
※ 회고문 이므로 경어가 아닌점 양해바랍니다.
시작
23년 7월 부트캠프에서 첫 팀프로젝트를 시작했다. 프로젝트 이름은 AI 소프트웨어 업그레이드 프로젝트로, 넘파이로 작성되어있는 mlp모델을 최신 프레임워크 기반의 다른 모델로 바꾸고, .ipynb로 되어있던 SW를 .py기반으로 리팩터링하는 프로젝트 였다.
처음 팀원들을 만나보니 부트캠프에 참 다양한 사람들이 많다는걸 새삼 깨달았던 기억이 있다. 석사출신도 있고, 놀랍게도 전 대기업 인사팀 부장님도 계셨다..😲 간단한 회의끝에 팀장을 맡게 되었고, 이후 일정과 의견취합, 코딩, git관리등을 수행하며 어찌저찌 프로젝트를 나름 괜찮게 끝냈던것 같다. 팀원들의 피어리뷰도 긍정적으로 받았던 기억이 있다. 다만 끝난뒤에 돌아보니 팀장으로서 엔지니어로서 미숙했던점이 너무 많았던것 같아 아쉽다. 아무래도 첫 팀프로젝트이기에 미숙한것은 당연하다면 당연하지만..
어쨋든 경험이 성장으로 이어지려면 회고는 필수이므로, 나중에 스스로 어떤 어려움을 겪고 어떤 미숙함이 있었는지를 볼 수 있게 적어둔다.
어떤걸 느끼고 깨달았나
레포 초기구성과 브랜치 전략의 필요성
그동안 간단하게 git과 github를 사용하고는 있었지만, 어디까지나 나 혼자 작업하여 올리는 용도로 사용하고만 있었다. 그래서 막상 git관리를 맡된 이후 어떤식으로 github를 관리해야하는지 참 막막했던것 같다. git-flow, github-flow등 git 브랜치 전략에대해서도 모르고있었기에, 그냥 사람별로 브랜치를 나눠서 작업했다. 초기 레포 구성과 역할분배도 안했다. 그냥 레포열고 브랜치 나누고 개인별로 ipynb를 만들어서 작업하는 식이었다. 그야말로 주먹구구식..
 사람별로 브랜치를 나눠논 모습..
사람별로 브랜치를 나눠논 모습..
이런식으로 작업하니 발생했던 문제가, 브랜치를 main으로 병합하는 기능이 무의미해졌다는 점이다. 초기에 어떤식으로 구성할지를 안정해놨으니 파일 이름도 디렉토리 구조도 난장판이었다. 브랜치별로 같은기능을 하는 파일인데 이름이 다르고, 같은 데이터가 다른 디렉토리에 있고.. 이러니 main으로 병합을 할 수가 없고, 일일히 브랜치를 받아 손으로 이름과 내용등을 수정하고 다시 push, 이후에 병합하게 되었다. 그 과정에서 어떤 파일을 살리고 버릴지 작업자와 계속 소통해야하니 작업효율도 내려갔음은 당연하다.
이런식으로 git을 사용하는건 의미가 없는 행동이었다는걸 프로젝트 도중에 깨달았다. 그때는 이미 터트리고 다시 시작하기엔 늦었고. 다른작업을 하느라 바빠서 일단은 레포를 그대로 가져가기로 결정하긴했다.
결국 초기에 레포 구조를 짜놓고 역할을 분배해서 일을 하는것이 중요하겠다. 작업자별로 같은 파일 구조를 공유해야 병합도 편하고 변경사항을 알기도 편하다. 브랜치역시 마찬가지. 물론 개인별로 나누는 방법도 있겠지만, 역시 git-flow나 github-flow처럼 기능별로 브랜치를 분기하고 병합하는 과정이 효과적일것이다.
git에서 ipynb의 형상을 관리하는법
ipynb는 코드셀 뿐만아니라 메타데이터와 출력까지 JSON형태로 저장하게 되는데, 이에따라 겉으로 보이는 코드가 같더라도 실제 형상은 다를 수 있다. git은 JSON에서 어디가 코드셀이고 어디가 부가적인 부분인지를 모르니, 죄다 버저닝하는것이다. 프로젝트 당시 이걸 모르고 작업하다가 받은 PR을 작업자 브랜치에 병합할때 피를 봤다.
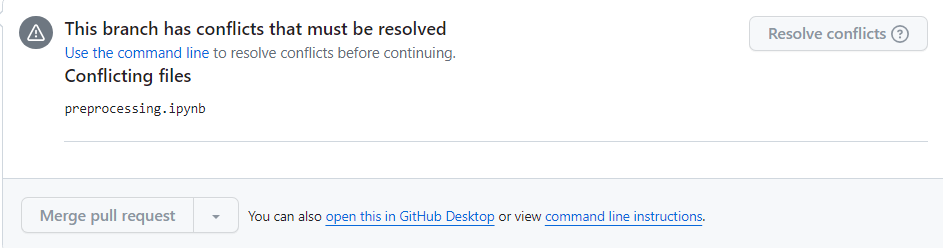 conflict가 너무 많아 resolve가 안되는 상황
conflict가 너무 많아 resolve가 안되는 상황
병합할때마다 메타데이터와 실행결과로 인해 conflict가 지속적으로 발생했다. 물론 conflict가 적을땐 깃허브에서 해결가능하지만, 그림처럼 너무 많은부분에서 문제가 있으면 아예 해결이 안된다. 로컬로 가져와서 CLI로 좀 만져봤지만 실패했다.😓
이런 문제를 해결하기위해선 ipynb의 메타데이터와 실행결과를 commit할때마다 밀어줘야 한다. 당연히 손으로할 순 없고, nbstripout를 사용하는편이 좋다. nbstripout을 설치하고 .gitattributes에 .ipynb파일의 filter를 nbstripout으로 설정하면 로컬엔 메타데이터와 실행결과를 남긴채로 git 형상엔 둘을 밀어버린 형태로 관리할 수 있다. 프로젝트가 끝나고서야 알았기때문에, 본 프로젝트엔 아쉽게도 적용하지 못하고 다음 프로젝트부터 적용하였다.
모듈화의 중요성, 코드 최적화에 대한 고민
프로젝트의 리팩터링 파트역시 내가 맡았다. .ipynb에서 코드셀을 실행하는 방식으로 작동하던 레거시를 .py로 바꾸고 CLI환경에서 실행가능하게끔 바꾸는 작업이었다. 사실 사용모델까지 바꾸고 기능도 추가하고 하다보니 리팩터링보단 아예 새로 만드는게 좋을것 같아 레거시코드를 버리고 새로 만들었다.
그동안의 내 프로그래밍은 항상 절차지향적 프로그래밍에 갇혀있었으므로, 이번에 새로 만드는김에 처음으로 OOP의 개념을 적용하여 작성했다. 물론 파이썬은 객체지향언어가 아니고, 내 코드도 OOP라 부르기에 민망한 수준이지만.. 그래도 OOP의 방식을 적용해보고자 했다.
추상화에 대해 고민해본뒤 공통적으로 필요한 메서드들을 최상위 모델 클래스에서 정의했고, 다음으로 서로다른 task를 수행하는 3개의 하위모델에 상속시키는 방식으로 구성했다. 각 하위모델은 필요에따라 상속받은 메서드를 자신에게 맞게 오버라이딩 하여 구성하였다. (초기엔 attribute를 __로 캡슐화 했지만 사실 파이썬엔 진정한 private가 없기도 하고 불편하기도 해서 뺐다.)
class Model: # 함수 세부내용 생략
def __init__(self):
@classmethod
def load_data(cls, df=None, mode='split'):
def _to_frame(self, data, target=False):
def train(self, params=None, df=None):
def predict(self, X):
def performance(self, df=None):
def save_model(self):
def make_val_data(self, n_samples:int=100, seed:int=None):
class Model1(Model):
# train만 오버라이딩
def train(self, params=None, df=None):
class Model2(Model):
...코드 예시
이런식으로 작성하니 확실히 코드길이가 줄어들고 구조를 알아보기 편해졌다. 구조만 잘 알고있으면 절차지향형보다 쉽게 눈에들어온다. 기능을 수정하는것도 쉽다.
여기까진 좋았는데, 데이터를 불러오는 함수를 잘못된 방식으로 작성해서 디버깅과의 싸움에 돌입하였다. 당시에 나는 scikit-learn이나 pandas같은 라이브러리의 고수준 API를 주로 활용했기때문에 한번에 여러 모드와 기능을 수행할 수 있는 방식의 함수와 메서드 형태에 익숙했다. 그래서 저수준의 함수와 메서드를 모듈화를 하지 않고 고수준 API를 흉내내는 우를 범한것이다.
def load_data1(df1=None, mode='split'):
"""
data1을 불러와서 전처리된 데이터셋을 반환
df를 입력하면 해당데이터셋 처리
전처리:
1. 'Sex'컬럼 원핫인코딩
2. 수치형 표준화
args:
df1 : 전처리할 데이터프레임
mode : 'raw'= Xy만분리, 'prepro'=Xy분리후 전처리,
'split'=전처리이후 train test분리
returns:
raw : X, y, df1
prepro : X, y
split => X_train, X_test, y_train, y_test, data1_ct
"""
...docstring만 봐도 알 수 있겠지만 기본적인 기능을 하는 저수준의 함수인데 mode를 추가해서 여러 기능을 수행하도록 작성했고, load기능을 수행하는 함수인데 전처리와 표준화기능을 별도분리하지 않고 같이 넣어놨다. (지금보니 split기능까지 여기서 하도록 해놨다.)
상황이 이러니 모듈화가 안되서 코드가 더러워지고 곳곳에서 버그가 터졌다. 다양한 형태의 입력데이터에 대응할 수 있도록 작성해놨는데, load_data에서 mode를 바꾸는것으론 한계가 있으니 자꾸만 버그가 터진다. 그때그때 땜방식으로 버그를 고치기위해 코드를 추가하니 load_data를 사용하는 Model클래스의 메서드들도 알아보기 힘들게 코드가 지저분해졌다. 결국 fancy한 API 욕심을 부리다가 지저분하고 버그많은 코드를 작성하게됬다.
실제 프로그램을 제어하는 main도 문제였다.
def main():
while True:
if ...:
elif ...:
if ...:
while ...:
if ...:
while ...:
else ...:코드 예시
이런식으로 if else 지옥이었다. 당시 시간압박이 있어서 메인 프로그램 구조를 생각할 시간이 없다보니 그냥 초보의 습관이 그대로 나왔다. 이것보다 훨씬 깔끔한 방식으로 작성가능함을 물론 알고있었지만, 알고만 있고 실제로 구체적으로 어떤식으로 해야할진 잘 몰라서 그냥 기능구현에만 집중했다. 결과적으로 작동은 하는코드인데, 다른사람이 봤을때 이해하고 수정하기 어려운 형태이다.
다시 같은 프로그램을 작성하게 된다면 불러오기, 전처리, 데이터 무결성 보증등을 전부 모듈화해서 작성하게 될 것 같다. 원하는 기능에 맞춰 함수를 작게 쪼개면 재사용성도 높고 디버깅도 쉬워질것이다. 코드도 선언형에 더 가까워질테니 보기도 쉽다.
이런 문제들을 고민하다가 디자인 패턴까지 생각이 닿고 고민하게 된것 같다. 같은기능도 어떤식으로 작성하느냐에 따라 가독성과 디버깅, 나아가 유지보수 난이도가 크게 차이나는것 같다. 다만 프로젝트 도중에 이런것까지 고민하고 공부해서 적용할 시간은 절대없고, 당시엔 막연히 시간날때 알아보자는 정도의 생각만 있었다. 물론 다른거 먼저 공부하느라 아직까지 못알아봤다. (취직을 위해선 코테와 CS지식, DS지식부터 쌓는게 먼저다..)
긍정적 피드백의 중요성
기술적인 부분 외에도 느낀게 있다면 바로 긍정적 피드백의 중요성이다. 내가 꾸준히 여러 팀프로젝트에 참여하고 소통하면서 느낀바, 나를 포함에 대부분의 사람들은 생각보다 감정과 이성을 분리하지 못한다. 생각보다 훨씬 더. 같은말이라도 뉘앙스가 나쁘면 맞다는걸 알아도 받아들이지 못한다. 누군가 대립의견을 제시하면 조심해서 말하더라도 언짢은기분이 든다. 마찬가지로, 긍정적인 기분이 들지않으면 목표에 대한 동기가 희미해진다.
현실파악? 좋다. 팩트체크? 좋다. 메타인지가 확실해야 어디로 가야할지를 알 수 있으니. 그런데 대부분의 사람들에게 현실파악이란 행위는 부정적이고 실망스러운 기분을 유발하기 마련이다.

합리적으로 사고한다면 자신의 기분과, 목표에 대한 의지를 분리해야겠지만.. 그게 어디 보통 쉬운일이겠는가. 그저 메타인지만 한채로, 알고만 있는채로 멈춰서게 된다. 실제로 의사결정을 위한 회의를 할때도, 개인에게 피드백을 할때도 비판과 현실파악의 행위에서 끝났던 경우엔 이후의 단기결과가 좋지 않았던 경우가 많았던것 같다. 비판적 사고를 통해 뭐가 문제인지 알 순 있어도, 이후 개선하려는 행동력을 갖게된 경우는 잘 없었다. 나도 다른사람도.
그래서 긍정적 피드백으로 소통을 마무리하는것이 중요한것 같다. 원래도 알고있었지만, 이번 팀 프로젝트를 하면서 더욱 크게 와닿는다. 프로젝트를 마무리하면서 서로간의 피드백을 남기는 시간이 있었는데, 이때 동료들 특히 팀원으로 같이 프로젝트를 진행하셨던 전 대기업 부장님의 긍정적 피드백과 인정에 성취감과 앞으로의 발전에 대한 동력을 얻었던것 같다. 사실 대기업 부장까지 하다 오신분 눈높이에서 취준생이 일을 잘해봐야 얼마나 잘했겠나. 다만 알고있음에도 기분이 좋고 더 성장하고자 하는 열정이 생겨난다. 나도 이런걸 해줄 수 있는 사람이 되야 동료와 같이 성장하는 개발자가 될 수 있다.
내 스스로 회고해보니 회의나 의견표출에 있어서 긍정적인 피드백을 마무리한 경우가 많지는 않았던것 같다. 물론 누군갈 탓하거나 지적하거나 이런행위를 한건 아니고 항상 타인에게 좋은평가를 남기는 편이긴한데, 내용적으로는 한계에 대해 언급하거나 대립의견을 제시하는등 회의적인 뉘앙스의 의견표출로 끝냈던 경우가 많다. 앞으로는, 가능하면 무조건 긍정적인 방향으로 마무리하도록 노력하고자 한다. (물론 대책없이 긍정적일 필요까진 없고..😅 넛지를 잘 가하는 방식으로)
마무리
사실 프로젝트 하면서 자잘하게 느낀것들은 좀 더 있지만, 스스로 생각하기에 중요한 내용들은 이게 전부인것 같다. 한번의 경험으로 알게된 모든걸 다음에 전부 가져가긴 힘들다고 본다. 기술적인건 반복숙달하면 되니 잊어먹어도 문제없고, 다만 긍정적인 피드백의 중요성 하나만큼은 내가 나중에 주니어가 되고 시니어가 되더라도 잊어먹지 않았으면 한다.
