본 Paper Review는 고려대학교 스마트생산시스템 연구실 2024년 동계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다
Abstract
앙상블: 머신러닝의 성능을 향상시키는 간단한 방법으로 한 데이터 셋을 여러 다른 모델에서 훈련한 뒤, 그 결과의 평균을 내어 예측하는 것
앙상블 문제점
- 여러 모델의 앙상블을 사용하면 예측이 번거러움
- 개별 모델이 큰 신경망인 경우 계산 비용이 매우 높아지는 문제 존재
본 논문의 제안
- Knowledge Distillation 방법: 앙상블의 지식을 단일 모델로 압축하는 것
1. Introduction
- 대규모 기계 학습에서 훈련 단계와 배포 단계 간에 요구 사항이 다름
- 학습에는 대규모 데이터셋을 사용하여 구조를 추출
- 실시간 작동 및 많은 계산이 필요하지 않으며, 배포는 지연 시간과 계산 리소스에 더 엄격한 요구 사항이 있다고 언급함
본 논문은 복잡한 모델을 훈련한 후, 이를 "distillation"이라는 새로운 종류의 훈련을 사용하여 배포에 더 적합한 작은 모델로 지식을 전송하는 방법을 제안
대규모 모델의 지식을 작은 모델로 전송할 수 있다는 것을 입증
본 논문은 또한 학습된 모델의 지식을 학습된 매개변수 값과 동일하게 식별하는 것이 어려워지는 문제를 해결하기 위해 학습된 모델의 지식을 입력 벡터에서 출력 벡터로의 학습된 매핑으로 봐야 한다는 추상적인 시각을 제시
특히, 대규모 모델은 많은 클래스 간의 차이를 학습하므로 정상적인 훈련 목표는 올바른 답의 평균 로그 확률을 최대화하는 것이지만, 학습의 부작용으로 올바르지 않은 답에 대한 확률도 할당 됨
복잡한 모델의 일반화 능력을 작은 모델로 전송하기 위한 한 가지 방법
-> 복잡한 모델이 생성한 클래스 확률을 "soft targets"로 사용하는 것을 제안
이러한 soft targets의 엔트로피가 높을수록 각 훈련 케이스 당 더 많은 정보를 제공하고 훈련 사례 간의 그래디언트 변동이 훨씬 적기 때문에 작은 모델은 원래 복잡한 모델보다 훨씬 적은 데이터에서 높은 학습률로 훈련될 수 있음
논문은 "distillation"이라는 일반적인 솔루션을 제시
이는 복잡한 모델이 적절한 soft targets을 생성하도록 최종 softmax의 온도를 높이는 것
이후 작은 모델을 훈련할 때도 동일한 높은 온도를 사용하여 이러한 soft targets과 일치시킴
논문은 나중에 복잡한 모델의 로짓을 일치시키는 것이 사실상 "distillation"의 특별한 경우임을 보여줌
최종적으로, 작은 모델을 훈련하기 위해 사용되는 전송 세트는 미정 레이블 데이터로만 구성있는 될 수도 있고, 원래 훈련 세트를 사용할 수도 있으며, 이 때 소규모 모델이 소프트 타겟을 일치시키는 동안 작은 항목을 추가하여 정확한 답을 예측하도록 유도할 수 있음
2. Distillation
신경망은 일반적으로 "softmax" 출력 레이어를 사용하여 각 클래스에 대해 계산된 logit, 를 확률 로 변환함
softmax 식은 아래와 같음
여기서 T는 온도를 나타내며, 일반적으로 1로 설정함
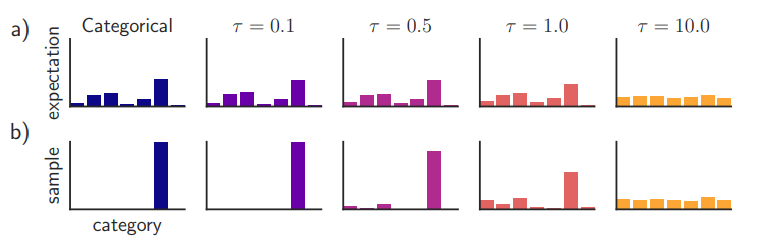
Temperature에 따른 softmax 확률값 (출처 : https://arxiv.org/pdf/1611.01144.pdf)
T 값이 높을수록 클래스 간의 확률 분포가 더 부드러워짐간단한 형태의 지식 전송인 Distillation
: 지식은 전달 모델을 전송 세트에 대해 훈련시킴으로써 이루어지며, 제안하는 Distillation 구조는 아래와 같음
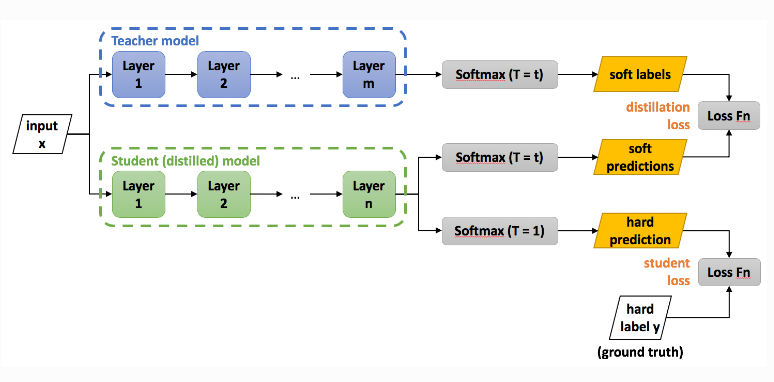
Knowledge Distillation 구조 (출처 : https://intellabs.github.io/distiller/knowledge_distillation.html)
각 전이 세트의 경우에 대해 얻어진 소프트 타겟 분포는 복잡한 모델의 softmax에서 높은 온도를 사용하여 생성
훈련된 후, 동일한 높은 온도를 사용하여 전이 모델을 훈련하지만, 훈련이 완료된 후에는 온도를 1로 설정
전이 세트의 모든 또는 일부에 대해 올바른 레이블이 알려진 경우,
이 방법은 소프트 타겟을 생성하는 복잡한 모델로부터 올바른 레이블을 생성하도록 전이 모델을 훈련시킴으로써 효과적으로 개선될 수 있음
한 가지 방법은 올바른 레이블을 사용하여 소프트 타겟을 수정하는 것이지만, 논문에서는 두 가지 서로 다른 목적 함수의 가중 평균을 사용하는 것이 더 효과적이라고 언급
첫 번째 목적 함수는 소프트 타겟과의 cross entropy이며, 이 교차 엔트로피는 전이 모델의 softmax에서 소프트 타겟을 생성할 때 사용된 것과 동일한 높은 온도로 계산
두 번째 목적 함수는 올바른 레이블과의 cross entropy이며, 이는 전이 모델의 softmax에서 정확히 동일한 로짓을 사용하지만 온도가 1인 상태에서 계산
실험 중에 distillation에 사용되는 온도를 변경하면서 하드 및 소프트 타겟 모두를 사용할 때, 소프트 타겟이 생성하는 그라디언트 크기는 로 스케일되기 때문에 이 값을 T^2로 곱해주는 것이 중요함
이렇게 함으로써 distillation에 사용되는 온도를 변경할 때 하드 및 소프트 타겟의 상대적인 기여가 대략 변경되지 않도록 보장함
2.1 Matching logits is a special case of distillation
식 (2)에서는 온도 T 에 따른 cross entropy의 변화 즉, 그라디언트는 아래와 같이 표현
식 (3)에서는 logit의 크기에 비해 온도가 높을 경우에 근사화한 것
여기서는 로짓이 각 전이 케이스에 대해 개별적으로 zero-meaned(평균이 0이 되도록)되었다고 가정하여 간소화한 식 (4)를 얻음
높은 온도(T가 큰 상황)에서, distillation은 거의 모든 logit을 매치시키는 것이 거의 같다고 볼 수 있음
logit이 각 전이 케이스에 대해 개별적으로 zero-meaned되었다는 가정 하에서 1/2(zi − vi)²을 최소화하는 것과 동등함
그러나 낮은 온도(T가 작은 상황)에서는 cross entropy 그라디언트가 평균보다 훨씬 더 작은 logit에 대해 훨씬 덜 중요하게 되며, 이는 이러한 logit이 학습 중에 거의 제약이 없었을 수 있으므로 매우 노이지하게 작동할 수 있다는 가능성이 있음
그러나 매우 작은 logit이 복잡한 모델이 얻은 지식에 관한 유용한 정보를 전달할 수도 있음
결론적으로 본 논문은 distillation이 복잡한 모델에서 얻은 지식을 완벽하게 잡아내기에는 너무 작은 경우에는 중간 온도가 가장 효과적이라는 것을 실험을 통해 보여주며, 이는 큰 음의 로짓을 무시하는 것이 도움이 될 수 있다는 강력한 힌트로 받아들일 수 있음
3. Preliminary experiments on MNIST
주어진 다변량 시계열 데이터에 대한 문제 정의
-
예측 작업은 주어진 이전 시계열 세그먼트로 부터 다음 k 단계의 값을 예측
-
분류 작업은 각 시계열 인스턴스 X에 대해 해당하는 범주형 라벨 집합 C로 매핑
3.2 MODEL ARCHITECTURE
MNIST 데이터셋
60,000개의 훈련 데이터에 대해 두 가지 모델을 사용
복잡한 신경망 모델 1200 ReLU를 가지는 두 개의 은닉층을 사용, dropout과 weight constraints를 적절히 사용
간단한 신경망 모델 800 ReLU를 가지는 두 개의 은닉층을 사용, 추가적인 학습 기법은 활용하지 않음
테스트 이미지에 대하여
- 복잡한 신경망 모델은 67개의 오류 달성
- 간단한 신경망 모델은 146개의 오류 달성
- 복잡한 신경망 모델의 지식을 T = 20으로 간단한 신경망 모델에 지식 증류를 했을 때, 74개의 테스트 오류를 달성
소프트 타겟이 번역된 훈련 데이터로부터 학습한 일반화 방법에 관한 지식을 전송할 수 있음을 보임
전이 세트에서 숫자 3의 예제를 모두 생략

MNIST without "3" (출처 : https://url.kr/s534kt)
전이 모델은 테스트 세트에서 206개의 오류
이 중 133개는 테스트 세트의 1010개의 숫자 3에서 발생
대부분의 오류는 숫자 3 클래스에 대한 학습된 편향이 너무 낮기 때문에 발생
이 편향을 3.5만큼 증가시키면, 전이 모델은 109개의 오류를 만듦
그 중 14개는 숫자 3에 대한 오류
따라서 올바른 편향을 가지면 전이 모델은 훈련 중에 3을 본 적이 없어도 테스트 3의 98.6%를 올바르게 예측함
마지막으로, 전이 세트에는 훈련 세트의 7과 8만 포함된 경우 전이 모델은 47.3%의 테스트 오류를 발생
그러나 7과 8의 편향을 최적화하기 위해 감소시킨 경우, 테스트 오류는 13.2%로 감소함
4. Experiments on speech recognition
- 음성 인식을 위해 사용되는 Deep Neural Network (DNN) 음향 모델에 대한 앙상블링하는 방법으로 실험 진행
- 논문에서 제안한 distillation 전략이 앙상블 모델을 단일 모델로 정제하여 동일한 규모의 모델보다 훨씬 효과적으로 작동함을 보여줌
본 논문에서 사용된 DNN 음향 모델은 8개의 은닉 레이어로 구성되어 있으며 각 레이어에는 2560개의 ReLU 활성화 함수가 있으며 최종 softmax 레이어에는 14,000개의 레이블 (HMM targets)이 있음
입력은 40개의 Mel-스케일된 필터 뱅크 계수로 이루어진 26프레임이며, 각 프레임마다 10ms 간격으로 이동하며 21번째 프레임의 HMM 상태를 예측함 (총 매개변수 수는 약 85M)
훈련에는 약 2000시간의 영어 음성 데이터를 사용하며 약 700M개의 훈련 예제를 얻음
이 시스템은 개발 세트에서 58.9%의 프레임 정확도와 10.9%의 Word Error Rate (WER)를 달성
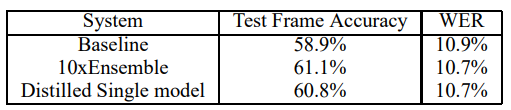
Frame Accuracy 및 Word Error Rate (WER) 측면에서 distillation을 통한 모델이 좋은 성과를 보여주고 있으며, Distillation이 앙상블된 모델의 지식을 효과적으로 단일 모델로 전달하여 성능을 향상시킬 수 있다는 가능성을 보여줌
4.1 Results
실험에서 동일한 아키텍처와 훈련 절차를 사용하여 를 예측하기 위해 10개의 별개의 모델을 훈련
모델 간의 다양성을 추가하기 위해 각 모델이 보는 데이터 세트를 변형시켜보았지만, 이는 결과에 별다른 영향을 주지 않았으며, 따라서 간단한 방식을 선택함
distillation에는 T = [1, 2, 5, 10] 를 사용하며 Hard target에 대한 cross entropy 에 대한 상대적인 가중치는 0.5로 설정함
10개 모델의 앙상블을 사용한 프레임 분류 정확도에서 얻은 개선의 80% 이상이 distillation을 통해 전이되었으며, 이는 MNIST에서의 예비 실험에서 관찰한 개선과 유사함
앙상블은 WER (23,000단어 테스트 세트에서)의 최종 목표에는 더 작은 개선을 가져왔지만, 다시 한 번 앙상블에서 얻은 WER의 개선이 distillation으로 전이됨
5. Training ensembles of specialists on very big datasets
대규모 데이터셋에서 모델 앙상블을 효과적으로 학습하는 방법에 대한 내용을 다룸
- 모델 앙상블을 학습하는 것은 병렬 계산을 활용하는 매우 간단한 방법이지만, 대규모 데이터셋에서 큰 신경망 모델을 사용할 때 학습 시 필요한 계산양이 과도하다는 문제가 존재함
- 이러한 문제를 해결하기 위해 특화된 모델들을 학습하여 클래스의 다양한 하위 집합에 중점을 두는 방법을 소개
- 전문가 모델을 학습하는 주요 문제 중 하나는 세부적인 구분을 위해 중점을 둔다는 점에서 과적합(overfitting)이 쉽게 발생한다는 것
- 소프트 타겟을 사용함으로써 전문가 모델들이 세부적인 구분을 학습하는 동안 더 강건하게 학습할 수 있도록 도와줌
5.1 The JFT dataset
JFT(JFT dataset) 구글의 내부 DATASET
JFT는 1억 개의 레이블이 지정된 이미지를 가지고 있으며 15,000개의 레이블 존재
5.2 Specialist Models
클래스의 수가 매우 많을 때, 복잡한 모델을 앙상블 하기 위해 전체의 데이터 셋에 대해서 훈련된 하나의 Generalist model과 혼동하기 쉬운 클래스 Subset 데이터에 대해 훈련된 Specialist models를 함께 사용하는 것이 좋음
각 전문가 모델은 매우 혼동하기 쉬운 클래스의 예제가 풍부한 데이터에서 훈련되며(예: 다양한 종류의 버섯), 이러한 전문가 모델의 softmax는 관심 없는 모든 클래스를 하나의 dustbin 클래스로 결합하여 훨씬 작게 만들 수 있음
- 과적합을 줄이고 하위 수준의 피처 디텍터를 학습하는 작업을 공유하기 위해 각 전문가 모델은 generalist model의 가중치로 초기화
- 그런 다음 이 가중치는 해당 전문가가 특별한 하위 집합에서 절반의 예제로 훈련되고 나머지 훈련 세트에서 무작위로 샘플링된 나머지 절반의 예제로 훈련되도록 약간 수정
- 훈련 후에는 Specialist 클래스가 과잉 샘플링된 비율의 로그로 dustbin 클래스의 로짓을 증가시켜 편향된 훈련 세트를 보정할 수 있음
5.3 Assigning classes to specialists
Specialist models에 대한 객체 범주의 그룹을 도출하기 위해, 우리는 전체 네트워크가 자주 혼동하는 클래스에 중점을 두어야 함
혼동 행렬을 계산하고 그를 사용하여 이러한 클러스터를 찾는 방법이 가능했지만, 실제 레이블이 클러스터를 구성하는 데 필요하지 않은 더 간단한 접근 방식인 true label이 필요없는 클러스터링 방식으로 그룹화를 시도함
- Generalist 모델의 예측에 대한 공분산 행렬을 사용
- K-means 알고리즘 또는 그의 온라인 버전을 사용하여 클러스터링을 수행
- 클러스터링 결과로 특정 전문가 모델에 대한 클러스터를 얻음

5.4 Performing inference with ensembles of specialists
전문가 모델이 포함된 앙상블의 성능을 확인하기 전에, 전문가 모델이 풀리면 어떤 일이 발생하는지 확인함
주어진 입력 이미지 x에 대해 다음 두 단계로 최상위 분류를 수행
- 단계 1: 각 테스트 케이스에 대해 전문가 모델에 따라 n개의 가장 확률이 높은 클래스를 찾음, 해당 클래스 집합을 라고 하며, 실험에서는 을 사용
- 단계 2: 특수 클래스의 확률 분포가 비어 있지 않은 와 교차하는 이 있는 모든 전문가 모델 을 가져와 이를 활성 전문가 집합 라고 함, 그런 다음을 최소화하는 모든 클래스에 대한 전체 확률 분포 를 찾음
, 는 전문가 모델 또는 일반적인 전체 모델의 확률 분포를 나타냄
5.5Results
Baseline 전체 네트워크보다, 각 전문가 모델이 빠르게 훈련됨
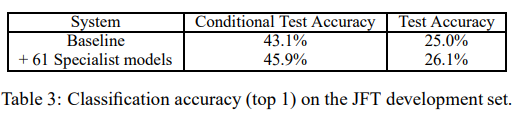
모든 전문가 모델이 독립적으로 훈련된다는 내용을 설명하며 Baseline 시스템과 전문가 모델을 결합한 결과로 전체적인 테스트 정확도가 4.4% 향상됨을 보임
JFT 전문가 실험에서는 61개의 전문가 모델을 훈련하고, 특히 각 전문가가 커버하는 클래스의 중첩으로 인해 정확도 개선이 나타나는 것을 확인할 수 있으며, 이러한 접근은 병렬화가 용이하다는 장점임
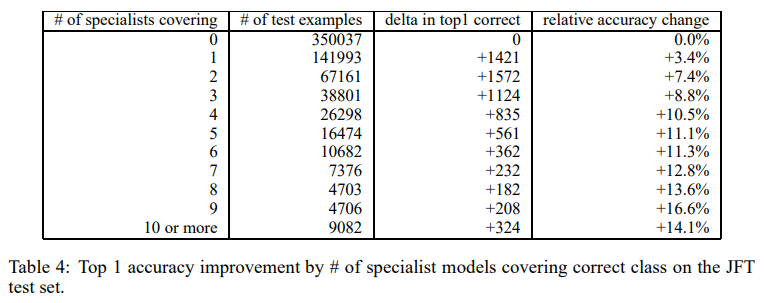
전문가 모델이 추가될수록 나타나는 상대적 개선률을 확인할 수 있음
6.Soft Targets as Regularizers
Soft Targets as Regularizers, Soft target을 사용하면 단일 Hard target으로는 전달하기 어려운 유용한 정보를 전달할 수 있음

훈련 세트와 3%의 훈련 세트에서 모델을 훈련시키는 경우를 비교함
Hard target으로 훈련시킨 경우에는 44.5%의 정확도로 심각한 오버피팅이 나타났지만, Soft target을 사용한 경우에는 57.0%의 정확도로 거의 전체 훈련 세트의 정보를 회복할 수 있음을 보임
Soft target을 사용한 모델은 초기 중단 없이도 효과적으로 수렴함
-> 이러한 결과는 Soft target이 전체 데이터셋에서 학습한 정규성을 다른 모델에 효과적으로 전달하는 데 효과적임을 강조
6.1 Using soft targets to prevent specialists from overfitting
- 전문가 모델을 일반적인 가중치로 초기화되고 특수 클래스에 대한 Hard target과 함께 비전문가 클래스에 대한 Soft target으로 훈련되면, 전문가 모델은 비전문가 클래스에 대한 지식을 효과적으로 보존할 수 있음
- Soft target은 일반 전문가 모델에 의해 제공되며 교육 중에 Hard target과 함께 사용됨
- 3%의 음성 데이터를 사용한 실험이 이 접근 방식이 전문가들이 비전문가 클래스에 대한 지식을 보존하는 데 도움이 되면서도 과적합을 방지하는 데 효과적인지를 지원한다고 언급함
7. Relationship to Mixtures of Experts
데이터 하위 집합에서 훈련된 전문가의 사용은 Mixtures of Experts(MoE)과 약간 유사한 면이 존재
MoE는 gating 네트워크를 사용하여 각 예제를 각 전문가에 할당할 확률을 계산함
전문가들은 할당된 예제를 처리하는 방법을 학습하는 동안 게이팅 네트워크는 해당 예제에 대한 전문가의 상대적인 판별 성능을 기반으로 어떤 전문가에게 할당할지를 선택하는 방법을 학습
전문가들의 판별 성능을 사용하여 학습된 할당을 결정하는 것은 입력 벡터를 단순히 클러스터링하고 각 클러스터에 전문가를 할당하는 것보다 훨씬 나은 방법이지만, 이러한 학습을 병렬로 수행하기 어려움
- 첫째, 각 전문가의 가중치 훈련 세트가 다른 모든 전문가에 의존하는 방식으로 계속 변경됨
- 둘째, 게이팅 네트워크는 예제에 대해 서로 다른 전문가들의 성능을 비교하여 할당 확률을 수정해야 함
이 어려움으로 인해 MoE는 거대한 데이터셋이 포함된 작업에서 가장 유익할 수 있는 상황에서는 드물게 사용됨
- MoE를 훈련시키는 것보다 전문가 모델의 훈련을 병렬로 처리하는 것이 쉬움
- 먼저 Generalist 모델을 훈련하고 혼란 행렬을 사용하여 전문가들이 훈련되는 하위 집합을 정의함
- 이 하위 집합이 정의된 후에는 전문가들을 완전히 독립적으로 훈련
- 추론 시에는 일반 모델의 예측을 사용하여 관련 있는 전문가를 결정하고 해당 전문가만 실행하면 됨
8. Discussion
본 논문은 증류(distillation)가 앙상블이나 크고 강하게 정규화된 모델로부터 지식을 작은 증류된 모델로 전송하는 데 매우 효과적임을 보임
1) MNIST에서는 증류가 작은 증류된 모델을 훈련하는 데 사용되는 전송 집합이 하나 이상의 클래스의 예제가 전혀 없어도 놀랍게 잘 작동함
2) 안드로이드 음성 검색에서 사용된 것과 유사한 깊은 음향 모델의 경우, 깊은 신경망 앙상블을 훈련하여 얻은 거의 모든 성능 향상을 크기가 동일한 단일 신경망으로 증류할 수 있다는 것을 보임
3) 실제로 큰 신경망의 경우 전체 앙상블을 훈련하는 것 조차 현실적으로 어려울 수 있지만, 매우 오랜 시간 동안 훈련된 단일 큰 네트워크의 성능을 여러 전문 네트워크를 학습하여 크게 향상시킬 수 있다는 것을 보임
각각의 전문가 네트워크는 매우 혼동되기 쉬운 클러스터 내의 클래스 간을 식별하는 방법을 학습함
하지만 아직까지는 이러한 전문가 네트워크의 지식을 다시 단일 큰 네트워크로 증류할 수 있는지는 보여주지 못함
