앞서 가상 메모리에 관해서 공부를 했다.
그런데, 이 가상메모리에 대해서 정말 많은 개념들이 등장을 했는데 이 중 “ 메모리간 페이지 공유 “ 라는 부분에서 페이지는 Demand Paging이라는 방법을 통해서 어떤 페이지가 Pysical Memory에 적재되고, Virtual Memory에 적재되는지 알게 되었다.
그런데, Valid와 Invalid를 통해 페이지의 존재 여부를 알 수 있고, Page Fault Trap 이 발생한다고 했다.
이 Page Fault 발생 시 Swap Area에서 페이지를 가져와 Pysical Memory에 적재를 한다고 했다. 그런데 어떻게 Swap Area에서 찾아서 Pysical Memory에 적재가 될까?
이것을 결정하는 방법이 페이지 교체 알고리즘이다.
이 페이지 교체 알고리즘은 여러개가 있지만, 이 중 FIFO, 최적, LRU, LFU, MFU에 대해서 알아보자.
FIFO 페이지 교체
First In First Out이다. 그렇다 말 그대로 먼저 들어온 페이지를 먼저 교체해주는 알고리즘이다.
큐에 저장하여 빼주는 가장 쉬운 방법이긴 하지만, 실제로 먼저 들어온것이 먼저 나가지 않는 현상이 발생할 수 있다.
최적 페이지 교체(Optimal Page Replacement)
가장 이상적인 알고리즘이지만, 프로세스가 앞으로 사용해야 할 페이지를 미리 알아야한다는 점은 불가능하기 때문에 문제가 있다.
이 알고리즘은 다른 알고리즘과 비교 연구 목적을 위해 사용되는 알고리즘이다.
LRU 페이지 교체 (LRU Page Replacement)
LRU(Least Recently Used) 알고리즘은 오랫동안 사용하지 않은 페이지를 교체하는 알고리즘이다.
가장 오랫동안 사용하지 않은 페이지라면, 앞으로도 사용하지 않을 가능성이 높다는 가정으로 시작하는 알고리즘 이다. 반대로 생각하면 최근에 사용한 페이지의 경우는 계속 사용할 가능성이 높으므로 교체를 하지 않는다.
사용된 시간을 알 수 있는 부분을 저장하여 가장 오랫동안 사용되지 않은 데이터는 제거를 하는데, 이 때 페이지마다 카운터가 필요하다.
또, 이는 큐(Queue)를 이용하여 구현을 할 수 있다. 사용한 데이터는 큐에서 제거하여 맨 위로 다시 올린다. 만약, 프레임이 모자랄 경우, 맨 아래에 있는 데이터를 삭제한다.
하지만, 이 알고리즘도 단점은 존재한다.
프로세스가 주 기억장치에 접근할때마다 참조된 페이지 시간을 기록해야 하므로, 막대한 오버헤드가 발생하거나 큐, 스택과 같은 별도의 하드웨어가 필요하다.
LFU 페이지 교체 (LFU Page Replacement)
LFU(Least Frequently Used)는 참조 횟수가 가장 낮은 페이지를 교체하는것이다.
LRU는 직전에 참조된 “시점"을 반영하지만, LFU는 참조된 “횟수"를 반영한다.이로 인해서 장기적 시간 규모에서의 참조 성향을 고려할 수 있지만, 가장 최근에 참조한 데이터가 참조 횟수가 다른 데이터보다 낮다는 이유로 교체가 될 수 있으며, 구현이 더 복잡하고 LRU와 마찬가지로 오버헤드가 상당하다.
MFU 페이지 교체 (MFU Page Replacement)
MFU(Most Frequently Used)는 참조 회수가 가장 높은 페이지를 교체 하는것이다.
LFU는 낮은것을 교체하였지만, 이는 높은것을 교체한다는 차이점이 있다.
여기까지 조사를 해 보았는데 딱히 실제로 사용할것같은 알고리즘은 없다고 생각을 했다.
아니, 사용을 할 순 있겠지만 방대한 오버헤드와 다양한 문제를 가지고있는 알고리즘이 있어 실제로 사용이 되거나 가장 효율이 좋은 알고리즘을 찾아보았다.
NUR = NRU ( Not Used Recnetly, Not Recently Used)
클럭 알고리즘이라는 NUR은 LRU와 근사한 최근에 사용하지 않은 페이지 교체라는 알고리즘을 사용한다.
하지만, 최근하지 사용하지 않은 페이지라고 100% 장담하기는 어렵다.
“어? LRU 는 Pysical Memory에 적재 될 때 페이지마다 참조된 시간을 기록해야해서 오버헤드가 많이 발생한다고 하지 않았나요?”
맞다, 하지만 이는 근사한 개념이라고 했지, 완전 같은 개념이라고 하지 않았다. 되려 더 낮은 오버헤드와 더 높은 성능을 보여준다.
아니, 그럼 어떤 방법을 이용하길래 오버헤드가 낮고 좋은 효율을 뽑아낸다는 것일까?
바로, “참조 비트" 와 “변형 비트" 이 두 가지를 이용하여 나타낸다.
- 참조 비트 : 페이지가 호출되지 않았을 때 0, 변경되었을때 1
- 변형 비트 : 페이지 내용이 변경되지 않았을 때 0, 변경되었을 때 1
`
이를 어떻게 이용한다는것일까?
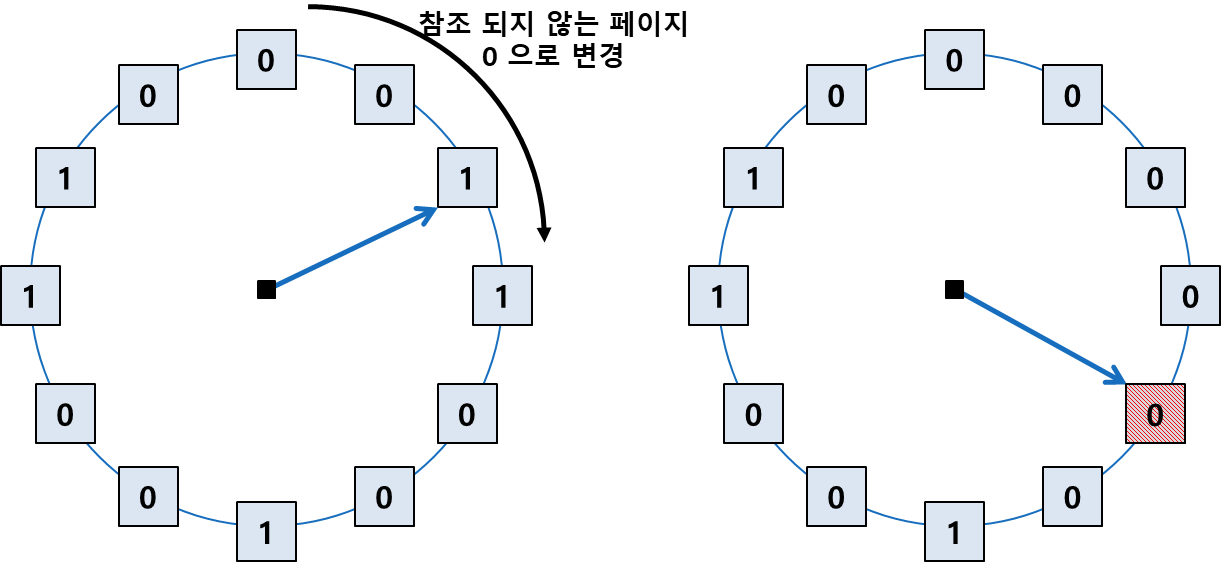
이 NUR 알고리즘은 참조 비트를 순차적으로 조사하여 동작을 한다.
- 프레임 내의 페이지가 참조될 때 하드웨어에 의해 1로 자동 세팅을 해 준다.
- 클럭 알고리즘은 한 바퀴를 돌며 참조되지 않은 페이지의 참조 비트 값을 0으로 바꾼 후 지나간다.
- 참조 비트가 0인 페이지를 방문하면 해당 페이지를 교체한다.
솔직히 이 3단계가 잘 이해가 되지 않는다.
즉, 처음에 페이지가 참조되면 1이 되고, 한 바퀴를 도는 동안 사용되지 않았으면 0이 된다.
다음에 한 바퀴를 더 돌았는데 그 때도 참조가 되지 않았다면 이는 교체 대상 페이지로 선정을 하는 알고리즘이다.
이 NUR 클럭 알고리즘은 시계 바늘이 한 바퀴 도는 동안 걸리는 시간만큼 페이지를 메모리에 유지시켜 페이지의 부재율을 줄이도록 설계가 되어있는데, 이 때문에 클럭 알고리즘을 2차 기회 알고리즘이라고 부르기도 한다.
