특정한 웹 서비스의 존재 이유는 무엇일까? 사람마다 그 답이 다르겠지만, 나는 기존에 존재하던 서비스를 개선하거나, 존재하지 않는 서비스를 새로 개발함으로써 서비스 이용자의 삶을 윤택하게 하는 것이라고 생각한다. 따라서 새로운 서비스를 기획하는 사람은 자신이 제공할 서비스에 대하여 다음과 같은 질문에 답할 수 있어야 할 것이다.
첫째, 내 서비스는 어떤 점에서 새로운가? 어떤 서비스가 다른 서비스보다 새롭다면, 같거나 유사한 문제의식을 가진 다른 상용 서비스들(이하 비교군 서비스)이 가진 장점과 단점을 구분할 수 있어야 한다. 또한, 내가 생각하는 서비스가 왜 지금까지 존재하지 않았는지 스스로 질문할 수 있을 것이다. 둘째, 누구를 위한 것인가? 내 서비스의 비교군에 비해 대상자를 좁히거나 넓힐 수 있을까? 또는 전혀 다른 관점에서 사용자를 특정할 수 있을까? 비교군 서비스를 사용할 수 있는 사람들이 그 서비스를 사용하지 않는 이유는 무엇일까? 셋째, 내 서비스가 사용자들의 삶을 어떻게 더 낫게 만들 수 있을까? 윤택하다는 것이 무슨 뜻일까? 비교군 서비스들은 왜 이들의 삶을 더 윤택하게 하지 못했을까? 상기한 질문들은 항해가 끝날 때 까지 계속해서 고민해야 할 부분이다. 진행 상황에 대해 기록을 남김으로써, 항해가 끝났을 때 우리 서비스가 이 질문에 얼마나 답할 수 있는지 스스로 판단하고자 여기에 기준을 남겨놓는다.
우리는 백엔드 개발 팀으로, 프론트 & 백엔드 협업 팀이 구체적인 서비스를 개발하는 것을 목적으로 하는 것과 달리, 백엔드 사이드에 한정하여 천만건 이상의 데이터 흐름을 통제하는 경험을 하는 것을 목적으로 하고 있다. 그럼에도, 구체적인 서비스를 기획하는 것은 서비스 개선 방향을 특정할 여지가 크다는 점, 우리 팀의 개발에 동기부여를 할 수 있다는 점 등에서 장점이 있을 것이라고 생각했다.
우리는 NodeJs 기반 "한국어 사용이 어려운 외국인을 위한 병원 탐색 서비스"를 기획하였다. 외국인 여행자 또는 이민자로서 한국어 사용이 어려운 경우를 상정한 서비스로서, 사용자의 현재 위치를 기반으로 특정 외국어가 가능한 근거리의 병원, 또는 약국 정보와 경로를 추천해주는 것을 목적으로 한다.

서비스를 이용하기 위해 로그인을 필요로 하는데, 회원가입시 Optional하게 Personal Informations를 입력하게 하였다. 이 나이, 성별, 한국/사보험 유무 등을 포함하는 이 Option은 외국인이 한국 병원에서 진료를 받기 위해 필요한 정보 중 일부로, 서비스 사용자가 추천 병원으로 이동하는 등의 경우 병원 또는 관련 전문가에게 제공할 목적으로 만들어졌다. 이는 서비스 사용자가 긴급한 경우, 병원 도착 후 문서 작성 시간을 최소화하기 위한 존재 목적도 겸하고 있다.
로그인에 성공하게 되면, 사용자는 자신의 증상(Symtoms)을 사용자가 원하는 언어로 입력할 수 있다. 서비스가 지원하는 언어는 영어, 태국어, 중국어 등 8개 언어로 한정하였는데, 이는 2021년 기준 새로 진료받은 외국인 환자의 국적을 기준으로 Top 8을 고른 것이다(https://www.korea.kr/news/pressReleaseView.do?newsId=156513354). 이는 약 80~90%의 외국인 환자의 언어를 커버할 수 있는 범주이다.
증상과 더불어, 사용자가 필요로하는 의료 수준(Necessary Medical Measures)과 긴급한 수준(Emergency Level)을 카테고리에서 선택하도록 했다. 이 정보는 DB에 저장된 병원 리스트로부터 추천 우선순위를 나눌 때 사용될 수 있다. 가령 사용자가 병원 진료가 필요한 것이 아니라 약 처방만으로 충분하고, 긴급 수준도 낮다면, 우리 서비스는 근거리에 위치한 외국어가 가능한 약국을 추천해 줄 수 있다. 반대의 경우라면 관련 병원을 추천해 줄 수 있을 것이다.
이렇게 증상, 필요로 하는 의료 수준 및 긴급 수준을 입력하면 Socket.io로 구현된 ChatRoom을 통해 Bot이 관련 정보를 종합 및 처리하여 가장 적합한 병원 정보를 반환할 수 있다. 사용자가 반환받는 병원 정보로는 병원의 이름, 운영 시간(사용 당시 운영시간이 아니라면 반환하지 않는다), 분과 명(Divisions. 내과, 가정의학과, etc...), 전화번호, 우리 서비스 사용자가 입력한 언어의 한국어 변역(using AWS Translator API), 사용자의 현재 위치로부터 추천 병원까지 최단 경로 등이다. 경로 탐색을 위해 Kakao API를 사용하였다.
단순히 자신의 증상을 입력한 것 만으로 관련 병원 정보를 정확히 탐색하기 어렵기 때문에, KoGTP2 기반 multi-classification 모델을 달아, Symptoms를 입력받으면 관련 분과 명(Division)을 반환하도록 하였다. 모델의 fine-tuning을 위해 하이닥 Q&A (https://www.hidoc.co.kr/healthqna/list)와 네이버 지식인으로부터 환자의 증상 및 담당 의사의 분과 명을 수집하였다. 하이닥 Q&A의 경우 데이터 편향성이 존재할 수 있다는 지적을 한 팀원으로부터 받을 수 있었는데, 하이닥 Q&A의 경우 환자가 증상에 대해 질문글을 올릴 때 진료과 및 답변을 받을 전문의를 직접 선택할 수 있도록 하고 있기 때문이다. 하이닥 서비스 이용자는, 자신의 질환에 대한 충분한 이해가 있다면, 관련 질환의 유명 전문의로부터 직접 답변을 받을 수 있다는 장점이 있겠지만, 학습 데이터로는 적합하지 않을 수 있다. 대중의 질환에 대한 이해와 의사의 이해가 반드시 일치하지 않을 수 있기 때문인데, 가령 자신의 질환에 대해 이해가 부족한 환자는 관련 분과보다 가장 먼저 보이는 진료과목 또는 점수(하이닥 스코어)가 높은 의사를 지명할 가능성이 있다. 하이닥 Q&A를 통해 질문할 때 선택할 수 있는 진료과목의 default는 가정의학과인데, 하이닥 Q&A에 등록된 진료과 별 질문 수 중 가장 Q&A가 많이 등록된 진료과목 역시 가정의학과(22년 11월 13일 현재 기준 약 41000개, 총 약 28만건)인데, 이는 약 2만 4천건이 등록된 정형외과보다 1.5배 이상 높고, 가장 등록된 질문수가 낮은 알레르기 내과(약 1천여건)보다 40배 이상 높은 질문 수이다. 이는 가정의학(Family Midicine)이 1차 병원으로서 진료 범위가 넓은 것을 감안하더라도 상당히 큰 격차인데, 정보 선택에 있어서 대중적 편향(질문군을 대표하는 분과를 선택하려는 대표성 휴리스틱Representative heuristic)이 개입한 결과로 볼 여지가 존재할 가능성이 있다. 따라서 환자가 증상에 대해 질문할 때 진료과목을 선택하지 않고, 대신 의사가 질문을 보고 답변을 달지 선택하는 네이버 지식인 Q&A 서비스로부터 Fine-tuning data를 추가로 crawling하기로 했다. 하이닥 데이터는 크롤링이 거의 완료된 상황인데, 네이버 지식인 데이터를 사용한 경우와 accuracy를 비교하여 최종적으로 하나를 선택할 예정이다.
KoGTP-2 모델이 반환할 진료과목수는 가정의학과, 내과, 외과, 신경과, 한의학과 등 16개로, 약국 정보는 여기 포함되어 있지 않은데, 우리 서비스 사용자의 input value중 하나인 필요로하는 진료 수준(Necessary Medical Measures)에 따라 인공지능 모델을 돌려 분과명을 추출하지 않고 DB에서 직접 반환하도록 하였다. 현재 수집한 DB는 서울시 공공데이터 및 보건소 홈페이지로부터 크롤링한 것으로(중앙응급의료센터(https://www.e-gen.or.kr/intro/intro.do) 및 각 자치구 보건소), 서울시 내 약 40000개의 병원 정보와 400여개의 외국어 지원 가능 병원 정보, 외국어 사용이 가능한 수백여개의 약국 정보 등이다(JSON 변환 후 Bulk Create, 총 39065개 + a).
KoGTP2 모델은 구현되어 있지만 Fine-tuning용 데이터를 수집하는 단계에 아직 머물러 있는데, 과도하게 crawling을 요청하면 서버로부터 IP Ban을 당하는 것 같다. 관련 이슈에 대해 의논한 결과, 현재 팀 내에서 사용 가능한 해결책은 크게 두 가지로, Thor를 사용해 VPN효과를 얻는 것, 다른 하나는 도커 인스턴스를 여러 개 만들어 서버에 crawling 요청을 하는 것이었다. Thor를 사용해 크롤링하는 것에는 성공했지만 속도가 매우 느린 것이 단점이어서, 도커를 사용하는 방법을 시도하는 중에 있다.
백엔드 서버에서 데이터 플로우를 도식화 해보면 다음과 같다.

WAS와 WS는 상기한 대로 구현되고 있지만, 문제는 서버 부하를 줄이기 위해 존재하는 Cache Server의 구현에 있다. 외국어 Query를 한국어로 번역한 뒤, Cache server의 Q&A 테이블에 저장된 Query를 전문검색(Full-text query)하고자 한다. 입력받은 query와 cache server에 저장된 query의 유사도(Similarity)를 판단하여 정확한 Answer를 반환하기 위해서이다. Answer 정보는 캐시 서버에 저장된, 다른 사용자의 검색 당시 현재 위치를 제외한 나머지 병원정보들을 일컫는다.
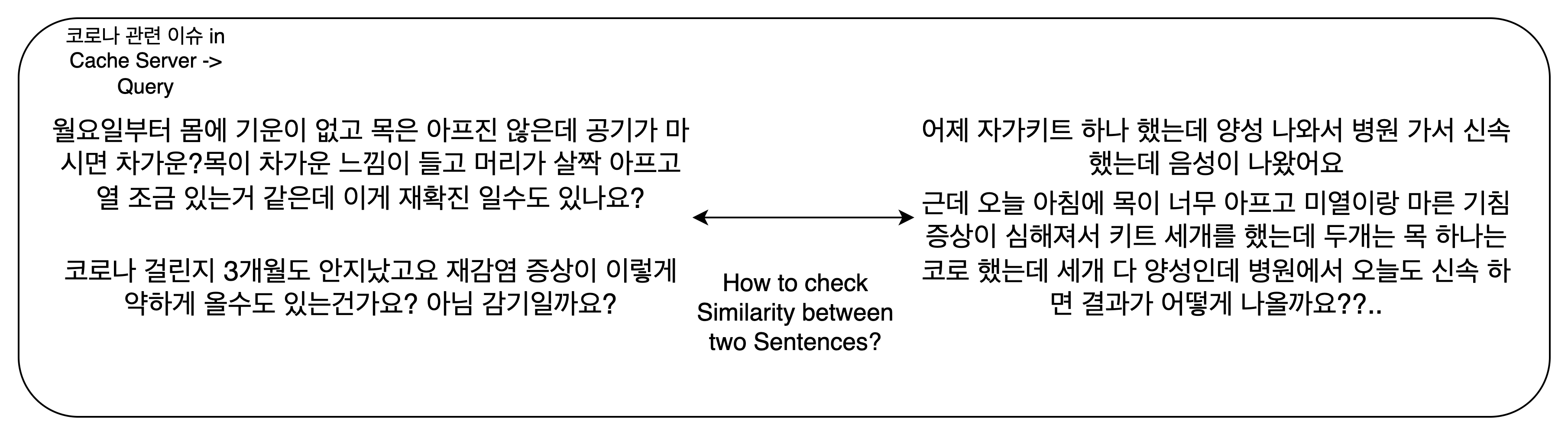
두 문장간 유사도를 측정하기 위해 크게 세 가지의 방법을 의논하고 있다. 첫째, 자카드 유사도 기반 검색 알고리즘을 도입할 수 있다. 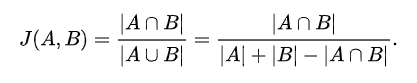
아주 단순하지만 그만큼 가벼운 방법론으로, 두 문장이 공통적으로 사용하는 단어의 갯수를 두 문장에 사용된 총 단어의 갯수로 나눈 값을 두 문장 사이의 유사도로 삼는 것이다. 그러나 우리 서비스는 두 한국어로 번역된 문장 사이의 유사도를 측정하는데, 한국어 형태소는 의미가 유사하지만 다른 표현 방식들이 존재하고(가령 먹고, 먹으니, 먹되, 먹는 등은 기본형은 동일하지만 표현방식이 조금씩 다르다), 같은 동음이의어가 존재할 수 있다(가령 "사과"라는 단어는 맥락에 따라 apple일수도, appology일 수도 있다). 따라서 자카드 유사도가 두 query의 의미론적 유사성을 나타내는 충실한 지표라는 보장이 없다. 두 번째 방법은 tri 자료구조 형식으로 query 문장 전체를 저장하고, 자료구조 중간부터 탐색 가능한 탐색 알고리즘을 개발하여 search하는 것이다. 이 아이디어는 즉흥적인 것으로 효율성이 떨어져 폐기하였다. 세 번째 방법은 KeyBERT model을 사용해 문장의 중심 키워드를 몇 개 추출한 뒤, 이 keywords로 ElasticSearch 기반 DB를 search하는 것이다. 자카드 유사도 기반 알고리즘이 가진 신뢰성 문제를 해결하는 데 도움이 되지만, 기존의 KoGTP2 기반 분류 모델의 무거움을 해소하고자 cache서버를 도입하는 입장에서, 다른 인공지능 모델을 추가하는 것이 과연 좋은 선택일지 의문이라는 점이다. 따라서 모델 또는 cache서버 경량화를 위한 별도의 구상이 필요한 시점이다.
또 다른 당면과제는 서버간 부하 분산 issue이다. 가령 WAS에 너무 많은 부담이 몰리게 되면, WS는 순서에 따른 데이터 처리가 어려워지면서 전반적인 서비스 속도의 저하로 이어질 수 있다. Nodejs는 non-blocking single thread system이므로, 비동기 처리의 강점을 살리면서 부하를 분산하는 로드밸런싱 기법이 필요할 수 있다. Docker / k8s는 사용가능한 선택지 중 하나로, AWS Kinesis와 병렬 사용 가능한지 여부를 탐색하고 있다. 멘토님께서는 AWS ECS fargate를 추천해주셨는데, 우리 서비스에 어떻게 접목할 수 있을 지 의논중에 있다. 또한 현재는 우리 서비스가 Javascript & express 서버로 구현되고 있지만, 차후 MSA 형태로 리팩토링할 때 Nest.js의 모듈 기반 아키텍쳐 구현 방식이 도움이 될 것으로 보고 있다. 따라서 Nest.js 스터디를 4~6회 정도로 운영할 생각이다.
마지막으로 병원 Data의 validation 문제가 남아있다. 어떻게 병원 DB의 최신성을 유지할 수 있을까? 어떤 병원은 외국어 지원 가능 여부가 달라질 수도 있고, 폐업하거나 이전할 수도 있다. 지금은 Kakao API를 사용해 병원의 폐업 여부를 탐색하고 있지만, 우회로로써 외부 API에 의존하지 않는 더 나은 방법을 의논중이다.
