private void run() {
int baseNumber = 10;
// baseNumber++; 변경을 하는 순간 final이 아님
// 쉐도잉 : 내부에 선언한 변수로 바깥의 변수를 덮음
// 로컬 클래스
class LocalClass {
void printBaseNumber() {
int baseNumber = 11; // 변수 선언을 통해 값을 외부 값을 덮음(쉐도잉이 됨)
System.out.println(baseNumber);
}
}
// 익명 클래스
Consumer<Integer> integerConsumer = new Consumer<Integer>() {
@Override
public void accept(Integer baseNumber) { // 파라미터로 받아온 값으로 외부 값을 덮음(쉐도잉이 됨)
System.out.println("익명 클래스 : " + baseNumber);
}
};
// 람다(람다는 람다를 감싸고 있는 메소드와 같은 범위(scope)임 > 같은 이름으로 변수를 선언 할 수 없음)
IntConsumer printInt = (i) -> {
// 변수 선언이 안됨(컴파일 오류 - 쉐도잉이 안됨)
// int baseNumber = 33;
System.out.println("람다 : " + baseNumber);
};
}람다와 로컬/익명 클래스가 다른 하나는 변수의 범위(scope)에 대한 부분이다.
람다 : 람다가 속한 메소드와 같은 범위로 인식된다.
로컬/익명 클래스 : 로컬/익명 클래스와 속한 메소드의 범위가 다르다.
이와 같은 차이는 위 Code에서 보다시피 같은 이름의 변수 선언 가능여부로 확인된다.
로컬/익명 클래스는 범위가 다르기 때문에 같은 이름(baseNumber)으로 선언(할당x)해도
컴파일 에러가 나지 않는다.
하지만 람다 내부에서 같은 이름으로 선언하게 되면 같은 이름의 변수가 이미 선언되었다며
컴파일 에러가 발생한다.
쉐도윙(Shadowing)이란 마치 그림자가 물체를 덮는 것처럼
내부에 선언한 변수로 외부의 변수 값을 덮는 것으로 람다는 변수의 범위로 인해 쉐도윙이 되지않는다.
또한 람다에는 다음과 같은 변수 규칙이 있는데
- 람다식은 외부 block 에 있는 변수에 접근할 수 있다.
- 외부에 있는 변수가 지역 변수 일 경우 final 혹은 effectively final 인 경우에만 접근이 가능하다.
출처 : https://vagabond95.me/posts/lambda-with-final
위 코드에서는 final이라는 키워드를 명시적으로 사용하지 않았다.
하지만 한번 값을 선언하고 변경하지 않으면 암묵적으로 컴파일러는 이를 final로 간주하는데
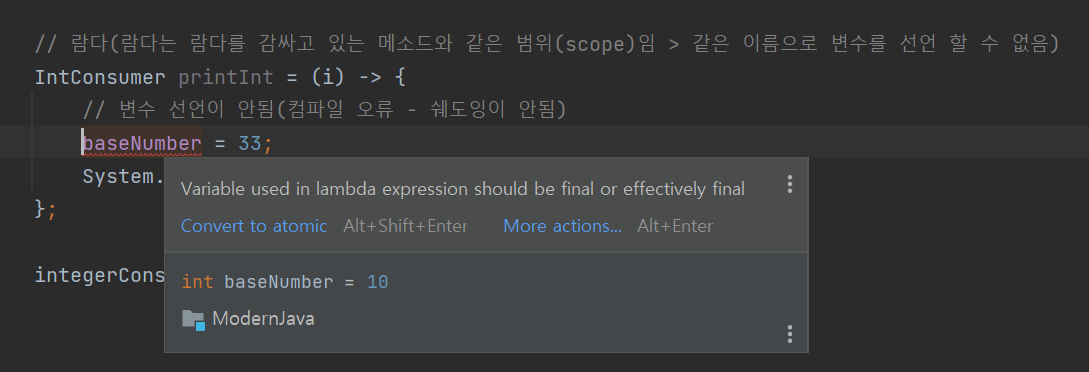
만약 변경한다면 final 변수가 아니게되고
람다에서는 외부 변수로는 final만 가능하기 때문에 컴파일 에러가 발생한다.
final한 값만을 사용해야 하는 이유에 대해 설명하신 글(https://vagabond95.me/posts/lambda-with-final)을 통해 이해하자면 메소드 간에 지역 변수값 공유(sync)는 stack 영역에서의 문제이기 때문에 불가하여
애초에 이를 변경하지 못하게 막았다는 것으로 이해했다.
위 글에 따르면 global 변수나 static 변수는 stack 영역이 아닌 공통 영역에 있는 값이라
람다에서도 변경이 가능하다고 한다.
public class Greeting {
String name;
public Greeting() {};
public Greeting(String name) {
this.name = name;
}
String getName() {
return name;
}
static void hi(String name) {
System.out.println("hi " + name);
}
void hello(String name) {
System.out.println("hello " + name);
}
static String returnHiString(String name) {
return "hi " + name;
}
String returnHelloString(String name) {
return "hello " + name;
}
}다음으로 메소드 레퍼런스(Method Reference)를 설명하기 위한 코드들이다.
메소드 레퍼런스는 말 그대로 메소드를 참조하는 것으로 함수형 인터페이스에서
실제 구현부를 일일히 작성하는 것이 아니라 다른 메소드를 가져와 사용하는 것을 말한다.
(위 코드에서 Greeting은 참조할 메소드들이 있는 클래스이다.)
// :: 다른 인스턴스의 메소드를 참조해서 사용하겠다는 의미
// static 메소드 사용(인스턴스 생성 필요없음)
Function<String, String> returnHiString = Greeting::returnHiString;
System.out.println(returnHiString.apply("minwoo"));
UnaryOperator<String> returnHiString2 = Greeting::returnHiString;
System.out.println(returnHiString2.apply("minwoo"));
Consumer<String> hiAction = Greeting::hi;
hiAction.accept("minwoo");메소드 중에서 static 메소드와 instance 메소드를 참조하는 방식이 다른데
먼저 static 메소드의 경우 인스턴스 생성(new)가 필요 없으므로
바로 클래스명::메소드 명으로 참조하여 사용이 가능하다.
함수형 인터페이스는 input/output에 따라 구분하여 받아 줄 수 있다.
Function<in, out> / UnaryOperator<in&out> / Consumer<in> / Supplier<out>
(함수형 인터페이스로 받아주고 apply(), accept(), get() 메소드를 사용해야 동작한다!)
// 인스턴스 메소드를 사용할 경우
Greeting greeting = new Greeting();
Function<String, String> returnHelloString = greeting::returnHelloString;
System.out.println(returnHelloString.apply("minwoo"));
UnaryOperator<String> returnHelloString2 = greeting::returnHelloString;
System.out.println(returnHelloString2.apply("minwoo"));
Consumer<String> helloAction = greeting::hello;
helloAction.accept("minwoo");instance 메소드는 위와 유사하지만 클래스를 new 키워드 등을 통해 인스턴스화 한 후
인스턴스 객체::메소드명 방식으로 사용하는 것이 다르다.
// 기본 생성자(no param)로 만들 때
Supplier<Greeting> defaultGreeting = Greeting::new;
Greeting greetingInstance = defaultGreeting.get(); // get()을 해줘야 객체가 생성됨
greetingInstance.hi("minwoo");
// 초기값이 있는 생성자(param)로 만들 때
Function<String, Greeting> paramGreeting = Greeting::new;
Greeting paramInstance = paramGreeting.apply("minwoo");
System.out.println(paramInstance.getName());생성자도 기본적으로 메소드이므로 메소드 레퍼런스를 통한 생성이 가능하다.
기본 생성자의 경우 초기값이 없기 때문에 Output만 있는 Supplier<out>가 적합한데
객체의 생성은 get()하는 시점이므로 이를 빼먹지 않도록 주의해야 한다.
// 임의 객체의 인스턴스 메소드 참조
String[] names = {"bbb", "ccc", "aaa"};
Arrays.sort(names, new Comparator<String>() { // @FunctionalInterface
@Override
public int compare(String s1, String s2) {
return 0;
}
});
Arrays.sort(names, (s1, s2) -> 0);
// 임의의 객체(String)의 인스턴스 메소드인 compareToIgnoreCase 메소드(static이 아님)를 참조하여 사용
Arrays.sort(names, String::compareToIgnoreCase);
System.out.println(Arrays.toString(names)); // [aaa, bbb, ccc]앞에서는 객체를 지정하여 해당 객체의 내부 메소드를 사용했다면
위의 Code는 임의의 객체를 사용하여 그 내부 메소드를 참조하는 방법이다.
기존에 Comparator가 함수형 인터페이스이기 때문에 아래와 같이 간단하게 쓰는 것도 가능하고
names의 각 문자열(String)이 하나의 객체라고 하였을 때 String 객체 내의 compareToIgnoreCase() 메소드를 사용하여 sort() 메소드의 두번째 인자인 정렬 인자를 줄 수도 있다.

람다를 공부하면서도 이게 어떻게 쓰일지 감이 안와서 좀 답답한 느낌이 들었다.
왜 굳이 새로운 방식으로 가끔은 더 복잡하게도 쓰는 것 같아서 의아함이 들기도 했고...
찾아보니 람다의 장단점이 있으니 상황에 따라 맞게 쓰는 것이 베스트인 것 같다.(https://junghn.tistory.com/entry/JAVA-%EB%9E%8C%EB%8B%A4%EC%8B%9DLambda-Expressions%EC%9D%B4%EB%9E%80-%EC%82%AC%EC%9A%A9%EB%B0%A9%EB%B2%95-%EC%9E%A5%EB%8B%A8%EC%A0%90)
하지만 '장인은 도구 탓을 하지 않는다'는데 나는 도구도 잘 모르겠으니 탓할 것이 없다.
적어도 일단 정리해두면 남이 쓴 람다 Code를 이해는 하며 배울 수 있다고 생각해본다!
