개요
글로벌하게 이름이 중복되어서는 안되는 경우가 있다. db가 아닌 인 메모리 형식으로 데이터를 가지고 있어야 한다. 데이터를 담아두는 방식에 따라서 중복 검사의 속도가 엄청나게 차이 날 수 있다는 것을 알았다.
내용
rust의 Vec과 HashSet을 비교해 볼 예정이다. 1,000,000개의 넣어주고 contains 메서드를 호출하여 중복 값이 존재하는지 찾아보겠다.
Vector
fn main() {
// 1. 데이터 약 10만개의 string 이름을 가지는 vector를 생성한다.
// 2. full scan을 해서 해다 이름이 있는지 검사한다?
let mut name_list: Vec<String> = Vec::new();
for i in 0..1_000_000 {
name_list.push(format!("test_name_{}", i));
}
let start = Instant::now();
if name_list.contains(&"test_name_999999".to_string()) {
println!("중복된 이름 있음");
} else {
println!("중복 없음");
}
let elapsed = Instant::now() - start;
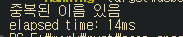
println!("elapsed time: {}ms", elapsed.as_millis());
}
HashSet
fn main() {
// 1. hashset에 데이터 100,000 개를 넣어준다.
// 2. 특정 이름이 중복인지 검사한다.
let mut hash_set: HashSet<String> = HashSet::new();
for i in 0..1_000_000 {
hash_set.insert(format!("test_name_{}", i));
}
let start = Instant::now();
if hash_set.contains("test_name_999999") {
println!("중복된 이름 있음");
} else {
println!("중복 없음");
}
let elapsed = Instant::now() - start;
println!("elapsed time: {}ms", elapsed.as_millis());
}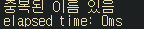
HashSet의 찾는 속도는 0ms가 나오는 것을 확인할 수 있다. 데이터가 더 늘어나더라도 똑같은 결과가 나온다. 찾으려는 키가 들어오면 해시 함수를 통해 메모리의 특정 주소를 즉시 계산해내고 그 주소로 바로 이동을 하여 찾기 때문에 데이터의 총량은 검색 시간에 영향을 끼치지 않는다.
결론
개발을 하면서 사용하기 편한 Vec을 자주 사용했다. 어떤 목적을 가지고 사용하는지도 생각을 좀 하면서 사용해야겠다.
