구글 이미지 크롤링
selinum 라이브러리 설치
pip install selenium
pip install webdriver-manager구글 크롬 자동 설치
# 구글 크롬 드라이버의 자동설치를 위한 라이브러리 불러오기
from webdriver_manager.chrome import ChromeDriverManager
# 크롬 드라이버의 제어를 위해 selenium라이브러리를 불러오기
from selenium import webdriver
# 크롬 드라이버 시작. 프로그램이 설치되지 않았다면 프로그램을 자동으로 설치
driver = webdriver.Chrome(ChromeDriverManager().install())
#구글의 이미지 검색 사이트로 이동
URL='https://www.google.co.kr/imghp'
driver.get(url=URL)
# 사이트로 이동할 때까지 최대 10초 대기
driver.implicitly_wait(time_to_wait=10)실행결과

"Chrome이 자동화된 테스트 소프트웨어에 의해 제어되고 있습니다." 문구가 나옴
구글 상에서 이미지 크롤링하는 코드 만들기
# 키 입력을 위한 라이브러리를 불러오기
from selenium.webdriver.common.keys import Keys
# 셀레니움의 css selector를 통해 원소 찾기
elem = driver.find_element_by_css_selector("#sbtc > div > div.a4bIc > input")
# 검색할 사진은 바다
elem.send_keys("바다")
# 엔터키를 입력하여 검색
elem.send_keys(Keys.RETURN)실행결과
이미지 검색이기 때문에 이미지만 검색됨
* 원소를 찾을 때, selector, xPath, styles 등을 이용하여 원소를 찾을 수 있음.
이미지 더보기 자동 클릭
import time
# 바다 부분 찾기
elem = driver.find_element_by_tag_name("body")
# 페이지 다운키를 60회 눌러 사진이 계속 보이도록 하기
for i in range(60):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
# 예외처리
try:
# 중간에 [결과 더보기]버튼이 있다면 눌러서 계속 사진이 보이도록 하기
driver.find_element_by_css_selector('#islmp > div > div > div > div.gBPM8 > div.qvfT1 > div.YstHxe > input').click()
# [결과 더보기] 버튼이 눌린 후 페이지 다운키를 60회 눌러 사진이 계속 보이도록 함
for i in range(60):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
except:
pass이미지 개수 출력
# 이미지의 원소 모두 찾기
links=[]
# 찾은 이미지 수 만큼 반복
images = driver.find_elements_by_css_selector("#islrg > div.islrc > div > a.wXeWr.islib.nfEiy > div.bRMDJf.islir > img")
for image in images:
# 이미지에서 링크 주소가 있으면
if image.get_attribute('src') is not None:
# 이미지의 다운로드 링크 주소를 links 리스트에 추가
links.append(image.get_attribute('src'))
# 이미지 개수 출력
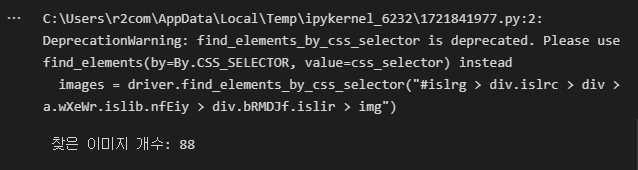
print(' 찾은 이미지 개수:',len(links))실행 결과
찾은 이미지 다운로드
# request 라이브러리 불러오기
import urllib.request
# links의 리스트를 enumerate 하여 반복.
# k 값은 번호, i 값은 links 리스트의 원소값
for k,i in enumerate(links):
url = i
# 사진 다운로드. 경로는 절대 경로
urllib.request.urlretrieve(url, "C:\\파이썬과 40개의 작품들\\19. 구글 이미지 크롤링\\사진다운로드\\"+str(k)+".jpg")
print('다운로드 완료하였습니다.')주피터 노트북 코드를 py코드로 변경
# py파일로 변경해주는 nbconvert라이브러리 설치
pip install nbconvert
# ipynb 코드 py로 변경
jupyter nbconvert --to script main19.ipynb사진에 얼굴만 찾아 모자이크 처리(Open CV)
라이브러리 설치
pip install opencv-python사진 다운로드
사이트에서 - group 검색 후 사람얼굴 많은 사진 다운
실행파일이 있는 경로로 [샘플사진]이라고 이름 변경 후 저장
얼굴 찾는 코드 작성
# numpy 라이브러리 불러오기
import numpy as np
# openCV 라이브러리 불러오기
import cv2
# 얼굴과 눈을 찾기 위한 OpenCV알고리즘이 적용된 파일 불러오기
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
eye_casecade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_eye.xml')
# OpenCV 에서 한글경로의 파일을 읽지못해 numpy파일로 읽어오기
ff = np.fromfile(r'23. 사진에서 얼굴만 찾아 모자이크처리 (OpenCV)\샘플사진.jpg', np.uint8)
# imdecode하여 numpy이미지 파일을 OpenCV이미지로 불러오기
img = cv2.imdecode(ff, cv2.IMREAD_UNCHANGED)
# 이미지 크기 조절
img = cv2.resize(img, dsize=(0, 0), fx=0.6, fy=0.6, interpolation=cv2.INTER_LINEAR)
# 이미지에서 얼굴을 찾기 위해 회색조로 처리
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 여러 개의 얼굴을 찾기.
# 1.2는 ScaleFactor 감도, 5는 miniJeighbor 최소 이격거리
# 두 값을 조절하여 감도의 조절이 가능
faces = face_cascade.detectMultiScale(gray, 1.2,5)
# 얼굴을 찾아 파란색 네모를 표시하는 반복문
for (x,y,w,h) in faces:
cv2.rectangle(img, (x,y), (x+w, y+h), (255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_casecade.detectMultiScale(roi_gray)
# 눈을 찾아 녹색 네모 표시
for (ex, ey, ew, eh) in eyes:
cv2.rectangle(roi_color, (ex,ey), (ex+ew, ey+eh),(0,255,0),2)
cv2.imshow('face find', img)
cv2.waitKey(0)
cv2.destroyAllWindows()실행결과

사진 속 얼굴을 모자이크 처리하는 코드
import numpy as np
import cv2
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
eye_casecade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_eye.xml')
ff = np.fromfile(r'23. 사진에서 얼굴만 찾아 모자이크처리 (OpenCV)\샘플사진.jpg', np.uint8)
img = cv2.imdecode(ff, cv2.IMREAD_UNCHANGED)
img = cv2.resize(img, dsize=(0, 0), fx=0.6, fy=0.6, interpolation=cv2.INTER_LINEAR)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.2,5)
for (x,y,w,h) in faces:
# 탐지된 얼굴부분 자르기
face_img = img[y:y+h, x:x+w]
# 이미지 축소
face_img = cv2.resize(face_img, dsize=(0, 0), fx=0.05, fy=0.05)
# 이미지 확대
face_img = cv2.resize(face_img, (w, h), interpolation=cv2.INTER_AREA)
# 자른 이미지를 축소 확대한 이미지로 대체
img[y:y+h, x:x+w] = face_img
cv2.imshow('face find', img)
cv2.waitKey(0)
cv2.destroyAllWindows()실행결과

로또번호 시각화하기
라이브러리 설치
pip install openpyxl로또 당첨번호 자료 엑셀 파일 다운받기
-
동행 복권 사이트 접속
https://www.dhlottery.co.kr/ -
[당첨결과] - [회차별 당첨번호]
-
1회부터 최근 회차까지 선택 후 엑셀 파일 다운로드(*.xls)
-
실행 폴더에 lotto파일명으로 저장
import pandas as pd
file_path = r'26. 로또번호 시각화하기\lotto.xlsx'
df_from_excel = pd.read_excel(file_path,engine='openpyxl')
df_from_excel = df_from_excel.drop(index=[0,1])
df_from_excel.columns = [
'년도', '회차','추첨일','1등당첨자수',
'1등당첨금액','2등당첨자수','2등당첨금액','3등당첨자수',
'3등당첨금액','4등당첨자수','4등당첨금액','5등당첨자수',
'5등당첨금액','당첨번호1','당첨번호2','당첨번호3',
'당첨번호4','당첨번호5','당첨번호6','보너스번호'
]
print(df_from_excel.head())
print(df_from_excel['회차'].values)
print(df_from_excel['1등당첨금액'].values)실행결과

판다스 값으로 읽고 그래프로 그리는 코드 만들기
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
file_path = r'26. 로또번호 시각화하기\lotto.xlsx'
df_from_excel = pd.read_excel(file_path,engine='openpyxl')
df_from_excel = df_from_excel.drop(index=[0,1])
df_from_excel.columns = [
'년도', '회차','추첨일','1등당첨자수',
'1등당첨금액','2등당첨자수','2등당첨금액','3등당첨자수',
'3등당첨금액','4등당첨자수','4등당첨금액','5등당첨자수',
'5등당첨금액','당첨번호1','당첨번호2','당첨번호3',
'당첨번호4','당첨번호5','당첨번호6','보너스번호'
]
df_from_excel['1등당첨금액']=df_from_excel['1등당첨금액'].str.replace(pat=r'[ㄱ-ㅣ가-힣,]+', repl= r'', regex=True)
df_from_excel['2등당첨금액']=df_from_excel['2등당첨금액'].str.replace(pat=r'[ㄱ-ㅣ가-힣,]+', repl= r'', regex=True)
df_from_excel['3등당첨금액']=df_from_excel['3등당첨금액'].str.replace(pat=r'[ㄱ-ㅣ가-힣,]+', repl= r'', regex=True)
df_from_excel['4등당첨금액']=df_from_excel['4등당첨금액'].str.replace(pat=r'[ㄱ-ㅣ가-힣,]+', repl= r'', regex=True)
df_from_excel['5등당첨금액']=df_from_excel['5등당첨금액'].str.replace(pat=r'[ㄱ-ㅣ가-힣,]+', repl= r'', regex=True)
df_from_excel["1등당첨금액"] = pd.to_numeric(df_from_excel["1등당첨금액"])
df_from_excel["2등당첨금액"] = pd.to_numeric(df_from_excel["2등당첨금액"])
df_from_excel["3등당첨금액"] = pd.to_numeric(df_from_excel["3등당첨금액"])
df_from_excel["4등당첨금액"] = pd.to_numeric(df_from_excel["4등당첨금액"])
df_from_excel["5등당첨금액"] = pd.to_numeric(df_from_excel["5등당첨금액"])
print( df_from_excel[['1등당첨금액','2등당첨금액','3등당첨금액','4등당첨금액','5등당첨금액']] )
font_path = "C:/Windows/Fonts/NGULIM.TTF"
font = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font)
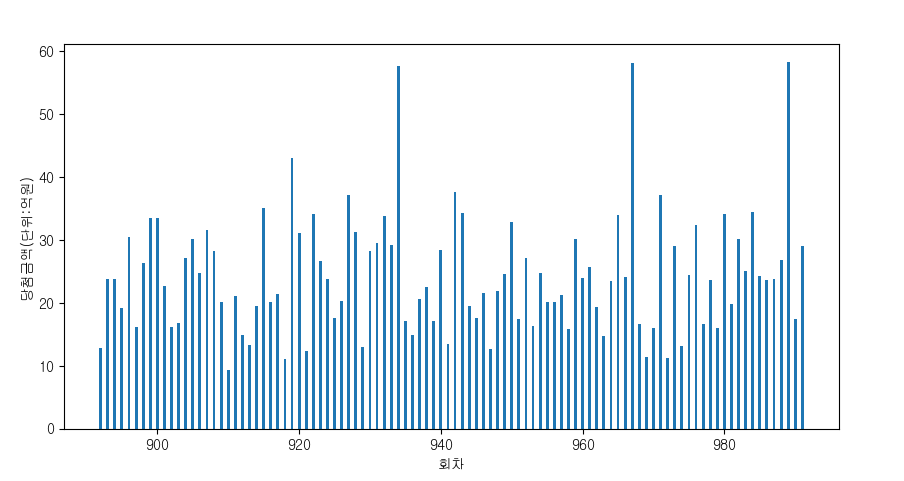
x = df_from_excel['회차'].iloc[:100].values
price = df_from_excel['1등당첨금액'].iloc[:100].values / 100000000
plt.figure(figsize=(10, 5))
plt.xlabel('회차')
plt.ylabel('당첨금액(단위:억원)')
plt.bar(x, price, width=0.4)
plt.show()실행 결과