Transformer 구현 및 코드 분석
Vision Transformer를 이해하기 위해 Transformer를 직접 코드로 구현해보면서
모델을 이해해 봄(출처 : 딥러닝을 이용한 자연어처리 입문, https://wikidocs.net/31379)
포지셔널 인코딩
입력 데이터의 위치정보를 입력데이터에 추가함
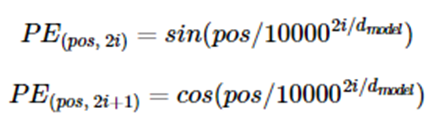
위 수식을 인덱스에 따른 위치정보로 표현해서 임베딩된 데이터에 추가해줌
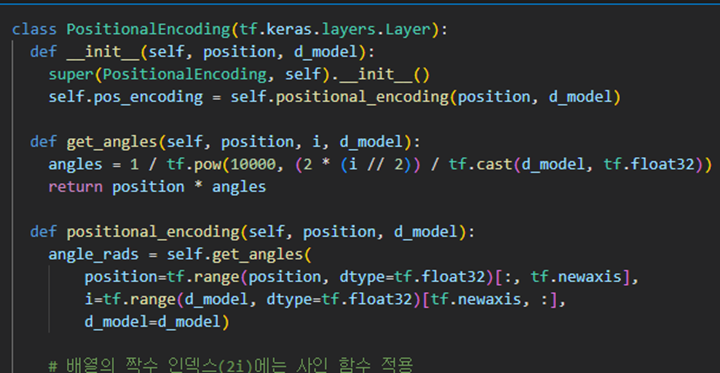
Scaled dot-product Attention
입력데이터에서 구한 Q, K, V를 입력하면 값(셀프 어텐션 값)을 계산해줌
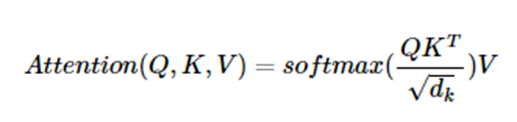

Multi-head Attention
위에서 한 코드는 한번의 attention인데 여러 번의 attention을 병렬로 사용,
병렬로 attention한 결과들을 합쳐 새로운 가중치 행렬 W를 곱해줌
먼저 input에 Q, K, V를 각각 만드는 dense layer를 곱함 -> Q, K, V 생성됨
Q, K, V를 각각 num_heads만큼 나누어서 (input_dim / num_heads)의 차원을 가지는
num_heads만큼의 attention을 만듬.
각각의 attention을 Scaled dot-product후 합친 후 W 곱해줌
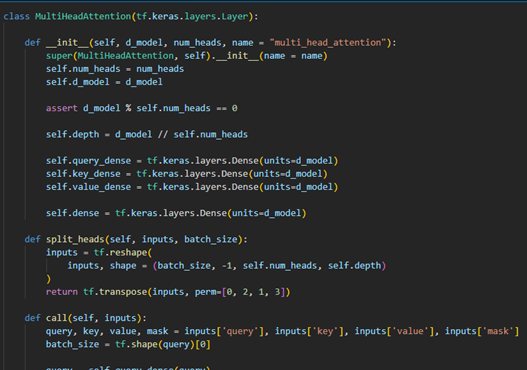
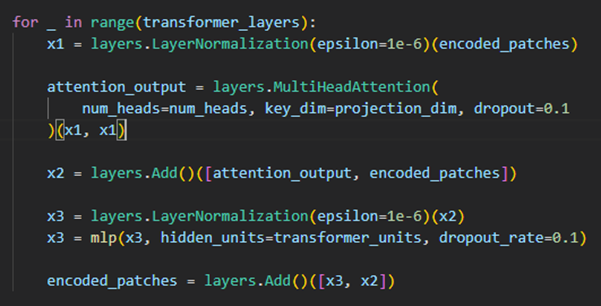
인코더 구현
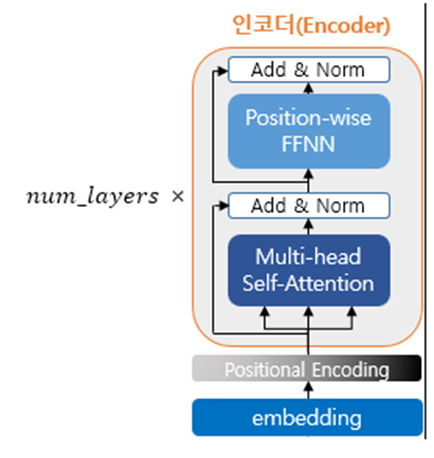
위 이미지처럼 인코더 블록 하나를 구현하고 num_layers만큼 쌓아주엇음
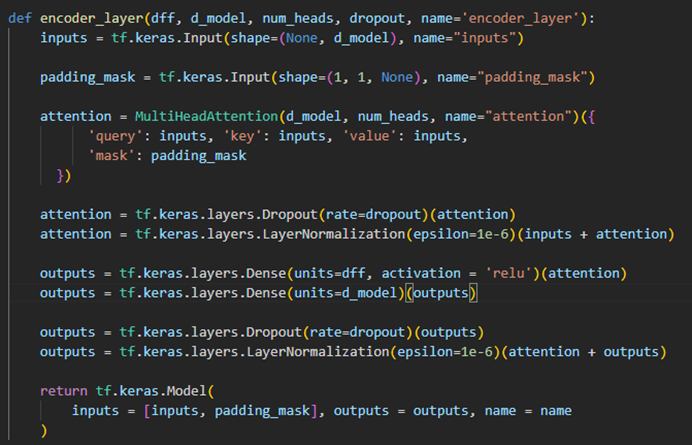
Vision Transformer 구현 및 코드 분석
(출처 : https://keras.io/examples/vision/image_classification_with_vision_transformer/)

Transformer 모델을 이미지에 적용시킨 모델
이미지를 여러 개의 patch로 나누고, 시퀸스 데이터처럼 만듬
그 후 Position Embedding을 더한 다음 Transformer Encoder를 통과시킨다
이미지를 여러 Patch 나누기 + Position Embedding


tf.image.extract_patches 함수를 사용해 이미지를 여러 Patch로 나눔,
나눈 patch들을 projection + position embedding으로 값을 바꿔줌
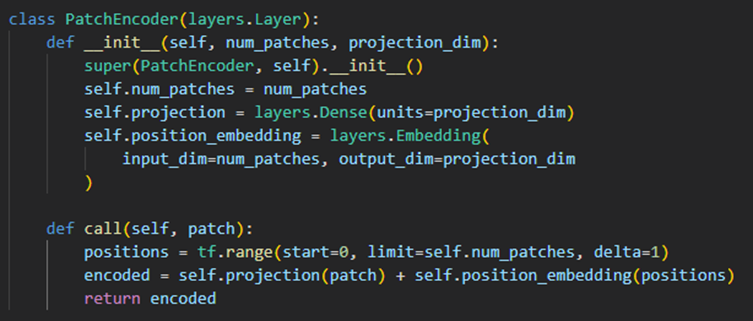
transformer에서는 position embedding을 sin, cos함수로 표현했는데,
ViT에서는 embedding함수로 위치 정보 파라미터를 업데이트 할 수 있도록 구현한 것 같음.
ViT 모델 구현
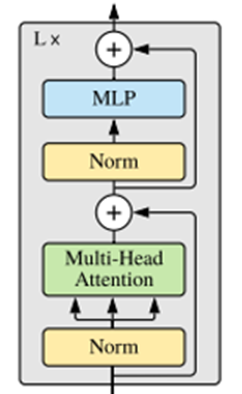
Transformer에서는 Multi Head Attention을 직접 구현해 봤는데
ViT에서는 tensorflow에서 구현된 함수를 사용하였다.
최종 구현
1, 2에서 만든 코드를 합치고, 마지막에 일반 분류문제처럼 Layer를 추가 해 주어서
최종 ViT 모델을 구현하였다
