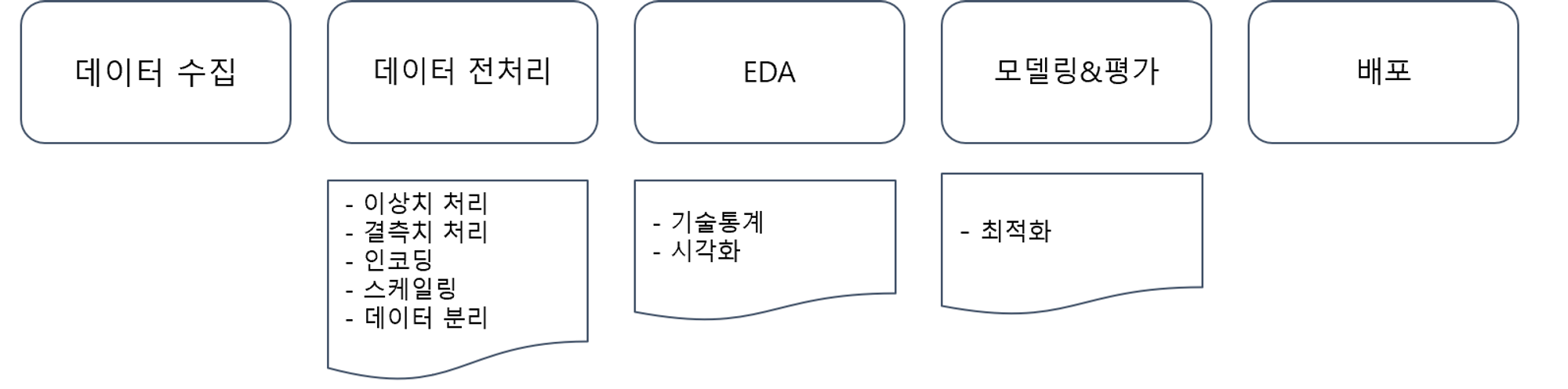
예측모델링 프로세스
- 앞서 회귀분석은
모델링&평가부분을 다룸 - 평가 이전 데이터 전처리와 EDA에 대한 학습을 통해 전체적인 예측모델링 프로세스를 다뤄본다.
데이터 수집
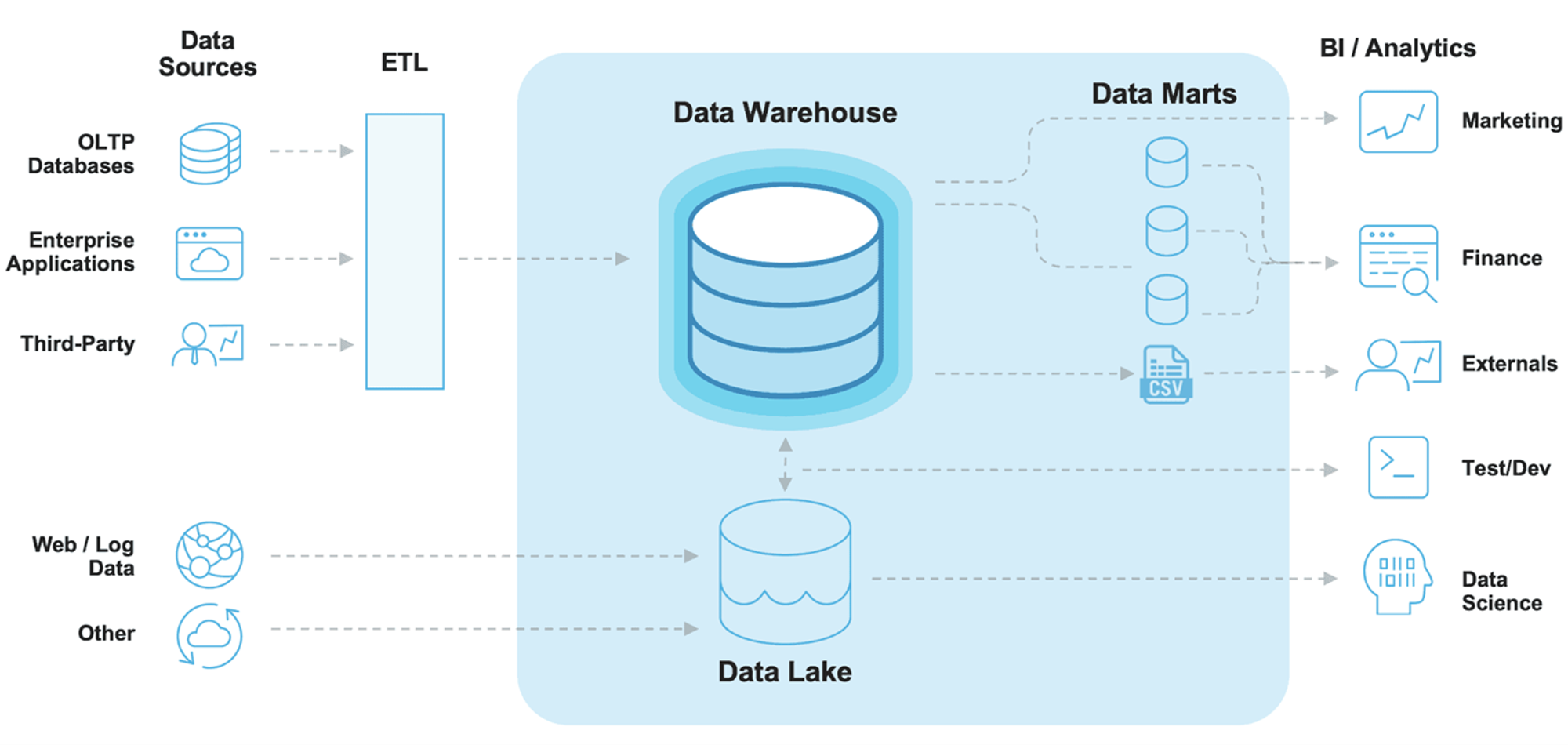
- 데이터 수집, 적재 : 데이터 엔지니어
- 이미 존재하는 데이터를 SQL, Python 등으로 추출, 리포팅, 머신러닝 예측 : 데이터 분석가
- Data Source
- OLTP Database: OnLine Transaction Processing 은 온라인 뱅킹,쇼핑, 주문 입력 등 동시에 발생하는 다수의 트랜잭션(데이터베이스 작업의 단위) 처리 유형
- Enterprise Applications: 회사 내 데이터 (ex 고객 관계 데이터, 제품 마케팅 세일즈)
- Third - Party: Google Analytics와 같은 외부소스에서 수집되는 데이터
- Web/Log: 사용자의 로그데이터
- ETL : Extract, Transform, Load
- Data Lake: 원시 형태의 다양한 유형의 데이터를 저장(원천데이터)
- Data Warehouse: 보다 구조화된 형태로 정제된 데이터를 저장
- Data Marts: 회사의 금융, 마케팅, 영업 부서와 같이 특정 조직의 목적을 위해 가공된 데이터
- BI/Analytics: business Intelligence(BI)는 의사결정에 사용될 데이터를 수집하고 분석하는 프로세스
현업에서는 이미 저장되어있는 Data Warehouse를 사용한다.
기존에 저장되어있지 않다면
1) csv, excel 다운
2) api를 통한 데이터 수집
3) data crawling
등을 통해 수집하여 분석한다.
탐색적 데이터 분석 EDA
- 데이터의 시각화, 기술통계 등의 방법을 통해 데이터를 이해하고 탐구하는 과정
- 데이터에 대한 정보를 얻을 수 있으며, 적절한 모델링 정보도 얻을 수 있음
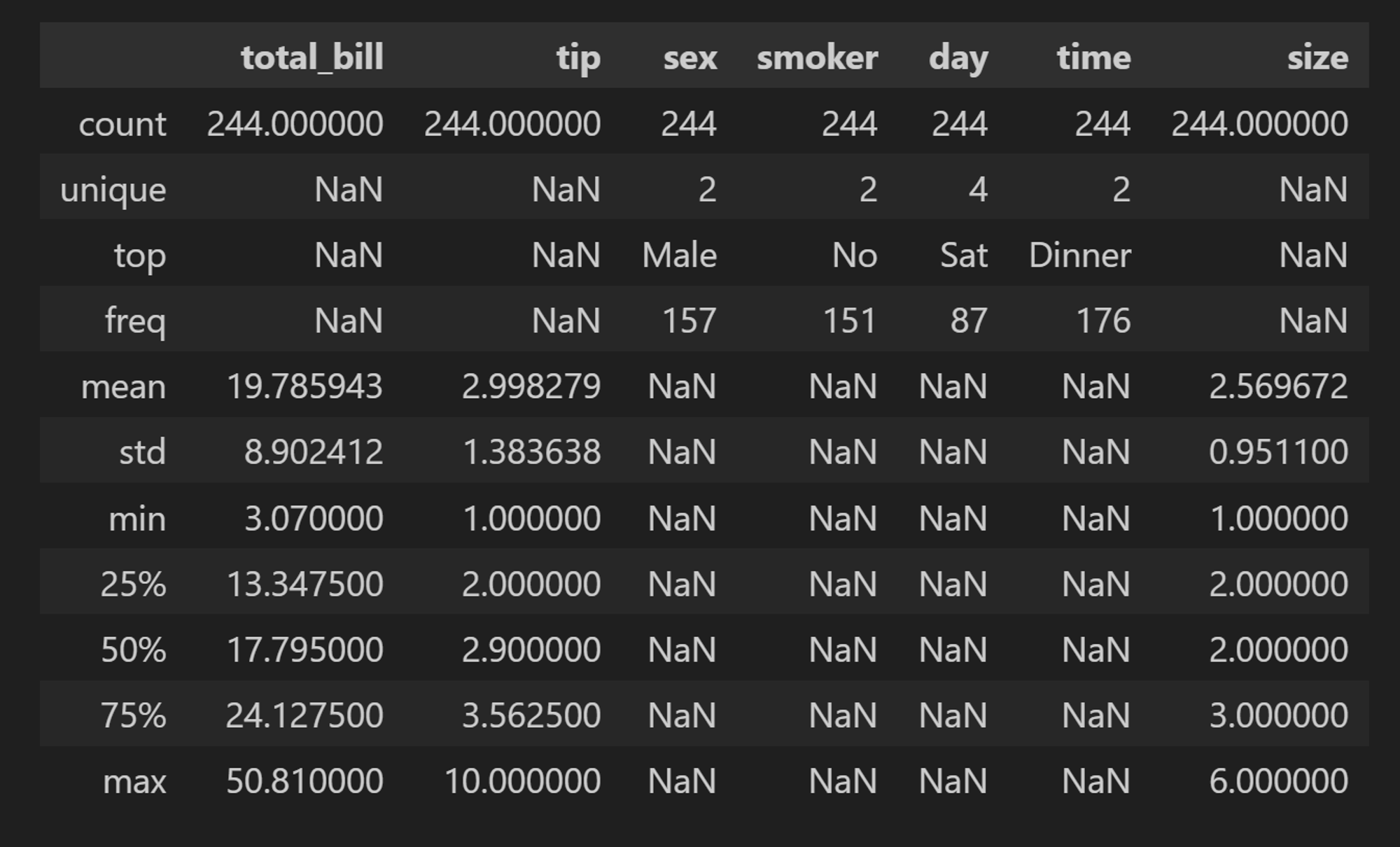
기술통계를 통한 EDA
- ex.
describe(),info() - 최대/최소값, 분포, 이상치 등을 파악
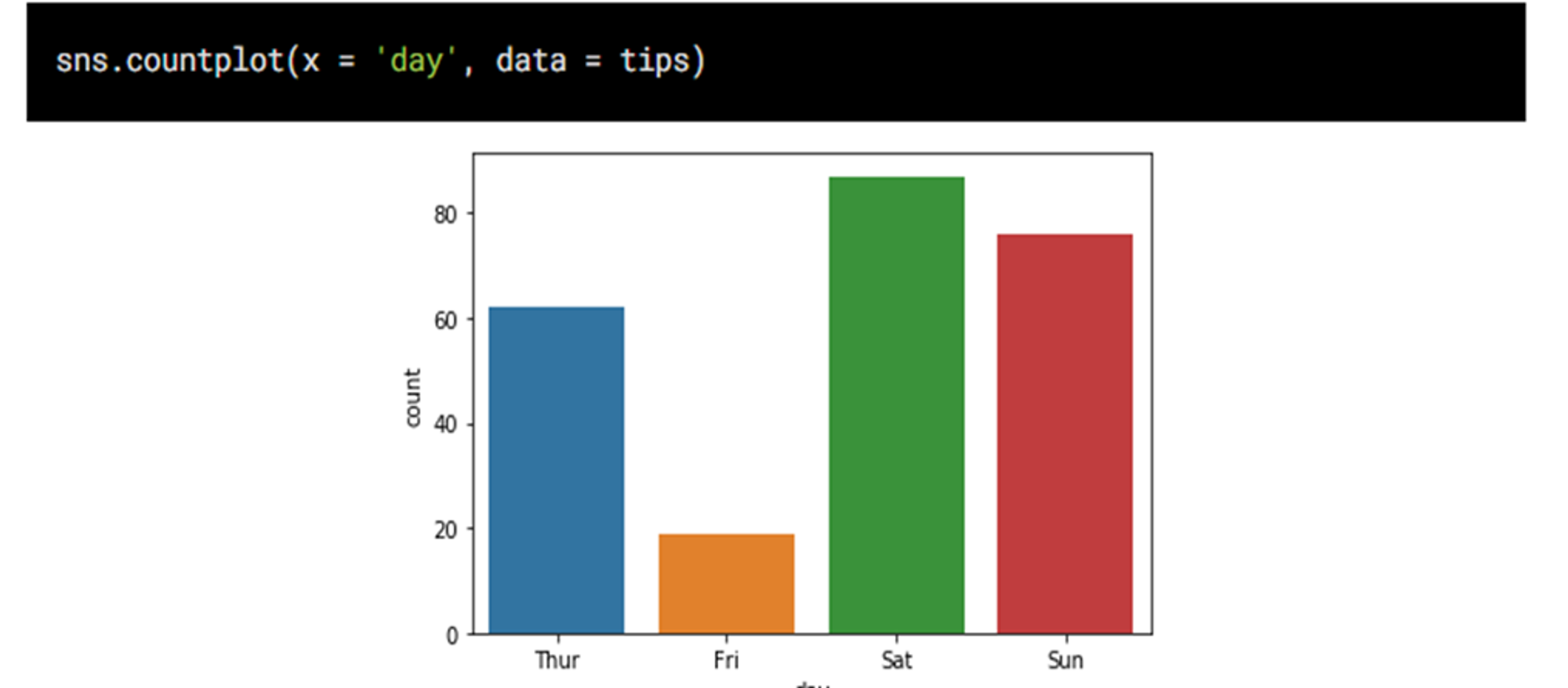
시각화를 통한 EDA
- 범주형 자료, 수치형 자료를 적절한 그래프로 표현하여 한눈에 파악해보기
- seaborn, matplotlib 라이브러리 사용
- 그래프 종류
- countplot : 범주형자료 갯수 파악
- barplot : 범주형, 연속형 자료
- boxplot : 범주형, 수치형 자료(중앙값, 분포, 사분위수, 이상치 탐색)
- histplot : 수치형 자료 빈도
- scatterplot : 수치형끼리
- pairplot : 한번에 여러개의 변수 동시 시각화
데이터 전처리
이상치(Outlier)
관측된 데이터 범위에서 많이 벗어난 아주 작은 값 또는 큰 값
1. ESD로 이상치 탐색
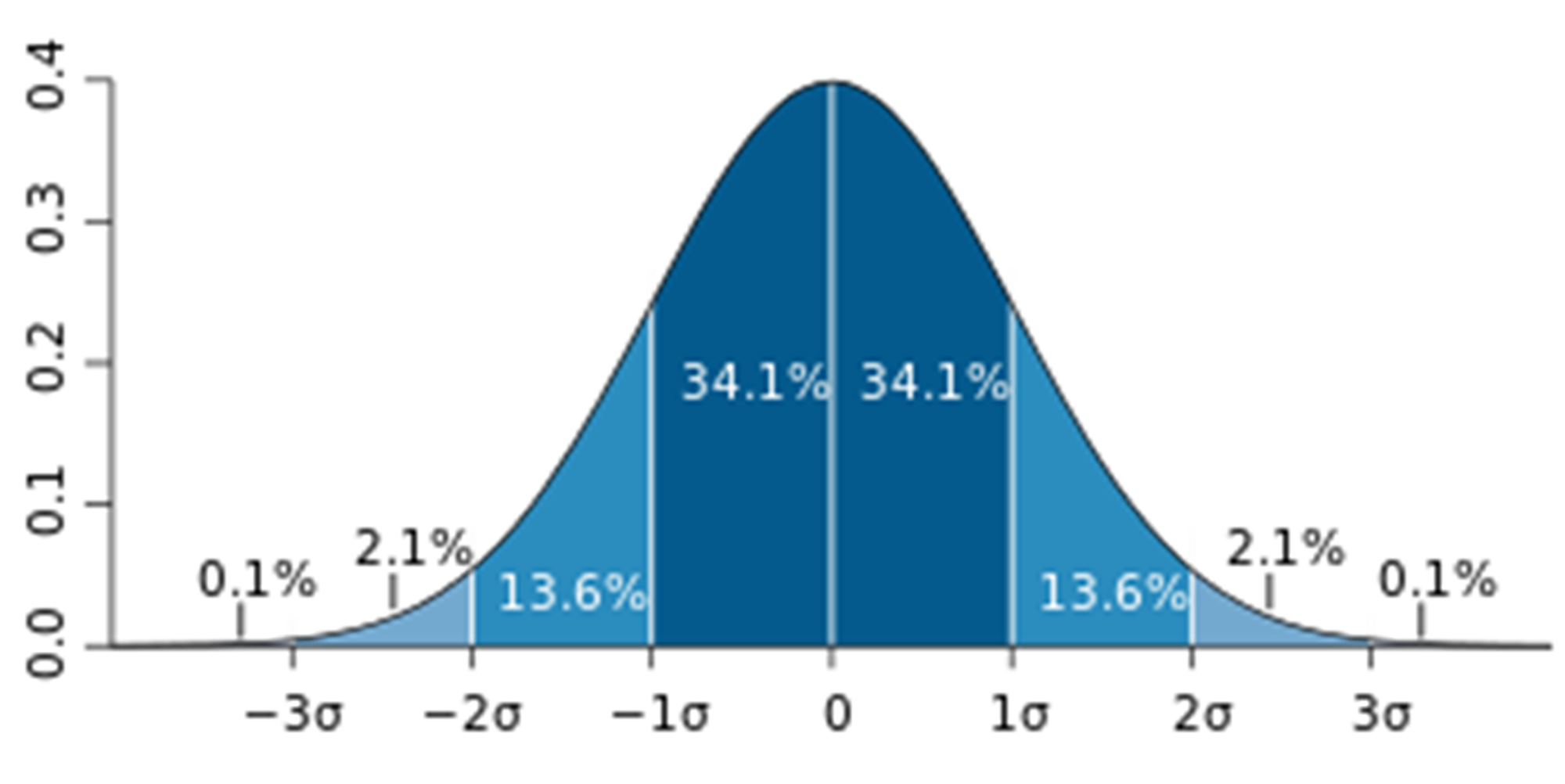
- Extreme Studentized Deviation
- 정규분포를 이용한 이상치 탐색
- 정규분포의 평균에서 표준편차의 3배 이상 떨어진 값
- 데이터가 너무 비대칭적이거나 샘플크기가 적다면 사용하기 무리
- ESD를 이용한 이상치 처리
import numpy as np
mean = np.mean(data)
std = np.std(data)
upper_limit = mean + 3*std
lower_limit = mean - 3*std2. IQR로 이상치 탐색
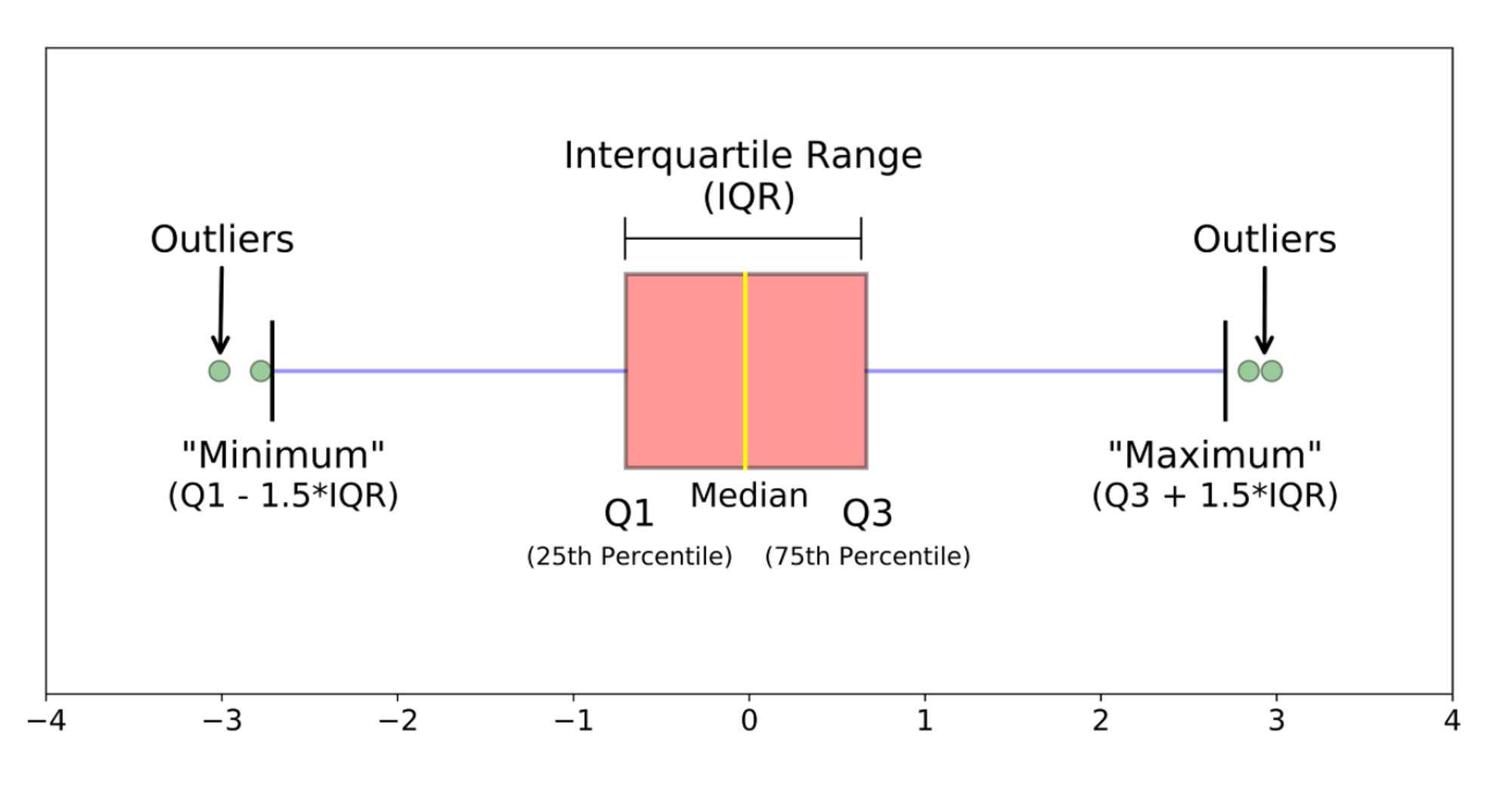
- Inter Quantitle Range
- boxplot 그래프
- IQR = Q3 - Q1
- 상한이상치 : Q3 + 1.5 * IQR
- 하한이상치 : Q1 - 1.5 * IQR
- IQR을 이용한 이상치 처리
Q1 = df['column'].quantile(0.25)
Q3 = df['column'].qunatile(0.75)
IQR = Q3 - Q1
uppper_limit = Q3 + 1.5*IQR
lower_limit = Q1 - 1.5*IQR결측치(Missing Value)
: 존재하지 않는(NaN, null) 데이터
범주형 자료 결측치 처리
- 최빈값 대치
- 사용 함수
- 간단한 삭제 & 대치
df.dropna(axis = 0): 행 삭제df.dropna(axis = 1): 열 삭제- Boolean Indexing
df.fillna(value): 특정 값으로 대치(평균, 중앙, 최빈값)
- 알고리즘을 이용
sklearn.impute.SimpleImputer:평균, 중앙, 최빈값으로 대치SimpleImputer.statistics_: 대치한 값 확인 가능
sklearn.impute.IterativeImputer: 다변량대치(회귀 대치)sklearn.impute.KNNImputer: KNN 알고리즘을 이용한 대치
- 간단한 삭제 & 대치
수치형 자료 결측치 처리
- 평균값 대치
- 중앙값 대치
범주형 전처리(인코딩)
인코딩 : 어떤 정보를 정해진 규칙에 따라 변환하는 것
레이블 인코딩
- 범주형 값을 고유한 숫자로 할당(ex. 성별, 좌석등급 등)
- 장점 : 모델이 처리하기 쉬운 수치형으로 데이터 변환
- 단점 : 순서간 크기에 의미가 부여되어 모델이 잘못 해석될 수 있음
- 사용함수
sklearn.preprocessing.LabelEncoder- 메소드
fit: 데이터 학습transform: 정수형 데이터로 변환fit_transform: fit과 transform을 연결하여 한번에 실행inverse_transform: 인코딩된 데이터를 원래 문자열로 변환
- 속성
classes_: 인코더가 학습한 클래스(범주)
원-핫 인코딩
- 각 범주를 이진 형식으로 변환하는 기법(ex. 빨/파/초 등 명목형)
- 장점: 각 범주가 독립적으로 표현되어, 순서가 중요도를 잘못 학습하는 것을 방지, 명목형 데이터에 권장
- 단점: 범주 개수가 많을 경우 차원이 크게 증가(차원의 저주) , 모델의 복잡도를 증가, 과적합 유발
- 사용 함수
pd.get_dummiessklearn.preprocessing.OneHotEncoder- 메소드(LabelEncoder와 동일)
fit: 데이터 학습transform: 정수형 데이터로 변환fit_transform: fit과 transform을 연결하여 한번에 실행inverse_transform: 인코딩된 데이터를 원래 문자열로 변환
categories_: 인코더가 학습한 클래스(범주)get_feature_names_out(): 학습한 클래스 이름(리스트)
- 메소드(LabelEncoder와 동일)
# CSR 데이터 데이터프레임으로 만들기
csr_df = pd.DataFrame(csr_data.toarray(), columns = oe.get_feature_names_out())
# 기존 데이터프레임에 붙이기(옆으로)
pd.DataFrame([titaninc_df,csr_df], axis = 1) 수치형 전처리(스케일링)
: 각자 단위값이 다른 수치형 데이터를 보정하는 작업
표준화(Standardization)
- 평균을 0 표준편차를 1로 조정하는 방법
- 장점
- 이상치가 있거나 분포가 치우처져 있을 때 유용
- 모든 특성의 스케일을 동일하게 맞춤, 많은 알고리즘에서 좋은 성능
- 단점 : 데이터의 최소-최대 값이 정해지지 않음
- 사용함수
sklearn.preprocessing.StandardScaler- 메소드
fit: 데이터학습(평균과 표준편차를 계산)transform: 데이터 스케일링 진행
- 속성
mean_: 데이터의 평균 값scale_,var_: 데이터의 표준 편차,분산 값n_features_in_: fit 할 때 들어간 변수 개수feature_names_in_: fit 할 때 들어간 변수 이름n_samples_seen_: fit 할 때 들어간 데이터의 개수
정규화(Normalization)
- 데이터를 0과 1사이 값으로 조정(최소값 0, 최대값 1)
- 장점
- 모든 특성의 스케일을 동일하게 맞춤
- 최대-최소 범위가 명확
- 단점 : 이상치에 영향을 많이 받을 수 있음(이상치가 없을 때 유용함)
- 사용함수
sklearn.preprocessing.MinMaxScaler- (표준화와 공통인 것은 제외)
- 속성
-data_min_: 원 데이터의 최소 값
-data_max_: 원 데이터의 최대 값
-data_range_: 원 데이터의 최대-최소 범위
데이터 분리
과대적합
- 데이터를 너무 과도하게 학습한 나머지 해당 문제만 잘 맞추고 새로운 데이터를 제대로 예측 혹은 분류하지 못하는 현상
- 과적합 원인
- 모델의 복잡도
- 데이터의 양이 충분하지 않음
- 학습 반복이 많음(딥러닝의 경우)
- 데이터 불균형(정상환자 - 암환지 비율이 95:5)
과적합 해결 - 테스트 데이터의 분리
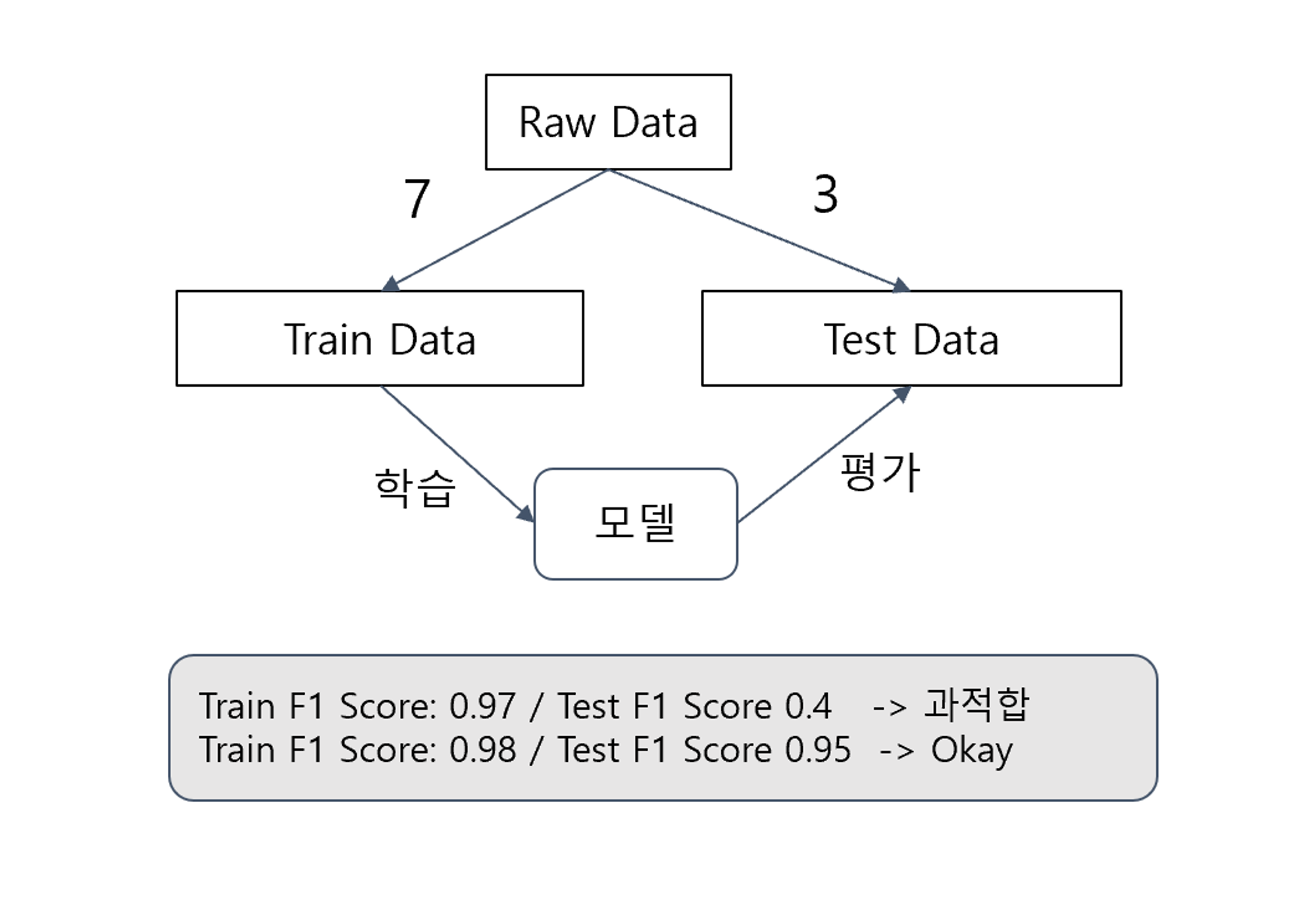
- Train Data : 모델을 학습(fit)하기 위한 데이터
- Test Data : 모델을 평가하기 위한 데이터
- 함수 및 파라미터 설명
sklearn.model_selection.train_test_split- 파라미터
test_size: 테스트 데이터 세트 크기 (3)train_size: 학습 데이터 세트 크기 (7)shuffle: 데이터 분리 시 섞기random_state: 호출할 때마다 동일한 학습/테스트 데이터를 생성하기 위한 난수 값. 수행할 때 마다 동일한 데이터 세트로 분리하기 위해 숫자를 고정 시켜야 함stratify: 원본의 비율에 맞게 Train Data와 Test Data의 비율을 맞추어줌. 불균형이 심할 때 사용함.
- 반환 값(순서 중요)
X_train,X_test,y_train,y_test
- 파라미터
데이터 분석 프로세스 정리
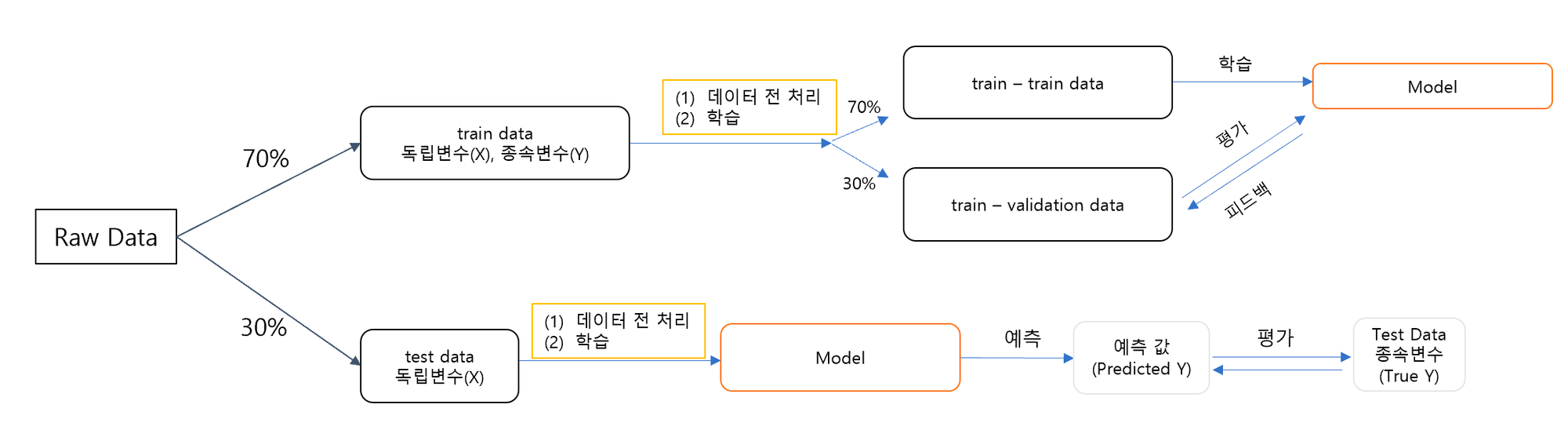
실습 데이터 따라하고 보면서 이해하기

잘 하고 있는겨?