
개요
백테스트를 할 때, db에서 매번 데이터를 읽어와 처리하도록 구현했다. 속도가 너무 느렸고 가져와야 할 데이터의 양이 많아질수록 속도가 더 심해졌다. 어떻게 처리하면 좋을지 찾아보던 중에 parquet라는 파일을 사용하면 데이터를 빠르게 읽어올 수 있다는 것을 알았다.
parquet 파일 생성하기
polars를 사용했다.
// cargo.toml
polars = { version = "0.53.0", features = ["parquet", "lazy", "sql", "serde", "serde-lazy"] } async fn test_2024_candles_to_parquet() -> anyhow::Result<()> {
let connection_string = "postgresql://postgres:2677@192.168.1.114:5432/postgres";
let db = DbClient::new(connection_string).await?;
// 2024년 데이터 가져오기 (limit 없이 모든 데이터)
let candles = db.get_candles_1m_by_range("BTCUSDT", 2024, 2024).await?;
println!("2024년 데이터 개수: {}", candles.len());
// FlattenedCandles로 변환
let flatten_candles: FlattenedCandles = candles.into();
// DataFrame 생성
let mut df = df!(
"times" => &flatten_candles.times,
"opens" => &flatten_candles.opens,
"highs" => &flatten_candles.highs,
"lows" => &flatten_candles.lows,
"closes" => &flatten_candles.closes,
"volumes" => &flatten_candles.volumes,
)?;
println!("DataFrame 생성 완료:");
println!("{}", df);
// Parquet 파일로 저장
let file = std::fs::File::create("../../parquet/2024_1m_candles.parquet")?;
ParquetWriter::new(file).finish(&mut df)?;
println!("✅ 2024년 캔들 데이터를 parquet 파일로 저장 완료!");
Ok(())
}polars는 컬럼 베이스이다. db에서 데이터를 읽어와 soa 구조로 변경하고 df! 매크로를 사용해 dateframe을 만들어주었다. 생성한 후 parquet파일을 생성해 주었다.
parquet 파일 읽어오기
parquet module을 만들어 읽어오는 함수를 만들었다.
pub fn read_parquet_data(file_name: &str) -> anyhow::Result<FlattenedCandles> {
// 1. parquet file을 읽는다.
// 2. 읽은 df를 rust 객체로 변환한다 (soa -> soa)
let start_read_parquet = Instant::now();
let relative_path = format!("../../parquet/{}", file_name);
let df_read =
LazyFrame::scan_parquet(relative_path.as_str().into(), Default::default())?.collect()?;
let elapsed_read_parquet = Instant::now() - start_read_parquet;
println!(
"read parequet | elapsed: {}ms",
elapsed_read_parquet.as_millis()
);
let start_convert_faltten_candles = Instant::now();
let flattened_candles = FlattenedCandles::new_with_df(&df_read)?;
let elapsed_convert_faltten_candles = Instant::now() - start_convert_faltten_candles;
println!(
"start_convert_faltten_candles | elapsed: {}ms",
elapsed_convert_faltten_candles.as_millis()
);
Ok(flattened_candles)
}parquet파일을 읽어오는 시간과 rust 객체로 맵핑하는 시간을 계산해보았다. polars의 강력한점은 lazy하게 데이터를 읽을 수 있다. 테스트 단계이므로 collect를 통해 메모리에 파일에 있는 데이터를 전부 올렸다.
polars의 강력한 점
현재 장비가 가용 가능한 메모리보다parquet의 데이터가 훨씬 크더라도 lazy하게 처리하기에 사용이 가능하다.stream으로 처리하는 것은 추후 테스트해볼 예정이다.
생성한 parquet 파일을 읽어서 rust의 객체로 맵핑하는 테스트를 하여 elapsed타임을 측정했다.

2024년도의 1년치 1분봉 데이터인 약 540,000개의 데이터를 읽어 메모리에 올리는데 무려 97ms의 시간이 걸렸다.
비교를 위해서 db에서 2024년도의 1분봉 데이터를 읽어오는 테스트를 진행했다. 최적화를 하지는 않았다는 것을 감안해서 봐야한다.

| 데이터 소스 | 소요 시간 (ms) | 비고 |
|---|---|---|
| Parquet | 97 ms | 가장 빠름 |
| 데이터베이스 (DB) | 4,608 ms | - |
분석 결과: Parquet 포맷 사용 시 DB 대비 실행 시간이 약 97.9% 감소했습니다.
백테스팅 속도 비교
parquet을 사용한 케이스는 2024년도 데이터를 사용했고, db의 경우 현재부터 1년치 데이터를 사용했기에 데이터는 다를 수 있다.
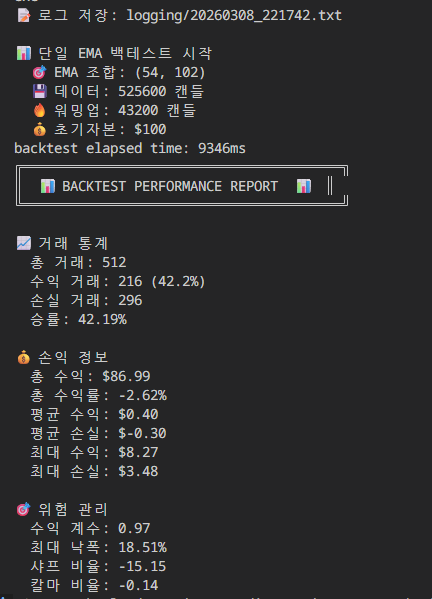
백테스팅 db 데이터
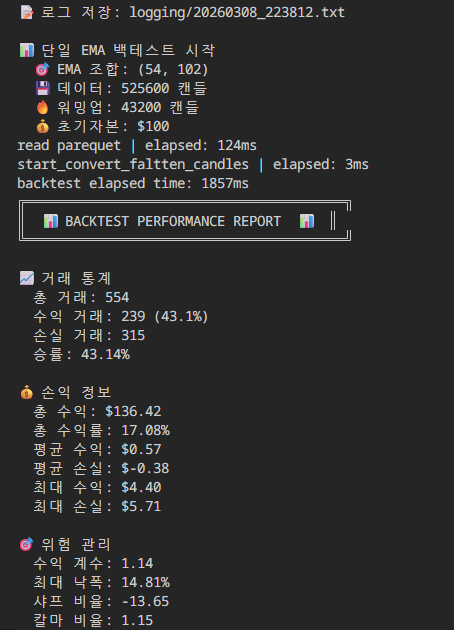
백테스팅 parquet 데이터
백테스팅 실행 속도 비교 (전체 프로세스)
| 테스트 환경 | 소요 시간 (ms) | 초 단위 변환 | 성능 향상 |
|---|---|---|---|
| Database (PostgreSQL) | 9,346 ms | 약 9.35초 | 1.0x (기준) |
| Parquet (Local) | 1,857 ms | 약 1.86초 | 약 5.03x 🚀 |
Insight: 데이터 로딩 속도의 혁신이 전체 백테스트 사이클 시간을 80.1% 감소시켰습니다.
결론
parquet를 사용해서 비약적인 성능 향상을 시켰다. 특히 OHLC데이터의 경우 이전 데이터는 수정할 일이 없으므로 데이터 베이스에서 가져오는 것보다 각 기간별로 parquet 데이터로 만들어 사용하는 것이 더 효과적인 것 같다. 특히 여러 데이터를 빠르게 테스트하기 위해서는 더욱 중요한 것 같다.
개선해야 할 문제점으로는 parquet는 컬럼 베이스 데이터인데 억지로 aos 형식으로 rust 객체로 맵핑하는데 약 100ms의 오버헤드가 발생하고 있다. 알고리즘 또한 soa 방식을 사용하여 처리하는 식으로 바꾸면 더욱 효과적일 것 같다. 물론 상태를 저장해야 하는 경우에는 soa의 경우 지나치게 복잡해질 수 있으므로 그 점을 고려하여 개선해 볼 예정이다.
성능이 우수한 backtest 엔진을 먼저 만든 뒤, 여러 전략을 테스트해 봐야겠다.
