요즘 코드에 대해 어떻게 비용을 줄일까에 대한 생각을 해보고 있습니다.
물론 각자의 컬렉션에 장단점이 있기 때문에, 자세히 알아보지 않으면 오히려 리펙토링 한 것들이 비용이 더 많이 나오는 경우가 있습니다.
또한 모든것이 트레이드 오프이기 때문에 잘 이해 하시고 사용하셨으면 좋겠습니다.
contains()
우리가 자주 사용하는 contains()에서 많은 비용이 발생하는 사실 알고 있었나요?
아래의 코드는 북마크를 확인하는 코드입니다.
override fun toggleBookmark(document: Document) {
val documents = searchSharedPreference.getDocuments()
// 기존 보관함 목록 포함여부 확인 후 추가 / 삭제 분기처리
if (documents.contains(document)) {
searchSharedPreference.removeDocument(document)
} else {
searchSharedPreference.addDocument(document)
}
} 해당 북마크를 검사할때, 해당 북마크가 List 타입이라면, 최악의 경우 비용은 O(N)입니다.
하지만 우린 검색에 더 좋은 컬렉션을 알고 있습니다.
HashMap과 Set입니다.
이중에, 중복값이 없다면 Set을 이용하는 편이 좋습니다.
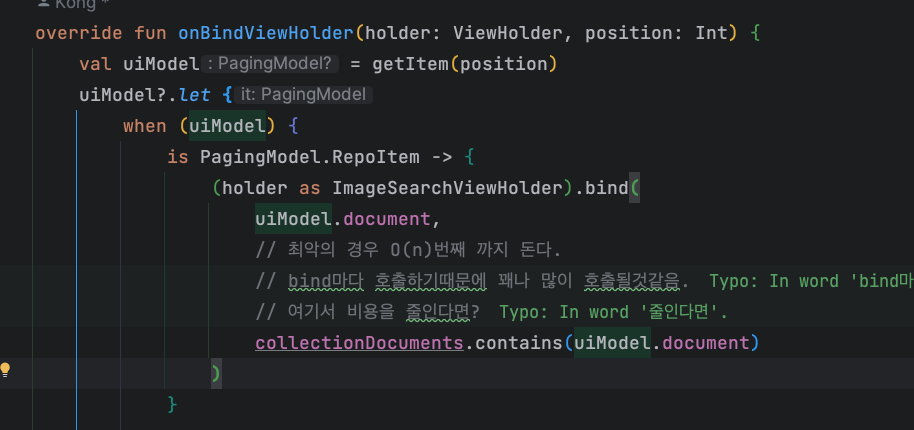
위의 코드는 List의 Adapter를 구현한 코드입니다.
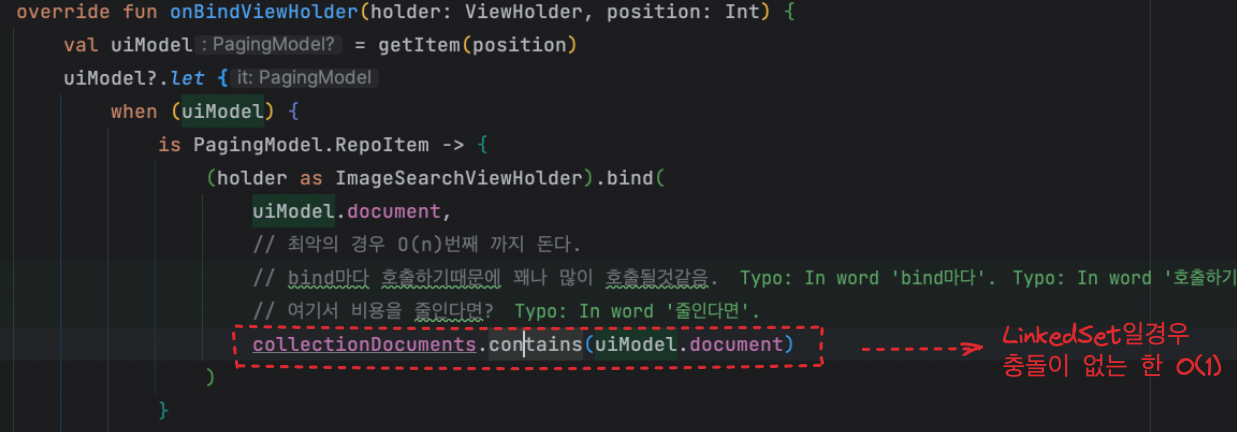
collectionDocuments가 List라면, contains()는 최대 O(N)까지 걸릴것입니다.
onBindViewHolder는 스크롤할때마다 호출될것이고, collectionDocuments가 좀만 많아진다면 호출하는 비용이 만만치 않을것 같습니다.
이를 한번 수정해봅시다.
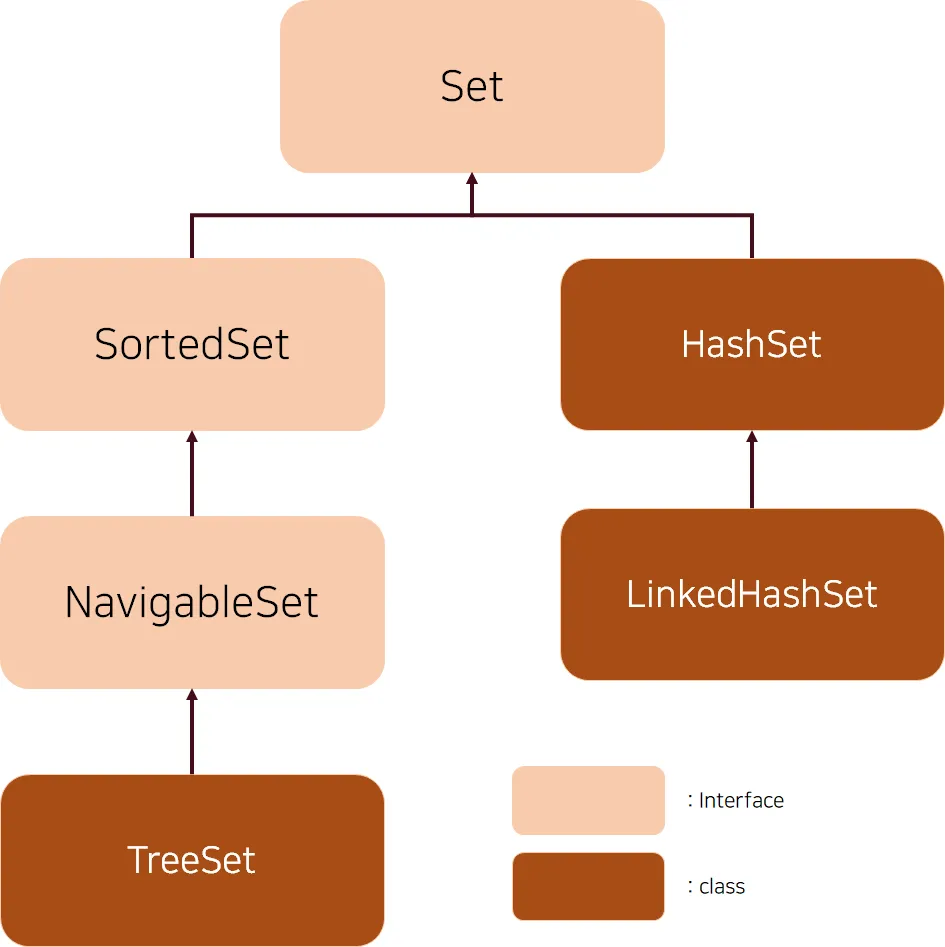
Set에는 TreeSet, HashSet, LinkedHashSet이 존재합니다.
TreeSet은 HashSet이나 LinkedHashSet보다 전반적으로 더 느린 속도를 보이지만, NavigableSet과 SortedSet의 함수들을 사용하여 정렬된 상태에서 장점을 살리면 더 구체화된 목적에 사용가능합니다.
하지만 저희는 정렬이 아닌 순서가 지켜져야 하기 때문에 LinkedHashSet을 사용하도록 합니다.
중요한것은 중복이 없기 때문에 Set이 사용가능합니다.

저도 개발자인데 같이 교류 많이 해봐요 ㅎㅎ! 서로 화이팅합시다!