강의 수강률 저조 원인 파악하기-타겟오류 검증
적절한 타겟에게 판매를 하고있는가?
🤔 현재 상황 살펴보기
1️⃣ 스파르타코딩클럽 광고의 메인 타겟은 2-30대입니다.
2️⃣ 2-30대의 구매 건수는 다른 나이대에 비해 높은 편입니다.
3️⃣ 이번에 완주 후 퀴즈를 제출하는 이벤트에서 2-30대의 참여율이 저조했습니다.
4️⃣ 퀴즈에 참여하지 않은 인원의 전화인터뷰에서 “바빠서”라는 답변이 압도적으로 많았습니다.
- 가설 세우기
- 다른 연령대에 비해 바쁜 20~30대의 수강 완주율이 상대적으로 낮을 것이다.
- 생각 정리하기
- [검증 방법]
- 나이대별 완주율을 비교한다
- [이후 액션]
- 2-30대가 실제로 완주율이 낮을 경우 프로덕트가 적절한 고객에게 가지 못해 불만족이 발생하고 있는 상황이므로 프로덕트를 개선하거나 광고 메인 타겟을 변경할 수 있다.
- 데이터 분석하기
#라이브러리 선언, 데이터 불러오기
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic') #한글 깨짐 방지 설정
sparta_data = pd.read_csv('sparta_data = pd.read_csv('/content/sprata_data.csv')
sparta_data.head()')
#마지막 5개의 데이터 확인 하기
sparta_data.tail()
#나이대 age와 진도율 progress_rate을 이용해 가설 검증, 나이대별 평균 진도율 구하기.
#나이대별로 수강률 합 구하기
progress_rate_by_age = sparta_data.groupby('age')['progress_rate'].sum()
progress_rate_by_age
#나이대별 수강인원 구하기
number_people_by_age = sparta_data.groupby('age')['_id'].count()
number_people_by_age
#나이대별 완주율 평균 구하기
average = progress_rate_by_age/number_people_by_age
average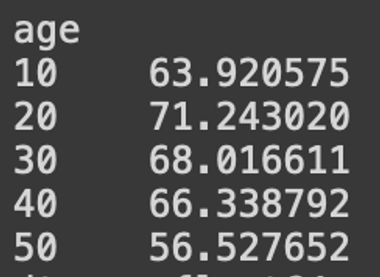
2. 시각화하기
#plt.figure(width, height) : 넓이와 높이 만큼 이미지를 생성한다는 것을 말해줍니다!
plt.figure(figsize=(6,6))
#그래프의 x축 눈금 설정
plt.xticks([10,20,30,40,50])
#plt.bar(X축값, Y축값)
plt.bar(average.index, average)
#그래프의 바에 각 수치율을 추가 해 볼까요?
bar = plt.bar(average.index, average, width=8)
for rect in bar:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width()/2.0, height, '%.1f' % height, ha='center', va='bottom', size = 12)
#그래프의 제목
#타이틀과 그래프와의 간격은 pad= 수치 로 나타내어요!
plt.title('[나이대 별 평균 수강율]',fontsize=15,pad=20)
#그래프의 x축 라벨 이름
#labelpad 파라미터는 축 레이블의 여백을 지정합니다.
plt.xlabel('나이',fontsize=12,labelpad=20)
#그래프의 y축 라벨 이름
plt.ylabel('수강생(명)',fontsize=14,rotation=360,labelpad=35)
#그래프를 화면에 나타나도록 합니다.
plt.show()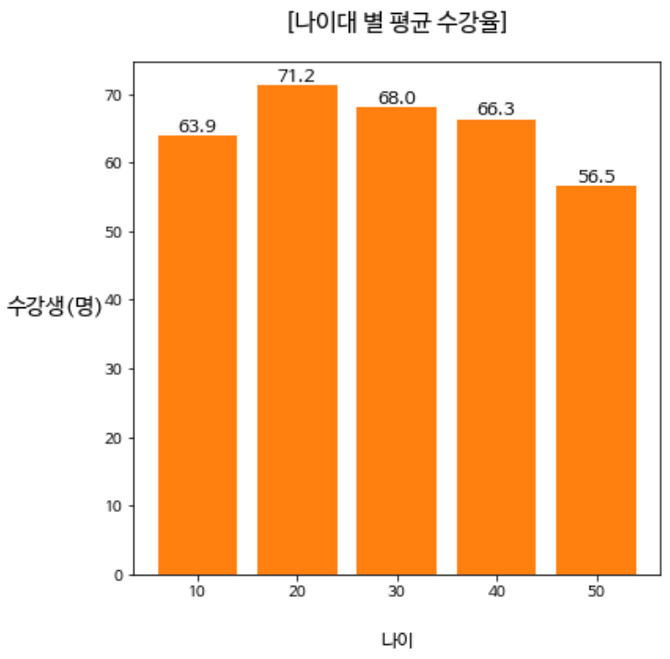
3. 결론도출
20대 30대의 평균 수강률이 가장 높기 때문에 2030에게 적절하게 판매하고 있다. 광고 타겟등을 변경할 필요는 없다.
강의 수강률 저조 원인 파악하기-찐한관리와 완주율
- 가설세우기
🤔 현재 상황 살펴보기 최근 3개월간 찐한관리 신청 비율과 완주율이 모두 감소하고 있다.
가설설정 : 찐한관리를 받은 인원이 그렇지 않은 인원보다 완주율이 높을 것이다.
- 분석하기
#라이브러리 불러오기
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')
sparta_data = pd.read_csv('/content/sprata_data.csv')
sparta_data.head()
#managed로 찐한관리 여부 확인.
managed = ['TRUE','FALSE'] # 데이터 수정하기
managed
#관리 여부에 따라, 수강완료율 평균 구하기
managed_data_avg = sparta_data.groupby('managed')['progress_rate'].sum()/sparta_data.groupby('managed')['_id'].count()
managed_data_avg
#plt.figure(width, height) : 넓이와 높이 만큼 이미지를 생성한다는 것을 말해줍니다!
plt.figure(figsize=(6,6))
#각각 어떤 값이 들어가야 하는지 입력해 볼까요?
#plt.bar(X축값, Y축값)
plt.bar("x축 기입" ,"y축 기입")
#그래프의 바에 각 수치율을 추가 해 볼까요?
bar = plt.bar(managed_data_avg.index, managed_data_avg)
for rect in bar:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width()/2.0, height, '%.1f' % height, ha='center', va='bottom', size = 12)
#그래프의 제목
plt.title('찐한관리 유무에 따른 평균 완주율',fontsize=14)
#그래프의 x축 라벨 이름
plt.xlabel('평균 완주율',fontsize=12)
#x축 눈금 레이블 지정하기
#기존의 0,1이라는 x축 레이블을, labels =["..."]로 변경 가능 합니다 :)
plt.xticks([0,1], labels=["찐한관리 비 신청자","찐한관리 신청자"])
#그래프의 y축 라벨 이름
plt.ylabel('찐한관리 여부',fontsize=12,rotation=360,labelpad=35)
#x축 눈금의 글씨를 45도 회전
plt.xticks(rotation=45)
#y축 눈금의 글씨를 360도 회전
plt.yticks(rotation=360)
#그래프를 화면에 나타나도록 합니다.
plt.show()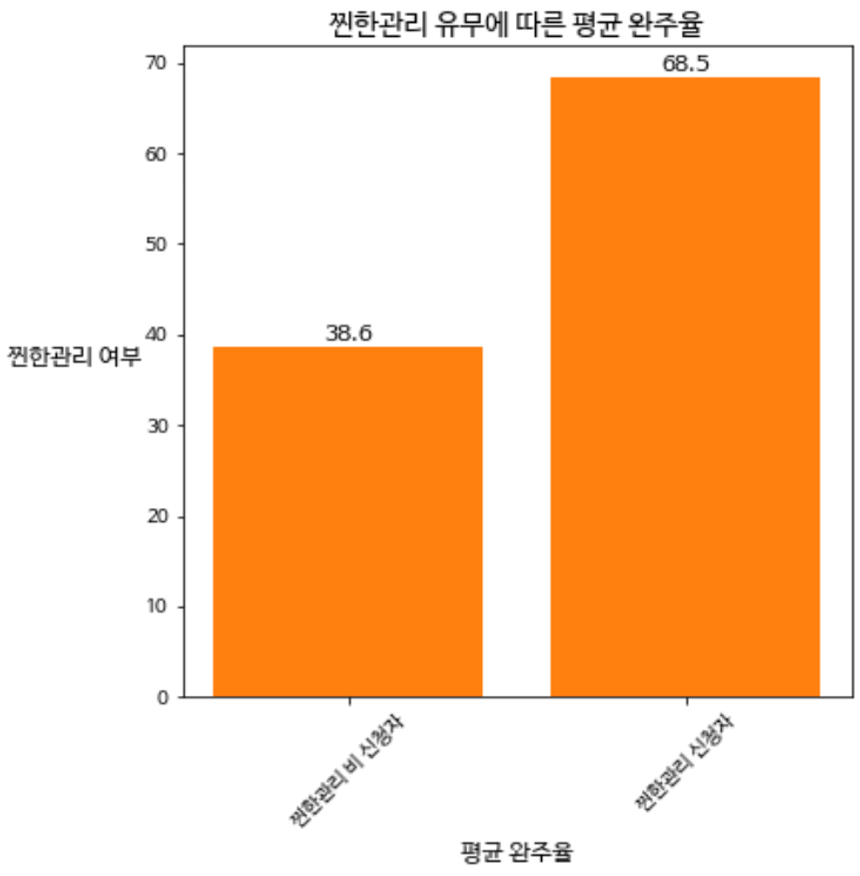
3. 결론도출 : 찐한관리 신청자의 평균 강의 완주율이 월등히 높다. 완주율 상승을 위해 수강생의 찐한관리 신청 비율을 높여야 한다.
강의 수강률 저조 원인 파악하기-프로덕트 개선원인
- 가설세우기
✔️ 목표한 만큼 강의 컨텐츠를 모두 수강 완료하는 것에 도움을 주려면
콘텐츠가 충분히 흥미있고 유익해야 합니다. 이 부분을 확인해볼까요?
→ 앗 이미 8월 즈음 콘텐츠 개편이 완료되어 적용된 상황입니다.
→ 흠.. 8월이라.. 완주율이 꺾인 시점과 유사한데 좀 더 파볼까요?
🤔 현재 상황 살펴보기
8월 2주 차 개강반부터 새로 제작된 3주차 콘텐츠를 듣기 시작했습니다.가설설정 : 8월 둘째 주 부터 변경된 3주 차 강의의 완주율이 현저히 떨어졌을 것이다.
- 데이터 분석
#라이브러리 불러오기
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')
sparta_data = pd.read_table('/content/cohort_data.csv',sep=',')
#파이썬의 type()함수를 쓰면, 데이터의 종류를 확인 할수 있어요 :)
print(type(sparta_data['created_at'][1]))
#sparta_date 정보에서 access_date 열에서 데이터 첫번째 부분만 확인 하면 되겠죠?
format='%Y-%m-%dT%H:%M:%S.%f'
sparta_data['start_time'] = pd.to_datetime(sparta_data['created_at'], format=format,infer_datetime_format=True)
#수강 시작 주 구하기
sparta_data['start_week']= sparta_data['start_time'].dt.isocalendar().week
#이전에 배웠듯이 set()은 set안의 데이터는 순서가 정해져있지 않고, 중복되지 않는 고유한 요소를 가져옵니다!
category_range = set(sparta_data['start_week'])
progress_rate = list(sparta_data['progress_rate'])
#범주를 구분하는 기준 bins 처음(0)과 끝(100) 잊지 말고 기입 해주세요!
bins = [0,4.11,26.03,41.10,61.64,80.82,100]
#구분한 범주의 라벨 labels
labels=[0,1,2,3,4,5]
#범주화에 사용하는 함수 pd.cut
cuts = pd.cut(progress_rate,bins, right=True,include_lowest=True, labels=labels)
cuts
#결과물을 테이블로 변경하기
cuts = pd.DataFrame(cuts)
cuts.tail()
#concat() 함수를 이용하여, sparta_data 테이블과, cuts 테이블 병합 할수 있습니다 :)
sparta_data = pd.concat([sparta_data,cuts],axis=1, join='inner')
sparta_data.head()
#그래서, 귀찮더라도, 우리가 원하는 컬럼의 이름을 다 작성해 줍시다!
sparta_data.columns=['created_at','user_id','name','progress_rate','start_time','start_week',"week"]
sparta_data.head()
#기존의 테이블을, start_week와, week로 묶어줍니다!
grouping = sparta_data.groupby(['start_week','week'])
grouping.head()
cohort_data = grouping['user_id'].apply(pd.Series.nunique)
cohort_data = pd.DataFrame(cohort_data)
cohort_data.head(20)
#첫 주가 31주니 변수를 하나 만들어 줍니다!
f=31
#처음 수강 시작한 주의 범위가 {31,32,33,34,35,36} 이니, range(6)으로 합시다!
for i in range(6):
#5주차의 강의가 마지막이고, 0주차까지 이니, 시작은 5에서 시작해 1씩 0까지 감소 시킬수 있어요!
for j in range(5, 0, -1):
cohort_data.at[(f,j-1), 'user_id'] = int(cohort_data.at[(f,j),'user_id']) + int(cohort_data.at[(f,j-1),'user_id'])
#주차는(31부터 32 33..) 1씩 늘어나죠?
f=f+1
cohort_data = cohort_data.reset_index()
cohort_data.head()
3. 피벗테이블 만들기
cohort_counts = cohort_data.pivot(index="start_week",
columns="week",
values="user_id")
cohort_counts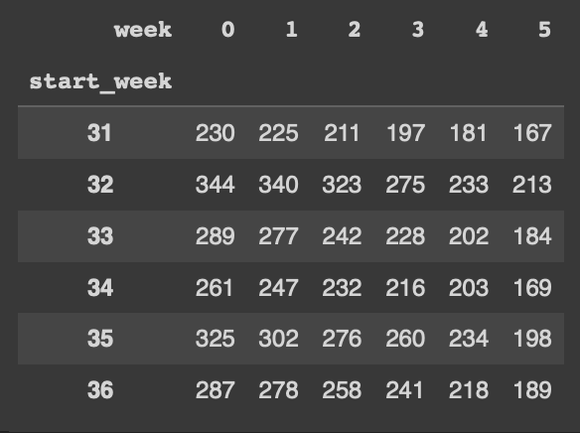
4. 리텐션테이블 만들기
# 앞서 만든 피벗 테이블을 retention 변수에 저장하기
retention = cohort_counts
#각 주(week) 별 최초 수강생 수만 가져오기 (나눠줄때, 분모가 되는 부분!)
cohort_sizes = cohort_counts.iloc[:,0]
cohort_sizes.head()
# 표의 단일 데이터에 최초 수강생의 수를 나누어, 각 주당 수강생 수강율 나타내기!
retention = cohort_counts.divide(cohort_sizes, axis=0)
retention.head()
#각 수치 퍼센트로 변경하기
#round 함수로 3자리 수에서 반올림 한 후, 100을 곱해 줍니다!
retention.round(3)*100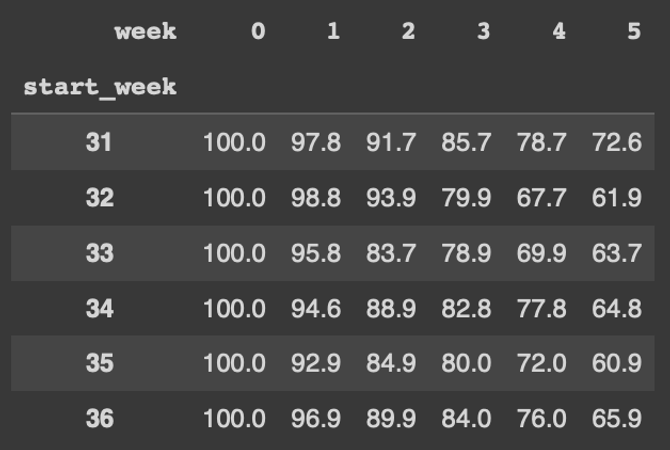
- 시각화하기
#테이블 크기 설정 하기
plt.figure(figsize=(10,8))
sns.heatmap(data=retention,
annot=True,
fmt='.0%',
vmin=0,
vmax=1,
cmap="BuGn")
plt.xlabel('주차', fontsize=14,labelpad=30)
plt.ylabel('개강일', fontsize=14,rotation=360,labelpad=30)
plt.yticks(rotation=360)
plt.show()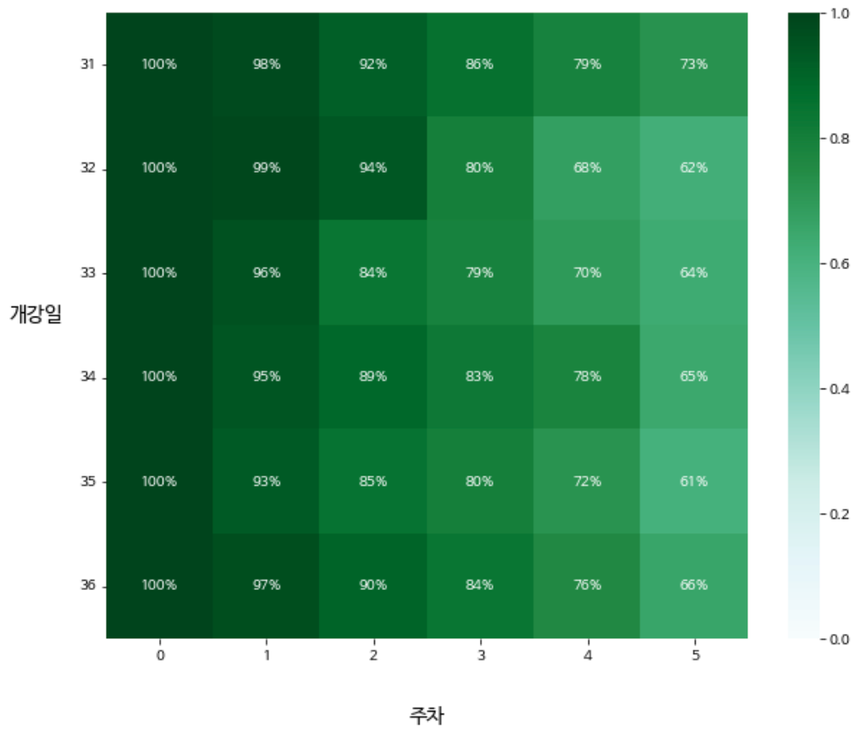
- 결론도출 : 8월 3주차 이후 확연하게 눈에 띄는 변화를 찾기 어렵기 때문에 바뀐 8월 3주차의 컨텐츠로 인해 수강률이 저조해졌다고 단정 짓기 어렵다. 3주차 다른 요인으로 인해 완주율이 떨어졌다고 보아야 한다.

잘 하고 있는겨?