Knowledge Distillation
출처 : (https://light-tree.tistory.com/196)
pretrained된 Teacher network(큰 모델)의 학습된 정보를 추출해서
student network(작은 모델) 학습시키는데 이용하는 것.
그냥 작은 모델로 학습하는 것 보다 더 높은 정확도를 얻을 수 있음

Soft label : [0, 0, 0, 1] 처럼 원핫 인코딩된 결과가 아니라 [0.1, 0.2, 0.1, 0.6] 처럼 확률로
나타낸 라벨값
soft predictions : softmax한 값에 T를 나눠주어 극단적인 값의 분포를 완화해줌
hard prediction : 그냥 softmax한 값
결과적으로 distillation loss + student loss 값을 이용해 student모델을 학습시킴으로써
teacher model의 정보를 이용할 수 있다
Knowledge Distillation 코드 구현
코드 출처 : (https://keras.io/examples/keras_recipes/better_knowledge_distillation/)
사용할 데이터셋 : oxford_flowers102
Teacher model : Pretrained된 BiT ResNet152x2 모델
(https://www.kaggle.com/datasets/spsayakpaul/bitresnet101x3flowers102)
Student model: ResNet50V2
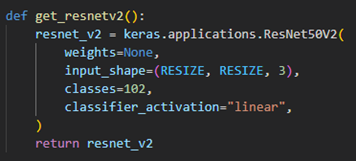
1. Distillation Loss 구현
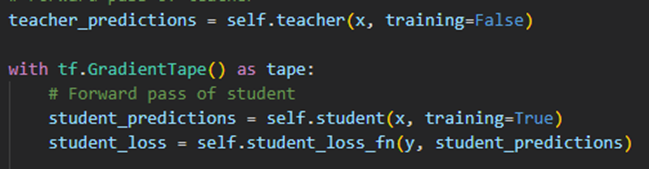

Teacher model과 student model의 softmax값에 T를 나누어줘 값을 평탄화 해주었고,
distillation_loss_fn(KL divergence)를 이용해 두 값의 분포 차이값을 계산함.
그리고 나서 student_loss와 distillation_loss값을 alpha로 비율을 조정해서 값을 더해
최종 loss값을 계산함.
2. 계산한 loss값을 이용해 가중치 업데이트

3. Knowledge distillation을 이용핸 student model의 결과
한시간(20 epoch)만큼 모델을 돌린 결과 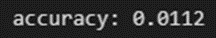
매우 안 좋은 결과가 나왔다.
https://git.io/JBO3Y에서 해당 Distillation을 100000 epoch만큼 훈련시킨 모델을 얻을 수 있는데 여기에서는 95.54%가 나왔다.
결론 : Knowledge distillation을 이용해 모델 크기를 줄일수는 있지만 학습 시키는 시간은
더 크게 해야 좋은 결과를 내는 작은 모델을 얻을 수 있을 것 같다.
SR에서의 Knowledge Distillation
Image Super-Resolution Using Knowledge Distillation(10.1007/978-3-030-20890-5_34) 참고
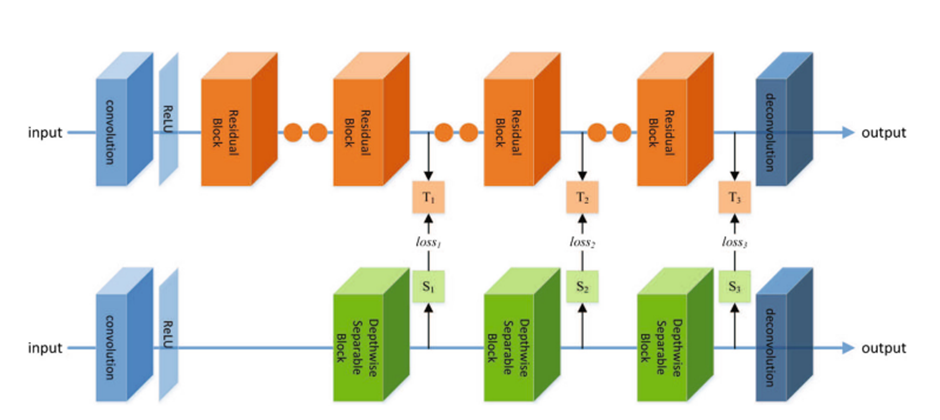
Teacher model에서 각각 T1, T2, T3의 statistical map을, Student model에서 s1, s2, s3의
statistical map을 추출해서 loss(Teacher output, Student output) + loss(t1, s1) + loss(t2, s2) + loss(t3, s3)를 loss로 계산해서 knowledge distillation을 구현
