
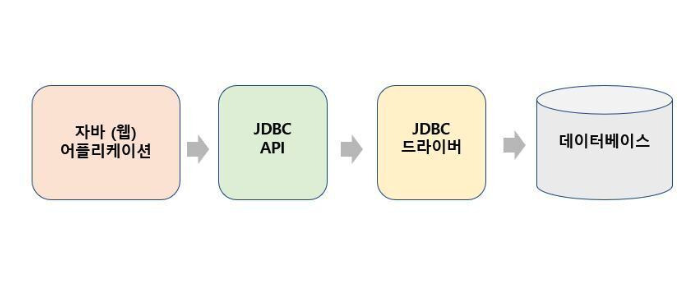
Connection 객체 생성 과정
- 애플리케이션에서 DB 드라이버를 통해 커넥션을 조회한다.
- DB 드라이버는 DB와 TCP/IP 커넥션을 연결한다.
(3 way handshake와 같은 네트워크 연결 동작 발생) - DB 드라이버는 TCP/IP 커넥션이 연결되면 아이디와 패스워드, 기타 부가 정보를 DB에 전달한다.
- DB는 아이디, 패스워드를 통해 내부 인증을 거친 후 내부에 DB를 생성한다.
- DB는 커넥션 생성이 완료되었다는 응답을 보낸다.
- DB 드라이버는 커넥션 객체를 생성해서 클라이언트에 반환한다.
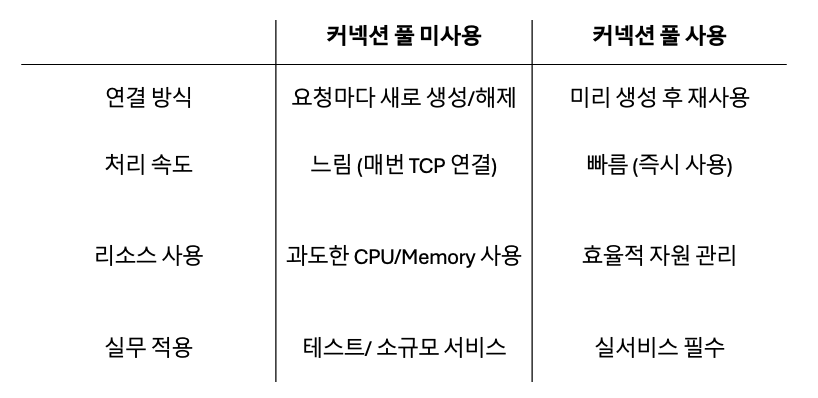
DB를 연결할 때마다 Connection 객체를 새로 만드는 것은 비용이 많이 들며 굉장히 비효율적이다.
DB 를 연결할 때마다 Connection 객체를 새로 만드는 것이 좋지 않은 이유
- 네트워크 비용: DB 연결을 설정하는 과정은 네트워크 통신을 동반한다. 새로운 Connection 객체를 생성할 때마다 DB 서버와의 네트워크 연결을 해야 하며, 이 과정은 일정 시간이 소요된다. 따라서 빈번한 Connection 생성은 불필요한 네트워크 비용을 발생시킨다.
- 리소스 사용: 각 Connection 객체는 DB 서버의 연결 세션을 나타낸다. DB 서버는 동시에 처리할 수 있는 연결 세션 수에 제한이 있으며, 무분별한 Connection 생성은 서버 리소스를 소모할 수 있다.
- 비용적 측면: Connection 객체 생성은 시간과 메모리를 소모한다. 특히 DB 연결 설정 및 인증 과정은 비용이 큰 작업이다.
Connection Pool 이란
DB 연결을 요청마다 새로 만드는 대신 미리 여러 개의 커넥션을 만들어 '풀(Pool)'에 보관하고 재사용하는 기법
Connection Pool의 핵심 목표
- 커넥션 생성에 드는 비용을 절감
- 서버의 처리량 향상
- 안정적인 DB 연결을 유지
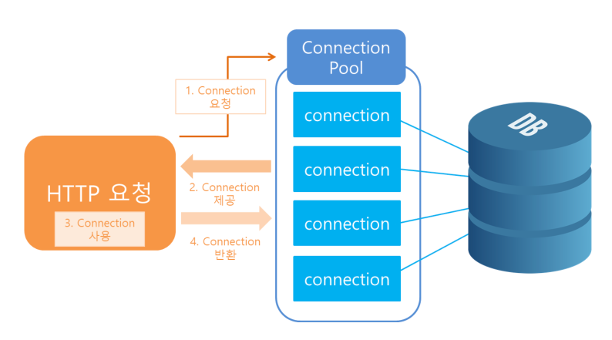
Connection Pool 동작 구조
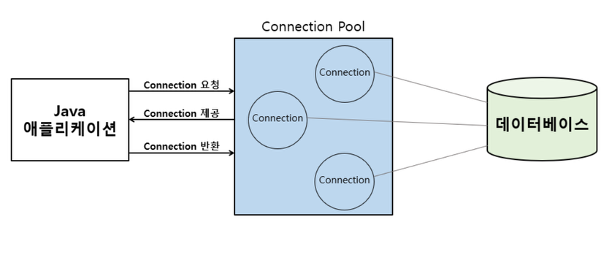
- 애플리케이션을 시작하는 시점에 커넥션 풀은 필요한 만큼 커넥션을 미리 생성하여 보관한다.
- 서비스의 특징과 스펙에 따라 생성되는 Connection 객체의 개수는 다르지만 일반적으로 기본값으로 10개를 생성한다.
- 커넥션 풀에 들어있는 Connection 객체는 TCP/IP로 DB와 연결되어 있는 상태이기 때문에 즉시 SQL을 DB에 전달할 수 있다.
- 즉, DB 드라이버를 통해 새로운 커넥션을 획득하는 것이 아닌 이미 생성되어 있는 커넥션을 참조하여 사용하게 된다.
- 커넥션 풀에 있는 커넥션을 요청하면 커넥션 풀은 자신이 가지고 있는 커넥션 객체 중 하나를 반환한다.
-> DB 드라이버를 통해 커넥션을 조회, 연결, 인증, SQL을 실행하는 시간 등 커넥션 객체를 생성하기 위한 과정을 생략할 수 있게 된다.
Connection Pool 장점
- 성능 향상: 미리 연결된 DB 연결을 Pool 에 유지하고, 요청이 들어올 때마다 해당 연결을 재사용함으로써 응답 시간을 단축하고 애플리케이션의 성능을 향상시킨다.
- 자원 관리: 연결을 생성하고 유지하는 데 필요한 자원을 최적화한다. 불필요한 연결을 만들지 않고, 연결을 재사용함으로써 메모리와 CPU 등의 자원을 효율적으로 관리할 수 있다.
- 동시성 관리: 동시에 여러 요청을 처리할 수 있는 연결을 제공하므로, 다수의 사용자가 동시에 애플리케이션에 접속해도 안정적으로 처리할 수 있다.
- 연결 풀링: 연결의 개수를 제한하고, 초과하는 요청이 들어올 경우 대기하도록 처리함으로써 데이터베이스 서버의 부하를 관리하고 과부하를 방지한다.
- 커넥션 오버헤드 감소: 반복적인 데이터베이스 연결/해제 작업에 따른 오버헤드를 감소시킨다.(커넥션 오버헤드 = DB 연결을 생성하고 해제하는 과정에서 발생하는 추가적인 비용과 부하)
Connection Pool 단점
- 리소스 사용: 일정 수의 연결을 미리 생성 및 유지해야 하므로, 메모리 등의 리소스를 일정 부분 소비한다.
- 설정 및 관리의 복잡성: 다양한 환경에서 최적의 성능을 발휘하기 위해서는 일정한 관리와 모니터링이 필요하다. 설정 파라미터의 조절이 필요한 경우에는 초기 설정 및 튜닝에 시간이 소요될 수 있다.
- 커넥션 누수: 애플리케이션에서 연결을 올바르게 반환하지 않거나 예외가 발생하는 경우, 커넥션 풀에서 연결이 제대로 반환되지 않을 수 있다. 이 경우 커넥션 누수가 발생할 수 있다.
Connection Pool 이 커지면 성능이 무조건 좋아질까?
커넥션 풀을 크게 설정하면,
많은 메모리를 사용하지만 동시에 많은 사용자가 대기 시간이 줄어들어 성능이 향상될 수 있다.
커넥션 풀을 작게 설정하면,
메모리 소모는 줄어들지만 동시 접속자가 많아지면 대기 시간이 길어질 수 있다.
따라서 커넥션 풀의 크기를 적절히 조절하여 최적의 성능을 유지해야 한다.
Connection Pool 의 적절한 크기
- 시스템 리소스 및 성능 모니터링: 시스템의 리소스 사용량과 성능을 모니터링하여 커넥션 풀의 최적 크기를 결정해야 한다.
ex) 메모리 사용량, CPU 부하, 네트워크 성능 등 - 부하 예측과 테스트: 애플리케이션의 부하 예측을 토대로 커넥션 풀의 크기를 조절하고, 실제 동작하는 환경에서 테스트하여 최적의 성능을 확인해야 한다.
대표 라이브러리

왜 DB에는 커넥션 풀을 쓰고 서버-서버 통신엔 안 쓸까?
사용자의 요청을 처리하는 데에는 서버-DB 간의 통신만 있는게 아니라 서버-서버 간의 통신도 많은데 왜 우리는 DB와의 연결에만 connection pool을 쓸까 하는 궁금증이 생겨나서 찾아보았다.

서버-서버 통신에는 '내장된 커넥션 풀'이 이미 존재한다. 또한 http 통신으로 이루어져 커넥션 풀이 필요할 만큼 부하가 크지 않다.

slow but steady