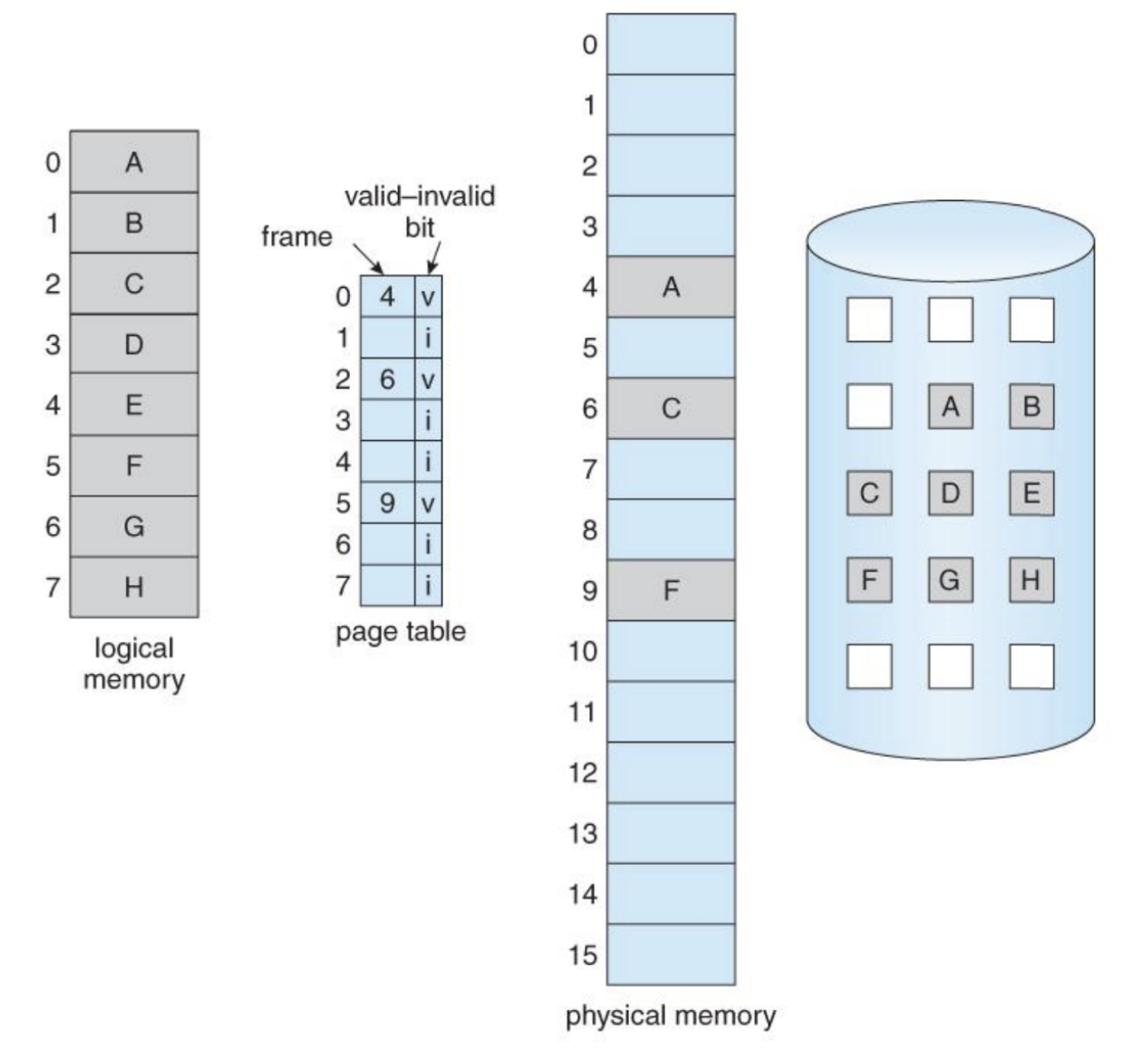
가상 메모리(Virtual Memory System) 2
오늘도 어제에 이어서 책으로 개념정리를 했습니다
세그멘테이션
지금까지 프로세스 주소 공간 전체를 메모리에 탑재하는 것을 가정해 왔습니다. 베이스와 바운드 레지스터를 사용하면 운영체제는 프로세스를 물리 메모리의 다른 부분으로 쉽게 재배치할 수 있습니다. 이러한 형태의 주소 공간에 대해 재미있는 사실을 발견할 수 있는데 스택과 힙 사이에 사용되지 않는 큰 공간이 존재한다는 것입니다.
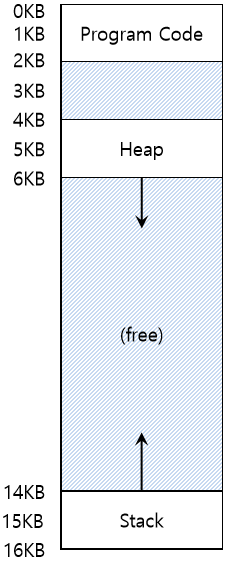
스택과 힙 사이의 공간은 사용되지 않더라도 주소 공간을 물리 메모리에 재배치할 때 물리 메모리를 차지합니다. 베이스와 바운드 레지스터 방식은 메모리 낭비가 심합니다. 또한, 주소 공간이 물리 메모리보다 큰 경우 실행이 매우 어렵습니다. 이런 측면에서 볼 때 베이스와 바운드 방식은 유연성이 없습니다
세그멘테이션 : 베이스/바운드(base/bound)의 일반화
이 문제를 해결하기 위한 아이디어가 세그멘테이션입니다. MMU에 하나의 베이스와 바운드값이 존재하는 것이 아니라 세그멘트(segment)마다 베이스와 바운드 값이 존재합니다. 세그멘트는 특정 길이를 가지는 연속적인 주소 공간입니다. 우리가 기준으로 삼은 주소 공간에는 코드, 스택, 및 힙의 세 종류의 세그멘트가 있습니다. 세그멘테이션을 사용하면 운영체제는 각 세그멘트를 물리 메모리의 각기 다른 위치에 배치할 수 있고, 사용되지 않는 가상 주소 공간이 물리 메모리를 차지하는 것을 방지할 수 있습니다.
위의 주소 공간을 물리 메모리에 배치하려고 한다면 각 세그멘트의 베이스와 바운드 쌍을 이용하여 세그멘트들을 독립적으로 물리 메모리에 배치할 수 있습니다
64KB의 물리 메모리에 3개의 세그멘트와 운영체제용으로 예약된 16KB 영역이 존재합니다.
그림에서 볼 수 있듯이, 사용 중인 메모리에만 물리 공간이 할당됩니다. 사용되지 않은 영역이 많은 대형 주소 공간을(드문드문 사용되는 주소 공간(sparse address space)이라고 부름) 수용할 수 있습니다
세그멘트 종류의 파악
하드웨어는 변환을 위해 세그멘트 레지스터를 사용합니다. 하드웨어는 가상 주소가 어느 세그멘트를 참조하는지 그리고 그 세그멘트 안에서 오프셋은 얼마인지를 어떻게 알 수 있을까요?
일반적인 접근법으로는 가상 주소의 최상위 비트 몇 개를 세그먼트 종류를 나타내는데 사용하는 것입니다. 이 기법은 VAX/VMS 시스템에서 사용되었습니다. 위의 예에서는 3개의 세그멘트가 있습니다. 주소 공간을 세그멘트로 나누기 위해서는 2비트가 필요합니다. 세그멘트를 표시하기 위해 가상 주소 14비트 중 최상위 2비트를 사용하는 경우 가상 주소의 모양은 다음과 같아 보일 것입니다.
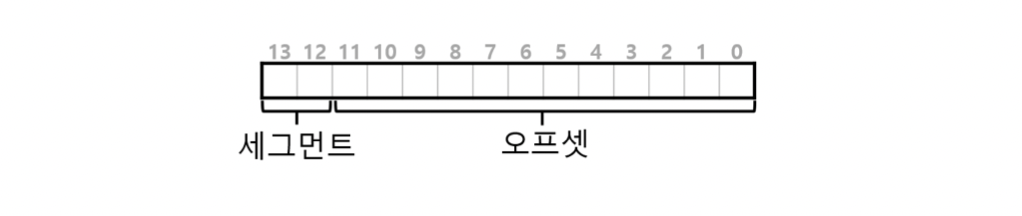
최상위 2비트가 00이면, 하드웨어는 가상 주소가 코드 세그멘트를 가리킨다는 것을 알고, 따라서 코드 세그멘트의 베이스와 바운드 쌍을 사용하여 주소를 정확한 물리 메모리에 재배치합니다. 최상위 2비트가 01이면 하드웨어는 주소가 힙 세그멘트라는 것을 인지하여 힙의 베이스와 바운드를 사용합니다
베이스와 바운드 값들을 배열로 저장할 경우, 물리 주소는 다음과 같이 계산됩니다

스택 세그먼트 참조
스택은 다른 세그먼트와 다른 구석이 있습니다. 코드와 힙은 아래로 자라는 반면에, 스택은 위로 자라기 때문입니다. 이 방향 이슈 때문에 다른 방식의 변환이 필요해집니다.
하드웨어 추가
간단한 하드웨어를 하나 추가합니다.
베이스-바운드 값 뿐 아니라 하드웨어는 세그먼트가 어느 방향으로 확장되는지도 알아야 합니다.
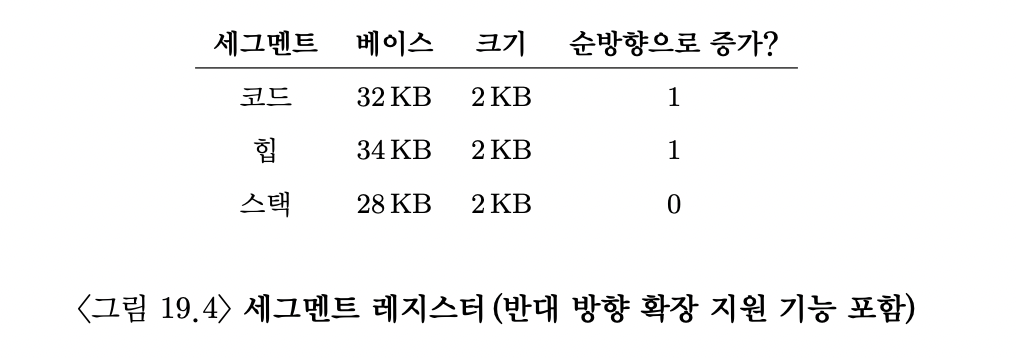
아래로 확장되면 1, 위로 확장되면 0으로 표시했습니다.
15KB 가상 주소에 접근한다고 예를 들어봅시다.
이 주소는 물리 주소의 27KB에 매핑되어야 합니다.
15KB = 11 1100 0000 0000 이고,
하드웨어는 상위 2비트를 사용해서 세그먼트를 지정합니다.
이를 고려하면 3KB의 오프셋이 남습니다.
올바른 음수 오프셋을 얻기 위해서 3KB에서 세그먼트 최대 크기를 빼야 합니다.
3KB-4KB(Max segment, bc of 12bit offset) = -1KB
따라서 Physical address = 28KB - 1KB = 27KB
세그멘테이션의 도입
세그멘테이션의 도입을 위해서는 운영체제가 몇가지 문제를 해결해야 한다
-
문맥교환
세그멘테이션을 사용할 경우 문맥 교환 시 운영체제는 세그멘트 레지스터의 저장과 복원을 해야합니다. 각 프로세스는 자신의 가상 주소공간을 갖는데, 운영체제는 프로세스 실행시 레지스터들을 올바르게 설정해야 합니다 -
세그먼트 크기의 변경
어떤 프로그램이 malloc()을 호출하여 객체를 할당했다고 하면, 어떤 경우에는 기존의 힙에서 해당 요청을 처리할 수 있을 것입니다. malloc()이 빈 공간을 찾고 해당 공간에 대한 포인터를 호출자에게 돌려줄 것입니다. 빈 공간이 없다면 힙 세그먼트의 크기를 증가시켜야 합니다. 메모리 관리 라이브러리가 힙을 확장하기 위하여 시스템 콜을 호출할 것입니다. 운영체제는 공간을 할당합니다. 세그먼트 크기 레지스터를 새로운 크기로 갱신하고 라이브러리에게 성공을 알려야 합니다. 그러면 라이브러리는 새로운 객체에 공간을 할당하고, 할당된 공간에 대한 포인터를 호출한 프로그램에게 반환하게 됩니다
시스템에 존재하는 메모리가 고갈되었거나, 프로그램이 이미 과도학 ㅔ많은 메모리를 사용 중이라면, 운영체제는 메모리 할당 요청을 거절할 수 있습니다 -
미사용 중인 물리 메모리 공간의 관리
새로운 주소 공간이 생성되면 운영체제는 이 공간의 세그멘트를 위한 비어있는 물리 메모리 영역을 찾을 수 있어야 합니다. 이전에 우리는 각 주소 공간의 크기가 동일하다고 가정했습니다. 물리 메모리는 프로세스가 탑재될 슬롯의 집합이라고 생각될 수 있었습니다. 지금은 프로세스가 많은 세그멘트를 가질 수 있고, 각 세그멘트는 크기가 다를 수 있습니다.
일반적으로 생길 수 있는 문제는 물리 메모리가 빠르게 작은 크기의 빈 공간들로 채워진다는 것입니다. 이 작은 빈 공간들은 새로이 생겨나는 세그멘트에 할당하기도 힘들거니와 기존 세그멘트를 확장하는 데에도 도움이 되지 않습니다. 이 문제를 외부 단편화라고 부릅니다
이 문제의 해결책 중 한 가지는 기존의 세그멘트를 정리하여 물리 메모리를 압축하는 것입니다.
빈 공간 관리
단편화 문제를 어떻게 방지할 것인가?
분할
분할 할당은 메모리 관리 기법 중 하나로, 메모리를 일정한 크기로 분할하여 작은 조각으로 나누어 프로세스에 할당하는 방식입니다. 이를 통해 메모리 내부 단편화를 해결할 수 있습니다. 분할 할당은 메모리를 작은 조각으로 나누어 할당하고, 할당 가능한 조각을 선택하여 프로세스에 할당하는 방식으로 동작합니다. 할당된 조각은 사용 중인 상태이고, 할당 가능한 조각은 다른 프로세스에 할당될 수 있는 상태입니다. 분할 할당은 간단하고 직관적인 방법이지만 내부 단편화로 인한 메모리 낭비가 발생할 수 있습니다.
병합
메모리 병합은 메모리에 있는 여러 개의 작은 빈 공간을 하나로 합치는 작업입니다. 메모리 병합을 통해 작은 조각들을 합쳐서 큰 연속적인 공간을 만들 수 있으며, 외부 단편화를 줄일 수 있습니다. 하지만 메모리 병합은 오버헤드가 크고, 병합을 위한 추가적인 작업과 시간이 필요하므로 성능에 영향을 줄 수 있습니다.
페이징
페이징에 관해서는 예전에 정리를 했던 게 있어서 그 부분을 봐주시면 감사하겠습니다
5/14 가상 메모리, 페이징(PAGING)
TLB
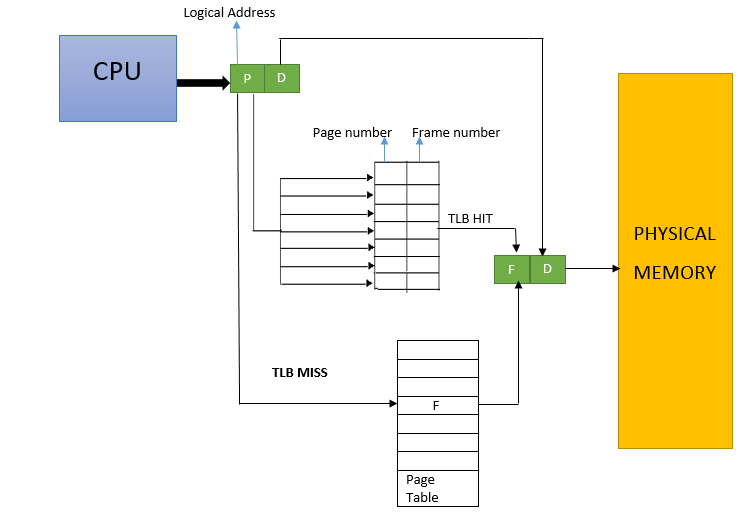
TLB(Translation Lookaside Buffer)는 가상 주소를 물리 주소로 변환하는 데 사용되는 캐시입니다. 가상 주소는 주로 프로세스가 사용하는 주소 공간이며, 물리 주소는 실제 메모리의 위치입니다. 가상 주소를 물리 주소로 변환하는 과정에서 TLB는 많은 시간을 절약하고 성능을 향상시킵니다.
TLB는 페이지 테이블의 일부를 캐시하는 하드웨어 구조입니다. 페이지 테이블은 가상 주소와 해당하는 물리 주소 간의 매핑 정보를 포함하고 있습니다. TLB는 최근에 접근한 페이지 테이블 항목을 캐시로 저장하여 빠른 접근이 가능하도록 합니다. 따라서 가상 주소를 물리 주소로 변환할 때는 먼저 TLB를 확인하고, TLB에 매핑 정보가 없는 경우 페이지 테이블을 참조하여 필요한 정보를 가져옵니다.
TLB는 캐시 메모리이기 때문에 제한된 크기를 가지고 있습니다. 때때로 가상 주소와 매핑된 물리 주소의 수가 TLB의 크기보다 많아져서 TLB 미스(TLB miss)가 발생할 수 있습니다. 이 경우, 추가적인 접근 시간이 필요하며, 페이지 테이블을 참조하여 TLB를 갱신합니다.
TLB는 메모리 관리의 성능을 향상시키기 위한 기법 중 하나로 사용됩니다. 캐시의 원리를 활용하여 가상 주소와 매핑된 물리 주소를 빠르게 찾아내므로, 매번 페이지 테이블을 참조하는 것보다 훨씬 효율적입니다.
