코드를 외울 필요는 없지만, 문제를 해결하기 위해 어떤 라이브러리를 사용하고, 어떤 구문을 통해 데이터를 전처리 할 것인지 익혀야 할 것 같다.
미션
가장 수강을 많이 하는 지역을 데이터분석으로 찾기
- 문제 가설 정의하기 -> 데이터 분석 기본 셋팅하기 -> 데이터 분석하기 -> 시각화하기 -> 결론 도출
#1. 라이브러리 불러오기
#1-1. pandas 및 파일 불러오기
import pandas as pd
sparta_data = pd.read_table('/content/students_area_detail.csv',sep=',')
#1-2. 데이터 살펴보기
area_info.head()
#1-3. 지역 분류하기(set, len)
category_range = set(sparta_data['area'])
print(category_range, len(category_range))
#2. 데이터 전처리
#2-1. 접속지역, 지역위도, 지역경도만으로 이루어진 테이블 만들기
#새로운 테이블을 만들고자 할 땐 기존의 테이블에서 필요한 "열의 이름"을 대괄호에 넣어 변수에 지정해 주면 됩니다
area_info=sparta_data[['area','latitude','longitude']]
#잘 만들어졌는지 초기 5개의 데이터 확인하기
area_info.head()
#2-2. 서울, 대전과 같은 같은 지역의 위치는 동일하므로 중복되는 지역 없애주기
#drop_duplicates()을 이용하면, area(지역) 컬럼의 중복 데이터를 처리 할 수 있습니다. :)
area_info=area_info.drop_duplicates(['area'])
area_info
#2-3. 인덱스(목차) 재정렬해주기
#.reset_index()를 이용해, 인덱스를 재정렬 할 수 있어요!
area_info= area_info.reset_index()
area_info
#2-4. '지역이름' 기준으로 데이터 정렬하기
area_info = area_info.sort_values(by=["area"], ascending=[True])
area_info
#2-5. 각 지역의 학생 수 구하기
number_of_students = pd.DataFrame(sparta_data.groupby('area')['user_id'].count())
number_of_students
#2-6. 지역별 학생수를 기존 테이블과 합치기
#merge()를 이용하여, 두 테이블을 병합 할수 있어요 :)!
result = pd.merge(area_info, number_of_students, on="area")
result
#3. 시각화 하기
#3-1. matplotlib, numpy 라이브러리 가져오기
import matplotlib.pyplot as plt
import numpy as np
#3-2. 그래프 그리기(x = 지역, y = 학생수)
#그래프 사이즈 변경
plt.figure(figsize=(10,5))
#그래프 x축 y축
plt.plot(result['area'], result['user_id'])
#그래프 명
plt.title('지역별 사용자 수')
#그래프 x축 레이블
plt.xlabel('지역')
#그래프 y축 레이블
plt.ylabel('사용자(명)')
#x축 눈금 수
plt.xticks(np.arange(13))
#그래프 출력
plt.show()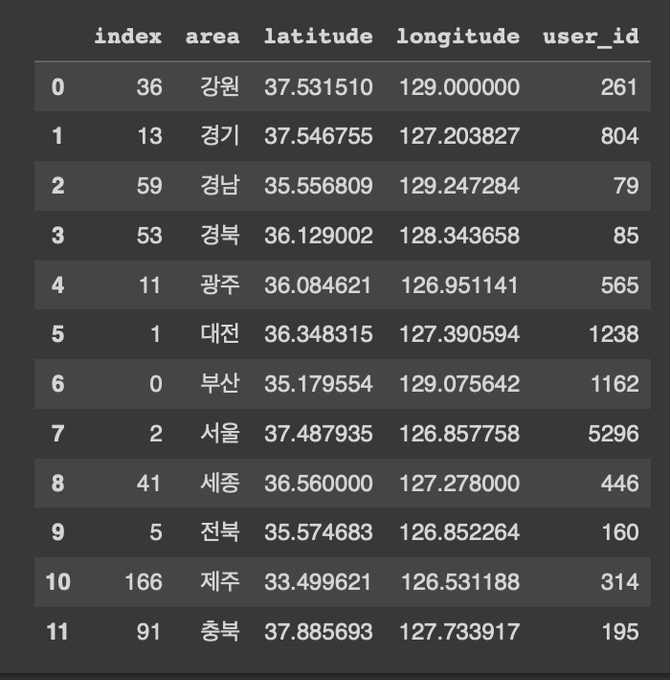
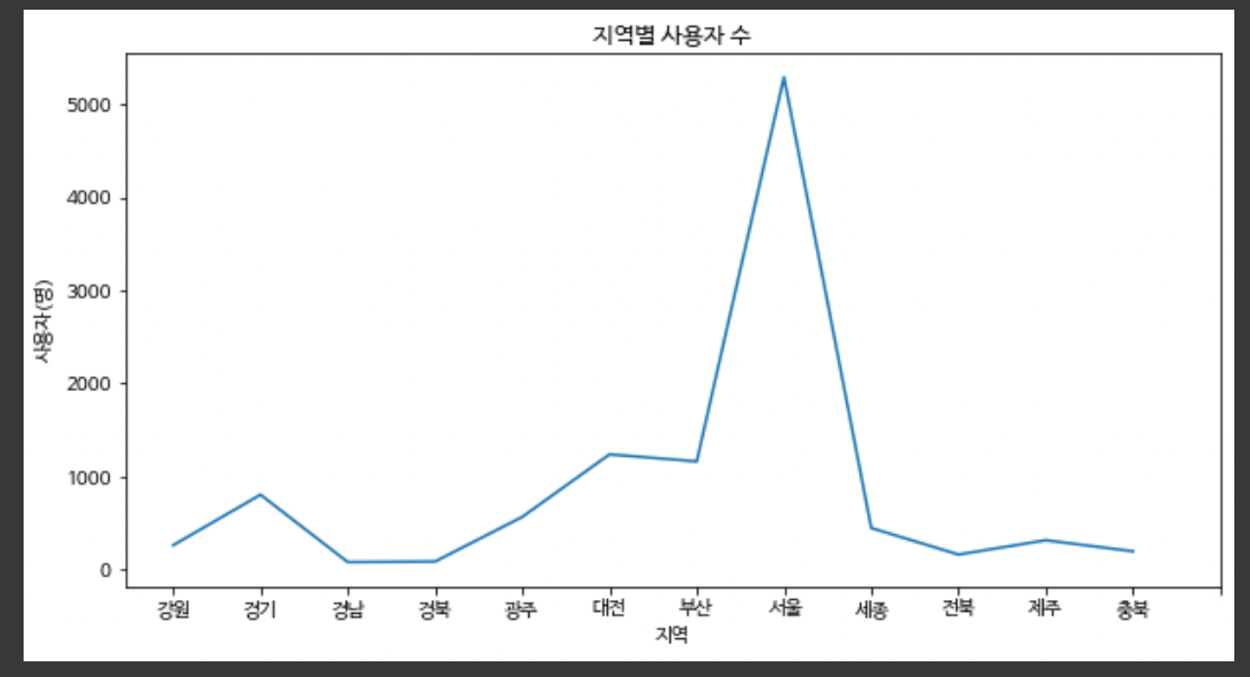
지도에 나타내보기
#1. folium 라이브러리 선언 import folium from folium.plugins import MarkerCluster #2. 대한민국 위도 경도 설정하기 m = folium.Map(location=[37.5536067,126.9674308], zoom_start=11) m #3. 반복문을 이용해 수강생 위치 찍어주기 for n in result.index: radius = result.loc[n,'user_id'] #loc[n,"열 이름"] => loc[]를 활용하여 n번째의 열을 조회 할수 있습니다! #즉, n번째의 user의 수를 가져 올수 있는 것이죠! folium.CircleMarker([result['latitude'][n],result['longitude'][n]], radius = radius/50, fill=True).add_to(m) #.add_to(m)를 활용하여, 지정해 두었던 우리나라의 지도를 가져올 수 있습니다! m
결론 : 서울 > 대전 > 부산 지역 순으로 수강생이 많다
과제
📖 스파르타코딩클럽은 튜터님들이 실시간으로 질문에 답변을 해주는 “즉문즉답”을 운영하고 있습니다. 우리는 수강생의 즉문즉답의 수요가 많은 요일을 알아내서 튜터님의 수를 요일에 따라 적절히 배치하고 싶은데요. 즉문 즉답은 궁금한 점을 튜터님께 질문하고 답을 얻는 시간이기 때문에, 많은 수강생들의 수강이 완료되는 시점을 아는 것이 중요합니다! 팀장님께서 '수강생들의 수업 완료 시간대는 주로 한가한 주말일 것이다'라는 가설을 세웠습니다. 이 가설을 증명을 해봅시다.
- 문제 정의 및 가설 설정하기 -> 데이터 분석 기본 세팅하기 -> 데이터 분석하기 -> 분석결과 시각화하기 -> 최종결론 내리기
- 가설 : 수강생들의 수업 완료 시간대는 주로 한가한 주말일 것이다.
#1. 데이터 가져오기
import pandas as pd
sparta_done = pd.read_table('/content/done_detail.csv',sep=',')#2. 데이터 확인하기
sparta_done.head() #3. 가설 검증을 위한 분석 설정 : done_date를 통해 수강 완료 요일의 user_id 갯수 합을 확인해보자.
#4. 데이터 전처리
#4-1.시간 데이터 전처리
print(type(sparta_done['done_date'][1]))
# >>> sparta_done의 done_date가 문자로 확인됨. -> 시간 데이터로 형태 변경
format='%Y-%m-%dT%H:%M:%S.%f'
sparta_done['done_date_time'] = pd.to_datetime(sparta_done['done_date'], format=format)
sparta_done.tail(5)
#4-2. 요일 추가해주기
sparta_done['done_date_time_weekday'] = sparta_done['done_date_time'].dt.day_name()
sparta_done.tail(5)
#4-3. 요일별 수강완료한 수강생 수 구하기
weeks = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekdata = sparta_done.groupby('done_date_time_weekday')['user_id'].count()
weekdata
# >>> 화요일에 가장 많이 수강을 완료함!
#4-4. 요일 순서대로 정렬해보기
weekdata = weekdata.agg(weeks)
weekdata
#5. 데이터 시각화
#5-1. matplotlib과 numpy 사용 선언하기
import matplotlib.pyplot as plt
import numpy as np
#그래프 사이즈
plt.figure(figsize=(10,5))
#그래프 x축 y축
plt.bar(weekdata.index, weekdata)
#그래프 명
plt.title('요일별 수강 완료한 수강생 수')
#그래프 x축 레이블
plt.xlabel('요일')
#그래프 y축 레이블
plt.ylabel('수강생(명)')
#x축 레이블을 90도로 변환
plt.xticks(rotation=90)
#그래프 출력
plt.show()
# >>> 요일별 수강완료 바그래프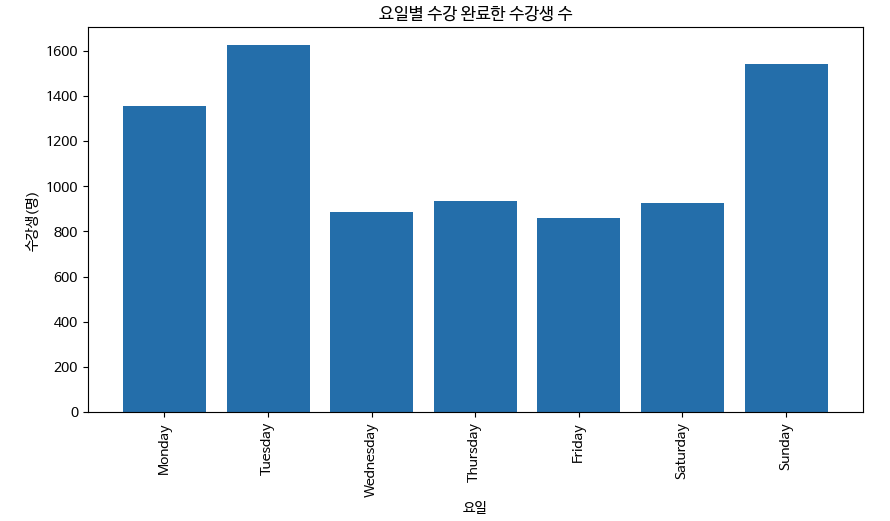
결론 : 화요일에 가장 많은 학생이 수강 완료함. 화요일에 튜터를 추가배치하는 것이 필요보인다.

잘 하고 있는겨?