며칠 전, 저희 팀원분들과 이야기를 나누던 중 문득 궁금한게 하나 생겼습니다. 당시 공유했던 의문을 의식의 흐름 기법으로 표현하자면(ㅋㅋ) 다음과 같습니다.
"서버는 내가 보낸 요청 메시지에 적힌 아이피 주소를 보고 내 아이피 주소로 내가 요청한 정보를 보내주는구나. 좋아. 근데 사파리 브라우저로 서버와 통신하나 크롬 브라우저로 서버랑 통신하나 내 아이피는 동일할 것 같은데, 어떻게 사파리 브라우저로 보낸 요청을 서버는 헷갈리지 않고 사파리 브라우저를 향해 response할 수 있을까?"
클라이언트와 서버 사이의 네트워크 통신
결론부터 말하면 TCP secment 송, 수신이 그것을 가능하게 합니다. 서버에도 포트번호가 있듯이, 클라이언트도 사용하는 애플리케이션마다 포트번호가 있기 때문이었어요!
이 과정을 보다 자세히 이해하기 위해 클라이언트와 서버 사이의 데이터 송수신 과정 전반을 이미지를 통해 먼저 살펴보겠습니다(TCP school 출처).
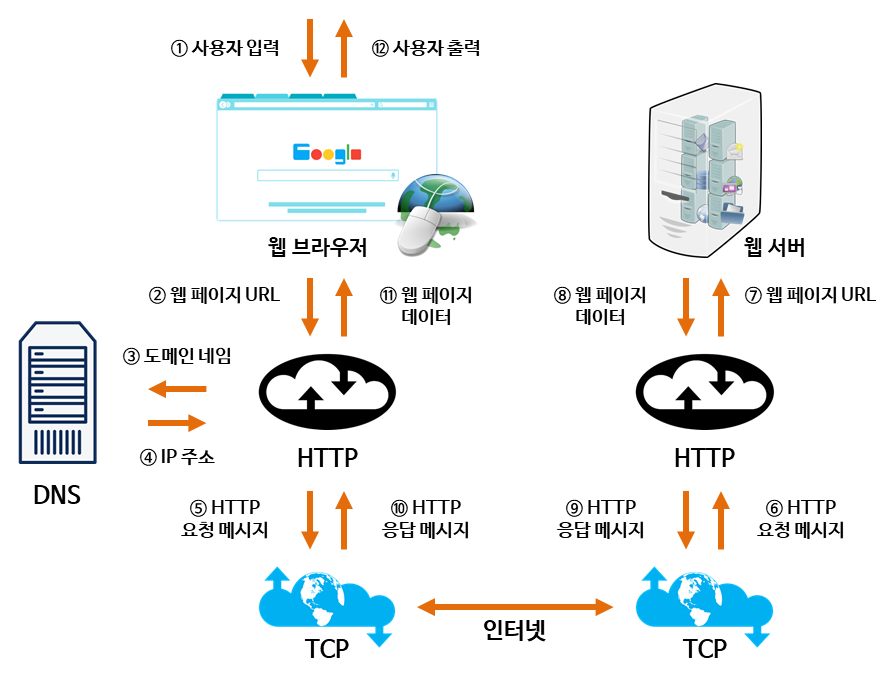
우선 사용자가 웹 브라우저를 통해 원하는 도메인을 검색창에 직접 입력했다고 가정하겠습니다(1). 웹 브라우저는 제가 입력한 도메인 주소를 HTTP protocol에 맞게 포장하고(2), 통신사 DNS 서버로 전송합니다(3). 통신사 DNS 서버는 dot(.)으로 구분된 도메인 주소 일부를 가지고 최종적으로 제가 입력한 도메인 주소와 매칭되는 IP를 찾기 위해 도메인 주소 일부와 경로 정보가 저장되어있는 다른 여러 DNS 서버(도메인 이름이 저장되어 있어 name server라고도 합니다)와 송수신 과정을 거칩니다. 검색한 도메인 주소와 매칭되는 IP를 찾는 것에 성공했다면(4), 브라우저는 IP 주소를 건내받아 HTTP 프로토콜을 사용해 HTTP 요청 메시지를 생성하게 됩니다(5). 이 HTTP 요청 메시지는 TCP 프로토콜을 사용해 여러 경로(정확히는 최적 거리에 있는 Router 사이의 송,수신)을 거쳐 해당 IP 주소를 가진 서버로 전송됩니다. 도착한 HTTP 요청 메시지는 TCP protocol(6), HTTP protocol을 거쳐 웹페이지 URL 정보로 변환됩니다(7). 서버는 요청한 정보에 맞춰 필요한 처리가 있다면 그것을 처리한 뒤(8), 그 결과물을 HTTP 프로토콜을 사용해 포장하는데, 이것이 HTTP 응답 메시지가 됩니다(9). 이후 TCP 프로토콜을 사용한 뒤, 어쩌면 거쳐왔을지도 모르는 경로(Router)를 거쳐 내 IP 주소로 이동합니다(10). HTTP 응답 메시지는 다시 TCP->HTTP 프로토콜을 거쳐 웹페이지 데이터로 변환됩니다(11). 이제 웹 브라우저는 서버로부터 받은 데이터를 바탕으로 요청한 콘텐츠를 표시하는 렌더링 엔진과, 사용자 인터페이스와 렌더링 엔진 사이의 동작을 제어하는 브라우저 엔진을 거쳐 사용자 인터페이스를 보여줍니다(12).
와, 정말. 요청한 웹페이지 화면을 빠르게 보여주기 위해 ms를 다툰다는걸 감안하면 정말 많은 과정이 한 순간 사이에 이루어 지는 것 같습니다(웹브라우저가 URL 구조를 해석하는 과정, 그리고 DNS 서버 사이의 송,수신 등은 간략하게 정리하였는데, 이는 다른 포스팅에서 조금 더 자세하게 이야기를 나누면 좋을 것 같습니다 :) ). 하지만 이것으론 부족합니다. 제가 궁금한 것은 서버가 어떻게 브라우저를 구분하는지 입니다.
TCP/IP 프로토콜을 사용한 송,수신
OSI 7 Layer와 TCP Protocol
위 그림의 HTTP ~ TCP 사이, 그러니까 5번과 10번, & 9번과 6번 부분을 이미지를 통해 조금 자세히 보겠습니다.
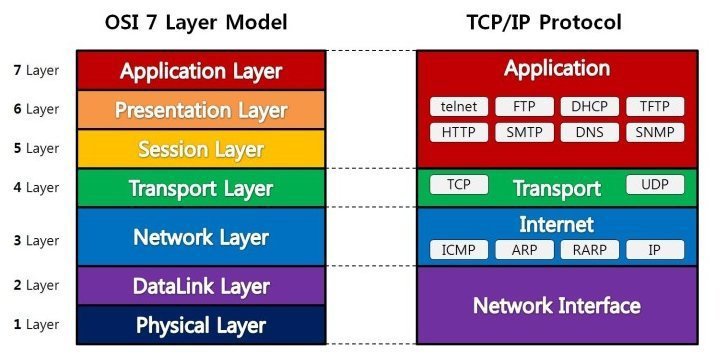
OSI 7 Layer와 TCP/IP Protocol은 모두 네트워크에서 통신이 일어나는 (같은)과정을 단계별로 도식화한 것입니다. 통신 과정을 계층별로 나눈 이유는 통신 과정을 단계별로 파악하기에 용이하기 때문입니다. 네트워크 통신 과정은 높은 단계에서 낮은 단계로, 또는 낮은 단계에서 높은 단계로 계층별로 순서대로 일어나기 때문에, 만약 문제가 발생하면 어떤 단계에서 문제가 일어났는지 파악하기 쉽다는 장점이 있습니다.
TCP/IP Protocol은 OSI 7 Layer와 계층을 대부분 공유하고 있고, 대부분의 네트워크가 이와 같은 프로토콜을 사용하고 있기 때문에 TCP/IP 프로토콜을 통해 네트워크 통신 과정을 이해하는 것이 더 바람직하다고 보는 견해도 있습니다만, 추상적인 구분일 뿐 계층을 공유하는 각 단계가 수행하는 것은 거의 동일하므로 저는 OSI 7 Layer를 통해 보다 자세히 이 과정을 살펴보려 합니다.
1. Physical Layer
이 계층은 비트, 즉 0, 1을 통해 데이터를 전송받거나 또는 외부로 데이터를 전송하는 역할을 수행합니다. 이름과 같이 소프트웨어와 같은 가상의(virtual) 것이기 보다 현실세계에 존재하는 물리적 장비, 즉 통신 케이블, 허브(컴퓨터 사이의 네트워크 연결), 리피터(노이즈로 인해 망가진 신호를 복원하거나 신호를 증폭하는 역할을 수행하지만, 현재는 대부분 허브로 대체되었습니다)등에 의존합니다.
2. DataLink Layer
데이터링크 레이어는 직접 연결된 두개의 노드 사이의 데이터 전송(node-to-node data transfer)기능을 수행합니다. 이 계층에서 노드란 스위치를 가리킨다고 봐도 무방합니다(2계층에 위치한 스위치라는 뜻에서 L2 switch라고도 합니다). 이 계층에서 스위치는 여러 역할을 수행하는데요. 예를 들어 스위치의 특정 포트를 활성 또는 비활성하는 기능, 특정 포트의 서비스 품질(Quality of Service) 조정, 네트워크 트래픽 모니터링을 위한 포트 미러링 설정 등이 있습니다.
L2 스위치의 가장 중요한 기능 중 하나는 MAC 필터링 및 액세스 제어 기능입니다. 사용자가 웹 브라우저를 통해 HTTP 요청 메세지를 서버를 향해 보내면, 이 요청 메시지는 4계층인 Transport Layer, 3계층인 Network Layer를 거쳐 패킷이라는 일정한 크기를 가진 데이터 전송의 한 단위로 변화하는데요. 패킷은 DataLink Layer에서 Frame이라는 패키지로 감싸지게 됩니다. Frame은 하나의 패킷과 출발지의 MAC Address, 그리고 도착지의 MAC address로 구성되어 있습니다. IP 주소가 때론 변할 수 있는, 클라이언트와 서버라는 최종 목적지들의 주소라면, MAC address란 절대 변하지 않고, (굳이 의도한 것이 아니라면)세계에서 유일한, 다른 컴퓨터(스위치)간 데이터를 전송하기 위한 물리적 주소입니다.

앞의 노란색 공간은 LIC 생산자를, 뒤의 파란색 공간은 이 LIC의 고유한 시리얼 넘버를 가리킵니다.Frame을 택배상자에 비유하면, 패킷은 전달할 물건, MAC address는 간선 상, 하차가 이루어질 터미널 주소에 비유할 수 있을 것 같습니다. 만약 중간중간 MAC address를 따라 여러 스위치(또는 라우터의 hop)를 거칠 필요 없이 한번에 서버-클라이언트 간 네트워크 통신이 가능하다면 어떨까요? 최종 목적지에 도달하기 위해 가까운 다음 스위치의 주소를 찾는 과정을 반복할 필요가 없으니, 아마도 이것이 더 빠르고, 리소스를 덜 소비할 것 같습니다. 그러나 서버-클라이언트 간 데이터 송수신 경로가 하나뿐이라면, 그 경로가 단절될 경우 송수신이 불가능해질 것입니다. MAC address를 따라 스위치간 Frame을 전송하는 방식은 유일한 경로에 대한 의존성을 분산시킬 수 있습니다. 또 IP 주소는 가변성을 가질 수 있기 때문에, 한 번 목표 네트워크 통신을 성공적으로 마무리지었다고 해서 영구히 그 IP 주소를 사용한 통신이 의도한 목적지와의 커뮤니케이션 결과물이라는 보장이 있을 수 없습니다. 반대로 MAC 주소만으로 네트워크 통신을 하는 것도 불가능에 가까운데, MAC 주소는 반영구적이기 때문입니다. MAC 주소간 통신만 존재한다면 MAC 주소 저장공간이 무한히 늘어나야겠지요.
다시 IP와 MAC 주소를 사용한 네트워크 통신 이야기로 돌아오겠습니다. L2 또는 L3 스위치가 패킷 내부의 비밀스런 정보를 모두 볼 필요는 없겠지요(택배기사분께서 택배의 내용물을 들여다 보지 않아도 물건을 전달할 수 있는 것처럼요). 스위치 간 네트워크 통신을 위해 필요한 정보는 출발지의 MAC address, 도착지의 Mac address, 그리고 출발지 및 도착지의 IP 주소 뿐입니다. 그런데 문제가 있습니다. 내 IP 주소와 서버 IP 주소, 그리고 내 MAC 주소는 알고 있습니다. 그런데 수많은 중간 목적지 사이에서 내 다음 목적지의 MAC 주소는 어떻게 알 수 있을까요?
본격적으로 경로 탐색을 시작하기 전에, 우선 목표 서버가 같은 네트워크 안에 있는지, 또는 그렇지 않은지 구분해야 합니다. 지금 필요한 것이 바로 목표 서버의 IP 주소와 나의 IP 주소, 그리고 서브넷 마스킹을 위한 서브넷 주소(255.255.255.0)입니다. 서브넷 주소는 두 아이피 주소 각각 앞의 몇 자리(즉 Network ID)가 서로 일치하는지 확인하기 위해 필요합니다. 만약 두 아이피 주소의 NetWork ID가 일치한다면 목표 서버는 같은 네트워크 안에 있다고 할 수 있습니다. 그렇다면 내 다음 목적지의 MAC 주소를 찾는 일은 L2 스위치 사이의 관계가 될 것입니다. 만약 그렇지 않다면, 내 L3 스위치(현재는 라우터와 같다고 봐도 좋을 것 같습니다)는 외부 네트워크의 다른 L3 스위치와 모종의 커뮤니케이션을 수행합니다. 둘을 구분하여, 아래에서 자세히 보시겠습니다.
우선 목표 서버가 같은 네트워크 안에 있는 경우입니다. 아시다시피 스위치에 연결된 컴퓨터는 하나가 아닙니다. Frame이 스위치에 전송되면, 스위치는 MAC 주소 테이블을 확인합니다. 만약 출발지 MAC 주소가 등록되어 있지 않다면, 내 MAC 주소를 Port와 함께 등록합니다. 그리고 목표 서버의 IP 주소와 매칭되는 MAC 주소가 스위치의 MAC 주소 테이블에 존재하는 경우, 목표 서버의 MAC 주소를 반환하면 끝입니다. 만약 MAC 주소가 존재하지 않는 경우, 스위치에 연결된 "모든" 컴퓨터에게 ARP 요청 메시지를 전송합니다. 이것을 Flooding이라고 합니다. ARP 요청 메시지를 수신한 컴퓨터 중, 목표 서버 IP와 Network ID가 일치하는 컴퓨터는 자신의 MAC 주소를 스위치로 반환합니다. 스위치는 목적지의 MAC 주소를 MAC 주소 테이블에 저장하고, 마침내 클라이언트는 스위치로부터 전달받은 서버의 MAC 주소를 확인한 뒤 통신을 시작합니다. 이러한 절차를 ARP Protocol(Address Resolution Protocol, 주소 결정 프로토콜)이라고 부릅니다.
3. Network Layer
만약 목표 서버가 같은 네트워크 안에 존재하지 않는다면 어떨까요? 외부 네트워크로 나가야 하니, 이젠 L2 스위치만이 아닌 3계층에 위치한 L3 스위치간의 송수신 문제를 포함합니다. 단일한 네트워크 안에서 MAC address로 경로를 찾는 것은 위에서 서술하였으니, 이번엔 L3 스위치(이하 라우터)간의 통신에 대해 더 살펴보겠습니다.
동일 네트워크 내부에 목표 서버가 존재하지 않는다면, 패킷은 기본 게이트웨이(Default Gateway)로 향합니다. 기본 게이트웨이는 내 컴퓨터가 속한 네트워크의 라우터를 말합니다. 어떤 패킷이던 자체 네트워크가 아닌 외부 네트워크에 도달하려면 반드시 게이트웨이를 거쳐야 합니다. 라우터 단위로 구성된 하나의 네트워크는 역시 다른 네트워크와 통신하기 위해 그 네트워크와 연결된 다른 라우터와 송수신합니다 (실제로 라우터가 네트워크의 한 단위는 아닙니다. 하나의 라우터는 여러개의 네트워크를 가지고 있을 수도 있습니다. 여기서는 쉽게 내용을 전달을 위해 한 라우터가 하나의 네트워크를 다른 네트워크와 구분하는 구분자라고 가정해보겠습니다. 웹이 무수한 라우터의 집합이라고 비유하기 위해 필요한 적절한 가정일 것 같네요 ㅎㅎ). 이 라우터와 라우터간 데이터(패킷) 전달은 한 번에 모든 경로를 이동함으로써 끝나는 것은 아닙니다. 인접 라우터까지 경로를 지정한 뒤, 인접 라우터로부터 최적 경로를 파악하여 최적 경로에 위치한 다른 인접 라우터로 패킷을 전송합니다. 이를 홉-바이-홉(hop-by-hop) 라우팅이라고 하고, 인접 라우터를 넥스트 홉(next hop)이라고 부릅니다. 문제는 최적 경로를 따라 넥스트 홉을 지정하는 것입니다.
각각 라우터는 라우팅 테이블(Routing table)이라는 저장소를 가지고 있습니다. 라우팅 테이블에는 여러 목적지 주소(IP)와 넥스트 홉의 IP 주소 등 경로 정보가 저장되어 있습니다. 라우터는 몇 가지 방법을 통해 이 최적 경로 정보를 수집하고 라우팅 테이블을 만듭니다. 서브넷 마스크를 사용해 네트워크 아이디가 일치하는(또는 가장 유사한) 라우터를 넥스트 홉으로 삼을 수도 있고요(다이렉트 라우팅). 개발자가 직접 특정 라우터를 넥스트 홉으로 삼도록 지정할 수도 있습니다(스태틱 라우팅). 특정 라우터를 무조건 넥스트 홉으로 지정하도록 하는 것은 지나치게 경로 의존성을 가지게 할 우려가 있습니다. 때문에 우회 경로를 찾는 로직이 필요한 경우도 있습니다(다이나믹 라우팅). 라우터가 점점 많아지고, 또 서브넷의 사용으로 인해 목표 서버의 IP와 완전히 일치하는 라우터를 찾기 어려운 경우도 있습니다. 때문에 신뢰성이 높은 라우팅 방법으로 얻어낸 주소별로 가중치를 둘 수도 있습니다. 다이렉트 라우팅, 스태틱 라우팅, 그리고 다이나믹 라우팅 순서로 우선순위를 가질 수 있습니다.
Packet
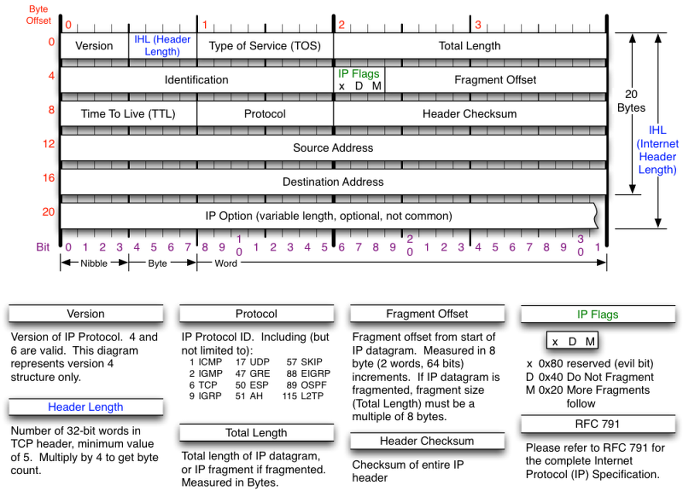
앞서 패킷에 대하여 계속 이야기하고 있는데요. 패킷은 데이터 전송의 최소 단위이면서, 동시에 출발지와 도착지의 IP주소 등을 포함하고 있습니다. 패킷의 헤더에는 IP의 버전을 가리키는 Version 필드, 라우팅할 때 서비스 우선순위를 정할 수 있는 Type-of-Service 필드, 패킷 분열 여부를 감지하는 Fragment identifier 필드, 목표 라우터에 도달하지 못할 것으로 판단되어 소멸되기 전에 미리 라우터를 건너뛸 수 있는 홉의 최대 한도를 정할 수 있는 Time-to-Live 필드(라우터를 건너뛸 때마다 하나씩 감소하여 0이되면 홉을 중단합니다)등 여러 옵션 정보가 담겨있습니다. 패킷의 Payload에 조각난 데이터가 담기게 되는데요. 페이로드의 최대 크기는 1460바이트로, 굉장히 작은 데이터 조각에 불과하지만, 이렇게 작은 조각을 여러 번 보냄으로써 커다란 데이터를 한번에 보냄으로써 발생할 수 있는 트래픽을 예방할 수 있습니다. 하드웨어 성능이 폭발적으로 증가하고 있는 지금은 패킷의 페이로드 크기를 더 늘리는 것도 가능할 것 같은데... 아마도 기존 네트워크와 충돌을 우려해서 일까요? :)
4. Transport Layer
커다란 데이터 덩어리 대신 패킷으로 데이터를 주고 받기 위해서는 우선 커다란 데이터를 잘게 쪼개는 작업이 필요할 것입니다. 상위 계층에서 HTTP 프로토콜을 통해 포장된 데이터는 4계층에서 네트워크 통신을 위한 작은 데이터 단위로 쪼개집니다. 모든 데이터가 쪼개지는 것은 아니고, 데이터가 최대 전송 유닛(Maximum Transmission Unit, MTU, 최대 1518Bytes)보다 큰 경우로 한정됩니다. MTU가 큰 용량은 아니기 때문에, 상당한 경우 데이터는 패킷 전송을 위해 쪼개져야 하는데요. 이 쪼개진 데이터에 TCP 헤더 또는 UDP 헤더가 붙은 것을 세그먼트(segment)라고 부릅니다. TCP 프로토콜과 UDP 프로토콜 모두 4계층에서 사용될 수 있는데요. 둘은 용도에 따라 다르게 쓰일 수 있습니다. 두 프로토콜을 구분하는 가장 큰 특징 중 하나는 일련 번호(Sequence number), 확인 응답 번호(Acknowledgment number), 윈도우 크기(Window size)등의 정보가 헤더에 담겨있는 지 여부입니다. UDP 헤더에는 상기한 정보가 포함되어있지 않기때문에 데이터 전송 속도 제어(Flow control), 패킷을 담아두는 버퍼가 넘치지 않도록 하는 혼잡 제어(Congestion control)등이 불가합니다. 즉 UDP 프로토콜은 TCP 프로토콜과 달리 데이터 전송의 신뢰성(Reliable transmission)을 보장하기 어렵습니다. 단 TCP 프로토콜은 반드시 목적지를 지정해야 하지만 UDP 프로토콜은 그렇지 않기 때문에, UDP 프로토콜이 브로트캐스트(Broadcast, 로컬 네트워크 내부의 컴퓨터에게 데이터를 일괄 전송하는 것. ARP Protocol에서도 언급했었죠?)에 더 적합하다고 볼 수 있습니다.
TCP 헤더의 구조
세그먼트는 Transport Layer 내부의 가상 공간인 TCP Buffer에 차곡차곡 쌓입니다. 앞서 패킷 하나가 네트워크 통신의 주체인 것 처럼 계속 이야기해왔지만, 하나의 패킷(세그먼트 + IP 헤더)마다 한번의 송신을 하는 것은 비효율적이기 때문에, 정해진 크기의 TCP Buffer에 세그먼트가 충분히 쌓이면 이 덩어리를 송수신합니다. 수신자는 한번에 받을 수 있는 정보 덩어리의 크기 정보를 TCP 헤더에 담아 보내는데, 이 크기를 윈도우 크기(Window size)라고 합니다. 송신자는 헤더에 담인 윈도우 크기를 보고 윈도우 크기만큼 한번에 정보 덩어리를 송신합니다. 수신자는 이 덩어리를 잘 받았다면, 송신자에게 확인 응답 번호(Acknowledgment number)를 보냅니다. 확인 응답 번호는 수신자가 받은 데이터 덩어리의 가장 끝 일련 번호(Sequence number)에 1을 더한 값입니다. 송신자는 확인 응답 번호를 받을 때 까지 대기하고 있습니다. 확인 응답 번호를 받은 송신자는 데이터 덩어리가 성공적으로 전송됐다고 믿고, 다음 시퀀스의 데이터 덩어리를 전송할 준비를 합니다. 윈도우 크기에 맞게 데이터 덩어리를 송수신하는 것은 네트워크 지연을 예방하기 위해 중요한 요건이 됩니다. 따라서 윈도우 크기를 고정하는 것 보다, 문제없이 전송이 이루어지면 윈도우 크기를 늘리거나, 중간에 데이터가 유실되거나 문제가 발생하면 윈도우 크기를 줄이는 등 유동적인 크기 조절이 보다 효율적인 데이터 전송을 가능하게 할 것입니다. 이를 Sliding window라고 부릅니다. 이 유동적인 윈도우 크기는 TCP Buffer 내부의 여유공간과 관련이 있습니다. 받은 세그먼트들을 호스트가 빠르게 처리해 TCP buffer를 빠르게 비우는 것도 트래픽 예방을 위해 중요한 요건 중 하나일텐데요. TCP Buffer 내부의 세그먼트들은 상위 계층의 응용 어플리케이션과 TCP 소켓을 매개로 상호작용합니다. TCP 소켓은 상위 계층(User mode)에서 TCP/IP 계층(Kernel mode)에 접근할 수 있는 추상적 인터페이스로서, 일종의 파일입니다. 읽고(req), 쓰는(res.send) 등의 작업이 소켓 파일 내부에서 이루어집니다. TCP 소켓은 IP 주소와 Port 주소를 더한 소켓 주소(Socket Address)를 갖는데, 해당 소켓 주소(그리고 해당 소켓)는 해당 호스트 내에서 유일하며 또 일시적(Emphemeral)입니다. 아무튼, 소켓을 통해 응용 어플리케이션이 충분히 빠른 시간 안에 데이터 덩어리를 소화하지 못하면 TCP buffer안에 세그먼트들은 점점 쌓일 것이고, 결국 통신 지연을 유발할 것입니다. 흥미로운 것은 이 Buffer 내 데이터 누적 현상은 데이터를 송신받고 난 다음에 일어나는 현상이라는 점인데요. 네트워크 통신 지연은 서버와 클라이언트 간 데이터 전송 지연만이 원인이 아닐 수 있다는 점을 꼭 기억할 필요가 있을 것 같습니다.
5. Session Layer
이제부터는 TCP/IP 프로토콜로 말하자면 응용 계층입니다. 이 계층에선 TCP/IP 세션을 만들거나 없에는 역할을 수행합니다. 세션은 두 계층간 통신을 정의하기 때문에, 통신의 방향성을 정하는 역할도 수행합니다. 통신의 방향성은 전이중 통신(Full Duplex, 두 계층 사이에 일방향 통신선이 각각의 방향으로 하나씩, 두 개 존재합니다. 데이터 송수신이 동시에 가능합니다), 반이중 통신(두 계층 사이에 양방향 통신선이 하나 존재합니다. 때문에 한쪽 계층이 송신 시 다른쪽에선 수신만 가능합니다), 동시 송수신 방식(Duplex, 일방향 통신선이 하나 존재합니다) 등으로 정할 수 있습니다.
6. Presentation Layer
이 계층에서는 사용자의 명령어를 완성하거나 결과를 표현해 줍니다. 데이터를 포장하거나, 압축하거나, 암호화합니다.
7. Application Layer
네트워크 소프트웨어의 UI 부분으로서, 사용자 I/O의 접점이기도 합니다.
서버는 어떻게 IP가 같은 두 브라우저를 구분할까?
처음의 질문을 기억하시나요? "서버는 어떻게 IP가 같은 두 브라우저를 구분할까?". IP가 같다면, IP 외 다른 식별자가 필요할 것입니다. 그 식별자는 바로 포트 주소였습니다. 포트 주소는 네트워크 서비스나 특정 프로세스를 구분하는 논리적 단위로, 16bit 크기를 가지고 있습니다. 즉 서로 다른 2^16개의 포트 번호가 존재할 수 있습니다. 잘 알려는 포트 번호로는 22번(SSH), 53번(DNS), 80번(WWW HTTP) 등이 있습니다. 0번~ 1023번 포트는 잘 알려진 포트(Well-known port), 1024번 ~ 49151번은 등록된 포트(Registered Port), 49152번 ~ 65535번은 동적 포트(Dynamic Port)라는 구분 기준으로 나눌수도 있습니다. 주의해야 할 점은 Server Socket의 최대 동시 연결 갯수가 포트 주소의 크기와 동일하지 않다는 부분인데요(만약 그렇다면 구글이나 네이버는 서버 동시 이용자 수 / 65535 개의 서버가 필요할 것입니다). 소켓의 수는 리눅스 파일 디스크립터 수 만큼 생성이 가능하다고 합니다. 소켓의 본질은 파일이니까요!
출처
OSI 7 Layer, (1) https://github.com/BJS-kr/Records/blob/main/%EC%95%8C%EC%93%B8%EC%BB%B4%EC%9E%A1/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC_%EC%83%81%EC%8B%9D.md, (2) https://shlee0882.tistory.com/110, (3) https://ryusae.tistory.com/4
arp protocol, (1) https://musclebear.tistory.com/12, (2) https://www.stevenjlee.net/2020/06/07/%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0-arp-address-resolution-protocol-%ED%94%84%EB%A1%9C%ED%86%A0%EC%BD%9C/, (3) https://en.wikipedia.org/wiki/Address_Resolution_Protocol#Example
router, https://catsbi.oopy.io/225439bd-ec84-4e16-aeca-0dfcb9954ea6
ip packet, https://mindnet.tistory.com/entry/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC-%EC%89%BD%EA%B2%8C-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0-18%ED%8E%B8-IP-Header-IP%ED%97%A4%EB%8D%94-%EA%B5%AC%EC%A1%B0
라우터와 L3 switch 구분, https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=nackji80&logNo=220228728915
IP, https://choseongho93.tistory.com/199
TCP, https://nesoy.github.io/articles/2018-10/TCP
슬라이딩 윈도우, https://4network.tistory.com/entry/windowsize
포트번호, https://ko.wikipedia.org/wiki/%ED%8F%AC%ED%8A%B8_(%EC%BB%B4%ED%93%A8%ED%84%B0_%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%82%B9)
