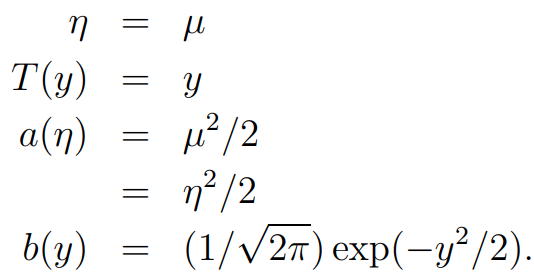
9. Constructing GLMs
왜 우리는 Exponential family를 사용하는 것일까요? 다음과 같은 properies가 있습니다
1. 에 관해서 Maximum Likelihood가 concave일때 cost function인 Negative Log-Likelihood는 convex가 됩니다
2.
3.
보통 기대값 E와 Var는 적분으로 구하지만 여기서는 미분을 통해서 구하기 때문에, 좀 더 쉽다는 장점이 있습니다. 따라서 저희는 Exponential family를 사용할 수 밖에 없습니다.
GLM 문제를 풀기 위해, 저희는 세 가지 추정을 합니다
1. ~ ExpoentialFamily()
2. , ,
3. x가 주어졌을 때, 우리는 기대값 T(y)를 구하는 것이 목표입니다. 를 만족할 때 h(x) output은 예측할 수 있습니다.
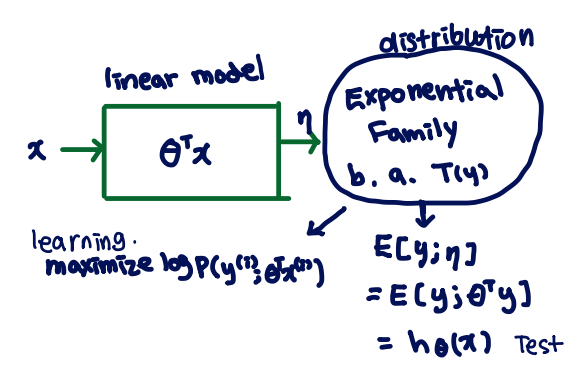
우리에게 중요한 것은 training 동안 무엇을 learning/ not learning하는지 아는 것이 중요합니다. 는 output function입니다. learning 동안 가 최대값이 되어야 합니다.
우리는 3 parameterization을 할 수 있습니다

9.2. Logistic Regression
입니다. 여기서 이므로 로 다시 쓸 수 있습니다. 이 때, 는 canonical parameter space에서 Bernoulli의 기대값입니다.
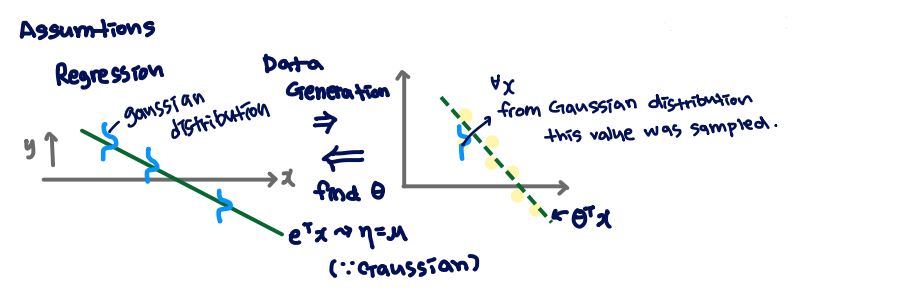
Regression에서 는 로 assumption됩니다. Gaussian distributiond이기 때문에 입니다. 에 대해 각각 Gaussian distribution을 이루고 있습니다. 이를 Data generation을 하게 되면 모든 x에 대해 Gaussian distribution으로 부터 sampling 됩니다. 이를 통해 반대로 를 찾는 것이 목표가 됩니다
9.3. Softmax Regression
note에서는 softmax를 GLM family로 소개를 하지만, 강의에서는 non-GLM approach를 취하고 있습니다. softmax regression의 목표는 cross entropy를 최소화하는 것에 있습니다
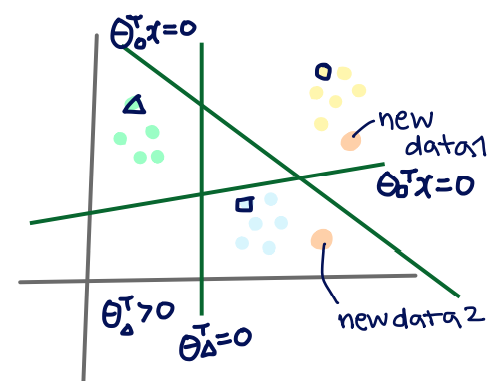
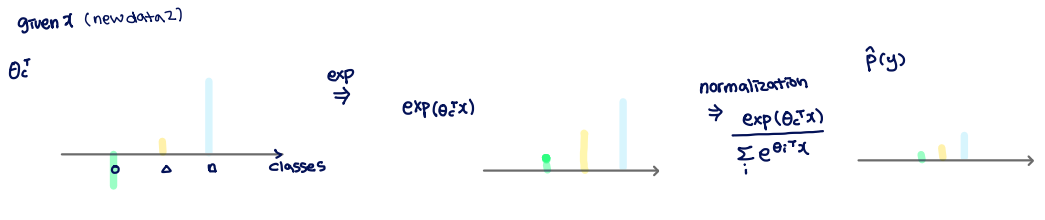
multi classification의 목표는 결국 새로운 데이터를 어떤 그룹에 들어가게 할지 결정하는 것입니다. 우리는 새로운 데이터 (new data2)가 주어졌을 때, 각각 어떤 그룹에 들어갈지 다음과 같이 나타낼 수 있습니다