
개요
필자는 스프링 스케줄러를 통해 알림 보내기 기능을 구현했었는데
@Scheduled(cron = "0 0 0 * * *")
@Transactional
public void sendDailyQuestionNotification() {
List<User> users = userRepository.findAll();
for (User user : users) {
Notification notification = Notification.builder()
.user(user)
.content("오늘의 질문이 도착했습니다 !")
.build();
notificationRepository.save(notification);
}
}위 코드와 같이
모든 유저 정보를 repository에서 findAll()을 사용해 가져와
알림을 보내는 방식이었다
하지만 매일 같은 시간에 데이터가 많이 저장되어있을
유저 테이블을 findAll()을 통해 가져오는것은
얼핏 보기에도 성능상에 문제가 있어보였다
해당 코드를 스프링 배치를 사용해 리팩토링 해보자
Spring Batch
우선 Spring Batch에 대해 알아보기 전에
배치 처리가 무엇인지 생각해볼 필요가 있다
batch란?
여러 작업을 한꺼번에 모아서 자동으로 처리하는 방식
특정 작업을 사람이 직접 처리하는것이 아닌
정해진 시간에, 혹은 주기적으로
대량의 데이터를 묶어서 자동으로 처리하는 것을 배치 처리라고 한다
스프링에서의 배치시스템을 보며 이해해보자
공식문서에서 spring batch란
사용자와의 상호작용 없이 매우 큰 데이터셋을 반복적으로 처리하며 복잡한 비즈니스 규칙을 주기적으로 적용하는 작업
이라고 나와있다
기억할 점이 있다면 Spring Batch는
스케줄링 프레임워크가 아니다
스프링 배치를 알아보기 위해 공식문서를 하나씩 열어보자
Spring Batch Architecture
스프링 배치는 세 가지 구성 요소를 가지고 있는데
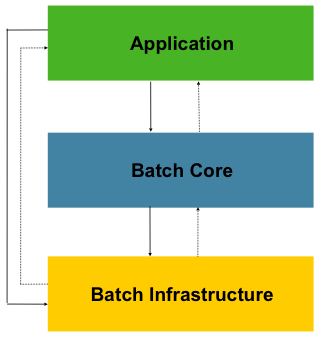
배치 작업과 사용자 정의 코드가 포함된 Application,
작업을 시작하고 제어하는 런타임 클래스들이 포함된 Core,
공통 입출력 및 서비스가 포함된 Infrastructure 이다
배치 솔루션을 구축하기 위해선 여러가지 고려사항이 있는데
양이 생각보다 많아 나중에 읽어보는 것을 추천한다
다음 그림은 배치 아키텍처의 단순화된 버전이다
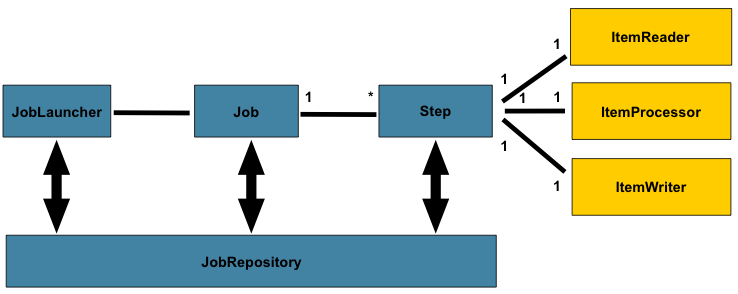
Job은 Job Launcher를 통해 실행되어야하고
실행중인 데이터는 JobRepository에 저장되어야한다
하나의 Job은 여러 Step을 가질 수 있고,
각 Step은 정확히 하나의 ItemReader, ItemProcessor, ItemWriter를 가진다
Job
Job은 전체 배치 프로세스를 캡슐화한 엔티티이다
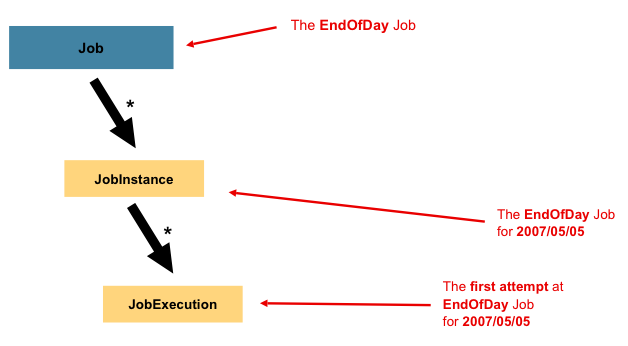
Job은 전체 구조의 가장 상위 계층으로
위 그림은 계층구조의 일부이다
자바에서 job을 설정하기 위해 여러 builder 클래스가 제공되고 아래는 예시이다
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.build();
}Step
Step은 배치 작업의 독립적이고 순차적인 처리 단계를 캡슐화한 도메인 객체로
모든 Job은 하나 이상의 step으로 구성되어 있다
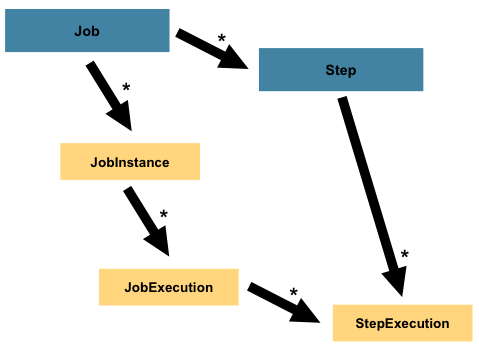
Step은 실제 배치 처리에 필요한 정의 및 제어 정보를 모두 포함한다
ItemReader
Step에서 입력 데이터를 한 번에 하나씩 가져오는 동작을 표현하는 추상화된 개념이다
ItemReader가 더 이상 제공할 데이터가 없으면
null을 반환함으로써 끝났다는 것을 알려준다
ItemWriter
Step의 출력 처리를 담당하는 추상화된 개념으로
한 번에 하나의 배치 또는 청크의 아이템들을 처리한다
일반적으로 다음에 어떤 입력을 받을지에 대한 정보는 없고
자신이 현재 호출될 때 전달받은 아이템들만 인식한다
청크란?
데이터 처리 단위를 의미
하나씩 데이터를 읽고 일정 개수가 모이면 한꺼번에 처리(쓰기)하는 방식
ItemProcessor
하나의 아이템에 대한 비즈니스 로직 처리를 나타내는 추상화된 개념이다
ItemReader는 아이템을 읽고, ItemWriter는 아이템을 쓰는 반면
ItemProcessor는 아이템을 변환하거나
비즈니스 로직을 적용할 수 있는 중간 지점을 제공한다
아이템을 처리하는 중에 유효하지 않다고 판단되면
null을 반환함으로써 해당 아이템을 기록하지 않도록 할 수 있다
지금까지의 이야기를 종합해보면
step으로 이루어진 job을 통해 배치 프로세스가 진행되는 것 같은데
공식문서를 읽어봐도 잘 이해가 되지 않는다 ..
코드를 통해 알아보자
구현
우선 배치를 사용하기 위해 의존성을 등록해준다
implementation 'org.springframework.boot:spring-boot-starter-batch'다음으로 컨피그 설정을 해준다
private final DataSource dataSource;
private final EntityManagerFactory entityManagerFactory;
private final int CHUNK_SIZE = 500;필자는 mySQL을 사용하기 때문에
데이터를 인서트할 DataSource와 엔티티매니저팩토리의 의존성을 주입받아준다
청크사이즈는 500으로 상수처리 해주었다
이제 본격적으로 구현을 시작해주면되는데
@Bean
public JpaPagingItemReader<User> userReader() {
return new JpaPagingItemReaderBuilder<User>()
.name("userReader")
.entityManagerFactory(entityManagerFactory)
.queryString("SELECT u FROM User u")
.pageSize(CHUNK_SIZE)
.build();
}우선 itemReader를 통해 읽어올 데이터를 지정해준다
reader의 이름, JPQL쿼리, 데이터를 몇 개씩 불러올지 설정해주었다
@Bean
public JdbcBatchItemWriter<Notification> dailyQuestionWriter() {
return new JdbcBatchItemWriterBuilder<Notification>()
.dataSource(dataSource)
.sql("INSERT INTO tb_notification (user_id, content, created_at) VALUES (?, ?, ?)")
.itemPreparedStatementSetter((notification, ps) -> {
ps.setLong(1, notification.getUserId());
ps.setString(2, notification.getContent());
ps.setTimestamp(3, Timestamp.valueOf(LocalDateTime.now()));
})
.build();
}다음으로 itemWriter를 등록해주었는데
배치처리를 해줄거기 때문에
조인될 userId와 메시지내용, 시간을 각각 바인딩 해주었다
@Bean
public ItemProcessor<User, Notification> dailyQuestionProcessor() {
return user -> Notification.builder()
.user(user)
.content("오늘의 질문이 도착했습니다 !")
.build();
}이제 ItemProcessor 설정을 통해
reader와 writer 사이에 비즈니스 로직을 설정해주면 된다
@Bean
public Step sendDailyQuestionStep(
JobRepository jobRepository,
PlatformTransactionManager transactionManager,
JpaPagingItemReader<User> userReader,
ItemProcessor<User, Notification> itemProcessor,
JdbcBatchItemWriter<Notification> itemWriter
) {
return new StepBuilder("sendDailyQuestionStep", jobRepository)
.<User, Notification>chunk(CHUNK_SIZE, transactionManager)
.reader(userReader)
.processor(itemProcessor)
.writer(itemWriter)
.build();
}위에 설정한 reader, writer, processor를 기반으로 step을 만들어준다
@Bean("sendDailyQnaJob")
public Job sendDailyQuestionJob(
JobRepository jobRepository,
Step sendDailyQuestionStep
) {
return new JobBuilder("sendDailyQuestionJob", jobRepository)
.start(sendDailyQuestionStep)
.build();
}마지막으로 Job에 만들어둔 Step을 등록시켜주면 컨피그 설정은 끝이다
@Scheduled(cron = "0 53 0 * * *")
public void sendDailyQuestionNotification() throws Exception{
JobParameters jobParameters = new JobParametersBuilder()
.addLong("time", System.currentTimeMillis())
.toJobParameters();
jobLauncher.run(sendDailyQuestionJob, jobParameters);
}이제 기존코드에 만들어놓은 job을 등록해주면 구현이 끝난다
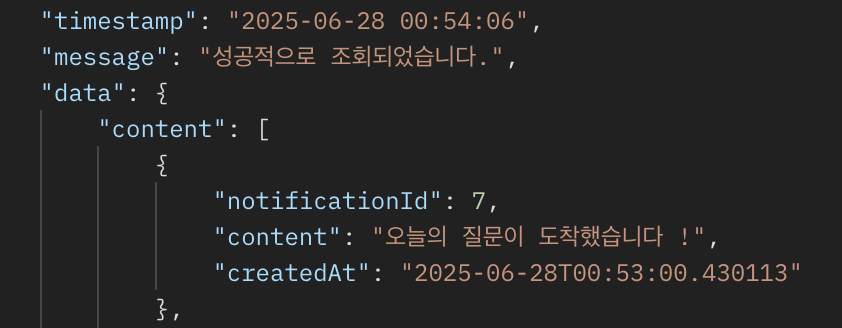
포스트맨을 통해 확인해봤을때
코드가 잘 실행되는것을 확인할 수 있다
성능 테스트
성능 테스트 기준은 유저 10만명 기준으로 잡았다

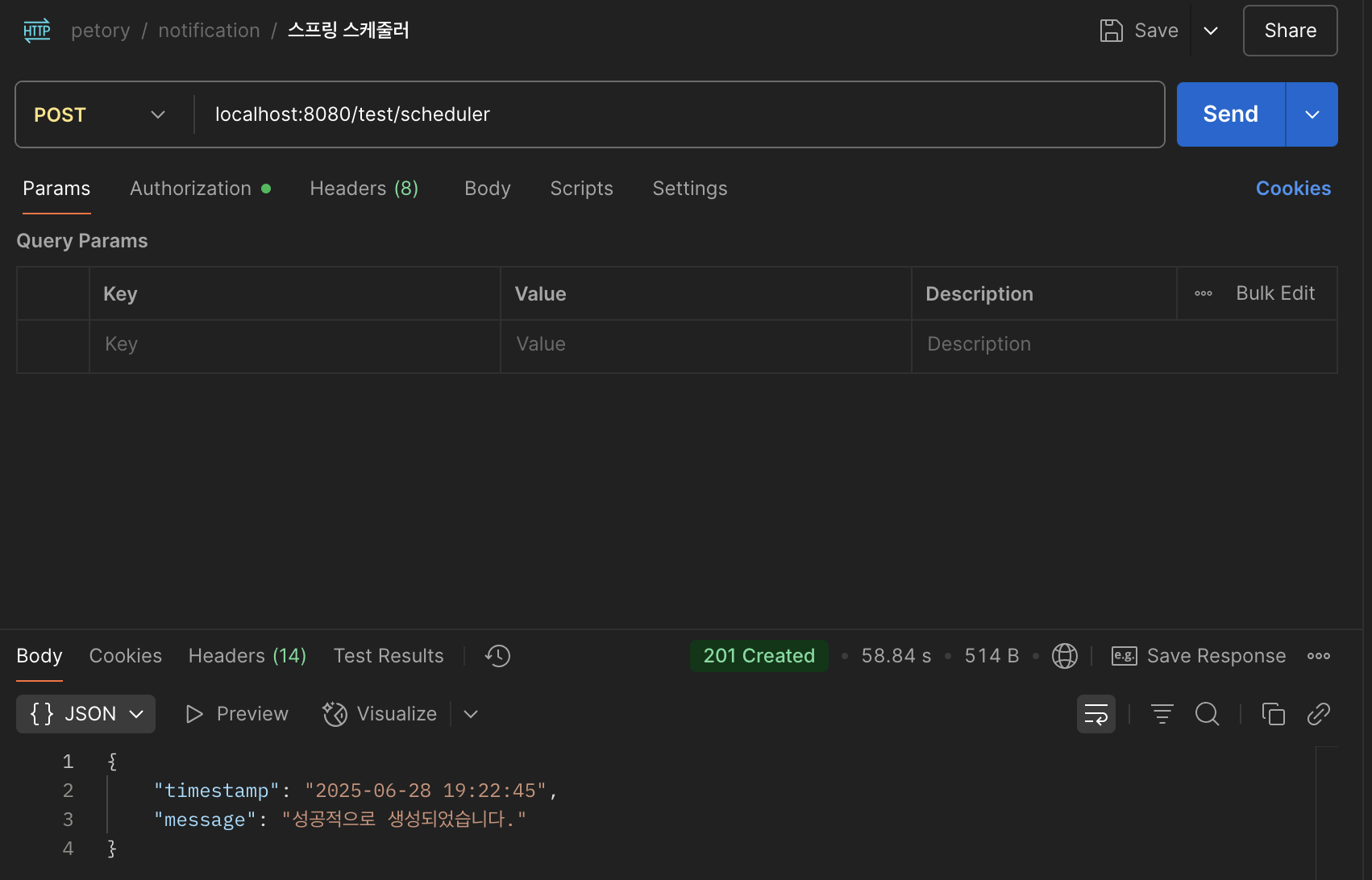
기존 방식: findAll() + for문 순차 저장
모든 유저를 findAll()로 조회한 후
for문을 통해 Notification을 하나씩 DB에 저장하는 방식이다
트랜잭션 내에서 동기적으로 순차 저장되며 병렬 처리나 청크 최적화가 전혀 없는 구조이다
처리 시간: 평균 약 58초

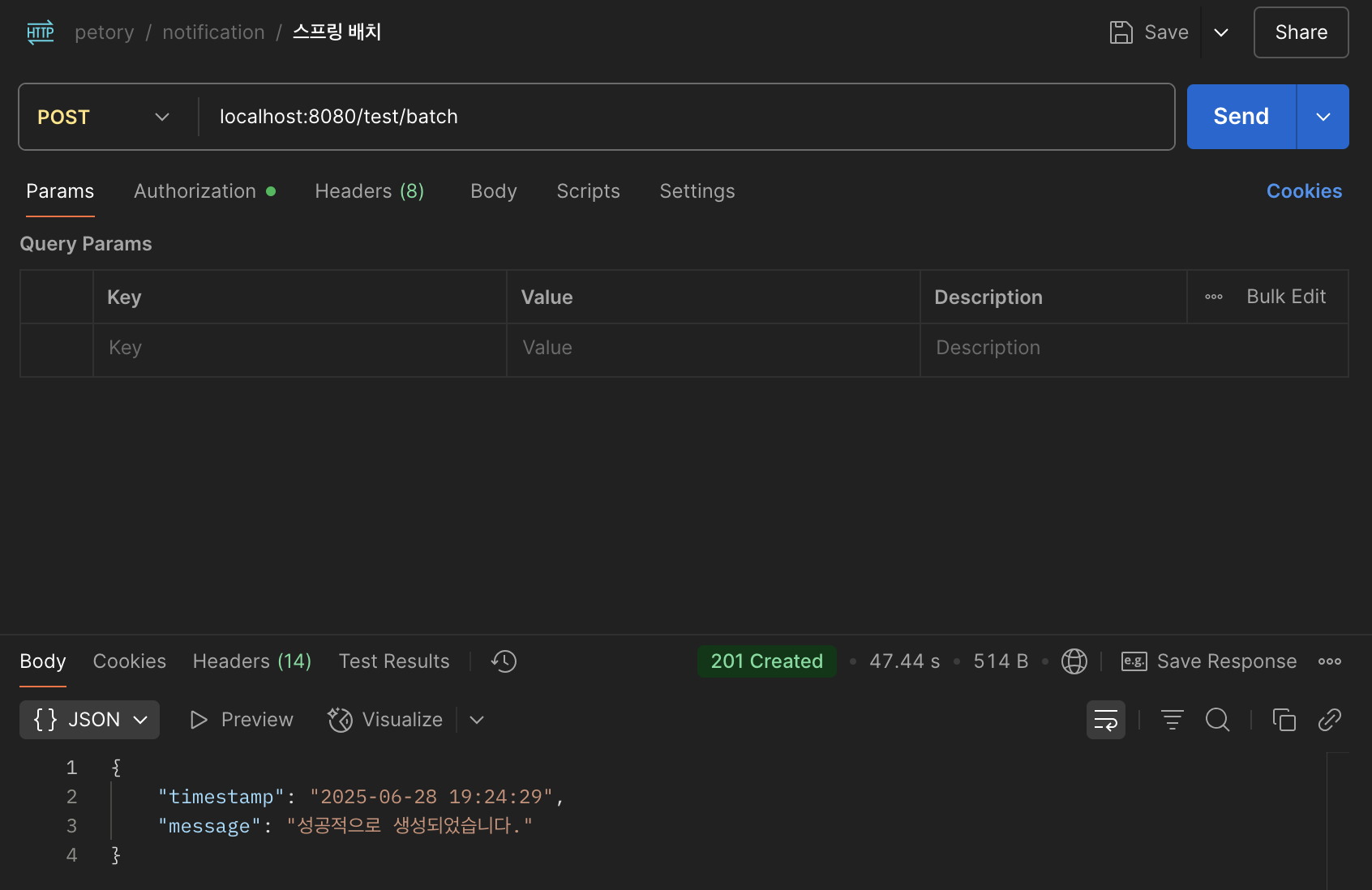
개선 방식: Spring Batch 도입
Spring Batch를 통해 데이터를 청크 단위로 나누어 다건 저장하는 구조로 변경했다
내부적으로 JpaItemWriter를 통해 batch insert가 일어나며
트랜잭션도 청크 단위로 커밋된다
현재 청크 크기는 500으로 설정되어 있다
처리 시간: 평균 약 48초
평균시간 기존 58초 -> 48초로
약 10초 단축 18%의 성능이 개선이 확인되었다
트러블슈팅
문제상황
# Spring Batch
spring.batch.jdbc.initialize-schema=alwaysproperties에 메타 데이터가 자동으로 생성될 수 있도록
해당 코드를 추가해두었는데
Caused by: java.sql.SQLSyntaxErrorException: Table 'petory_db.BATCH_JOB_INSTANCE' doesn't exist실제 메서드 실행 시 메타 데이터가 생성되지 않았다는 오류가 발생했다
문제 원인
문제원인은 역시나 메타데이터 테이블이 생성되지 않았기 때문이다
디버깅을 찍어보니 애초에 mysql 호출 자체를 하지 않고 있었는데
알고보니 위에 코드는 내장 데이터 테이블을 사용할때에 한해서 동작하는 코드였고 ,,
나는 docker를 통해 MySQL을 실행시켰기 때문에
해당 코드가 동작하지 않았던것이다
문제 해결
결국 수동 테스트를 통해 직접 메타데이터를 생성했다
External Libraries에 batch core에 들어가보면
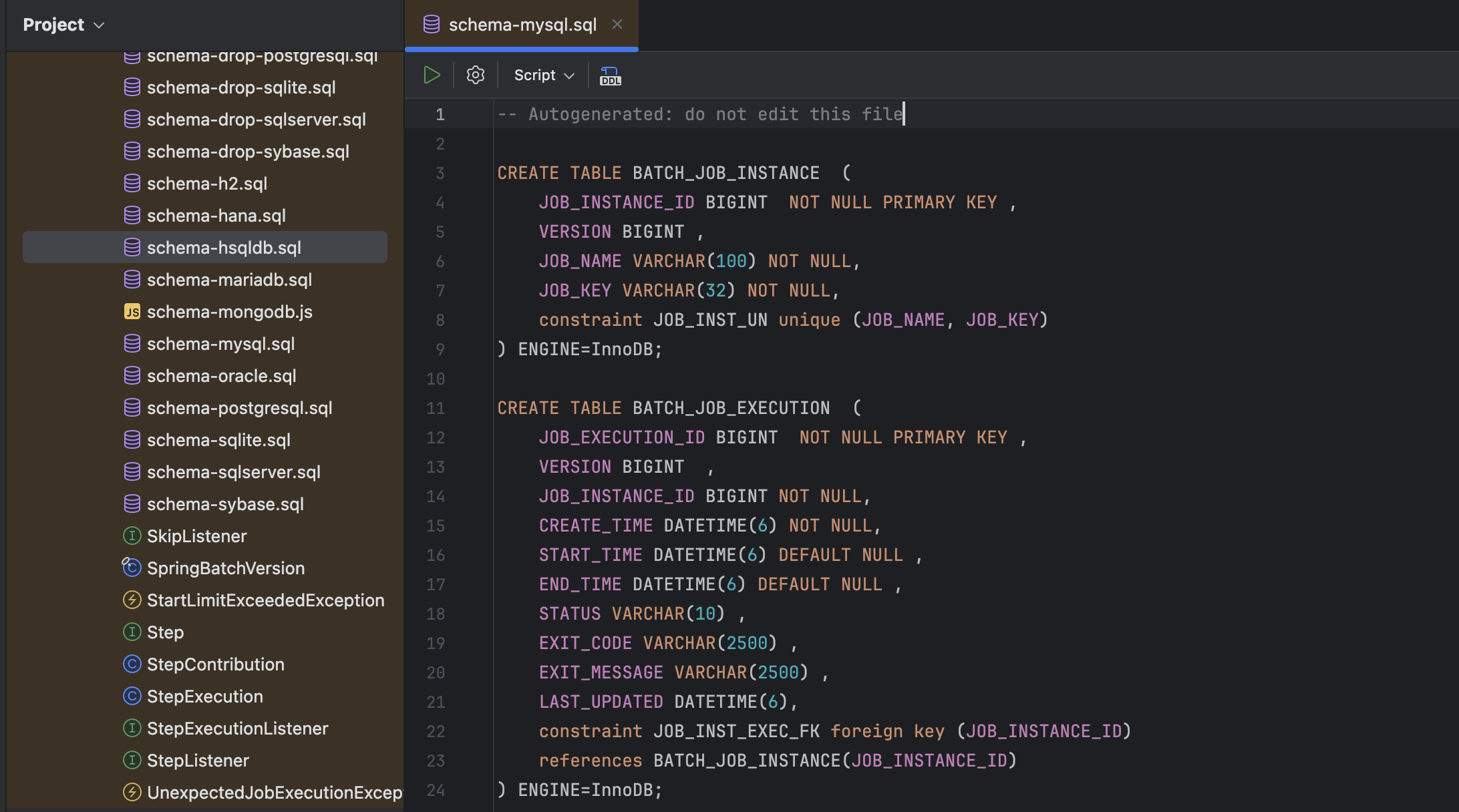
요런식으로 데이터가 정리되어있는데
해당 코드를 복사해서 직접 SQL 쿼리를 날려 생성해주면 된다
마무리
원래 목적이었던 성능 개선 자체는 성공했지만 솔직히 10만건 기준으로 평균 속도 48초는 많이 아쉬운거같다 .. 지금 생각중인건 비동기 방식으로 변경한다면 더 눈에 띄는 성과가 있을거같아 바로 도전해볼 예정이다
출처
