본 시리즈는 연합학습의 수렴률 분석을 단계별로 정리한 글입니다. 인공지능 학습과 수학에 대한 최소한의 배경지식만으로 연합학습 알고리즘의 수렴률 분석을 차근차근 학습할 수 있도록 구성되었습니다. 글의 내용에 대한 추가적인 배경지식이 필요한 경우,
보완 설명섹션을 통해 관련한 내용을 제공하고 있습니다.
1. Introduction
연합학습의 수렴성 분석을 이해하기 위해서는, 많은 배경지식이 요구된다. 최종적으로 대표적인 연합학습 알고리즘들 (e.g., FedAvg; FedProx) 의 수렴률 분석을 이해하기 위해, 앞으로의 내용들을 위한 배경지식들을 살펴본다.
2. Machine learning problem
머신러닝이 해결하고자 하는 기본적인 문제는 모델이 어떤 입력 데이터에 대한 예측을 수행할 때, 예측된 값과 실제 정답 사이의 오차가 최소화되는 파라미터를 찾는 것이다. 이 과정은 다음과 같이 공식화될 수 있다.
- : 목적 함수 (i.e., 손실 함수)
- : 입력 데이터
- : 출력 데이터
- : 파라미터
위의 공식을 자세히 살펴보면, 머신러닝 문제를 정의하기 위한 요소 중 하나인 오차를 직접적으로 의미하는 항이 없는 것을 볼 수 있다. 그 이유는 오차는 손실 함수의 출력 값 그 자체를 의미하는 용어이기 때문인데, 머신러닝에서 사용되는 손실 함수는 여러개가 있다. 본 글에서는 다음 섹션에서 간단한 머신러닝 예제들을 통해 두가지 손실함수들에 대해서 소개한다.
3. Examples of machine learning
머신러닝 기법의 종류는 무수히 많이 있지만, 여기에서는 간단한 몇가지 예제를 바탕으로 머신러닝 기법들이 사용하는 손실 함수에 대한 수학적인 표기와 몇가지 기호들을 살펴보자.
3.1 Least squares regression
최소 제곱 회귀는 출력 데이터 가 입력 데이터 에 의해 선형 방정식과 약간의 오차로 설명될 수 있다고 가정한다 (i.e., ). 손실 함수는 제곱 오차를 사용하며, 다음과 같이 주어진다.
보완 설명 1:
이 기호는 입력 데이터 에 대해, 모델이 예측한 값을 의미한다. 앞서 언급한 것과 같이 모델의 출력은 실제 출력 데이터 값에 대해서 약간의 오차가 존재하므로, 기호를 사용해서 나타낸다.
보완 설명 2:
이 공식은 인공지능 모델의 출력 () 를 의미한다. 인공지능 모델의 계산이 파라미터 () 와 입력 데이터 () 의 곱에 편향 () 을 더하는 과정이라는 것을 생각해 보면, 직관적으로 이해할 수 있다. 편향의 경우 모델의 종류 및 상황에 따라 존재하지 않을 수도 있으며, 의 경우 파라미터 행렬의 전치행렬을 의미하는데, 이는 실제 행렬 연산을 위해서 필요한 과정이지만, 단순히 파라미터와 입력 데이터의 행렬 곱으로 이해해도 무방하다.
보완 설명 3: L2 norm ()
노름(norm)이란, 어떤 벡터를 길이나 사이즈같은 양적인 수치로 매핑하기 위한 함수를 의미한다. 가장 많이 쓰이는 노름은 L2 노름이라고 불리는 유클리디언 노름으로, 다름과 같이 계산된다.
3.2 Support vector machine (SVM)
SVM은 입력 데이터 를 두개의 범주 (-1, 1) 로 분류하는 데 사용된다. 만약 목표가 최대 마진 분류라면, 힌지 손실 함수가 사용될 수 있다. 힌지 손실 함수는 다음과 같이 주어진다.
만약, 와 가 서로 다른 부호 (i.e., 잘못된 분류) 를 가진다면, 계산된 오차는 의 절댓값 만큼 커지게 된다.
반대로, 와 가 서로 같은 부호 (i.e., 올바른 분류) 를 가지고 의 절댓값이 1보다 크거나 같다면, 계산된 오차는 0이 된다. 하지만, 서로 같은 부호를 가지는 경우에도 의 절댓값이 1보다 작다면, 분류에 대한 모델의 확신이 충분히 크지 않기 때문에, 계산된 오차는 0보다 크다.
보완 설명 4: 최대 마진 분류
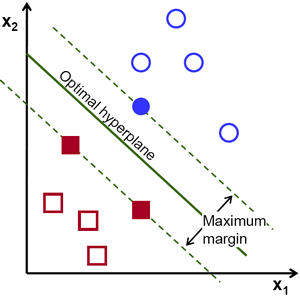
어떤 평면에 존재하는 데이터를 두개의 범주로 나눈다고 하면, 무수히 많은 구분선을 만들 수 있는데, 최대 마진 분류는 이 수많은 구분선 중에서 각 데이터 그룹 사이의 최대 거리 (i.e., 마진) 을 가지는 구분선 (i.e., 초평면; hyperplane) 을 찾아내는 방식이다.
4. Optimization problem
지금까지 섹션 2에서 머신러닝 학습의 문제를 공식화하여, 학습이 정확하게 어떤 것을 하는 것인지를 수학적으로 살펴보았고, 섹션 3에서 학습에 필요한 오차를 어떻게 계산하는지를 수학적으로 살펴보았다.
다음으로, 계산된 오차를 통해 어떻게 오차를 최소화하는 파라미터를 찾는 방법인 최적화 문제에 대해서 알아보자. 최적화 문제를 해결하기 위해서 가장 널리 사용되는 방법은 경사 하강법과 확률적 경사 하강법이다. 각 방식의 장단점이 존재하지만 본 글에서 다루고자 하는 내용을 벗어나므로, 여기서는 각 방식이 무엇인지만 간단하게 소개한다.
- 경사 하강법: 매 파라미터 업데이트 마다 모든 데이터에 대한 오차를 계산하여 파라미터를 업데이트한다.
- 확률적 경사 하강법: 매 파라미터 업데이트 마다 전체 데이터에서 무작위로 선택한 하나 또는 소량의 데이터를 사용하여 오차를 계산하고 파라미터를 업데이트한다.
두 최적화 방식이 사용하는 데이터의 수나 종류는 서로 상이하지만, 계산된 오차에 대해 파라미터를 업데이트하는 방식은 동일하다. 두 방식 모두 파라미터를 어떻게 얼마나 변화시킬지를 결정하기 위해, (1) 사용하는 손실함수를 파라미터에 대해 미분하여, (2) 파라미터 변화에 따른 손실 값의 변화 (i.e., 기울기) 를 계산하고, (3) 손실이 줄어드는 방향으로 파라미터를 업데이트 한다. 이 때, 기울기가 크면 클수록 더 많이 파라미터를 업데이트 한다.
이어지는 섹션들에서 각 방식의 수학적 표기법과 수렴률 증명을 알아보면서, 각 방식들의 차이를 조금 더 자세히 살펴보자.
5. Convergence of Gradient Descent
경사 하강법의 기본적인 아이디어는, 초기에 랜덤한 파라미터 에 대해 파라미터 업데이트를 순차적으로 수행하는 것이다. 이 과정은 다음과 같이 공식화된다.
- : 학습률
이 공식에서 학습률은 학습시 설정되는 값으로, 기울기와 곱해져 얼마나 많이 이동할지를 결정한다. 즉, 기울기 값과 함께 이동의 양을 결정하는 값이다. 지금까지 살펴본 내용을 종합하면, 머신러닝에서 모델의 수렴 (최소화) 는 손실 함수의 종류와 학습률에 따라서 결정되는 것을 알 수 있다.
따라서, (1) 손실 함수 자체가 최솟값이 없거나, (2) 여러개의 지역 최솟점이 있는 경우, (3) 임의로 값이 널뛰는 불연속 함수 등의 경우 수렴이 불가능할 수 있다. 다행히도, 대부분의 실제 문제에서는 손실 함수에 매끄러움 (smoothness) 그리고 볼록성 (convexity) 이라는 특별한 구조적 가정을 적용하는 것이 합리적이기 때문에 수렴률을 증명할 수 있다.
5.1 Smoothness
매끄러움은 함수의 기울기 값의 변화를 제한하는 구조적 가정이다. 함수의 기울기는 함수 값이 어떤 지점에서 특정 방향으로 얼마나 변화하는지를 나타낸다. 만약, 기울기가 매우 빠르게 변화한다면, 해당 지점에서 살짝의 변화만 주어도 매우 큰 변화가 발생하기 때문에, 주변의 기울기와 연관성이 높지 않다. 반면, 매끄러움이 보장된 함수는 기울기의 변화가 급진적이지 않으며, 따라서 어떤 지점 주변의 기울기도 해당 지점의 기울기와 연관성이 있다고 할 수 있다. 요약하자면, 매끄러움은 어떤 위치해서 함수의 기울기의 반대 방향으로 이동하는 것이 함수 값을 감소시킬 수 있다는 것을 의미한다.
여기서는 L-매끄러움을 사용해서 매끄러움을 가정하는데, 이는 다음과 같이 공식화된다. 미분 가능한 함수 가 모든 에 대해서 다음을 따를 때, L-매끄러움을 만족한다고 한다.
- : 실수 집합
- : 차원 실수 집합
- : 차원 실수 벡터를 입력으로 받아 하나의 실수를 반환하는 함수
- : 함수의 기울기, 즉 미분 값
- : Lipschitz 상수를 의미하며, 기울기 변화의 상한을 의미함.
이 공식을 조금 변형하면 다음과 같이 나타낼 수 있다.
변형된 공식에 따르면, 모든 지점에서 함수의 최대 기울기는 이라는 것을 직관적으로 알 수 있다.
5.2 Convexity
볼록성은 말 그대로 함수의 형태가 볼록하다는 것을 의미한다. 주의해야할 점은 아래로 볼록한 경우만 함수가 볼록하다고 표현하고, 위로 볼록한 경우에는 오목 (concave) 한 함수라고 표현한다. 조금 더 정확하게는 함수 위의 어떤 두 점을 연결하는 직선을 그렸을 때, 두 점 사이의 함수값들은 모두 두 점을 잇는 직선보다 아래에 존재하는 함수를 볼록한 함수라고 이야기 한다.
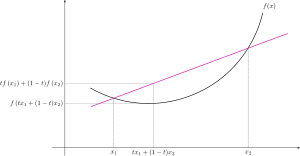
손실 함수에 대해 볼록성을 가정하는 것이 중요한 이유는, 최소점이 하나만 존재한다는 것을 볼록성이 보장하기 떄문인데, 이는 볼록함수의 기하학적인 형태를 생각해보면 쉽게 이해할 수 있다. 볼록 함수의 수학적인 정의는 다음과 같다. 함수 의 정의역 () 이 볼록 집합 (convex set) 이고, 모든 에 대해서 다음을 만족하면 볼록 함수라고 한다.
이 공식에서 꼴의 수식이 반복되는 것을 볼 수 있는데, 이것은 과 를 잇는 선분을 의미한다. 수식을, 로 변형해보면 의미가 보다 직관적으로 이해되는데, 는 에서 로 이동하는 벡터의 방향과 크기를 의미하고, 는 출발점을 의미한다. 즉, 에서 출발하여 방향으로 만큼 이동하는 것을 의미하는데, 가 0부터 1까지의 수이므로, 과 사이의 선분을 의미하는 것이다. 즉, 위의 공식은 과 의 사이의 직선은 항상 그 사이의 함수보다 위에 있거나, 같음을 나타내는 것이 된다.
보완 설명 5: convex set
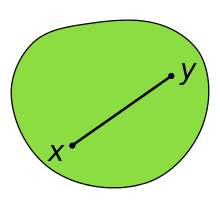
볼록한 함수에 대해서는 살펴보았지만, 볼록한 함수의 정의역 제한조건인 볼록한 집합에 대해서는 살펴보지 않았다. 볼록한 집합이란, 볼록한 함수와 크게 정의가 다르지 않은데, 간단하게 어떤 집합 가 있을 때, 내부의 어떤 두 점 , 를 잇는 선분 내의 모든 지점들도 집합 에 포함되는 경우를 의미한다. 이를 수학적으로 나타내면, 모든 에 대해 가 를 만족하는 집합을 볼록한 집합이라고 한다.
5.3 Strictly convex
볼록한 함수를 정의하는 식을 보면, 같거나 작은 () 부등호를 볼 수 있다. 따라서, 특정 영역에서 값의 변화가 없는 (i.e., 축에 평행한) 함수도 볼록 함수라고 정의할 수 있다. 따라서, 만약 단순히 손실 함수에 대해 볼록한 함수인 것만을 가정한다면, 수렴의 기준이 하나가 아니라 여러개일 수 있다는 것을 의미한다. 따라서, 우리는 수렴률을 분석하기 위해 엄격히 볼록한 함수라는 것을 추가적으로 가정한다. 엄격한 볼록 함수는 볼록 함수의 정의와 크게 다르지 않은데, 부등호를 작은 () 으로 바꾸는 것 만으로 정의를 할 수 있다.
위의 정의를 따르는 엄격한 볼록 함수는 이제 전역에서 최솟점이 1개인 함수가 되어, 수렴의 기준이 1개로 좁혀진다.
5.4 -strongly convex
지금까지 볼록 함수와 엄격한 볼록 함수를 알아보면서, 전역 최솟값이 하나인 손실 함수를 가정하는 방법을 알아보았다. 그러나, 분석에 있어 여전히 빠진 부분이 하나 존재한다. 바로 곡률의 하한을 제한하는 것이다. 곡률의 하한 제한이 존재하지 않는다면, 극단적으로 곡률이 낮은 함수도 손실 함수가 될 수 있고, 이는 사실상 곡률이 이하의 거의 0인 함수도 손실 함수가 될 수 있다는 것을 의미한다. 이러한 가정에서는 수렴률을 분석할 수 없기 떄문에, 마지막으로 수렴율 분석을 위해 곡률의 하한을 제한하는 가정인 -강한 볼록에 대해서 알아보자.
-강한 볼록의 개념은 볼록 함수의 정의에서 확장된다. 볼록 함수가 함수의 어떤 두 지점을 잇는 선분이 함수보다 위에 있다는 것을 보장한다면, -강한 볼록 함수는 여기에다가, 선분과 함수의 차이가 일정 이상 벌어지는 것을 더한 것을 의미한다. 함수의 정의역 내부의 모든 과 에 대해서, 다음을 만족할 때 이 함수는 -강한 볼록 함수라고 한다.
이 공식을 살펴보면, 기존 볼록 함수의 정의에 를 빼는 항이 추가된 것을 알 수 있다. 즉, 함수 값이 이만큼 더 아래에 존재해야 한다는 것을 의미한다. 이것의 수학적인 의미는 함수 의 이계 도함수의 함수 값이 항상 이상이여야 한다는 것을 의미하며, 따라서 함수의 곡률이 제한된다.
6. Conclusion
이번 글에서는, 머신러닝의 수학적 정의와 머신러닝의 예제들, 그리고 수렴률 분석에 필요한 손실함수에 대한 가정들을 알아보았다. 다음 글에서는 이 배경지식들을 바탕으로 실제로 수렴률을 분석하는 방법을 알아본다.
