DL with Python Introduction to deep learning for computer vision (Chapter 8)
출처: https://www.youtube.com/watch?v=bHb4arAh7ms
이 영상은 딥러닝 을 통한 컴퓨터 비전의 기초부터 시작하여, 합성곱 신경망( CNN)의 구조와 원리를 심층적으로 설명합니다. 영상에서는 데이터 증대기법과 사전 학습된 모델을 활용하여 과적합을 방지하고 성능을 향상시키는 방법을 다룹니다. 또한, CNN을 통해 고차원의 패턴을 인식할 수 있는 원리를 배울 수 있으며, 전반적으로 컴퓨터 비전에서 딥러닝기술이 얼마나 중요한지를 인식하게 됩니다. 실습 예제를 통해 실질적인 결과를 얻는 과정도 보여 주어 이론의 이해를 돕습니다. 결국, 이 비디오는 딥러닝의 실용성과 가능성을 탐구하는 데에 큰 도움이 됩니다. [1]
- 📚 컴퓨터 비전과 딥러닝 개요
본 장에서는 컴퓨터 비전의 기초와 더불어 딥러닝에서 가장 중요한 모델인 합성곱 신경망(convolutional networks)에 대해 다룬다. [1-5]
컴퓨터 비전은 딥러닝의 초기 성공 사례로, 2012년 Hinton 그룹이 ImageNet 챌린지를 우승하며 연구자들의 관심을 끌었다. [1-9]
합성곱 층, 풀링, 데이터 증강(data augmentation), 그리고 사전 학습된 모델을 활용한 성능 향상방법 등에 대해 설명한다. [1-6]
- 🧠 합성곱 신경망의 학습 원리
이미지를 0과 1 사이로 정규화하기 위해 255로 나누고, 동일한 방법으로 테스트 이미지를 처리한다. [2-1]
RMS Prop, 범주형 교차 엔트로피에 따라 모델을 컴파일하고, 정확도를 측정하는 방법은 이전과 같다. [2-2]
본 모델은 5에폭 동안 64의 배치 크기로 학습할 것이다. [2-3]
이전 챕터에서 사용했던 데이터 세트와 비슷하며, 결괏값은 약 97.8%의 테스트 정확도가 생성되었으나, 이번 모델은 99.2%의 정확도를 기대할 수 있다. [2-7]
합성곱층은 주로 지역 패턴을 학습하며, 이를 통해 이미지에서 특정 곡선이나 텍스처를 인식하게 된다. [2-20]
합성곱층에서 학습한 패턴은 위치 불변성을 가지므로, 어느 위치에서 패턴을 인식하더라도 동일한 기능을 수행할 수 있다. [2-27]
합성곱층은 공간적 계층 구조를 학습하며, 기본적인 선이나 텍스처에서 시작하여 복합적인 형태로 설계된 시각적 구조를 만들어낸다. [2-31]
각 합성곱 연산은 입력 피처 맵에서 패치를 추출하고 동일한 변환을 적용하며, 이 과정을 통해 특징 맵을 생성한다. [2-41]
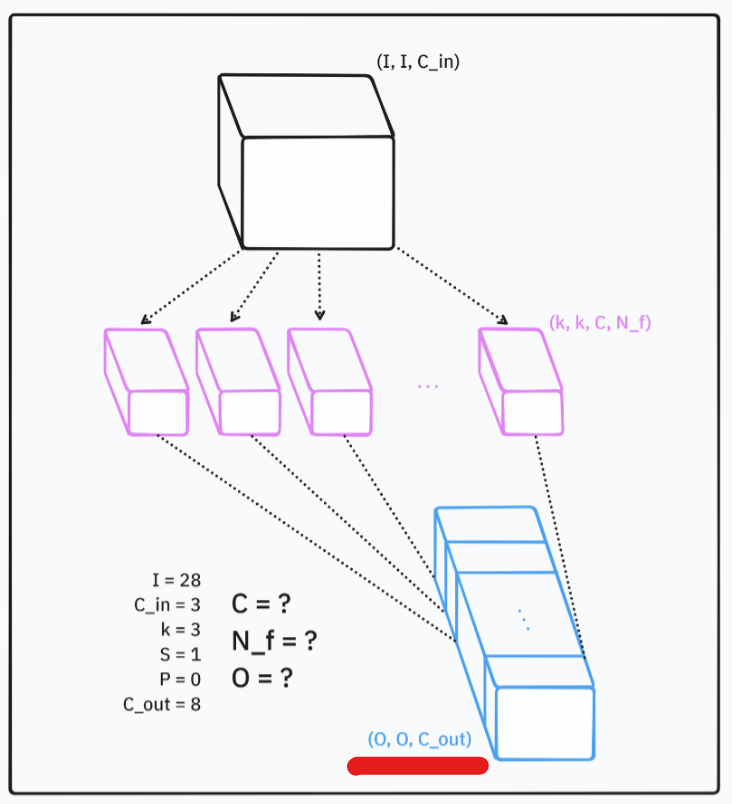
켈널 크기와 필터 개수는 합성곱층의 주요 매개변수이며, 일반적으로 3x3 크기의 필터가 사용된다. [2-59]
스트라이드와 패딩 기술을 사용하여 출력 크기를 조정하며, 이는 모델 성능에 영향을 미친다. [2-79]
2.1. 모델 성능 향상
이미지를 255로 나누어 0에서 1로 정규화한 후, 같은 방법을 테스트 이미지에도 적용한다. [2-1]
RMS Prop, categorical cross-entropy, 및 정확도를 사용하여 모델을 컴파일하며, 이에 대해 새로운 내용은 없다. [2-2]
모델 학습은 배치 크기 64로 5에포크 동안 진행된다. [2-3]
이전에 사용했던 데이터셋을 동일하게 적용하며, 밀집 층을 포함한 네트워크 구조를 기억해야 한다. [2-4]
해당 네트워크는 약 97.8의 테스트 정확도를 보였지만, 현재 더 높은 정확도를 기대할 수 있다. [2-7]
합성곱 신경망을 활용한 결과, 정확도가 97.8에서 99.2로 향상되었으며, 더 높은 성과를 기대할 수 있다. [2-10]
정확도차이는 단순히 1.4 포인트로 보일 수 있지만, 오류 감소율을 고려하면 61% 이상의 개선을 이루었다. [2-11]
2.2. ️ 합성곱 레이어의 작동 원리
합성곱 레이어는 로컬 패턴을 학습하며, 이를 위해 커널을 사용하여 입력 이미지를 스캔한다. [2-15]
커널은 입력 이미지의 작은 영역만을 보며, 곡선이나 텍스처와 같은 정보를 파악한다. [2-23]
합성곱 레이어가 학습한 패턴은 변환 불변성을 가지며, 즉 패턴의 위치가 중요하지 않다. 따라서 같은 패턴을 다른 위치에서도 인식할 수 있다. [2-27]
이는 완전 연결층에서는 제공되지 않는 특성이다. [2-29]
2.3. ️ 합성곱층의 공간 계층 구조 학습
합성곱층은 시각적 모듈의 공간 계층 구조를 학습할 수 있다. 이는 기본적인 선 또는 질감과 같은 매우 단순한 패턴에서 출발하여 점점 더 복잡한 구조를 만들 수 있다는 것을 의미한다. [2-31]
예를 들어, 기본적인 선이나 질감을 조합하여 눈, 귀, 코와 같은 단순한 객체를 만들 수 있으며, 이러한 객체를 다시 조합해 고양이의 머리와 같은 이미지로 발전시킬 수 있다. [2-34]
합성곱 연산은 3차 텐서(높이, 너비, 채널 수)에 대해 작동하며, 이러한 텐서에서 패치를 추출하고 동일한 변환을 모든 패치에 적용한다. [2-40]
각 필터는 특정 패턴을 식별하는 데 중점을 두며, 예를 들어 특정 방향의 선 또는 질감과 같은 패턴을 인식하는 역할을 한다. [2-48]
MNIST 데이터셋의 첫 번째 합성곱층은 28x28x1 이미지를 입력으로 받아 32개의 필터를 사용하여 26x26x32의 출력을 생성한다. 여기서 26이 되는 이유는 이후에 설명될 예정이다. [2-49]
2.4. ️ 컨볼루션 레이어의 핵심 매개변수
커널 크기는 입력에서 추출되는 패치의 크기를 정의하며, 일반적으로 3x3을 많이 사용하고, 5x5나 1x1이 특정한 경우에 사용될 수 있다. [2-57]
필터의 수는 커널의 수를 나타내며, 이는 해당 컨볼루션 레이어의 출력 채널 수와 일치한다. [2-62]
입력 피쳐 맵에서 3D 데이터를 슬라이드하여 패치를 추출하고, 변환을 적용한 결과는 각 패치에 대해 1D 벡터가 된다. [2-65]
예를 들어, 5x5의 입력 피쳐 맵에서 3x3의 패치를 추출하면, 최종 출력은 3x3x3의 형태가 된다. [2-67]
출력의 너비와 높이는 원래 입력 크기와 달라질 수 있으며, 이는 경계 효과와 관련 있다. [2-76]
2.5. 스트라이드와 패딩의 이해
입력 텐서에 대해 세로 및 가로로 픽셀을 건너뛰는 방식으로 출력 크기를 조정하는 것이 스트라이드이다. [2-79]
패딩을 사용하면 입력 텐서 주위에 제로를 추가하여 크기를 유지할 수 있으며, 이를 통해 입력과 출력의 크기를 동일하게 만들 수 있다. [2-88]
"valid" 패딩을 정의하면 입력 크기가 줄어들고, 기본값으로 설정되며, "same"을 정의하면 출력 크기를 입력과 동일하게 유지한다. [2-89]
입력이 5x5이고, 3x3 커널을 사용할 경우 중앙 픽셀을 찾을 수 없는 바깥쪽 픽셀 때문에 출력 크기가 줄어든다. [2-82]
각각의 경우에서 패딩과 스트라이드를 적절히 활용하여 효율적인 크기 조정이 가능하다. [2-85]
- 🧠 컨볼루션과 풀링의 중요성
Stride를 사용하면 특성 맵을 다운샘플링 할 수 있으며, 예를 들어 stride 2를 사용하면 폭과 높이가 각각 2배 줄어들게 된다. [3-5]
Max pooling은 입력의 두 가지 특성 맵 크기에서 최대값만 취하여 특성 맵을 공격적으로 다운샘플링하며, 이 과정에서 중요 정보를 유지한다. [3-8]
Max pooling을 사용하지 않을 경우 모델의 매개변수가 급증하여 모델 크기가 700,000개가 넘어가며, 이는 과적합으로 이어질 수 있다. [3-21]
Max pooling이 아닌 평균 풀링을 사용할 경우 특징의 존재 여부가 모호해져서, Max pooling이 더 효과적이다. [3-35]
리얼 데이터셋(예: 고양이와 개 이미지) 사용 시 정규화 기법으로 정확도를 70%에서 80-85%로 향상시키며, 사전 훈련된 네트워크를 활용하면 98%의 정확도를 달성할 수 있다. [3-45]
3.1. 스트라이드와 맥스 풀링의 개념
스트라이드는 피쳐 맵을 다운샘플링하는 방식으로, 예를 들어 스트라이드가 2일 경우, 너비와 높이가 각각 2배 감소한다. [3-1]
맥스 풀링 레이어는 피쳐 맵을 강하게 다운샘플링하고, 고정된 커널을 이용해 최대값을 선택한다. [3-8]
입력 텐서에서 2x2 영역마다 최대값을 유지하며, 이는 각 채널의 너비와 높이를 2배씩 감소시킨다. [3-11]
이렇게 하면 전체적으로 피쳐 맵의 볼륨이 4배로 줄어든다. [3-14]
마지막으로, 맥스 풀링의 핵심은 네 개의 값 중 최대값만을 선택하는 것이다. [3-16]
3.2. ️ 풀링과 다운샘플링의 중요성
최대 풀링(max pooling)을 사용하지 않으면 모델의 파라미터 수가 약 700,000개로 증가하며, 이는 이전 모델보다 약 7배 더 많다. [3-18]
각 합성곱 레이어는 원본 이미지의 매우 작은 영역에만 접근할 수 있어, 충분한 글로벌 특징을 추출하기 어렵다. [3-23]
깊이 있는 신경망에서는 필터가 점점 더 큰 패치에 접근해야 복잡한 패턴을 추출할 수 있지만, 7x7 픽셀의 제한된 입력으로는 이 과정이 어렵다. [3-28]
너무 많은 파라미터로 인해 과적합(overfitting)이 발생할 우려가 있으며, 이는 최대 풀링을 사용하는 이유 중 하나이다. [3-31]
최대 풀링이 평균 풀링보다 더 효과적인 이유는, 특정 특징의 존재 여부를 확인하는 데 있으며, 평균으로 인해 특징이 흐려질 수 있다. [3-35]
3.3. 개와 고양이 이미지 데이터셋을 활용한 모델 구축
이번 모델은 이전 모델과 유사하게 구축되며, 개와 고양이의 이미지로 구성된 5,000장의 데이터셋을 사용한다. 이 데이터셋은 개와 고양이가 각각 2,500장씩 포함되어 있어, 균형을 이룬다. [3-44]
5,000장 중에서 2,000장은 훈련에, 1,000장은 검증에, 나머지 2,000장은 테스트에 사용된다. 그러나 이 데이터셋은 작은 규모로, 실제 이미지에 비해 적은 양이다. [3-46]
훈련 과정에서 규제를 사용하지 않고 시작하며, 대략 70% 정확도를 목표로 하여 기준선을 설정한다. [3-50]
데이터 과적합을 피하기 위해 데이터 증강 기법을 도입하여 정확도를 80%~85%로 증가시킨다. 이는 70%에 비해 상당한 향상이다. [3-52]
사전 훈련된 네트워크를 활용하여 특징 추출 또는 미세 조정을 통해 98% 정확도를 달성하려고 한다. 이 정확도는 해당 데이터셋에서 가능한 최고 성과에 가깝다. [3-55]
3.4. 모델 구성과 데이터 전처리 과정
모델 내부에서 레스케일링 전처리를 포함하여 원본 데이터를 직접 사용할 수 있도록 하며, 이는 입력 텐서를 255로 나누는 방식이다. [3-71]
첫 번째 단계에서 32개의 필터를 사용하고, 몇 개의 합성곱 블록 후에 필터의 수를 두 배로 늘리는 일반적인 패턴을 따른다. [3-75]
각 합성곱 레이어 사이에 최대 풀링을 적용하며, 기본 풀 사이즈는 2이다. [3-76]
마지막 출력은 시그모이드 함수가 적용된 밀집층을 통해 이루어지며, 그 결과는 0에서 1 사이의 값을 갖는다. [3-77]
데이터 전처리에선 JPEG 파일을 RTP 파일로 디코딩하고, 세 가지 색상 채널을 포함하여, 이를 부동 소수점 텐서로 변환한다. [3-91]
- 🖼️ 이미지 데이터셋을 통한 딥러닝 훈련 절차
이미지를 108x180으로 리사이즈한 후 배치로 묶는다. 데이터셋은 훈련, 검증, 테스트 세 가지로 나누어 활용된다. [4-1]
이미지 데이터셋을 만들기 위해 TensorFlow를 사용하여 디렉터리에서 이미지를 읽으며, 두 개의 클래스(고양이와 개)에 대해 훈련과 검증, 테스트 데이터의 파일 수가 각각 2003, 1000, 2000임을 확인할 수 있다. [4-14]
데이터셋 객체를 사용하여 텐서플로우 훈련을 최적화하며, 비동기 데이터 미리 가져오기를 처리하는 기능이 있다. [4-16]
데이터 배치 작업 시 배치 사이즈와 랜덤 추가 작업을 정의하여, 각 샘플을 처리할 수 있는 구조를 갖춘다. [4-11]
데이터 증강 기법을 통해 동일 이미지의 반복 학습을 방지하고, 모델이 새로운 이미지를 학습할 수 있도록 다양한 변형을 적용하여 성능을 향상시킨다. 이를 통해 상당한 오버피팅 감소가 기대된다. [4-60]
4.1. ️ 이미지 데이터셋 정의 및 처리 방법
이미지 크기를 108 x 180으로 조정한 후 일괄 처리(batch processing) 한다. [4-1]
이미지를 읽기 위해 이미지 데이터셋을 디렉토리에서 사용하는 방법이 있다. [4-4]
세 가지 데이터셋(훈련, 검증, 테스트)을 정의하며, 각 데이터셋은 디렉토리 내 이미지를 기반으로 생성된다. [4-7]
이미지 크기를 180 x 180으로 변경할 수 있으며, 일괄 처리(batch size)도 설정할 수 있다. [4-10]
데이터셋 내의 클래스는 고양이와 개의 두 가지이며, 훈련 데이터는 2,003, 검증 데이터는 1,000, 테스트 데이터는 2,000개로 구성된다. [4-14]
4.2. ️ TensorFlow 데이터셋 활용 개요
TensorFlow Dataset는 Keras로 훈련할 때 매우 유용한 도구이며, 빠른 속도로 데이터 처리를 지원한다. [4-17]
이 데이터셋은 비동기 데이터 미리 가져오기를 처리할 수 있어 데이터 병렬화 최적화에 기여한다. [4-18]
NumPy 배열로부터 데이터셋을 생성할 수 있으며, dataset.from_tensor_slices를 이용해 텐서 객체로 변환한다. [4-23]
각 요소의 형태(shape)를 출력하면 개별 샘플당 하나의 데이터 구조를 생성하며, 배치(batch) 처리를 위해 배치 크기를 정의해야 한다. [4-27]
dot map 메소드를 이용하면 각 샘플에 특정 변형을 적용할 수 있으며, 이는 TensorFlow연산만 사용해야 한다. [4-34]
4.3. ️ 모델 성능 평가 및 오버피팅 문제
모델을 적합(fit)시키기 위해 데이터셋을 사용하였으나, 실행 시간이 소요되어 이미 실행해놓고 결과를 저장해놓았다. [4-44]
학습 정확도는 거의 1에 가깝고, 손실은 0에 가깝지만, 검증 데이터에서는 이와 달리 성능이 저조하여 오버피팅 현상이 발생한다. [4-48]
모델의 성능은 약 69.7%로 추정되며, 이는 약 70%에 가깝다. [4-53]
따라서, 현재 모델에서 나타나는 주된 문제는 오버피팅이다. [4-55]
4.4. 데이터 증강을 통한 성능 향상
데이터 증강은 오버피팅을 방지하기 위한 방법 중 하나로, 모델이 같은 이미지를 반복해서 학습하지 않도록 한다. [4-56]
다양한 방법으로 이미지의 픽셀 값을 변경하면서도 같은 라벨을 유지하는 것이 목표이다. [4-62]
이미지에 대해 무작위 변환(예: 뒤집기, 회전, 크기 조정 등)을 적용하여 새로운 이미지를 생성하는 방법을 설명한다. [4-66]
데이터 증강을 적용한 새로운 모델을 정의하는 과정에서 드롭아웃 층을 추가하여 오버피팅을 줄였다. [4-82]
데이터 증강을 통해 성능이 70%에서 82%로 증가하는 효과를 보여주며, 10% 이상의 향상은 매우 긍정적이다. [4-102]
4.5. 사전 훈련된 모델의 활용 이유
사전 훈련된 모델을 사용하는 이유는, 여러 가지 데이터 유형에 적용할 수 있기 때문이다. [4-111]
작은 데이터셋을 가질 경우, 비슷한 작업에서 이미 훈련된 다른 모델을 사용하는 것이 일반적이다. [4-115]
그러나 선택한 모델은 더 큰 데이터셋에서 유사해야 하며, 이는 효율적인 학습을 위한 중요한 요소다. [4-116]
본 예제에서는 ImageNet에서 사전 훈련된 모델을 사용할 것이며, ImageNet은 인기 있는 데이터셋 중 하나로 알려져 있다. [4-117]
- 🖼️ 딥러닝을 위한 특징 추출 및 미세 조정
1.4백만 개의 이미지와 1,000개 이상의 클래스를 사용하여 해당 클래스에는 개, 고양이 및 일상적인 사물이 포함된다. [5-1]
특징 추출의 아이디어는 원래 모델에서 분류기를 제거하고 새로운 분류기를 추가하는 것이며, 이 새로운 분류기는 임의로 초기화된다. [5-4]
VGG16 모델을 사용하여 Convolutional Layers와 Max PoolingLayers를 쌓아 구조를 구성하고, 최종 출력 크기는 5x5x512가 된다. [5-11]
특징 추출을 위한 두 가지 접근 방식이 있으며, 첫 번째는 데이터를 한 번 실행하여 결과를 배열로 저장한 후 분류기를 훈련하는 방법이다. [5-25]
데이터 증강을 통해 과적합을 방지하는 방법으로, 처음 두 개의 레이어를 고정하고 나중에 여러 레이어를 유동적으로 훈련할 수 있다는 점이 강조된다. [5-61]
5.1. 특성 추출 및 미세 조정의 이해
1.4백만 개의 이미지와 1,000개 이상의 클래스가 존재하며, 이 클래스에는 다양한 종류의 개와 고양이, 그리고 일상적인 물체들이 포함된다. [5-1]
특성 추출에서는 기존의 훈련된 합성곱 기반 모델과 분류기를 사용하여 새로운 분류기로 교체하는 방식으로 진행된다. [5-5]
VGG16 모델을 이용하며, 이는 현재 다양한 더 나은 모델들이 있지만 구조가 유사해서 선택되었고, 합성곱 층과 최대 풀링 층으로 구성된다는 점이 강조된다. [5-10]
모델에 ImageNet에서 가져온 사전 훈련 가중치를 사용할 것이며, 최상단의 3개 클래스를 제거할 계획이다. [5-15]
최종적으로 5x5x512로 축소된 출력을 평탄화하고 추가적인 처리를 할 예정이다. [5-21]
5.2. 딥러닝 모델의 성능 향상 방법
데이터 미리 가져오기를 통해 컴퓨터 비전의 특징을 고속으로 추출하고, 이를 바탕으로 클래시파이어를 훈련하는 방식이 가장 빠르다. [5-25]
데이터 증강을 적용하면 각 에포크마다 다양한 요구를 지원할 수 있으며, 이를 통해 과적합(overfitting)을 방지할 수 있다. [5-27]
모델의 출력 크기는 2000개의 훈련 특징으로 나타나며, 이는 5x5x512의 형태로 되어 있다. [5-45]
훈련 후 모델의 정확도는 97% 이상이며, 과적합이 존재하지만 여전히 좋은 성능을 보인다. [5-53]
가중치 동결을 통해 비훈련 가능한 레이어를 설정하고, 데이터 증강과 함께 모델을 구축하면 과적합이 크게 줄어드는 성과를 얻을 수 있다. [5-61]
5.3. 사전 훈련된 모델을 이용한 특성 추출 및 미세 조정 방법
사전 훈련된 모델을 사용할 때는 모델 자체를 훈련하지 않고 분류기만 훈련하는 방법이 있다. [5-80]
전체 또는 일부를 훈련시키는 다른 방법으로는 합성곱 모델을 훈련시키는 것이 있으며, 이 과정에서 사용자 네트워크를 기존의 훈련된 네트워크 위에 추가한다. [5-82]
기본 네트워크는 고정 상태로 두고 분류기 부분만 훈련한 후, 일부 계층을 해제하여 두 계층과 분류기를 동시에 훈련한다. [5-86]
모델을 미세 조정할 때는 배치 정규화 계층을 포함하여 특정 계층을 훈련 가능 상태로 만들지 않아야 한다. [5-92]
최종적으로, 모델을 재작성하여 더 낮은 학습률을 적용하며, 이전에 훈련한 모델에서 97.8%의 정확도를 기록하고, 최고의 결과를 얻을 수 있다. [5-100]
5.4. ️ 컴퓨터 비전과 딥러닝 개요
컴퓨터 비전과 딥러닝에 대한 소개가 진행되었으며, 다양한 분류 문제를 다루었다. [5-108]
합성곱 신경망(convolutional neural networks)은 컴퓨터 비전작업을 위해 현재 가장 우수한 기계 학습 모델이다. [5-110]
데이터 세트가 작더라도 처음부터 모델을 훈련시켜 상당히 괜찮은 결과를 얻을 수 있다. [5-112]
합성곱 층은 시각적 세계를 표현하기 위해 모듈형 패턴과 개념의 위계적 구조를 학습한다. [5-113]
데이터 증강을 통해 과적합(overfitting)을 완화할 수 있으며, 두 가지 간단한 방법으로 사전 훈련된 모델을 활용할 수 있다. [5-115]
