
포스팅 이유
프로젝트성으로 서비스 운영중인 환경의 쿠버네티스 클러스터 확장 작업을 진행했던 기록을 남기기 위함
1. 개요
서비스 운영중인 쿠버네티스 클러스터의 리소스 부족 및 OS 이슈등의 문제로 OS 버전의 업그레이드와 클러스터 확장을 병행하여 진행했습니다.
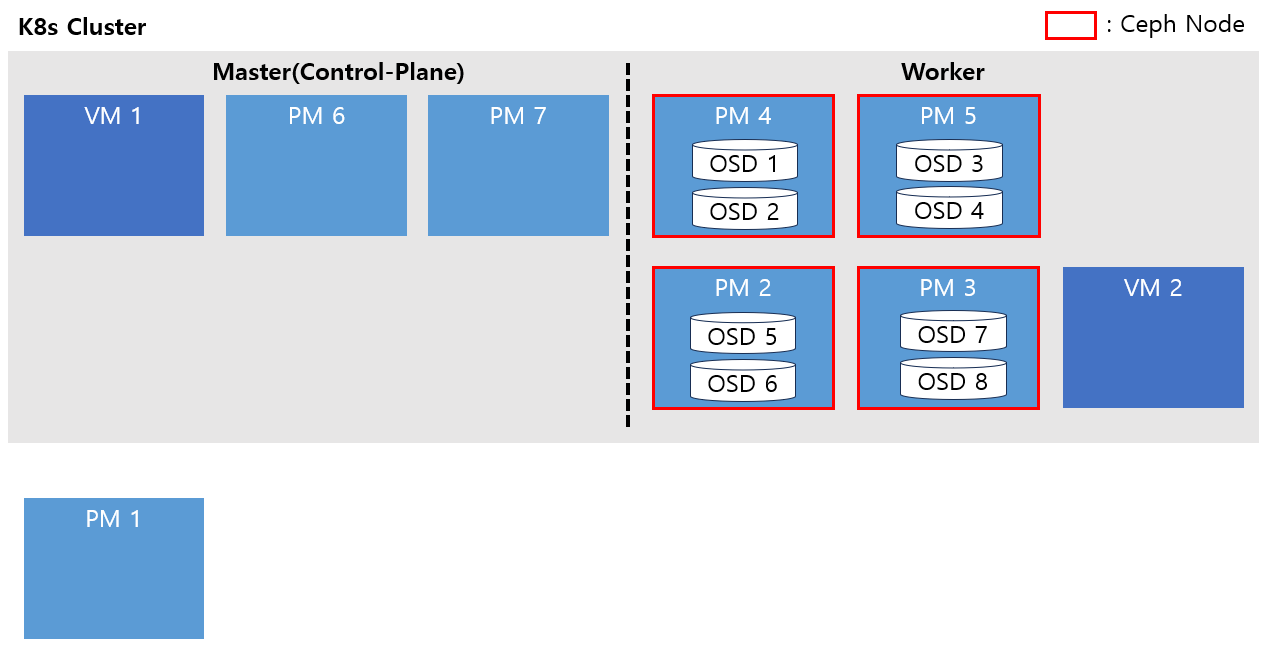
클러스터 정보
- Master 노드 3대, Worker 노드 2대 (총 5대)
- 5개 노드 모두 CentOS 7.6버전 사용중인 물리 장비(PM)
- Master 2, 3번과 Worker 1, 2번 노드에는 각각 sdb, sdc 두 개의 디스크 보유 중.
- 리소스 부족으로 Master 2번의 taint를 풀어 Worker처럼 사용.
- Worekr 1, 2번의 노드에 각각 osd를 두 개씩 구성하여 k8s내부에 rook ceph 클러스터 구성하여 사용중이었으나, 사용량이 많아짐에 따라 Master 2번 노드에 osd 2개를 추가하여 총 6개의 osd로 클러스터 구성
Master 2번을 Worker처럼 사용하며 ceph 구성까지 되어 있는 상황이었습니다.
해당 노드에서 장애가 발생할 시 클러스터 전체 영향도가 매우 크고 리소스 부족 문제를 근본적으로 해결하고자 여유 VM과 PM을 확보하여 클러스터 확장을 진행하기로 결정했습니다.
이 과정에서 OS 버전도 Cent OS 8버전대로 올리기로 결정했습니다.
2. 시나리오
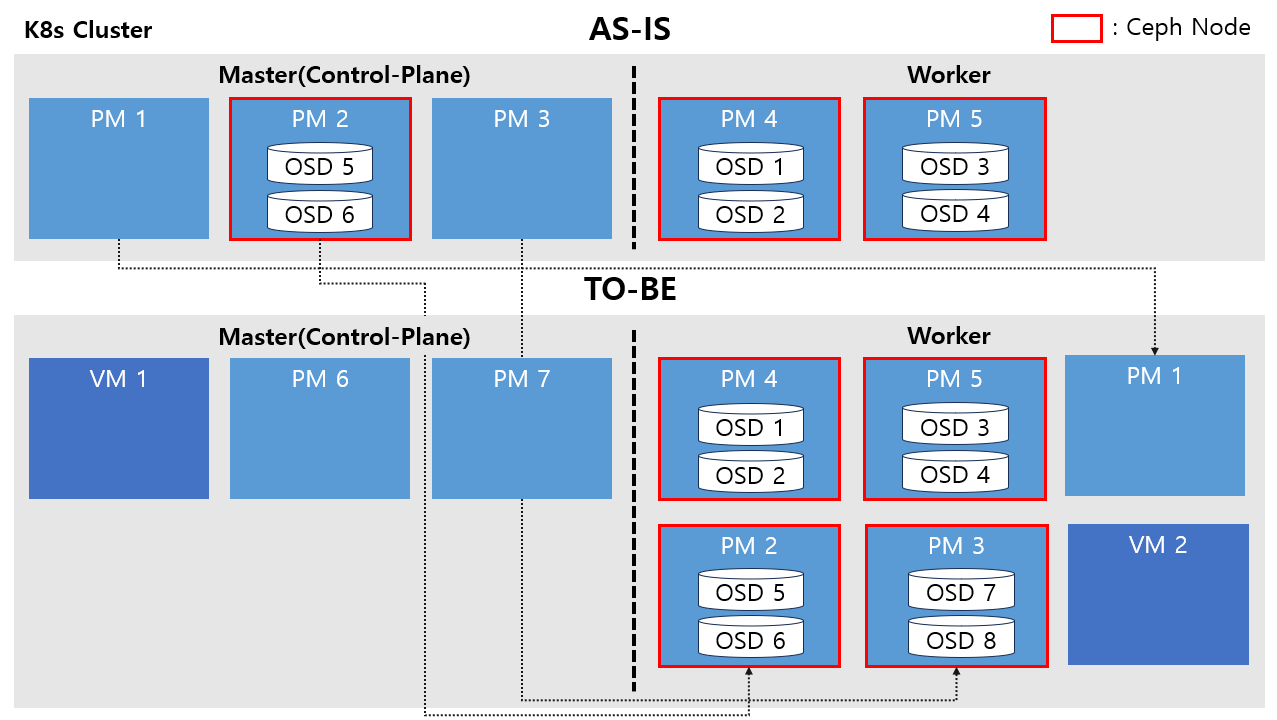
TO-BE를 어떻게 구성할지 먼저 확인해보겠습니다.
기존 Master 노드 3개를 Worker로 보내고 ceph node를 한개 추가하며 추가되는 VM과 PM을 클러스터 추가했습니다. 그리고 모든 노드는 Cent OS 7버전대에서 8버전대로 업그레이드합니다.
ceph의 경우 noout flag를 설정을 통해 osd out 상황 시 rebalacing을 발생시키지 않아 작업 시간을 단축할 수 있습니다. 또한 OS 변경 시 sdb, sdc 디스크쪽 데이터는 유지하여 기존 데이터를 지우지 않고 유지한 상태에서 다시 ceph cluster에 추가하여 디스크 I/O를 최소화합니다.
추가적으로 해당 환경은 폐쇄망이기 때문에 설치에 필요한 패키지를 사전에 반입하며 local-repo를 구성이 필요합니다.
위 내용들이 어떻게 진행될 지 구체적인 시나리오를 통해 순서대로 알아보겠습니다.
작업 순서
1. Master 노드 추가
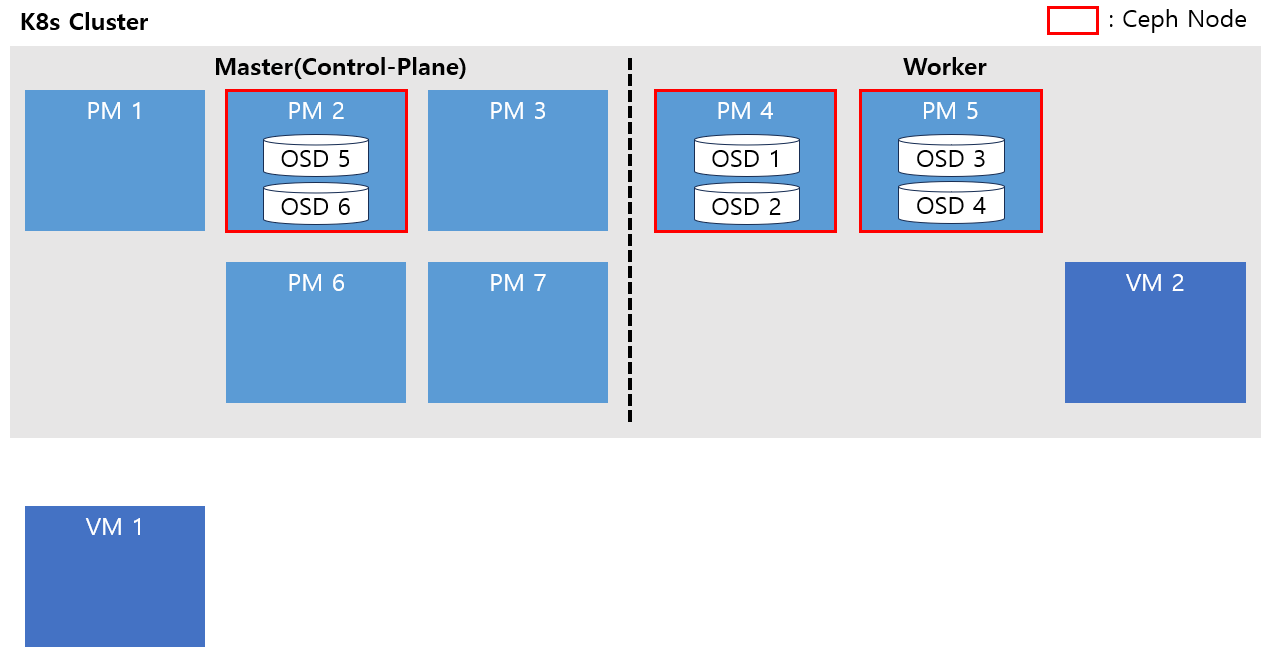
추가되는 PM 장비 2개에 Cent OS 8버전대로 구성하고 기존 클러스터에 Master 노드로 join합니다.
K8s는 OS 버전이 달라도 클러스터 구성이 가능하기 때문에 기존 노드들이 Cent OS 7버전을 사용하고 있어도 문제 없이 노드 join이 가능합니다.
VM 장비 1개에도 Cent OS 8버전대로 구성 후 기존 클러스터의 Worker 노드로 join합니다.
노드 join하는 방법은 별도의 포스팅에 업로드 되어있습니다.
2. 기존 Master 노드 제거
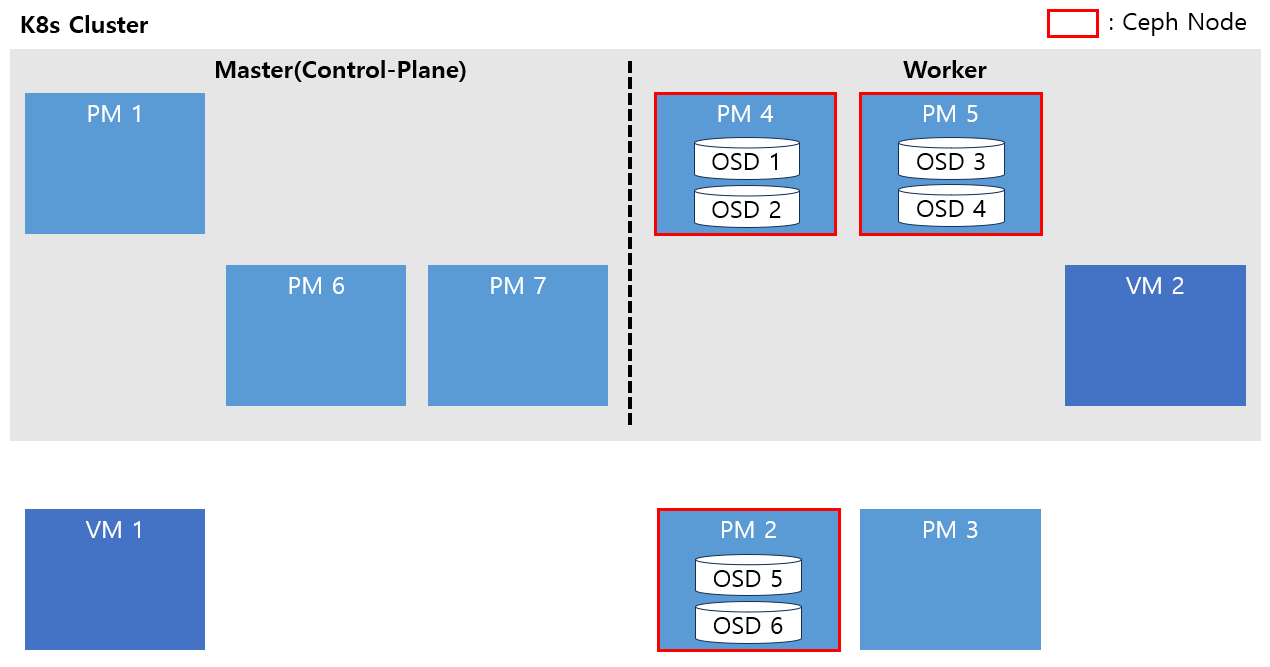
Master 노드가 5개인 상황에서 기존 Master 노드 2개를 제거합니다.
Master 노드 2번의 경우 노드 제거 작업을 하기 전 ceph tools를 통해 noout flag를 설정하고 해당 osd 5, 6번 deployment의 replicas를 0으로 변경한 후 node drain을 진행합니다.
이후 etcdctl을 통해 etcd member remove를 하여 PM1, PM6, PM7 세 개만 member로 만들어 leader가 선출될 때 까지 기다립니다.
etcd가 안정화되면 Master 2,3번을 지우고 reset하여 OS를 7 => 8로 업그레이드 진행합니다.
3. Worker 노드로 추가
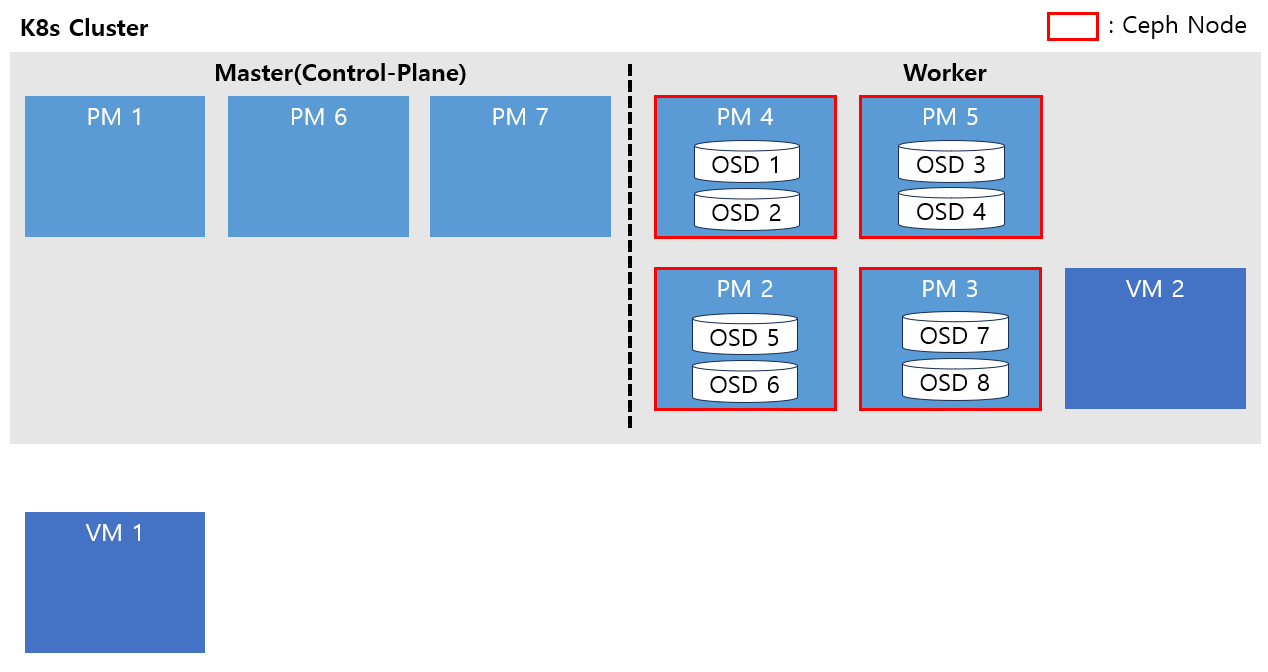
OS 업그레이드가 진행 된 PM2, PM3 장비를 Worker 노드로 추가합니다.
노드 추가 이후 osd 5, 6번 deployment의 replicas를 1로 다시 늘려주고, PM3 장비의 sdb, sdc 디스크도 osd 구성을 하여 ceph cluster에 추가합니다.
이후 noout flag를 다시 제거하여 rebalancing을 발생시킵니다.
rebalancing이 끝날 때 까지 기다리고 ceph가 안정화 된 이후 다음 작업을 진행합니다.
4. Master 1번 교체 (IP 스왑)
기존 Master 1번의 ip를 유지해야할 필요가 있어 해당 노드 교체는 IP 스왑을 통해 진행했습니다.
Master 1번 노드를 drain하고 etcd member에서 remove한 후 노드 삭제를 진행합니다.
이제 Master 노드가 두 개로 불안정한 상태이기 때문에 이후 작업을 최대한 빠르게 진행합니다.
IP 스왑을 통해 Master 1번 노드(PM1)의 IP를 VM1에 부여합니다.
IP가 제대로 넘어간 것을 확인 한 후 VM1을 Master 노드로 추가합니다.
제거한 PM1의 OS를 7 => 8로 업그레이드 합니다.
5. Worker 노드로 추가 및 기존 Worker OS 업그레이드
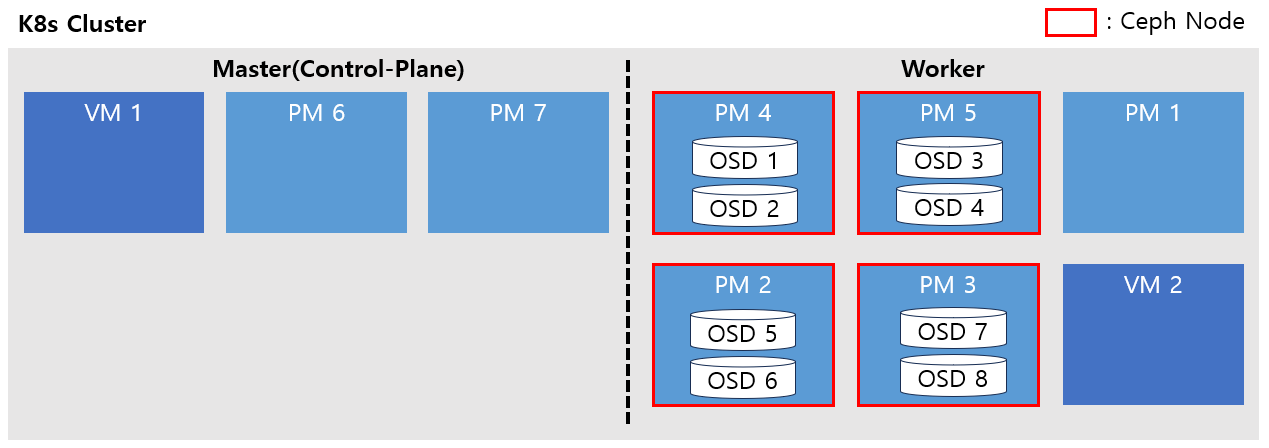
PM1을 Worker 노드로 추가합니다.
기존 Worker였던 PM4, PM5번을 제외한 모든 노드의 OS가 Cent OS 8버전대로 업그레이드 되었습니다.
이제 ceph tool를 통해 다시 noout flag를 적용하고 기존 PM4와 PM5의 osd 1, 2, 3, 4의 deployment replicas를 0으로 줄입니다.
osd 4개가 모두 내려간것을 확인한 후 두 노드에 drain을 걸고 노드를 제거합니다.
이후 PM4, PM5의 OS를 7 => 8로 업그레이드 진행합니다.
업그레이드가 된 후 다시 Worker 노드로 추가하고 osd 1, 2, 3, 4의 deployment replicas를 1로 올려줍니다.
마지막으로 noout flag를 다시 제거하여 rebalancing을 발생시킵니다.
마무리
전체 작업 기간은 1주일정도 걸렸고 운영중인 환경이다보니 서비스 영향도를 고려해 야간 시간대에 진행하였습니다.
단순한 노드 조인과 삭제는 많이 해봤지만 ceph가 구성되어 있고, 실제 운영중인 환경이고, OS 업그레이드까지 진행해야하는 복잡한 작업이라 부담이 많았지만 시나리오대로 잘 진행되어 무사히 마무리 할 수 있었습니다.
