분야
이 논문은 Monocular image에서 3d mesh(pose)를 estimate하는 분야의 논문입니다.
문제 제기
이 논문에서는 3d human pose estimation을 하는 기존의 방법의 문제점을 제기하면서 시작합니다. 3D human mesh estimation 분야는 많은 발전이 있었으나 사람들이 많이 모여있는(crowded) 상황에서는 고전을 면치 못하고 있습니다. 이 논문에서 주장하는 이러한 실패의 이유는 다음과 같습니다.
첫번째 이유: Domain Gap
이 논문에서 crowded scene에서의 estimation을 실패하는 이유중 하나로 지목한 것은 training set과 test set사이의 domain gap입니다. Train 하는데 사용된 데이터셋 중 하나인 MoCap dataset은 motion capture를 하여 만든 데이터셋으로 train을 위한 3d label이 잘 주어져 있습니다. Motion capture 방식의 특성상 crowded한 상황을 만들어내는 것이 어렵고 그렇기 때문에 실제 테스트 환경에서의 사람들의 분포정도가 다릅니다. 그렇기 때문에 crowded scene에서의 feature을 적절히 뽑아내지 못한다고 이 논문에서 주장합니다.
두 번째 이유: Feature processing 하는 방법의 문제
Localized된 bounding box들에 대하여 기존에 deep-CNN 구조를 가지는 feature extractor를 사용하여 feature들을 뽑아냈는데, 이러한 feature extractor는 마지막에 global average pooling을 이용합니다. 이러한 구조는 spatial information의 collapse를 일어나게 하고 그로 인해 target 사람의 feature와 non-target를 구별하지 못하게 만드는 문제를 발생시킵니다. Crowded scene에는 여러 사람이 겹치는 경우가 빈번하게 발생하고 아무리 bounding box를 정밀하게 조정한다고 해도 여러 사람이 겹치는 bounding box가 생길 수 밖에 없습니다.(Bounding box는 원래 사람마다 한개씩 assign이 되도록 하는게 원래 의도) 그러면 non target feature도 같이 추출이 되는데, global average pooling으로 인해 target feature와 함께 non target feature도 같이 평균으로 계산되어 영향을 주게 됩니다.
해결방법
Domain Gap에 대한 해결방안
Domain Gap이 생기는 이유는 MoCap 같은 dataset은 3d labeling이 되어있고 croded scene이 많지 않지만, 실제 데이터들은 3d label이 없을 뿐더러 crowded scene들도 빈번하게 등장합니다. 그래서 이를 해결하기 위해 논문의 저자들은 "2d pose estimator"를 사용하여 feature를 추출합니다. Feature extractor로 2d pose estimator를 사용하였기 때문에, 3d labeling이 되어있지 않은 실제 환경에서의 데이터 환경에서 크게 영향받지 않고 유의미한 feature를 뽑아낼 수 있습니다. 또한 2d pose esitmator는 MoCap 같은 3d labeled dataset으로 학습된 것이 아니기 때문에, 실제 테스트 환경과 더 유사한 환경에서 학습된 것이 이러한 domain gap을 줄였다고 주장합니다.
Spatial feature collapsing에 대한 해결방안
단순히 Deep-CNN 기반의 feature extractor만을 사용하는 것이 아닌 joint-based regressor를 이용하여 이 문제를 해결했다고 주장합니다. Joint-based regressor는 말 그래도 image에 있는 사람의 joint(관절)를 기반으로 feature를 추출하는 모델입니다. Joint-based regressor로 우선 joints들의 spatial locations을 예측하고 images에 있는 feature를 deep-CNN 기반의 extractor를 이용해서 뽑아낼 때, joint의 위치를 참고하여 추출하는 것입니다. 이를 이용하여 spatial feature를 유지하면서 pose estimation을 가능하게 한다고 논문의 저자들은 주장합니다.
모델 overview
전반적인 pipline에 대한 설명
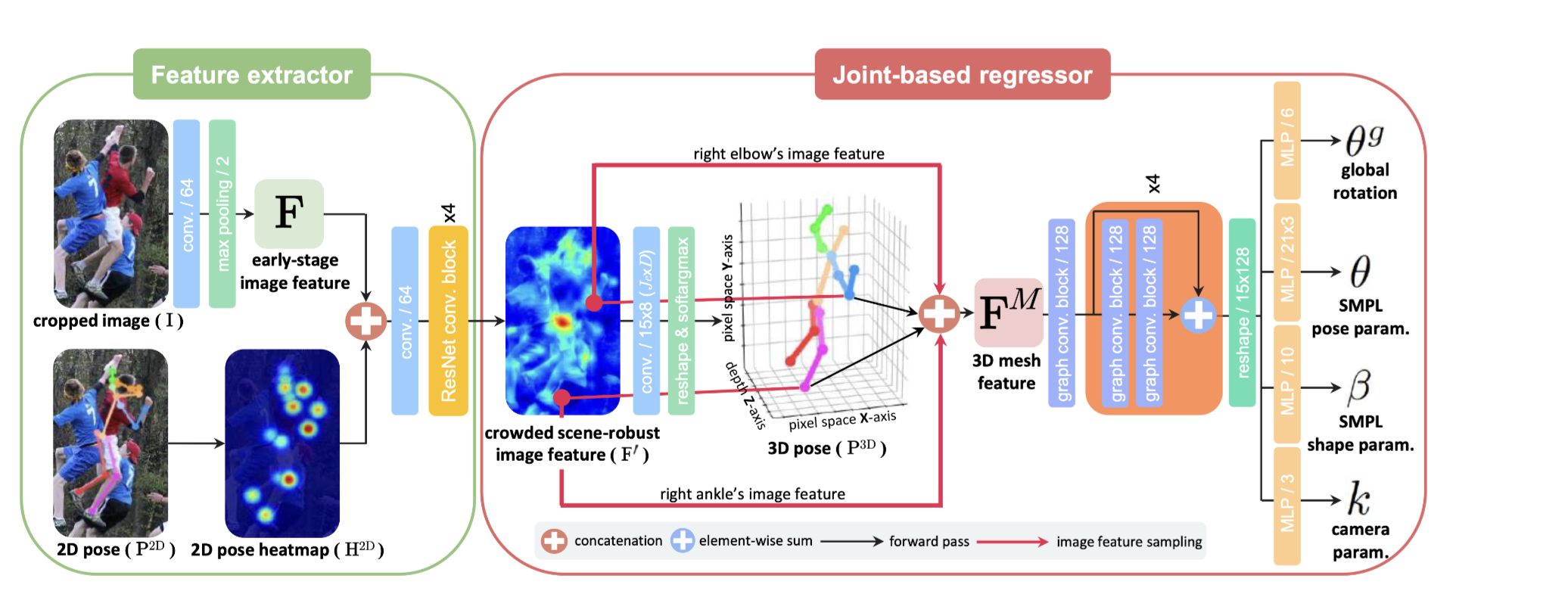
[출처: 3dcrowdnet 논문 figure 2]
3DCrowdNet은 input에서 사람이 있는 영역의 bounding box들을 잡고(가능한 작게 잡습니다) 이들을 crop합니다. Cropped된 이미지와 cropped된 이미지를 가지고 2d joints를 예측한 joints map이 이 모델의 input이 됩니다.
Cropped image를 가지고 early image feature를 backbone(논문에서는 Resnet-50 사용)으로 뽑아냅니다. 그리고 joint map(그림에서는 2D pose )을 가지고 2d gaussian heatmap을 만들어 냅니다.
위에서의 early image feature와 joint heatmap을 concat하여 이를 resnet 기반 backbone으로 feature extraction을 합니다. 논문에서 주장한 바에 따르면 joint를 가지고 feature extraction을 했기 때문에, spatial information이 무너지지 않고 유지될 수 있습니다. 이렇게 뽑아낸 feature를 pose guided image feature라고 부릅니다.
이러한 pose guided image feature를 가지고 position network를 이용해 3d joint image와 3d joint score를 계산합니다.
그 후 pose guided image featue, joint coord, joint score를 가지고 모델 파라미터들을 추정합니다. 이를 추정하는데에는 rotation network를 이용합니다. 이들은 SMPL 모델의 pose와 shape parameter, camera parameter, pose의 rotation에 대한 parameter들 입니다. 그렇게 추정한 parameter를 가지고 SMPL모델로 최종 human pose를 inference 합니다. 여기서 rotation network으로 뽑아낸 pose param을 다시 한번 vposer에 forward한 결과에 root pose를 concat하여 pose param을 예측합니다.
Position network
position network란 pose guided image feature를 가지고 3d joint image와 3d joint score를 예측하는 네트워크 입니다. 우선 input으로 들어온 pose guided image feature를 convolution layer를 통과시켜 3d joint heatmap을 만들고 이를 soft argmax 3d를 적용하여 heatmap의 peek가 나오게 하는 좌표값 즉 3d joint coordinate를 추정합니다. 또한 joint heatmap을 가지고 joint score를 계산하는데(아마 inference한 joint들에 대한 평가 점수 정도 되지 않을까 생각합니다. 오피셜 아님) 그리고 구한 joint coordinate들과 joint score를 return 합니다.
Rotation network
Rotation network는 pose guided image feature, joint coordinate 그리고 joint score를 가지고 root pose, SMPL pose parameter, SMPL shape parameter, camera parameter를 추정하는 네트워크입니다.
pose guided image feature와 joint coordinate를 가지고 joint feature를 뽑아내고, 이들과 joint coordinate, joint score를 가지고 최종 feature를 만들고 이 feature를 residual graph convolution network를 여러겹 쌓아서 만든 네트워크를 통과시켜 feature를 update합니다. update된 feature를 slicing 하여 root pose, pose param, shape param, cam param을 return 합니다.
네트워크 학습
loss function
최종 loss는 pose에 대한 loss와 mesh에 대한 loss로 이루어집니다. 여기서 mesh에 대한 loss란 global rotation parameter(), 예측한 pose parameter(), shape parameter()와 pseudo-GT parameter에 대한 distance()와 predicted mesh들과 regressed된 joints들 간의 distance()입니다. 그리고 pose에 대한 loss란 joint에 대한 pseudo GT와 예측한 joint들의 좌표들의 L1 distance 입니다. 2D anootions들로 supervised training을 하기 위해 camera parameter 를 가지고 projection 과정을 거쳐서 학습합니다. Pseudo GT는 선행논문 (Gyeongsik Moon and Kyoung Mu Lee. NeuralAnnot: Neural annotator for in-the-wild expressive 3D human pose and mesh training sets. arXiv preprint arXiv:2011.11232, 2020)와 (Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3D hands, face, and body from a single image. In CVPR, 2019)를 이용하여 구한 값입니다.(추후에 읽어보고 공부할 예정)
성능 평가
MPJPE, PA-MPJPE
MPJPE는 Mean Per Joint Position Error의 줄임말로 말 그대로 joint 위치당 평균 오차입니다.
PA-MPJPE는 Procrustes analysis를 추정된 joint와 GT joint에 적용한 후 이에 대한 MPJPE를 구한 것입니다.
결국 MPJPE, PA-MPJPE는 GT와 prediction간에 자세가 얼마나 유사한지를 나타내는 척도이다. 이 값들이 작을수록 GT와 자세(pose)가 유사하다는 의미입니다.
MPVPE
MPVPE는 Mean Per Vertex Position Error의 줄임말로, GT를 이루는 mesh들의 vertex의 position과 추정한 mesh의 vertex들의 평균 오차를 뜻합니다.
예상할 수 있겠지만 MPJPE, PA-MPJPE, MPVPE가 다른 모델보다 더 좋다는것이 결론입니다.
그 외에도 저자들은 모델을 구성하는 구성요소중 어떠한 부분을 제거할 때 성능에 어떤 영향을 미치는지에 대한 ablation study도 진행하였습니다. 그랬을때도 다른 모델보다 성능이 좋다는 결과가 나왔습니다.
