pandas 라이브러리를 활용한 다양한 방법들을 학습하였다.
👩🏻💻 학습한 것
1. 불러오기 관련
✅ nrows
✅ tsv 파일 불러오기
2. 불러올때 column 설정
✅ header
✅ names
✅ index_col
✅ index.name
✅ parse_dates
✅ dtype
3. API활용하여 XML 데이터 파싱
4. 저장하기
✅ to_csv(encoding, index=False, header = False)
✅ mode
1. pandas로 데이터 불러오기
- shape
행과 열의 갯수 표시
df = pd.read_csv("week1_1.csv")
display (df.head())
print (df.shape) # (50, 6)- nrows
데이터의 크기가 너무 커서 일부만 가져온 뒤 빠르게 데이터를 확인하고 싶을 때
df = pd.read_csv("week1_1.csv", nrows=7)
display (df.head())
print (df.shape)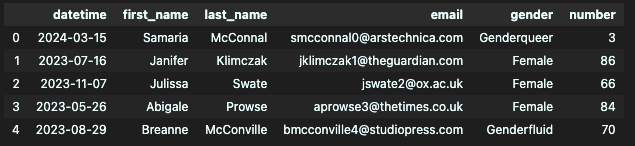
- sep
불러오는 파일의 구분자 - tsv파일?
TSV 파일은 Tab Separated Values의 약자로, 데이터를 탭(tab) 문자로 구분하여 저장하는 텍스트 파일 형식. 쉼표로 구분되는 csv보다 가독성이 좋을 수 있다.
df = pd.read_csv('/Users/sookyeong/Documents/내배캠/스탠다드B/week1_1.tsv', sep = '\t')
df.head()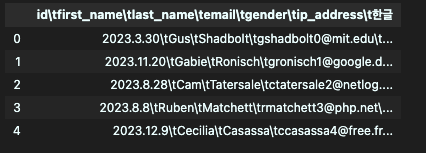
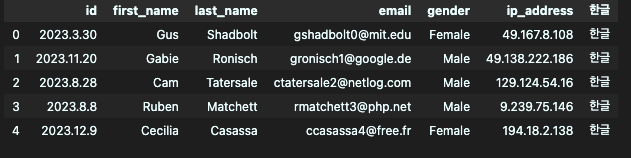
2. 데이터 불러오기 - COLUMN
- header = None
첫 행이 컬럼명이 아니고, 컬럼명 없이 데이터로만 이뤄져 있을 때. (데이터에 헤더가 없을 때 사용)
df = pd.read_csv("week1_1.csv", header=None)
df.head()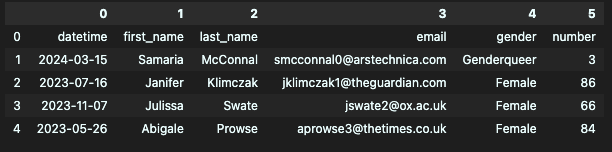
- names
헤더가 없는 상황에서 컬럼명을 넣어주고 싶을 때
df = pd.read_csv("week1_1.csv", names=['c1', 'c2', 'c3', 'c4', 'c5', 'c6'])
df.head()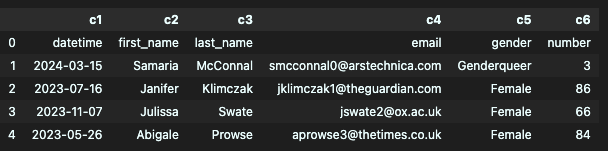
- header & names
첫 행이 컬럼명이 맞는데, 컬럼명을 새로 지정해주고 싶을 때.
df = pd.read_csv("week1_1.csv", header=None, names=['c1', 'c2', 'c3', 'c4', 'c5', 'c6'])
df.head()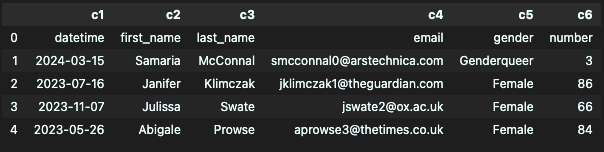
- header = 1
두번째 행을 컬럼명으로 지정하고 싶을 때. 주로 엑셀 형태로 관리되었던 파일에서 사용한다.(위에 공백을 처리하기 위해)
df = pd.read_csv("week1_1.csv", header=1) # 두번 째 행을 컬럼명으로 하고 싶을 때 (주로 엑셀 형태로 관리되었던 파일에서 사용.)
df.head()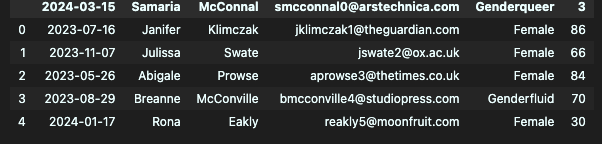
3. 데이터 불러오기 - INDEX
- index_col
n번째 열을 index로 사용하고 싶을 때
df = pd.read_csv("week1_1.csv", index_col=0)
df.head()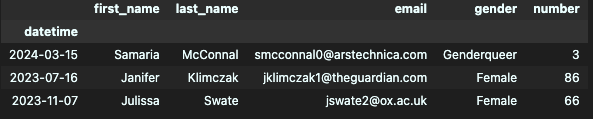
- index.name = None
index 이름을 없애고 싶을 때
df = pd.read_csv("week1_1.csv", index_col=0)
df.index.name = None
df.head()- parse_date
컬럼을 날짜형식으로 불러올때.- 인덱스 : parse_dates = True
- 일반컬럼 : parse_dates = 'column'
df = pd.read_csv("week1_1.csv", index_col=0, parse_dates = True)
df.index.name = None
df.head()
print(df.index.dtype) # datetime64[ns]날짜형식 활용
원하는 날짜를 기준으로 데이터를 불러올 수 있음
df[df.index.month == 10] #10월달의 데이터만
from datetime import datetime
cutoff_date = datetime(2023, 10, 1) # 해당날짜보다 큰 날짜 출력
df[df.index > cutoff_date]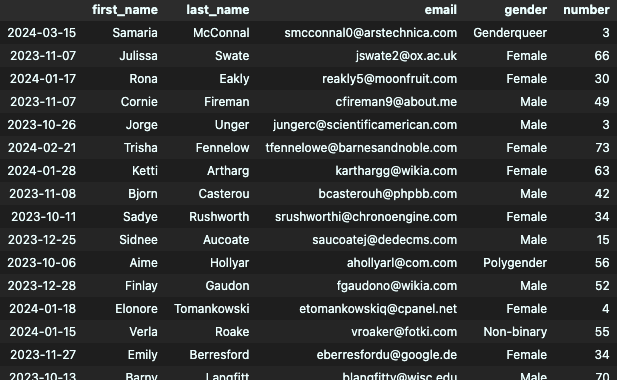
- dtype
데이터 타입을 지정하여 불러옴
df = pd.read_csv("week1_1.csv", dtype={'number':'object'})
df.dtypes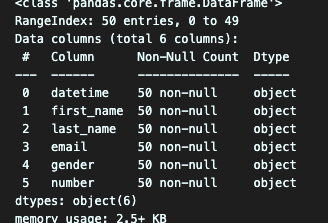
4. 데이터 불러오기 - API 활용한 XML Data 파싱
- xml 공공데이터 불러오기
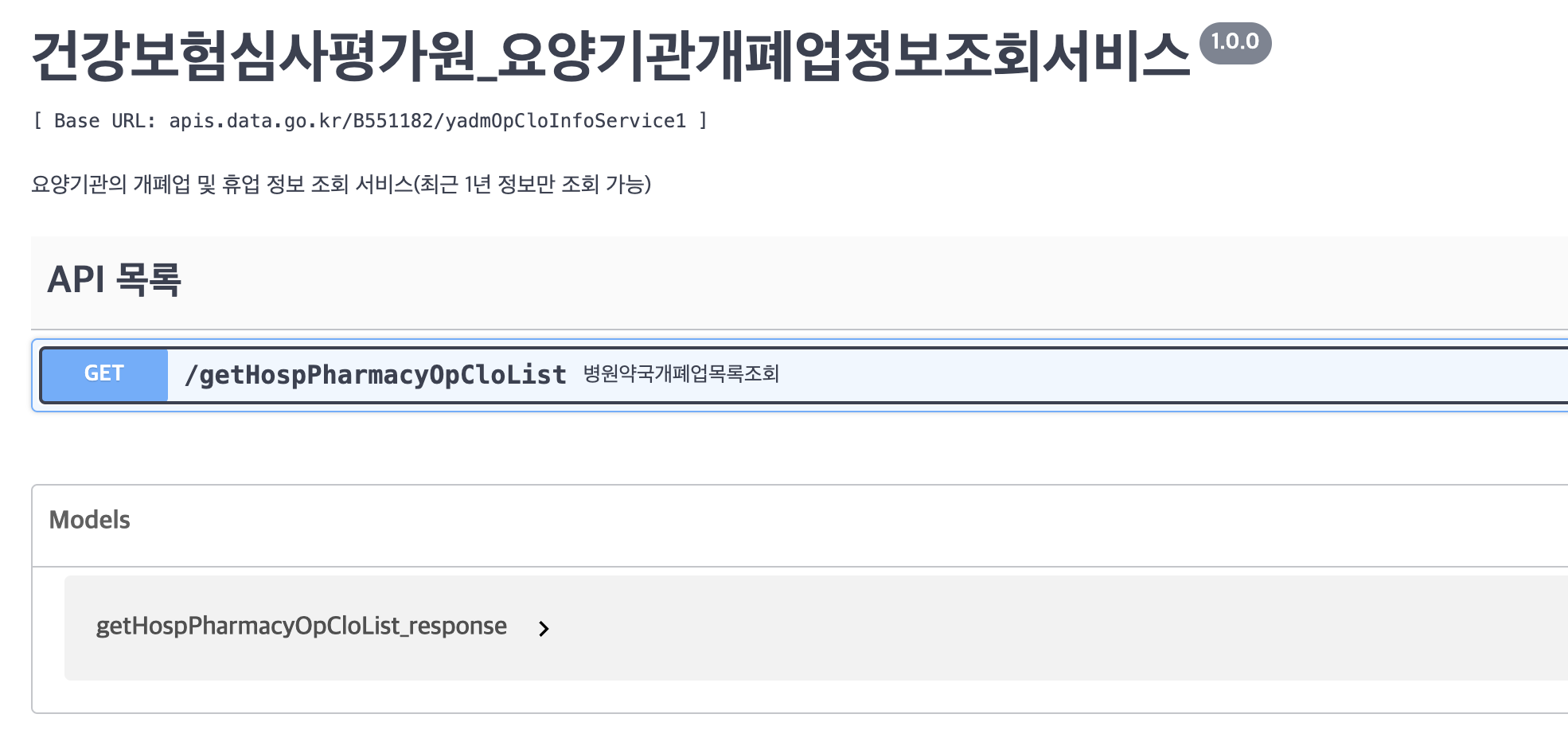
import requests
serviceKey = "~~~~~" # 일반 인증키 (Decoding)
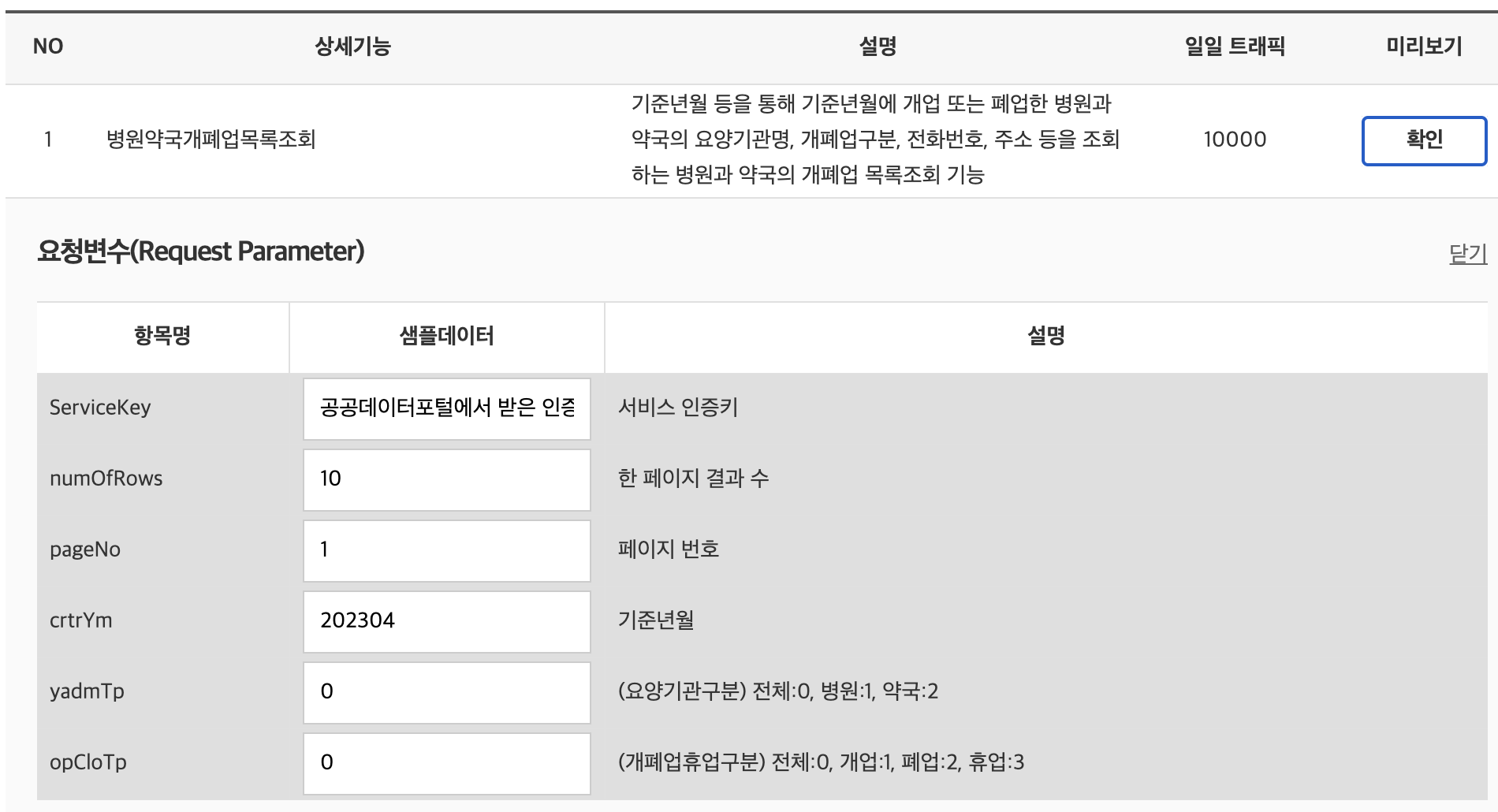
url = 'http://apis.data.go.kr/B551182/yadmOpCloInfoService1/getHospPharmacyOpCloList'
params ={'serviceKey' : serviceKey, 'numOfRows' : '10', 'pageNo' : '1', 'crtrYm' : '202401', 'yadmTp' : '0', 'opCloTp' : '0' }
response = requests.get(url, params=params)
# print(response.content) # bytes 형태여서 보기 힘듦.
content = response.content.decode('utf-8') # utf-8로 디코딩함.
df = pd.read_xml(response.content, xpath=".//item")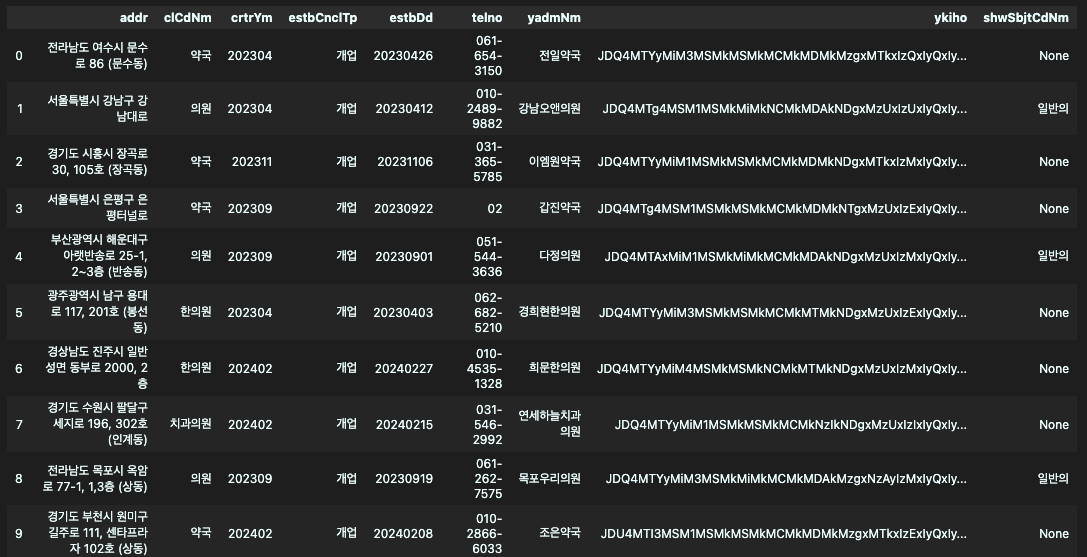
저장하기
- to_csv
df.to_csv('file_name.csv')
#저장한 파일이 글자가 깨졌다면
df.to_scv('file_name.csv', encoding = 'cp949')
#index 저장하지 않을 때
df.to_scv('file_name.csv', index = False)
#header 저장하지 않을 때
df.to_scv('file_name.csv', header = False)- mode
#파일이 이미 있을 경우 덮어쓰기
df.to_csv("file_name.csv", mode='w')
#파일이 이미 있을 경우 append하기 (모델 성능을 csv 파일로 저장할 때)
df.to_csv("file_name.csv", mode='a')
#파일이 이미 있을 경우 생성하지 않음
df.to_csv("file_name.csv", mode='x')
#tsv로 저장(자주사용하지 않음)
df.to_csv("file_name.tsv", sep = '\t')
잘 하고 있는겨?