
Introduction
Anomaly Detection(이상치 탐지)란?
Anomaly Detection(이상치 탐지)란, 데이터 안에서 anomaly, outlier, abnormal과 같이 예상하지 못한 패턴을 찾는 일련의 활동을 말합니다.
이번 포스트는 Anomaly Detection에 대한 첫 시작이기 때문에, 자세한 내용보다는 다음의 구성에 대한 개요 정도만 소개하려합니다.
- Anomaly Detection 적용 분야
- Anomaly Detection 종류
- Anomaly Detection 방법론
Anomaly Detection 적용 분야
- Fraud Detection System (이상 거래 탐지)
: 신용, 카드, 보험과 같은 금융계에서 불법 및 악용 사례를 탐지 - Intrusion Detection System (침입 탐지 시스템)
: 컴퓨터 또는 네트워크 시스템에 대한 원치 않는 조작을 탐지 - Predictive Maintenance (설비 예지 보전)
: 설비가 고장나기 전, 이상 신호를 탐지 - Customer Churn (고객 이탈)
: 제품 또는 서비스에서 구매와 사용을 중지하는 고객을 분석하는 분야
위의 사례들을 보면, 이벤트 사건이 정상 데이터에 비해 적은 것을 보실 수 있습니다. (Ex. 카드 거래 내역 중 대부분의 고객은 정상 거래를 하기 때문에, 이상 거래 내역이 매우 적음)
여기서, Anomaly Detection의 목적을 엿볼 수 있는데, 매우 많은 정상 데이터에서 극소수의 비정상 데이터를 구별하는 것이라 할 수 있습니다.
Anomaly Detection 종류
Anomaly Detection은 학습데이터에 따라 다음과 같이 3개로 볼 수 있습니다.
- Supervised Anomaly Detection
- Semi-supervised Anomaly Detection
- Unsupervised Anomaly Detection
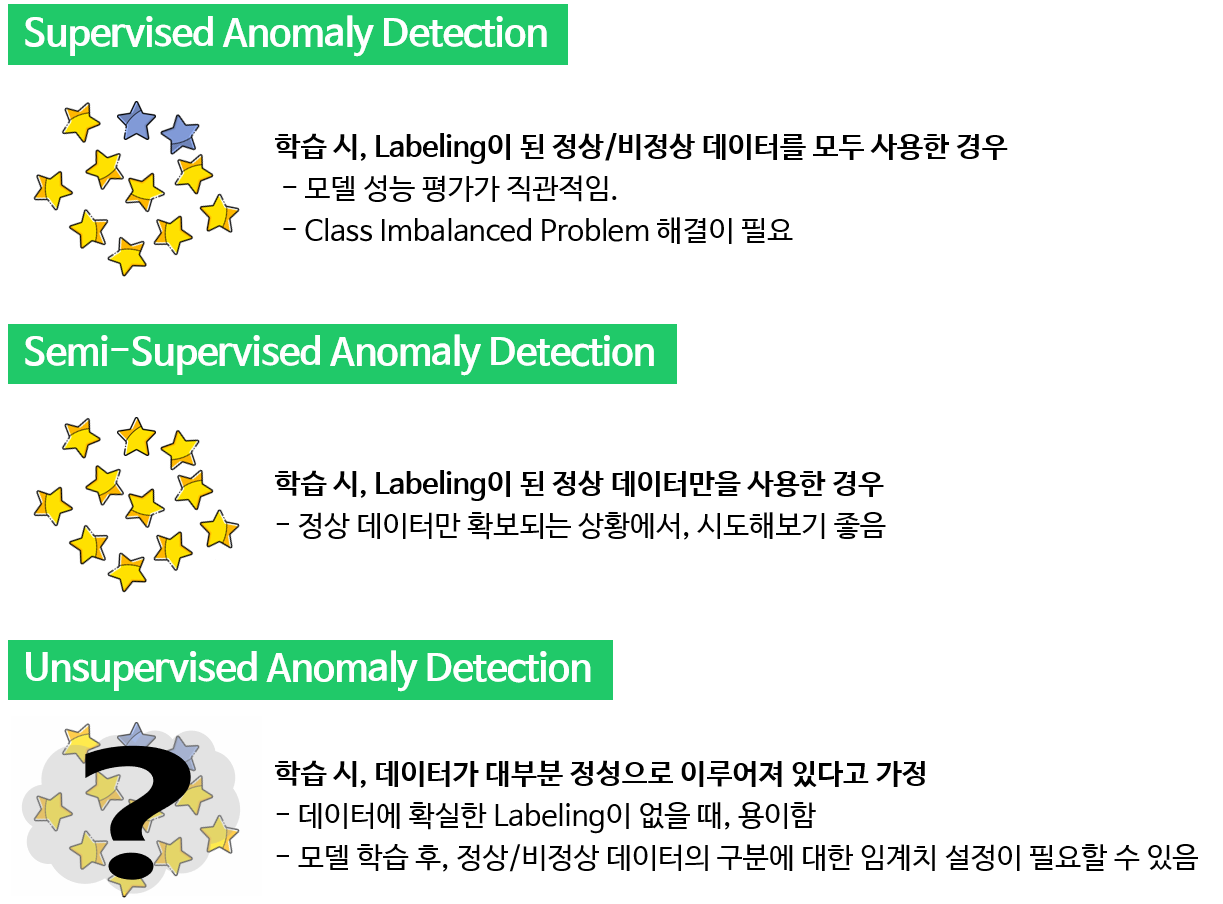
1. Supervised Anomaly Detection
학습 데이터에 비정상 데이터와 정상 데이터의 Label이 모두 존재했을 때의 경우를 말합니다. Classification의 관점으로도 볼 수 있는데, 이 경우 비정상 데이터가 매우 적기 때문에 Class Imbalanced Problem(데이터 불균형 문제)의 가능성이 있습니다.
Supervised Learning의 장점인 모델 성능 평가가 가능하다는 점에서 직관적일 수 있지만, 척도 선정에 주의해야합니다. 예를 들어 데이터의 99%가 정상일 때, 모든 데이터를 정상이라고 예측하게 되면 정확도가 99%이기 때문에 마치 성능이 좋은 것 같아 보이지만, 비정상 데이터를 모두 정상이라고 예측했기 때문에 Recall과 Sensitivity관점에서는 좋은 성능이 아닙니다.
2. Semi-supervised Anomaly Detection
Semi-supervised Anomaly Detection은 정상 데이터만을 가지고 학습한 경우를 말합니다. 현재 갖고 있는 데이터가 모두 정상 데이터이지만, 미래의 이상 징후를 탐지하고 싶은 경우에 적절합니다.
정상 데이터의 특징만을 학습해서 비정상 데이터가 테스트로 입력되었을 때, 정상 특징과 부합하지 않아 이상 징후를 탐지하는 컨셉입니다.
3. Unsupervised Anomaly Detection
학습 데이터에 정상, 비정상 데이터의 Labeling이 안 된 경우를 말합니다. 즉, 데이터에 대한 가정이 없을 경우로서 모든 데이터를 활용하여 학습을 하긴 하지만, 모델링 후 정상/비정상에 대한 구분이 필요할 수 있습니다. 적합이 잘 된다면 정상/비정상 데이터의 모델링 후 분포가 이질적으로 나타날 수 있습니다.
Anomaly Detection 방법론
정확한 기준으로는 나눌 순 없지만, 제 나름대로 아래와 같이 분류해보았습니다.
이번 포스팅에서는 간략한 설명만 하고, 이후 포스팅에서는 각각 자세한 내용과 논문을 통해 소개하도록 하겠습니다.
- Model-based Methods
- Density/Distance-based Methods
- Reconstruction-based Methods
1. Model-based Methods
- Isolation Forest : Tree based method로서 데이터를 분할 및 고립시켜 이상치를 탐지
- 1-class SVM : 데이터가 존재하는 영역을 정의하여, 영역 밖의 데이터들은 이상치로 간주
2. Density/Distance-based Methods
- Gaussian Mixture Model
- k-Nearest Neighbours (kNN) method
- LOF(Local Outlier Factors)
: 데이터의 밀도 또는 거리 척도를 통해, majority 군집과 minority 군집을 생성하여 이상치를 탐지
3. Reconstruction-based Methods
- PCA(Principal Component Analysis) Method
- Auto-Encoder based Method
: 고차원 데이터에서 주로 사용하는 방법론으로서 데이터를 압축/복원하여 복원된 정도로 이상치를 판단
위의 방법론 외에도 Deep Learning을 기반으로 한 Anomaly Detection 연구가 활발히 진행되고 있으며, 적은 비정상 데이터를 증강시킬 수 있는 방향으로도 학계에서는 많은 관심을 기울이고 있습니다.
Refernece
- 이호성님 블로그(수아랩)
- 김기현님 블로그(마키나락스)
- 김동화님 블로그(DSBA 연구실)
- Chandola, V., Banerjee, A., & Kumar, V. (2009). Anomaly detection: A survey. ACM computing surveys (CSUR), 41(3), 1-58.
- Chalapathy, R., & Chawla, S. (2019). Deep learning for anomaly detection: A survey. arXiv preprint arXiv:1901.03407.
- Xu, X., Liu, H., & Yao, M. (2019). Recent progress of anomaly detection. Complexity, 2019.
