금주의 성과는 데이터 전처리 코드 개선으로 인공지능 모델의 accuracy를 0.78 -> 0.92까지 향상시킨 점, 인공지능 모델 배포 후 기존에 구상했던 모든 서버를 구현, 연결하여 부하 테스트를 성공했다는 점과, AI모델이 올라가있는 서버를 덜 쓰기 위해 구상했던 캐시 서버의 개선된 버전을 온라인에 배포했다는 것이다. 데이터 흐름의 초기 구상은 다음과 같았다.
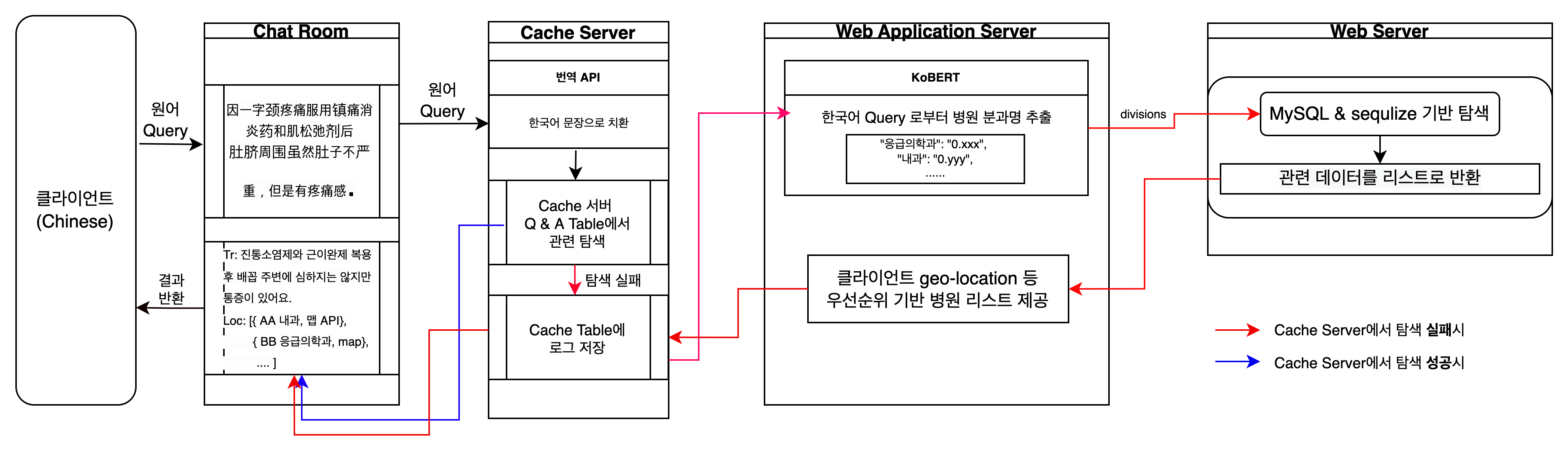
서비스 사용자로부터 외국어로 된 증상을 입력받으면, 캐시서버는 번역 API로부터 한국어로 번역된 문장을 받는다. 이 번역된 문장은 AI 서버로 향하고, AI 서버는 전처리 및 토큰화된 wordset을 반환한다. 캐시 서버는 내부 Q&A 테이블을 wordset으로 검색하는데, Q&A 테이블에 저장된 wordset과 검색하기 위한 wordset의 일치도가 가장 높은 Question의 Answer를 반환한다. 캐시 서버의 Q&A wordset은 서비스 사용자의 성공적인 탐색 사례를 전처리된 단어 집합인 wordset형태로 모두 저장한다. 캐시 서버는 또한 오래된 정보 또는 거의 재탐색되지 않은 정보를 삭제한다. 예를 들어 "목", "편도", "열과 통증" 따위의 단어가 검색 wordset과 Q&A 테이블의 Question wordset에 공통되어 있다면, 이 두 set 사이의 일치도가 높을 것이고, 이 Question과 매칭되어 있는 Answer("이비인후과")가 반환될 확률도 높아질 것이다. 일치도가 유사한 여러 개의 Question이 탐색되거나 유의한 Answer를 찾지 못한다면, 캐시 서버는 AI 서버에게 Answer를 요구한다.
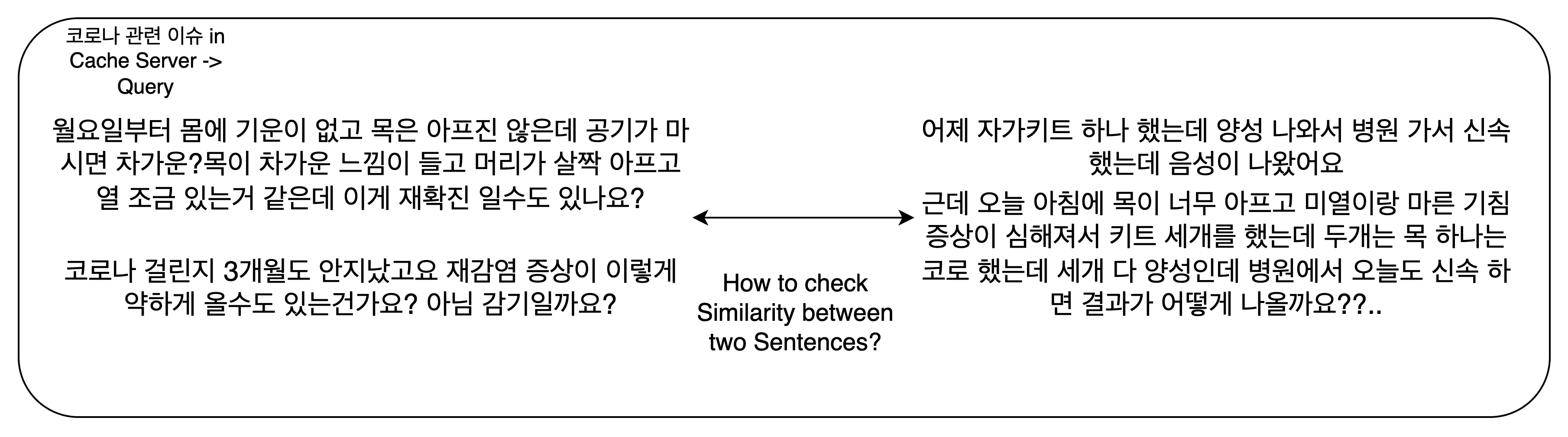
그러나 이 방법은 몇 가지 문제가 있다. 첫째, 일치도(또는 질문 사이의 유사한 정도)를 비교하기 위해 Q&A dataset 내부의 모든 Question을 탐색해야 한다. 단 하나의 적합한 정보를 추출하기 위해, 불필요한 n-1번의 검색 결과는 버려야한다. 둘째, 우리 서비스는 모두 캐시서버를 통과하고 있는데, 캐시서버에 과도한 읽기, 쓰기, 삭제 요청이 몰리게 되면 AI서버나 병원 정보를 저장하고 있는 WS가 얼마나 크던 서비스 결과를 받아볼 수 없게 된다. 캐시 서버에 저장된 데이터의 신선도를 보장하기 위해 실시간으로 데이터를 입력받고 삭제하는 것은 캐시 서버에 큰 부담을 줄 수 있다. 셋째, 보다 정확히 두 wordset 사이의 일치도를 계산하기 위하여 더 복잡한 알고리즘, 가령 keyBERT와 같은 AI 모델이 사용될 수 있지만, AI 서버를 덜 쓰기 위하여 다른 AI 모델을 도입하는 것은 모순적이다.
이 문제를 개선하기 위해 캐시 서버를 다음과 같이 개선하였다. 첫째, 미세 조정 학습을 위해 수집한 약 20만개의 네이버 Q&A 증상 데이터로부터 약 30만개의 단어와 14개 분과로 구성된 분과별 TF-IDF 테이블을 만들었다. TF-IDF 테이블은 전처리된 단어 Tokens가 분과 별로 가지는 나이브한 가중치 정보를 내포하고 있다. TF-IDF의 아이디어는 단순한데, 분과 별로 그 Token이 등장한 비율(Term Frequency)과 그 Token이 등장한 분과 수의 역수(Inverse Document Frequency)를 곱한 것이다. 오직 그 분과에서 여러 번 등장하는 Token이라면 TF와 IDF가 커질 것이므로, 더 높은 가중치를 가질 것이다. 그 반대의 경우도 마찬가지이다. 이런 나이브한 가중치를 사용하는 이유 중 하나는 이 TF-IDF 테이블이 주기적(가령 하루, 일주일, 한달 등 긴 기간)으로 update될 것을 가정할 때, 사이 기간이 짧을 수록 서버 부하가 증가하므로, 단순한 연산으로 구성할 수 있되 정확도와 속도를 Trade-off할 수 있다면 좋을 것이라고 판단했기 때문이었다. 둘째, 캐시 서버는 TF-IDF 테이블을 저장하고 있다가, 사용자로부터 증상 데이터를 입력 받으면 AI 서버에 전처리를 요구한다. AI 서버로부터 전처리된 단어 Tokens를 받은 캐시 서버는 내부의 TF-IDF 테이블로부터 이 단어와 매칭된 가중치를 검색한다. 기존에 Q&A 테이블에 저장된 모든 question wordset이 타겟이 된 것과 달리, 오직 Token 개수 만큼의 숫자 데이터를 불러오고 있을 뿐이다. 하나의 단어 Token은 TF-IDF 테이블에서 1x14의 크기를 가지며, 각 분과를 가리키는 방향성과 크기를 TF-IDF 형태의 나이브한 가중치로 가지고 있다. 검색이 끝나면, 분과 별로 가중치의 합을 구한다. 가중치의 합이 가장 큰 분과가 캐시 서버의 Answer가 된다. 이제 이 단순한 알고리즘이 AI 서버가 내놓은 답과 일치할 가능성을 정의하고, 정답일 가능성이 낮다면 AI 서버에서 정답을 구하도록 해야한다. 이를 위해 가중치 합의 분산을 구하도록 했다. 사용자가 입력한 증상 데이터의 길이가 너무 짧거나 긴 경우 발생할 문제를 예방하기 위해, 전처리된 Token 개수로 검색된 가중치의 분산을 나누어준다. 만약 분산값이 충분히 크다면, 사용자가 입력한 문장이 가지는 분과를 향한 방향성과 크기 역시 클 것으로 예상할 수 있다. 반대의 경우라면, 1. 입력받은 정보가 환자의 증상 정보가 아닌 경우(가령 사용자가 증상과 전혀 관련되지 않은 지문을 입력한 경우) 클라이언트에 경고 메시지("증상을 입력해 주세요" 등)를 전달하면 되고, 2. 증상 정보이지만 분과가 모호한 경우(가령 "외과" 분과와 "성형외과" 분과) AI 서버로 요청을 보내야 한다. AI 서버의 예측이 정답일 확률이 낮다면, 역시 클라이언트로 경고 메시지("자세히 입력해주세요", "증상을 입력해주세요" 등) 또는 다른 제안(인간 상담원과 연결 등)를 보내야 한다. 이를 대처하기 위해 AI 서버에 정답률이 낮을 경우의 예외 처리를 추가하였고, 캐시 서버가 내부 테이블을 검색할 때 TF-IDF 테이블에 없는 단어가 포함된 비율을 정의, 10% 이상 단어집에 없는 단어가 포함된 input을 받으면 경고 메시지를 반환하도록 하였다.
개선된 캐시 서버는 약 40개 단어로 이루어진 증상 데이터 하나를 Input 받았을 때 평균 1.45초 정도의 response time을 보였다. 동일 조건에서 AI server를 거치는 경우와 비교해 약 60%에 가까운 정도의 속도 향상을 보였으나, 트래픽이 몰리는 경우, 단어 길이 조정, 분산의 유의한 수준 변경을 통한 정확도-속도 Trade-off 등 다양한 테스팅 조건 하에서 무조건 AI 서버를 통과하는 것 보다 더 나은 속도를 보이면서 상당한 수준의 정확도를 보일 수 있을지 테스트 및 코드 개선을 이번 주 진행할 예정이다. 또 이번 주에 AI 서버를 t2xlarge에서 p2xlarge로 변경하면서 GPU를 사용한 예측이 가능해질 것이므로, 더 개선된 서버 조건에서 부하 및 성능 테스트를 진행할 예정이다.
남은 이슈중 하나는 보안 문제이다. 환자의 증상 정보는 민감정보에 속할 수 있고, 법적 보호 대상에 속하기 때문에 보안 이슈는 서비스 구현에 매우 크게 다가오는 부분인데, 본래 Https 서버들 사이의 커뮤니케이션을 전제하고 있었으나, socketio "unable to verify the first certificate" 에러 때문에 답보 상태에 있다(https://stackoverflow.com/questions/32248166/socket-io-unable-to-verify-the-first-certificate). stack overflow에 질문을 올려놓은 상태이며, 이번 주 내로 해결해야 할 과제로 잡았다. https 문제가 해결되면 helmet module을 적용할 예정이다.
마지막으로 Docker로 서버를 감싸는 것과 k8s 기반 로드밸런싱, nestjs + MSA 기반 리팩토링 과제가 남아있는데, 이는 상기한 이슈 해결 이후, 마지막 주 과제로 잡고 있다.
잘 마무리지을 수 있기를 빌며..
