
오늘은 이전에 챌린지반에서 강의를 진행했었던 예상 면접 질문들을 정리해 보려고 한다.
[Class와 Struct의 차이]
-
Class와 Struct는 사용자 데이터 타입을 정의할 때 사용된다. 일반적으로 Class는 객체를 정의할 때 사용하고, Struct는 데이터의 집합 느낌으로 사용한다.
-
Class는 상속이 가능하지만, Struct는 상속이 불가능하다.
-
Class는 참조 타입이고, Struct는 값 타입이다. 이에 따라 저장 메모리 영역이 다르다. (Class는 힙 영역, Struct는 스택 영역)
[스택, 힙 메모리의 차이]
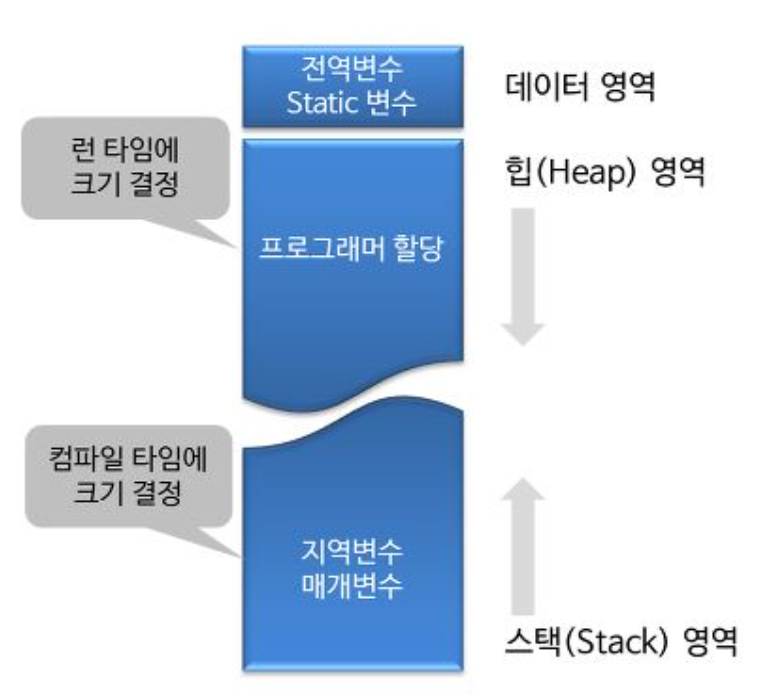
-
힙 영역 -> new 키워드로 생성하는 모든 것들. C#에선 가비지 컬렉터가 관리해준다.
-
스택 영역 -> 지역변수, 매개변수, Struct
[MVC 패턴이란?]
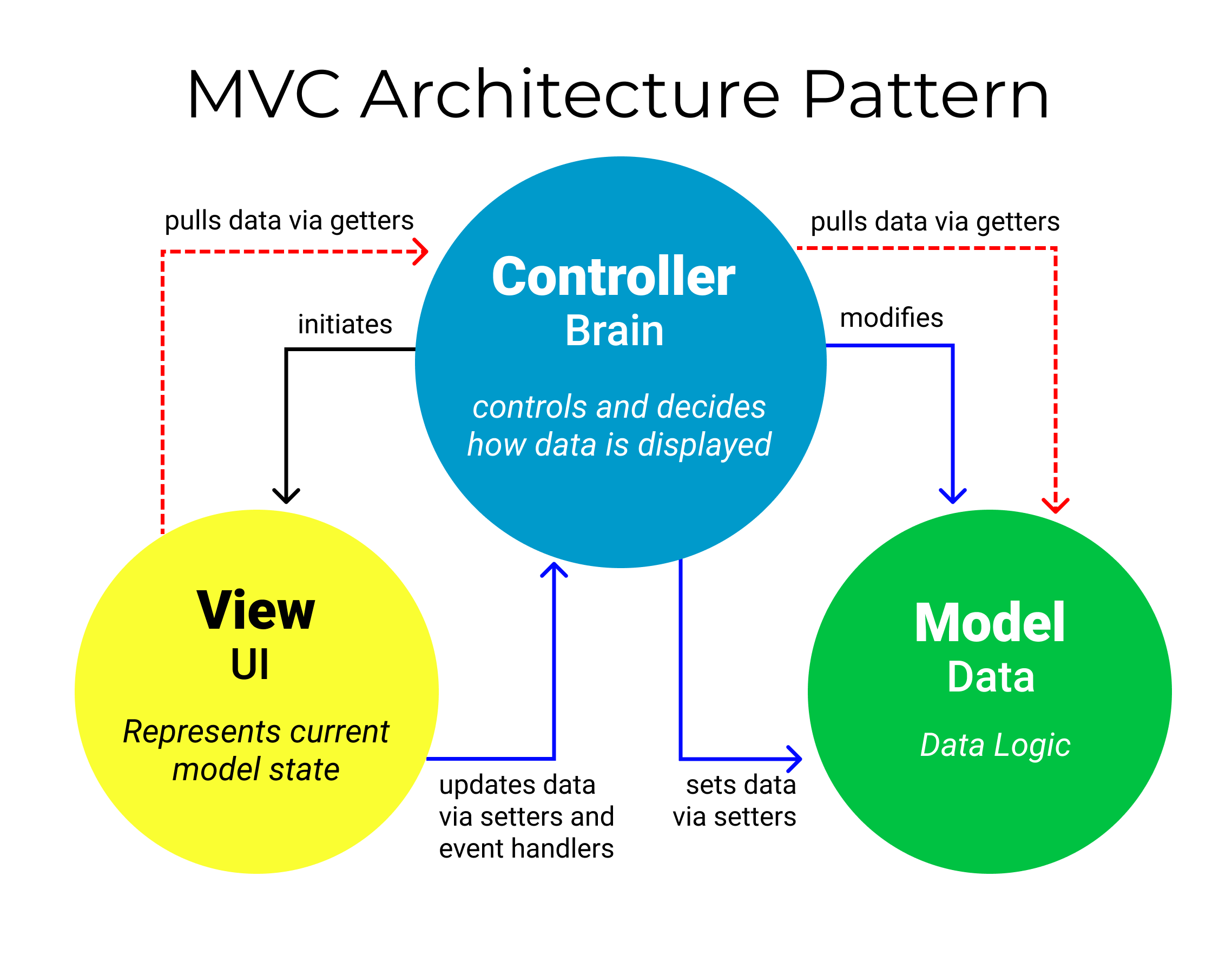
MVC 패턴은 Model, View, Controller 라는 요소로 코드를 분리하여 구성하는 패턴이다.
<Model>
게임의 데이터 와 비즈니스 로직을 처리
데이터 저장소와의 상호작용을 통해 데이터를 관리하는 역할을 수행
<View>
게임에서 외적으로 보이는 모든 요소 들이다.
모델의 데이터를 시각적으로 나타내는 역할을 수행
<Controller>
게임의 핵심 로직 들이다.
사용자의 입력을 받아 Model을 조작하여 데이터를 업데이트하고 View를 갱신하는 역할을 수행한다.
상호작용 방식
- 사용자가 게임에서 입력
- View가 입력을 감지하고 Controller에게 전달
- Controller는 입력을 처리하고 Model의 데이터를 업데이트
- Model은 데이터와 관련된 비즈니스 로직을 수행. 필요한 경우 데이터베이스와 상호작용. 이후 완료된 결과를 Controller에 반환.
- Controller는 Model의 결과를 받아 View에 전달.
- View는 전달받은 데이터를 사용하여 사용자에게 보여지는 화면을 업데이트
[가비지 컬렉션이란?]
힙 영역에 메모리를 할당하고 해제하지 않으면, 메모리에 올라온 상태가 유지된다. C나 C++은 프로그래머가 메모리를 직접 해제해줘야하지만, C#은 메모리를 관리해주는 시스템이 존재한다. 이 시스템의 중심이 되는 기능이 가비지 컬렉션이고, 이를 담당하고 있는 것이 가비지 컬렉터이다.
[유니티 최적화 기법]
<오브젝트 풀링>
오브젝트를 동적으로 생성 및 파괴를 하는 것이 아니라 미리 생성해두고 필요할 때만 꺼내서 쓰는 방식 이다. 예를 들어 게임에서 사용할 오브젝트를 로드 단계에서 일괄적으로 생성하여 오브젝트 풀에 저장해두고, 필요할 때 오브젝트 풀에서 꺼내서 사용하고 필요없을 때 오브젝트 풀에 넣는 방식이다. 이렇게 처리하면 게임 진행 단계에서의 GC.Alloc을 피할 수 있어 최적화에 유리하다.
하지만, 오브젝트 풀링을 사용하면 기본적으로 오브젝트 풀에 오브젝트들을 미리 생성해서 갖고 있기 때문에 계속해서 메모리를 사용할 수 밖에 없다.
따라서 오브젝트 풀의 크기를 작지도 크지도 않게 적당한 크기로 만드는 것이 오브젝트 풀링의 핵심이다.
<Class or Struct>
클래스는 힙 영역에 할당되고, 구조체는 스택 영역에 할당된다. 따라서 클래스와 달리 구조체는 인스턴스를 만들고 없애도 GC에 부담을 주지 않는다.
<캐싱>
당연한 얘기지만 자주 쓸 것 같은 오브젝트들은 사용할 때 마다 GetComponent하는 것이 아니라. 미리 캐싱해두고 사용하면 좋다. 예를 들어 플레이어가 일정 시간마다 타겟을 공격해야 되면 타겟을 공격할 때마다 찾는 것이 아니라. 처음 공격하기 전에 타겟을 미리 검색해두고, 일정 시간마다 공격하도록 처리해야한다.
<스프라이트 아틀라스>
여러 개의 텍스처를 단일 텍스처로 결합하는 기법이다. 여러 개의 스프라이트를 불러오려면 하나씩 불러와야 하기 때문에 불러 오는 스프라이트 개수만큼 드로우 콜이 생기는 데, 스프라이트 아틀라스를 사용하면 하나의 텍스처를 불러오기 때문에 드로우 콜이 한 번만 일어난다.
[유니티의 생명주기(Life Cycle]
유니티에는 사용자가 호출하지 않아도 자동으로 호출되는 함수들이 존재한다. 이 함수들의 호출 주기를 생명주기라고 부른다.
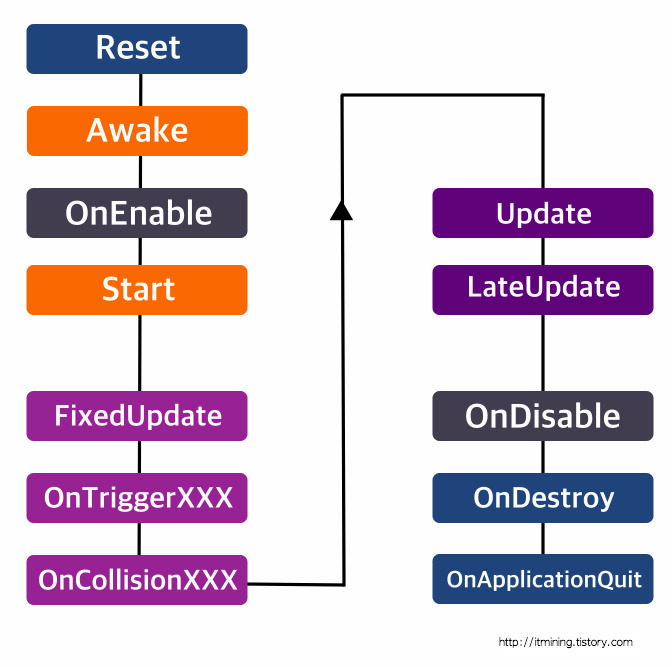
[리플렉션]
객체 자신에 대한 정보를 런타임에 들여다보는 기술. 보통 코드를 작성할 때 컴파일 타임에 모든 타입과 멤버가 정적으로 결정되지만, 리플렉션을 사용하면 실행 도중에 타입을 분석하고 동적으로 메서드를 호출하거나 값을 변경할 수 있음
[객체 지향 프로그래밍]
객체 지향은 객체를 중심으로 프로그램을 개발하는 것이다. 가장 큰 특징은 클래스를 활용하여 데이터부분과 처리부분을 하나로 묶어서 인스턴스화 시켜 사용한다는 점이다. 장점은 코드를 재사용하기 좋고, 유지보수가 편하다는 점이다.
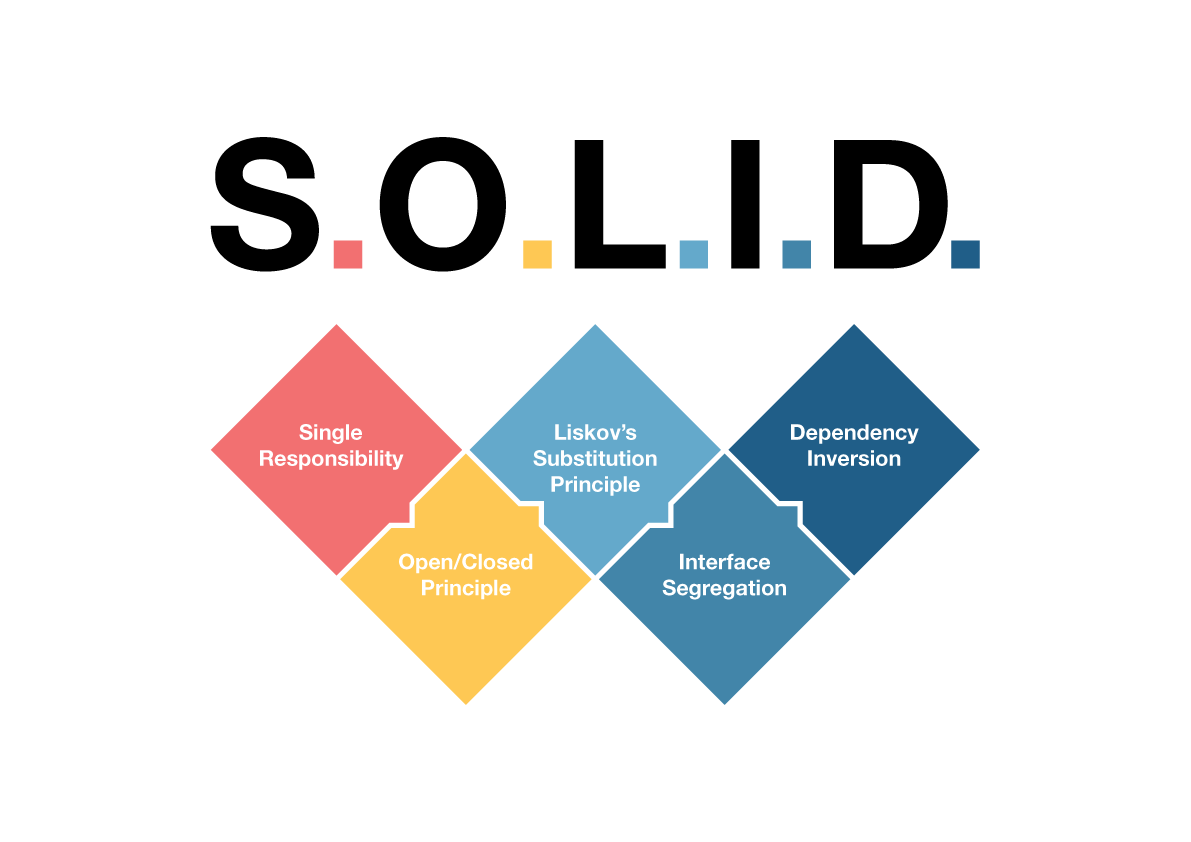
<5가지 설계 원칙(SOLID 원칙)>
- 단일 책임 원칙 : 클래스는 단 하나의 목적을 가져야 하며, 클래스를 변경하는 이유는 단 하나의 이유여야 한다.
- 개방 폐쇄 원칙 : 클래스는 확장에는 열려 있고, 변경에는 닫혀 있어야 한다.
- 리스코프 치환 원칙 : 상위 타입의 객체를 하위 타입으로 바꾸어도 프로그램은 일관되게 동작해야 한다.
- 인터페이스 분리 원칙 : 클라이언트는 이용하지 않는 메서드에 의존하지 않도록 인터페이스를 분리해야 한다.
- 의존 역전 법칙 : 클라이언트는 추상화(인터페이스)에 의존해야 하며, 구체화(구현된 클래스)에 의존해선 안된다.
<4가지 특징>
캡슐화
관련성 있는 데이터와 그 데이터를 다루는 메서드를 클래스로 묶고, 외부에서 직접적인 접근을 제어하는 것. Unity에선 보통 프로퍼티의 get, set 메소드를 활용해서 간접적으로 접근하도록 한다.추상화
간단하게 설명하면 여러 파생 클래스에서 반드시 필요한 공통된 부분을 베이스 클래스에서 공통적인 정의를 제공하는 것이다.상속
부모 클래스로부터 공통된 변수와 함수, 인터페이스를 물려 받는 것을 뜻한다.다형성
같은 종류의 클래스가 하나의 메시지에 대해 서로 다른 행동을 하는 것을 말한다. 다형성은 오버라이딩, 오버로딩 형태로 제공된다.
[Sort 알고리즘]
C#에서 제공하는 List<T>.Sort 메서드의 공식문서의 설명을 보면 다음과 같다.
If comparison is provided, the elements of the List<T> are sorted using the method represented by the delegate.
If comparison is null, an ArgumentNullException is thrown.
This method uses Array.Sort, which applies the introspective sort as follows:
If the partition size is less than or equal to 16 elements, it uses an insertion sort algorithm
If the number of partitions exceeds 2 log n, where n is the range of the input array, it uses a Heapsort algorithm.
Otherwise, it uses a Quicksort algorithm.
This implementation performs an unstable sort; that is, if two elements are equal, their order might not be preserved. In contrast, a stable sort preserves the order of elements that are equal.
This method is an O(n log n) operation, where n is Count.
간단하게 정리하면 퀵 정렬을 기본으로 사용하며, 크기가 작으면 삽입 정렬, 크기가 크면 힙 정렬을 사용한다는 뜻이다.
<퀵 정렬>
- 분할 정복 알고리즘
- 기준점을 만들고 그 기준을 토대로 작은 값과 큰값으로 나눈다. 이 동작을 재귀적으로 수행하며 정렬을 한다.
- 시간 복잡도 : 평균 - O(nlogn), 최악 - O(n^2)
<예시> : 퀵 정렬
void QuickSort(int[] arr, int left, int right) { if (left >= right) return; int pivot = arr[(left + right) / 2]; int index = Partition(arr, left, right, pivot); QuickSort(arr, left, index - 1); QuickSort(arr, index, right); } int Partition(int[] arr, int left, int right, int pivot) { while (left <= right) { while (arr[left] < pivot) left++; while (arr[right] > pivot) right--; if (left <= right) { (arr[left], arr[right]) = (arr[right], arr[left]); left++; right--; } } return left; }
<삽입 정렬>
- 한 칸씩 오른쪽으로 이동하면서 현재 값을 적절한 위치에 삽입
- 거의 정렬된 배열에서 가장 빠름
- 시간 복잡도 : 최선 - O(n), 최악 - O(n^2)
<예시> : 삽입 정렬
void InsertionSort(int[] arr) { for (int i = 1; i < arr.Length; i++) { int key = arr[i]; int j = i - 1; while (j >= 0 && arr[j] > key) { arr[j + 1] = arr[j]; j--; } arr[j + 1] = key; } }
<힙 정렬>
- 완전 이진 트리 구조의 힙을 사용
- 최대 힙을 구성하고, 루트를 맨 뒤로 보내며 정렬
- 시간 복잡도 : O(nlogn)
<예시> : 힙 정렬
void HeapSort(int[] arr) { int n = arr.Length; // Max Heap 구성 for (int i = n / 2 - 1; i >= 0; i--) Heapify(arr, n, i); // 힙에서 하나씩 꺼내 정렬 for (int i = n - 1; i >= 0; i--) { (arr[0], arr[i]) = (arr[i], arr[0]); // 루트랑 마지막 교체 Heapify(arr, i, 0); // 줄어든 범위에 대해 다시 힙 구성 } } void Heapify(int[] arr, int heapSize, int root) { int largest = root; int left = 2 * root + 1; int right = 2 * root + 2; if (left < heapSize && arr[left] > arr[largest]) largest = left; if (right < heapSize && arr[right] > arr[largest]) largest = right; if (largest != root) { (arr[root], arr[largest]) = (arr[largest], arr[root]); Heapify(arr, heapSize, largest); } }
