본 Paper Review는 고려대학교 스마트생산시스템 연구실 2024년 동계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다.
Abstract
- 본 논문은 Masked Autoencoder(MAE)가 컴퓨터 비전을 위한 확장 가능한 Self-supervised 학습기라는 것을 보여줌
- MAE APPROACH: 입력 이미지의 패치를 무작위로 마스킹하고, 누락된 픽셀을 재구성 하는 것
MAE의 두 가지 핵심
1. 비대칭 encoder-decoder 구조 개발
- encoder: 마스크되지 않은 보이는 패치 하위집합에서만 작동
- decoder: 경량 디코더는 잠재 표현과 마스크된 토큰으로부터 원본 이미지로 재 구성
2. 입력 이미지의 높은 비율(75%)을 마스킹 하는 것이 의미있는 self-supervised 작업이 가능
- 위 두 가지를 설계를 결합하여 대규모 학습 모델을 효율적이고, 효과적으로 훈련
- 이를 통해 훈련을 가속화하고, 정확도를 향상시켜 일반화 능력이 뛰어난 고용량 모델을 학습할 수 있음
- ViT-Huge 모델의 경우 ImageNet-1K 데이터만 사용하는 방법 중 최고의 정확도를 달성
- Downstream 에서의 전이 성능은 SUPERVISED 사전 학습을 능가함
- 더 큰 모델 또는 복잡한 데이터 작업에 대하여 확장 가능함
1. Introduction
딥러닝 분야에서 아키텍처의 폭발적인 발전과 성능, 용량의 지속적인 증가하고 있음[33,25,57]. 하드웨어의 빠른 발전으로 현재 모델들은 100만 장의 이미지를 쉽게 과적합 할 수 있으며[13], 공개적으로 액세스 할 수 없는 수 억 장의 라벨이 달린 이미지를 필요로 하는 추세임.
노이즈 제거 오토인코더[58]의 한 형태인 마스크된 오토인코더(MAE)의 개념은 자연어 처리 외에도 컴퓨터 비전 분야에 적용할 수 있음.
마스킹 자동 인코딩이 비전과 언어에서 다른 점은 무엇인가?
1) 최근까지 아키텍처가 달랐음.
비전 분야에서는 지난 10년 동안 CNN[34]이 지배적이었음[33]. convolutions는 일반적으로 규칙적인 그리드에서 작용하며, 마스크 토큰[14] 또는 위치 임베딩[57]과 같은 "INDICATOS"를 convolutions networks에 통합하는 것은 간단하지 않음. 이러한 구조적 차이가 Vision Transformers (ViT)[16]의 도입으로 해결됨.
2) 언어와 비전은 정보 밀도에서 다름.
언어는 인간이 생성한 신호로 의미와 정보 밀도가 매우 높음. 문장당 몇 개의 누락된 단어만 예측하도록 모델을 학습시킬 때, 해당 작업은 정교한 언어 이해를 유도하는 것으로 보임. 반면 이미지는 공간적 중복이 많은 자연스러운 신호로, 부품, 사물, 장면에 대한 높은 수준의 이해가 거의 없어도 인접한 패치에서 누락된 패치를 복구할 수 있음. 이러한 차이를 극복하고 유용한 기능을 학습하도록 장려하기 위해 컴퓨터 비전에서 무작위 패치의 매우 많은 부분을 마스킹하는 간단한 전략이 효과적이라는 것을 보임. 해당 전략은 중복성을 크게 줄이고 저수준 이미지 통계를 넘어 전체적인 이해가 필요한 까다로운 selfsupervisory 을 생성함.
(재구성 작업에 대한 이해는 아래 그림을 참고)


3) 디코더는 텍스트와 이미지를 재구성 할 때 다른 역할을 수행함.
비전에서는 디코더가 픽셀을 재구성하므로 일반적인 인식 작업보다 의미 수준이 낮음. 이는 디코더가 풍푸한 의미 정보를 포함하는 누락된 단어를 예측하는 언어와는 대조적임. BERT에서 디코더가 사소할 수 있지만[14], 이미지의 경우 디코더 설계가 학습된 잠재 표현의 의미 수준을 결정하는데 핵심적인 역할함을 발견.
위 3가지 분석을 바탕으로 시각적 표현학습을 위한 간단하고 효과적이며 확장가능한 형태의 Masked Autoencoder(MAE)를 제안함. MAE는 입력 이미지에서 무작위 패치를 마스킹하고 픽셀 공간에서 누락된 패치를 재구성 함. 비대칭 인코더 설계가 적용 됨. 아래 그림과 같이 인코더는 마스크 토큰 없이 보이는 패치 하위 집합에서만 작동하며, 디코더는 가볍고 마스크 토큰과 함께 잠재적 표현에서 입력을 재 구성함.
2. Related Work
Masked language modeling과 이에 대응 하는 자동 회귀 모델링(e.g.,BERT [14] and GPT [47, 48, 4])은 NLP 사전 학습에 매우 성공적인 방법이며, 이러한 방법은 입력 시퀀스의 일부를 유지하면서 누락된 내용을 예측하도록 모델을 훈련함.
이러한 방법은 확장성이 뛰어나며[4], 사전 학습된 표현이 다양한 Downstream 작업에도 잘 일반화된다는 많은 증거가 존재함.
Autoencoding은 표현을 학습하는 고전적 방법. 입력을 잠재 표현에 매핑하는 인코더와 입력을 재구성하는 디코더가 존재함. 예를 들어 PCA와 k-평균은 자동 인코더임[29]. 노이즈 제거 자동 인코더(DAE)[58]는 입력 신호를 손상시키고 손상되지 않은 원래의 신호를 재구성하는 방법을 학습하는 자동 인코더의 한 종류 임. 픽셀 마스킹[59,46,6] 또는 컬러 채널 제거[70]와 같은 일련의 방법은 다양한 손상 상태에서 일반화 된 DAE로 생각할 수 있음.
MAE는 노이즈 제거 자동 인코딩의 한 형태이나, 여러가지 면에서 기존 DAE와 다름.
Masked image encoding은 마스킹에 의해 손상된 이미지로 부터 표현을 학습함. 선구적인 연구[59]는 마스킹을 DAE의 노이즈 유형으로 제시함. 최근 연구들은 Context Encoder [46]와 같이 convolutional networks을 사용하여 누락된 큰 영역을 예측함. NLP분야의 성공에서 영감을 받은 최근 관련 방법[6, 16, 2]은 트랜스포머[57]를 기반으로 함. iGPT[6]는 픽셀 시퀀스에서 작동하며 알려지지 않은 픽셀을 예측하며, ViT[16]는 자기 지도 학습을 위한 마스킹 패치 예측을 연구함. 가장 최근에는 BEiT[2]가 이산 토큰을 예측할 것을 제안함[44, 50].
Self-supervised learning은 컴퓨터 비전에서 많은 관심을 받아왔으며, 종종 사전 학습을 위한 다양한 선행 과제에 초점을 맞추고 있음[15, 61, 42, 70, 45, 17]. 최근에는 두 개 이상의 뷰 간의 이미지 유사성 및 비유사성(또는 유사성만[21, 8])을 모델링하는 대조 학습[3, 22]이 인기를 끌고 있음[62, 43, 23, 7]. 대조 및 관련 방법은 데이터 증강에 크게 의존함[7, 21, 8]. Autoencoding과는 개념적으로 다른 방향을 추구하며, 다른 특성을 나타냄
3. Approach
MAE는 원본 신호의 부분 관찰을 토대로 해당 신호를 재구성하는 간단한 오토인코딩 방법
모든 오토인코더와 마찬가지로 우리의 방법은 관찰된 신호를 잠재 표현으로 매핑하는 인코더와 잠재 표현에서 원본 신호를 재구성하는 디코더를 갖고 있음. 고전적인 오토인코더와 달리 우리는 부분적으로 관찰된 신호에만 작동하는 인코더(마스크 토큰 없이)와 잠재 표현 및 마스크 토큰에서 전체 신호를 재구성하는 가벼운 디코더를 사용하는 비대칭 설계를 채택함.
아래 그림은 이 개념을 시각적으로 보여줌
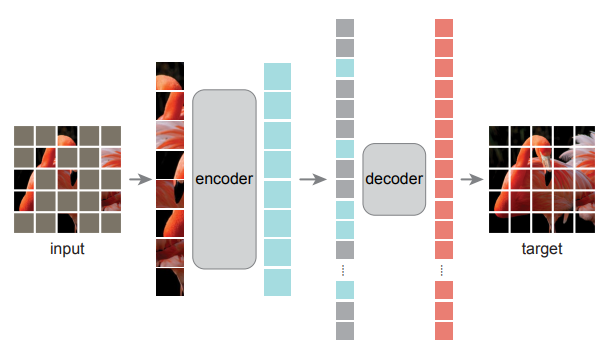
Masking:
- ViT [16]를 따라 이미지를 정규 비중첩 패치로 나눔.
- 패치의 하위 집합을 샘플링하고 남은 부분을 마스킹(즉, 제거)함.
- 균일한 분포를 따르며 중복 없이 무작위 패치를 샘플링 함 (“random sampling”)
- 높은 마스킹 비율(즉, 제거된 패치의 비율)로 랜덤 샘플링을 수행하면 이웃 패치에서 extrapolation으로 쉽게 해결할 수 없는 작업을 만듦.
- 균일한 분포는 잠재적인 중앙 편향(즉, 이미지 중심 근처의 더 많은 마스킹된 패치)을 방지함
- 매우 희소한 입력은 효율적인 인코더를 설계하는 기회를 제공
MAE encoder:
- MAE encoder는 ViT[16]이지만, 마스킹되지 않은 가시적인 패치에만 적용됨.
- MAE encoder는 표준 ViT에서와 마찬가지로 위치 임베딩이 추가된 선형 투영으로 패치를 임베딩한 다음 일련의 트랜스포머 블록을 통해 결과 세트를 처리함.
- MAE encoder는 전체 세트의 작은 부분 집합(예: 25%)에서만 작동함.
- 마스킹된 패치는 제거되고 마스크 토큰은 사용되지 않음.
- 이를 통해 약간의 컴퓨팅 및 메모리만으로 매우 큰 encoder를 학습할 수 있음.
- 전체 세트는 경량 디코더에서 처리됨.
MAE decoder:
- MAE decoder에 대한 입력은 (i) encoder된 가시 패치 및 (ii) 마스크 토큰으로 구성된 토큰의 전체 집합으로 구성.
- 각 마스크 토큰 [14]는 예측할 누락된 패치의 존재를 나타내는 공유 학습된 벡터임.
- 전체 집합의 모든 토큰에 위치 임베딩을 추가함.
- 이렇게 하지 않으면 마스크 토큰은 이미지 내의 위치에 대한 정보가 없음.
- decoder에는 또 다른 일련의 트랜스포머 블록이 있음.
MAE decoder는 이미지 재구성 작업을 수행하기 위해 사전 훈련 중에만 사용됨(인식을 위한 이미지 표현을 생성하기 위해 encoder만 사용). 따라서 decoder 아키텍처는 encoder 설계와 독립적인 방식으로 유연하게 설계될 수 있음. encoder보다 더 좁고 얕은 매우 작은 decoder로 실험함
EX)
- 기본 decoder는 encoder 대비 토큰당 <10% 계산을 수행함.
- 비대칭 설계를 사용하면 전체 토큰 세트가 경량 decoder 에서만 처리되므로 사전 훈련 시간이 크게 단축됨.
Reconstruction target:
- MAE는 마스크 된 각 패치의 픽셀 값을 예측하여 입력을 재구성함.
- decoder의 출력에 있는 각 요소는 패치의 픽셀 값 벡터를 나타냄.
- decoder의 마지막 레이어는 출력 채널의 수가 패치의 픽셀 값의 수와 동일한 선형 투영임.
- 손실 함수는 픽셀 공간에서 재구성된 이미지와 원본 이미지 사이의 평균 제곱 오차(MSE)를 계산함
- 정규화된 픽셀을 재구성 대상으로 사용하면 실험에서 표현 품질이 향상됨.
Simple implementation:
- MAE 사전 훈련은 효율적으로 구현되며, 특수한 희소 연산이 없음.
- 위치 임베딩이 추가된 선형 투영에 의해 모든 입력 패치에 대한 토큰을 생성함.
- 토큰 목록을 무작위로 셔플하고 마스킹 비율을 기반으로 목록의 마지막 부분을 제거함.
- 해당 프로세스는 encoder에 대한 작은 토큰 하위 집합을 생성하며 대체 없이 패치를 샘플링하는 것과 동일함.
- encoder 후 마스크 토큰 목록을 인코딩된 패치 목록에 추가하고 대상과의 정렬응 위해서 목록이 섞이지 않음
- 위치 임베딩이 추가된 decoder는 전체 목록에 적용이 됨
- 셔플링 및 셔플 해제 작업은 빠르게 진행이 되고, 희소작업이 필요하지 않아 오버헤드가 최소화 됨.
4. ImageNet Experiments
- ImageNet-1K(IN1K)[13] 교육 세트에 대해 self-supervised pre-training을 실시함
- (i) 엔드 투 엔드 미세 조정 or (ii) 선형 프로빙으로 표현을 평가하는 감독 교육을 실시함
- 단일 224x224 작물의 상위 1개 검증 정확도를 보고함.
- Baseline 모델을 ViT-Large 선택하고, ResNet-50보다 훨씬 큰 대형 모델이며 과적합되는 경향이 있음
- 제안하는 MAE 사용하면 지도학습 방식으로 사전학습시키는 것 보다, 오버피팅 문제가 적게 나타남
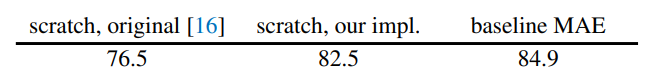
- 결과 값 비교: "ViT-L trained from scratch" VS "fine-tuned from our baseline MAE"
4.1. Main Properties
-
Masking ratio :
최적의 마스킹 비율은 아래 그림에서 나타나듯, 75%로, 매우 높음
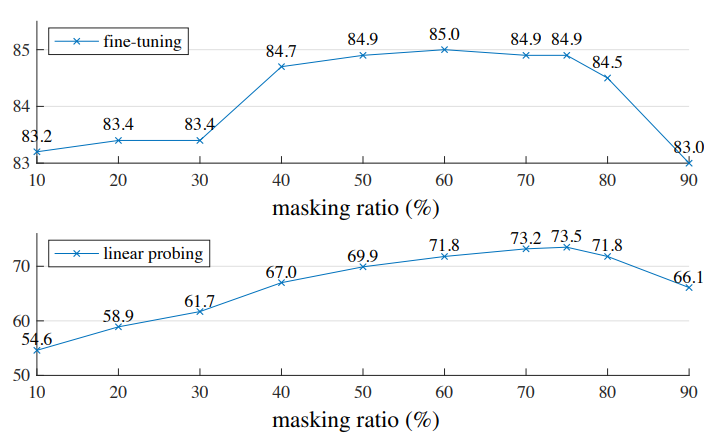
-
Decoder design :
MAE decoder는 유연하게 설계 가능함
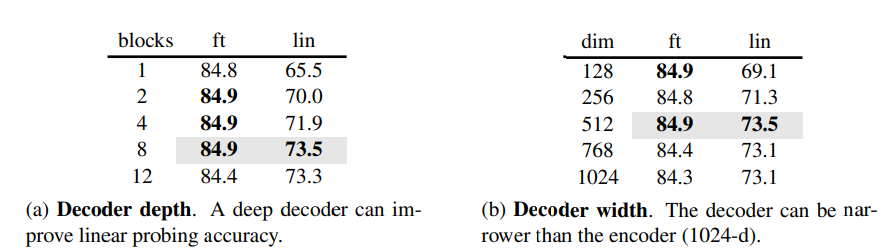
Decoder depth(Transformer 블록 수) -> 선형 탐색에는 깊은 디코더가 중요하나, 파인튜닝에는 영향이 적음.
Decoder width(채널 수) -> default 값 512-d로 파인튜닝 및 선형 탐색에서 잘 작동.
-
Mask token :
incoder에서 mask token을 건너뛰어 정확도를 향상시키고, 훈련 계산량을 크게 줄일 수 있음

-
Reconstruction target :
픽셀 단위 정규화를 사용한 결과가 정확도 향상
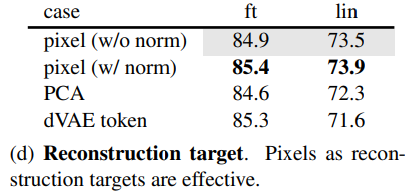
-
Data augmentation :
크롭만 사용하여도 잘 작동하며, 색상 지터링은 결과를 저하시키므로 사용하지 않음
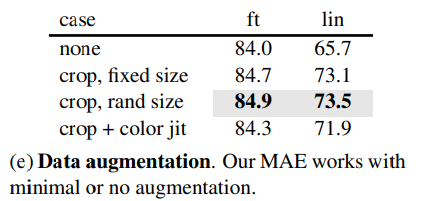
-
Mask sampling strategy :
랜덤 샘플링이 MAE에 가장 적합하며 높은 마스킹 비율을 허용하면서도 좋은 정확도를 제공함

-
Training schedule :
Training schedule에 따라 영향이 나타남,
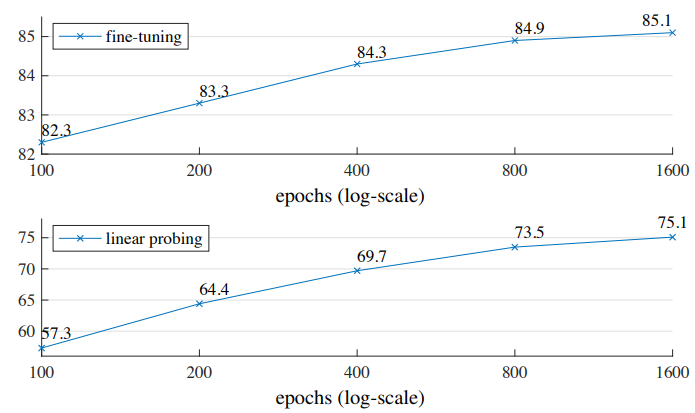
4.2. Comparisons with Previous Results
- 초기 ViT 논문 [16]에서는 ViT-L이 IN1K에서 훈련 시 성능이 감소
- supervised, our implementation가 더 나은 결과 값을 얻지만, 정확도가 포화됨
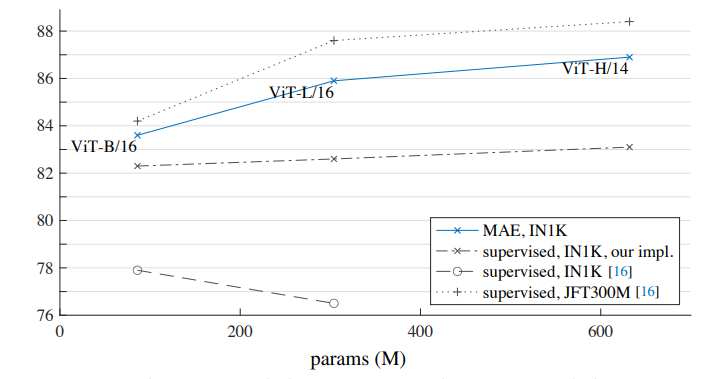
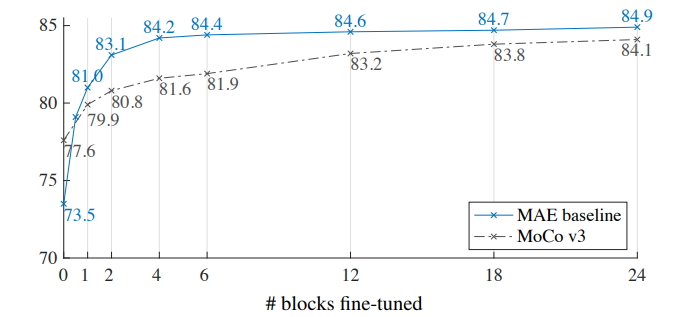
4.3. Partial Fine-tuning
- Fine-tuning 할 수록 성능이 더 좋아지나, 큰 차이가 없음
- 마지막 몇 개의 레이어를 파인튜닝하고 다른 레이어는 freeze 하는 것이 더 좋은 전략일 것
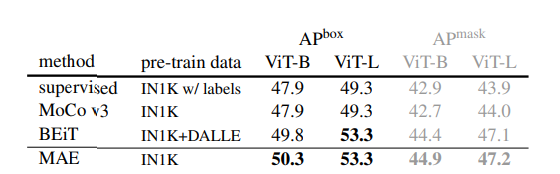
5. Transfer Learning Experiments
- Object detection and segmentation:
MAE는 모든 구성에서 지도학습 대비 우수한 성능을 보임
픽셀 기반 MAE는 토큰 기반 BEiT보다 우수하거나 유사하며, MAE가 훨씬 간단하고 빠름
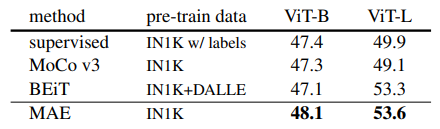
- Semantic segmentation:
MAE로 사전학습 시켰을 때 지도학습 대비 결과가 크게 향상됨
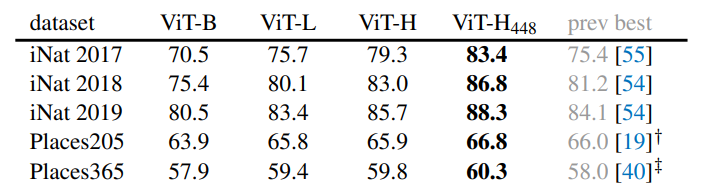
- Classification tasks:
MAE는 큰 dataset에 더 강력한 성능을 보임
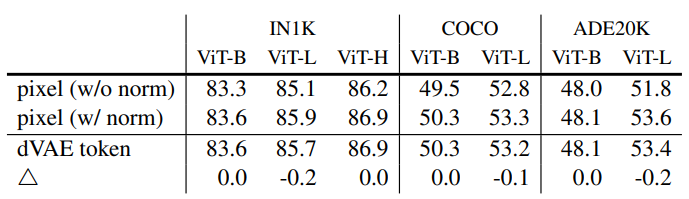
- Pixels VS tokens:
dVAE 토큰 사용은 정규화된 픽셀 사용보다 우수하지만, 정규화된 픽셀 사용과 통계적으로 유사함
따라서 MAE에 대하여 토큰화는 필요하지 않음
6. Discussion and Conclusion
- 본 연구에서는 NLP 기법과 유사한 간단한 자기 지도 학습 방법인 오토인코더가 ImageNet 및 전이 학습에서 확장 가능한 이점을 제공하는 것을 관찰함
- 비전에서의 자기 지도 학습이 NLP에서와 유사한 방향으로 나아가고 있다는 가능성을 시사함
- 이미지와 언어가 본질적으로 다른 성격의 신호로 이 차이를 신중하게 다뤄야한다는 점에 주목
