
Introduction
이번 포스팅에서는 Anomaly Detection의 두번째 방법론 소개로 Density-based Methods의 LOF(Local Outlier Factor)에 대해 살펴보도록 하겠습니다.
Breunig, M. M., Kriegel, H. P., Ng, R. T., & Sander, J. (2000, May). LOF: identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD international conference on Management of data (pp. 93-104). 논문과 고려대학교 강필성 교수님의 자료를 참고했습니다.
Motivation
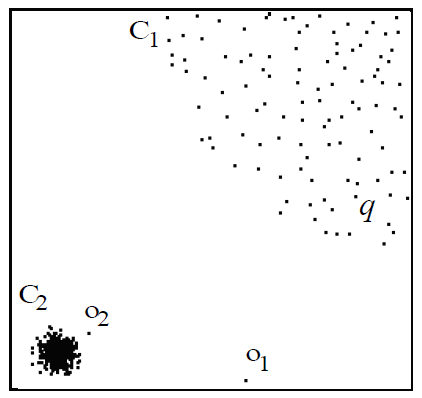
대부분의 이상치 탐지 알고리즘은 전체 데이터와 비교하여 각각의 관측치가 이상치인지 아닌지 판단하곤 합니다. 이러한 알고리즘은 위의 그림에서 에 대해 이상치라고 판단하지 않습니다.
- - 밀도가 낮은 그룹, - 밀도가 높은 그룹
- - 이상치
와 사이의 거리는 그룹내 관측치간의 거리와 유사하기 때문에, 전체적인 데이터 관점에서 보면 는 이상치로 보기 어렵습니다.
이러한 단점을 극복하기 위해, LOF는 국소적인(local) 정보를 이용하여 이상치 정도를 나타내는 것을 목적으로 합니다.
LOF(Local Outlier Factor)란?
1. 개념
LOF는 각각의 관측치가 데이터 안에서 얼마나 벗어나 있는가에 대한 정도(이상치 정도)를 나타냅니다. LOF의 가장 중요한 특징은 모든 데이터를 전체적으로 고려하는 것이 아니라, 해당 관측치의 주변 데이터(neighbor)를 이용하여 국소적(local) 관점으로 이상치 정도를 파악하는 것입니다. 또한, 주변 데이터를 몇개까지 고려할 것인가를 나타내는 라는 하이퍼-파라미터(hyper-parameter)만 결정하면 되는 장점이 있습니다.
2. Notion
알고리즘에서 사용되는 Notion 및 수식에 대해 알아보겠습니다.
2_1. the distance between objects p and q
: 관측치 p와 q의 거리
2_2. -distance of an object p
- : 관측치 p와 가장 가까운 데이터 k개에 대한 거리의 평균
2_3. -distance neighborhood of an object p
: 관측치 p의 -보다 가까운 이웃의 집합
(= -를 계산할 때 포함된 이웃의 집합)
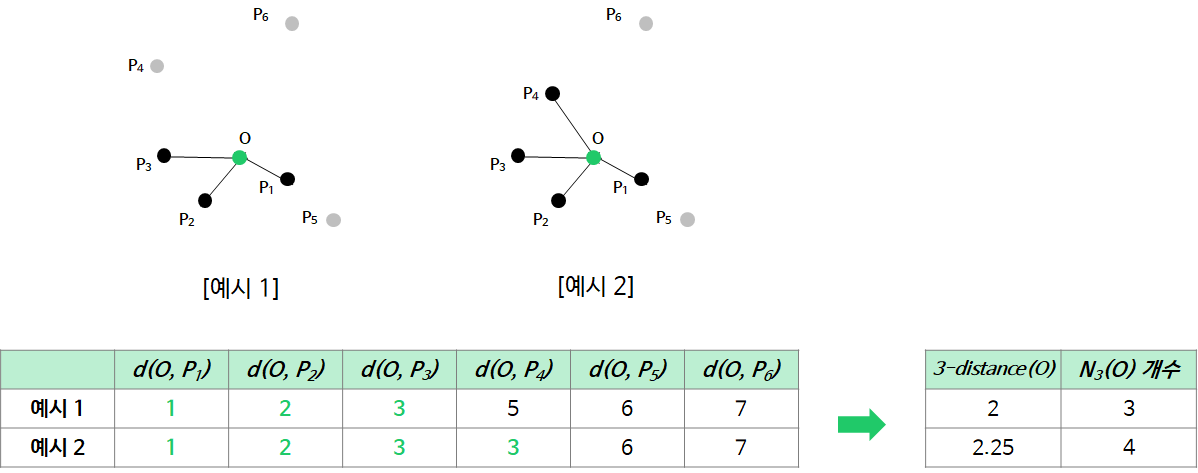
개를 선택하니깐, 의 개수는 아닌가요?
정답부터 말씀드리면, No 입니다.
위의 [예시2]와 같이 동일한 distance를 갖는 이웃이 있는 경우, 의 개수는 보다 클 수 있습니다.
2_4. reachability distance of an object p w.r.t. object o
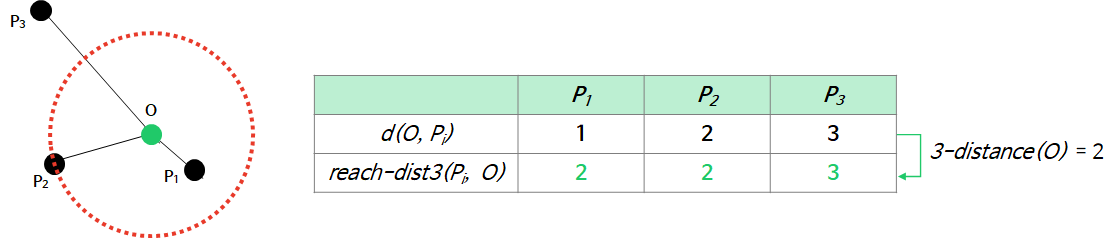
위의 그림으로 보면 직관적일 수 있습니다.
- 관측치 p가 o에서 멀다면 : 관측치 p와 o의 실제 거리
- 관측치 p가 o에서 가깝다면 : 관측치 o의 -distance
2_5. local reachability density(lrd) of an object p
수식을 해석하자면, 관측치 p에 대한 k-이웃의 평균의 역수입니다. 즉, 관측치 p주변에 이웃이 얼마나 밀도있게 있는가를 대변할 수 있습니다. k=3 일때의 예시를 통해 쉽게 접근해보도록 하겠습니다.
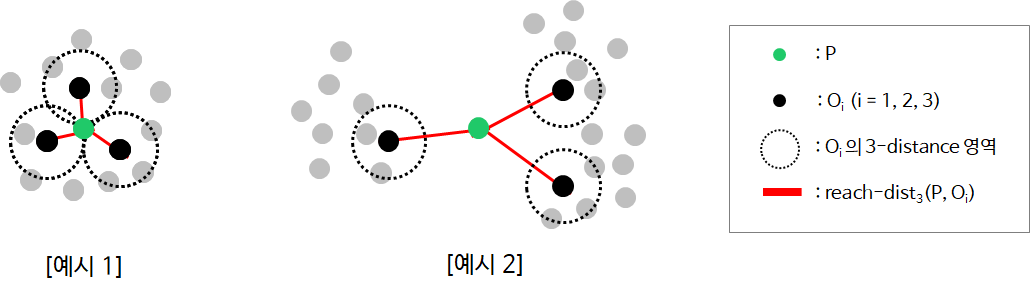
-
[예시1] : 관측치 p의 3-이웃이 가깝게 있고, 이웃 의 도 작기 때문에 는 큰 값이 산출
-
[예시2] : 관측치 p의 3-이웃이 멀게 있고, 이웃 의 이 크기 때문에 는 작은 값이 산출
2_6. local outlier factor(LOF) of an object p
최종적으로, 관측치 p의 이상치 정도를 나타내는 LOF는 위와 같이 정의되며, 관측치 p의 밀도()와 이웃 o의 밀도()의 비율을 평균한 것 입니다. 조금 더 쉽게 보면, 가 작을수록, 가 클수록 LOF는 커지며, 이상치라는 것입니다.
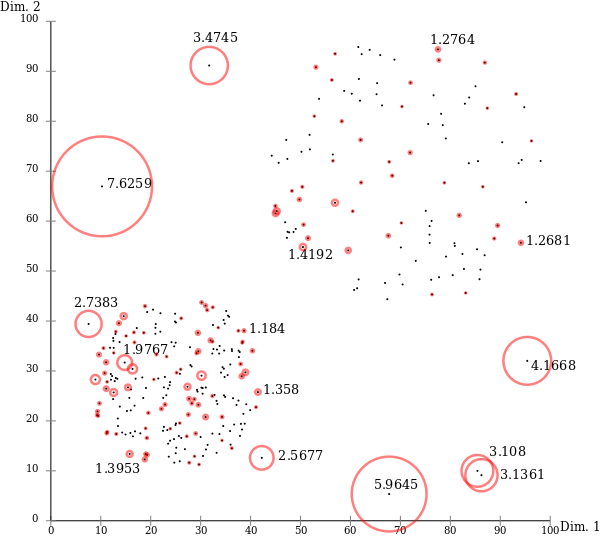
- LOF < 1 : 밀도가 높은 분포
- LOF ≒ 1 : 이웃 관측치와 비슷한 분포
- LOF > 1 : 밀도가 낮은 분포, 크면 클수록 이상치 정도가 큼.
Summing Up
- LOF(Local Outlier Factor)는 국소적(local) 정보를 활용하여, 이상치 정도를 나타내는 척도임.
- 주변 데이터를 몇 개까지 볼 것인지()에 대한 hyper-parameter 선정 필요
- LOF 값이 크면 클수록, 이상치 정도가 큼
Refernece

2개의 댓글

k-distance of an object p
k-distance(p) : 관측치 p와 가장 가까운 데이터 k개에 대한 거리의 평균
여기 부분 평균이 아니라 그냥 o,p에 대한 거리가 아닌가요?
즉 3-distance이라고 한다면 오름차순으로 3번째에 있는 거리를 말하는것으로 이해하고 있어서요,,,,
참고 할만한 Python 코드가 있을까여?