👩🏻💻 학습한 것
- 비지도학습 개념 : 정답을 알려주지 않고 데이터간 유사성으로 정답을 지정하는 것.
- Kmeans Clustering 군집화
- RFM으로 고객 세그멘테이션
- 고객 군집화의 방법
- Recency 구하기
- 불균형 군집화에 대한 로그스케일 적용
- 군집화모델 평가 : 실루엣 스코어
1. 비지도학습
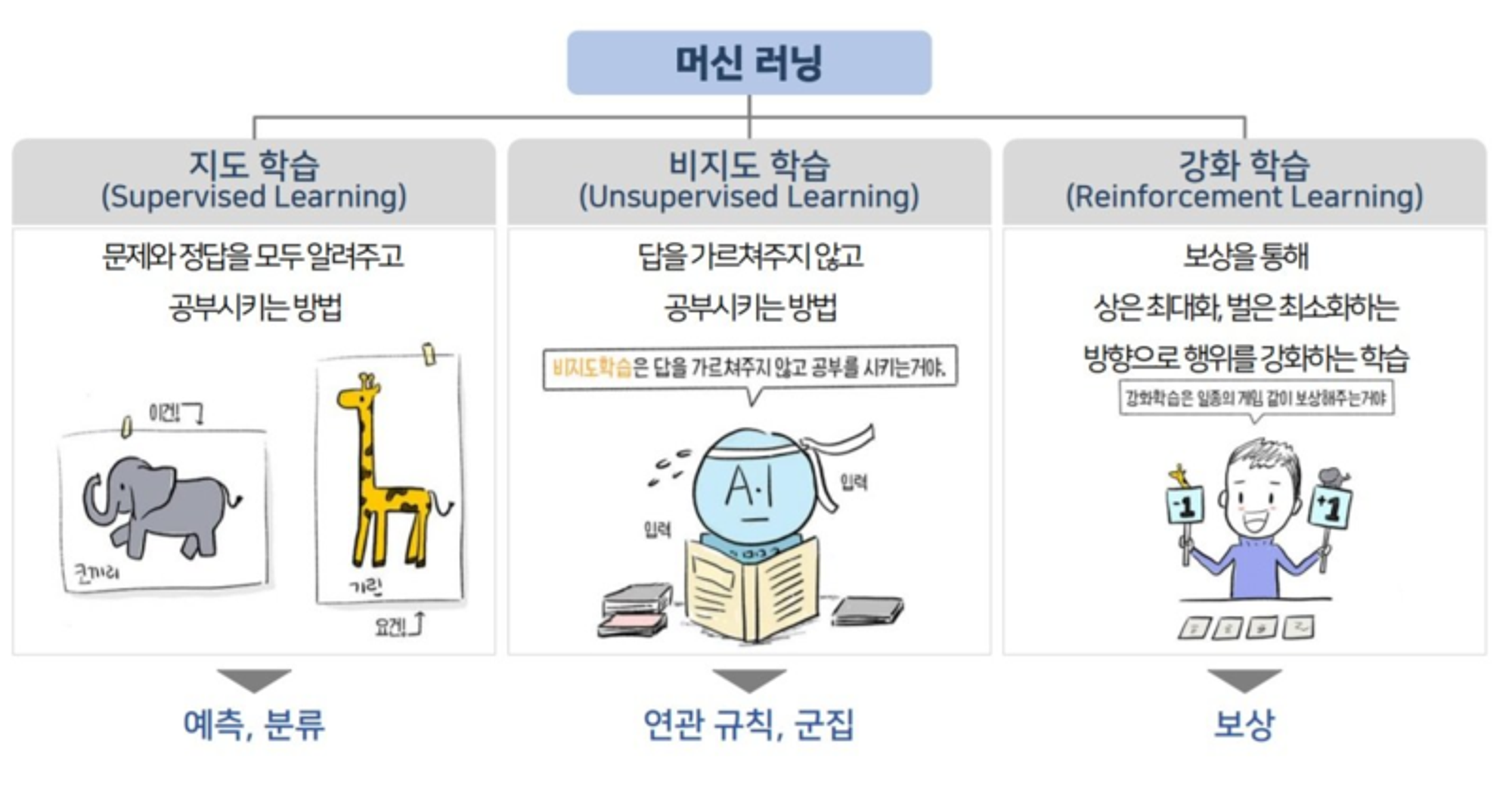
지도학습과 비지도학습
- 지도학습 : 문제(X)와 정답(Y)가 주어지고 정답(Y)를 맞추는 학습
- 비지도학습 : 정답(Y)를 알려주지 않고 데이터간 유사성을 이용해서 정답(Y)을 지정하는 방법
2. K-Means Clustering
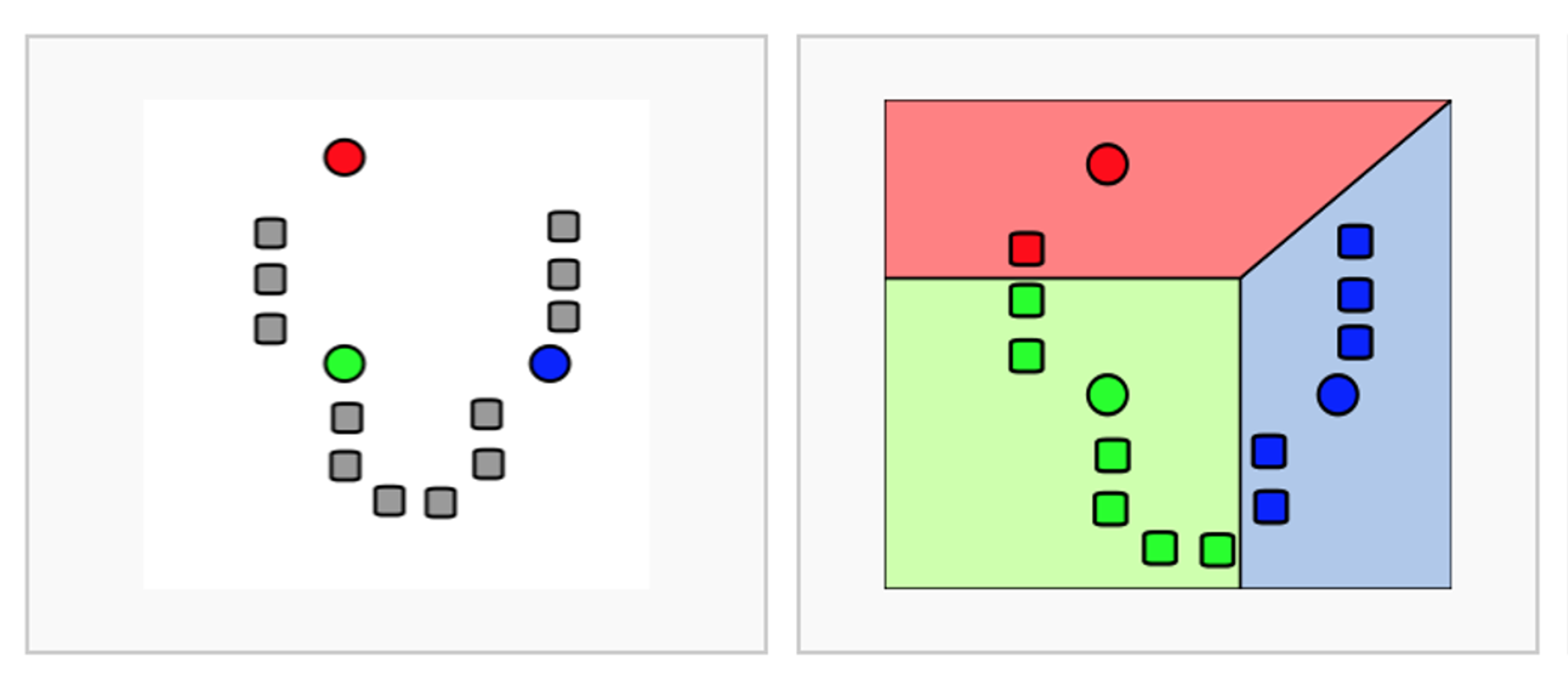
K-Means 수행순서
- K개 군집 수 설정
- 임의의 중심을 선정
- 해당 중심점과 거리가 가까운 데이터를 그룹화
- 데이터의 그룹의 무게 중심으로 중심점을 이동
- 중심점을 이동했기 때문에 다시 거리가 가까운 데이터를 그룹화
(3~5번 반복)
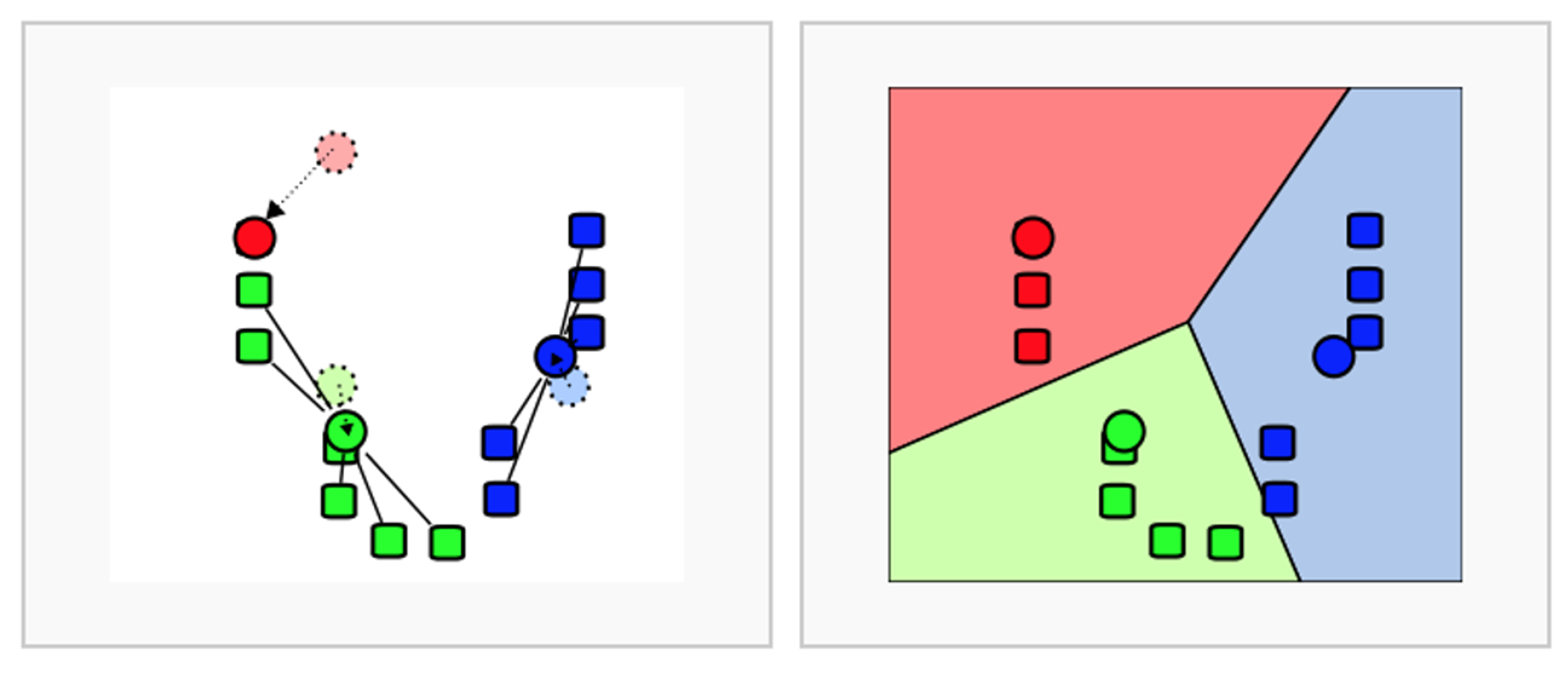
-> 좀 무식한 방법이라 할 수 있음
K-Means 정리
- 장점
- 일반적이고 적용하기 쉬움
- 단점
- 거리 기반으로 가까움을 측정하기 때문에 차원이 많을 수록 정확도가 떨어짐
- 반복 횟수가 많을 수록 시간이 느려짐
- 몇 개의 군집(K)을 선정할지 주관적임
- 평균을 이용하기 때문에(중심점) 이상치에 취약함
- Python 라이브러리
sklearn.cluster.KMeans- 함수 입력 값
n_cluster: 군집화 갯수max_iter: 최대 반복 횟수
- 메소드
labels_: 각 데이터 포인트가 속한 군집 중심점 레이블cluster_centers: 각 군집 중심점의 좌표
- 함수 입력 값
3. 군집평가 지표 - 실루엣계수
실루엣 계수란 ?
비지도 학습 특성상 답이 없기 때문에 평가를 하기 쉽지 않다.
다만, 군집화가 잘 되어있다는 것은 다른 군집간의 거리가 떨어져 있고 동일한 구집끼리는 가까이 있다는 것을 의미한다.
실루엣 분석(Silhouette Analaysis) : 군집간의 거리가 얼마나 효율적으로 분리되어잇는지 측정
실루엣 계수 특징
- 수식:
- 해석: 1로 갈수록 근처의 군집과 더 멀리 떨어짐. 0에 가까울 수록 근처 군집과 가까워 진다는 것
- Python 라이브러리
sklearn.metrics.sihouette_score: 전제 데이터의 실루엣 계수 평균 값 반환- 함수 입력 값
X: 데이터 세트labels: 레이블metrics: 측정 기준 기본은euclidean
- 함수 입력 값
좋은 군집화의 조건
- 실루엣 값이 높을수록(1에 가까울 수록)
- 0에 가까울수록 클러스터링 불확실
- 음수값은 클러스터링 결과가 잘못됨
- 개별 군집의 평균 값의 편차가 크지 않을 수록
4. 붓꽃 데이터 군집화
- 원본 데이터 분포 확인
import pandas as pd
import seaborn as sns
import sklearn
import matplotlib.pyplot as plt
iris_df = sns.load_dataset('iris')
iris_df.head(3)
sns.scatterplot(data = iris_df, x = 'sepal_length', y = 'sepal_width')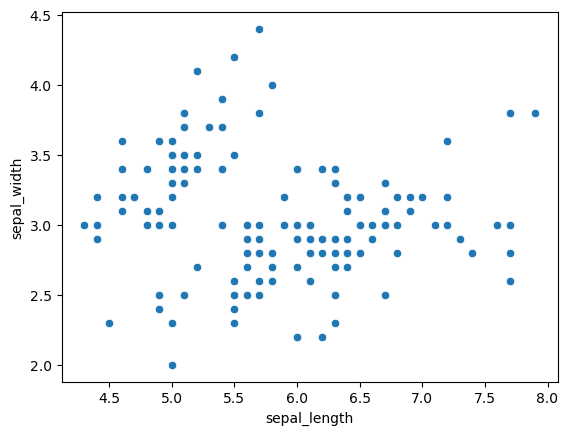
- KMeans 모델 학습 및 예측
iris_df_2 = iris_df.copy().drop(columns = 'species')
iris_df_2.head(3)
from sklearn.cluster import KMeans
X = iris_df_2[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']]
kmeans = KMeans(n_clusters = 3, random_state=42, init = 'k-means++', max_iter= 300)
kmeans.fit(X) #비지도학습이기 때문에 y값을 넣어주지 않음
iris_df_2['cluster'] = kmeans.predict(X)
iris_df_2.head(3) 
- 그래프 비교
plt.figure(figsize = (12, 6))
plt.subplot(1, 2, 1)
sns.scatterplot(data = iris_df, x = 'sepal_length', y = 'sepal_width', hue = 'species')
plt.title('Original')
plt.subplot(1, 2, 2)
sns.scatterplot(data = iris_df_2, x = 'sepal_length', y = 'sepal_width', hue = 'cluster', palette = 'winter')
plt.title('Clustering')
plt.show()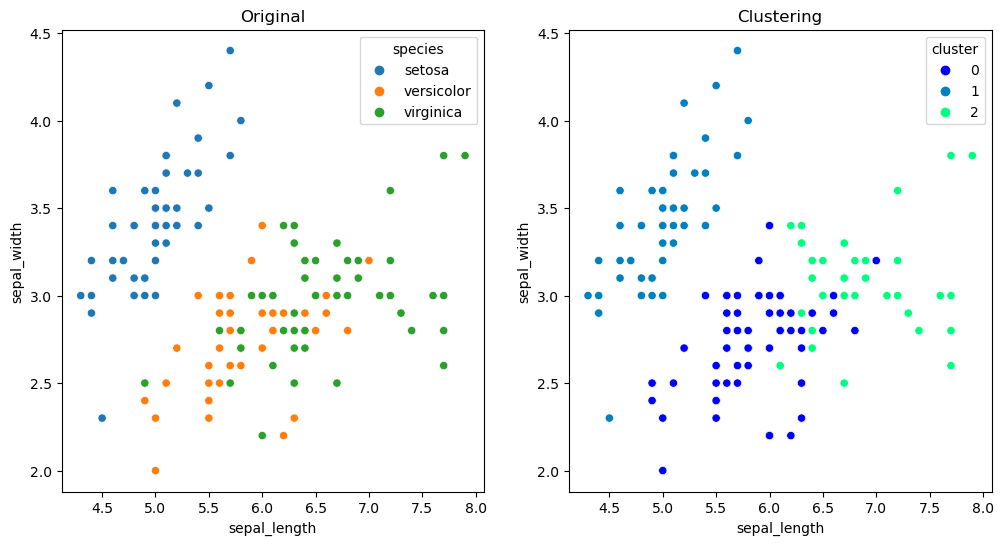
왼쪽 그래프는 군집화 그래프와 비교해보기 위해 species를 그려본 것.
1번 군집은 잘 군집화 된 것으로 보임
- 평가지표 - 실루엣 계수
from sklearn.metrics import silhouette_score
silhouette_score(X, iris_df_2['cluster'])0.5528190123564097
이 수준이면 클러스터링이 잘 되었다고 판단할 수 있다고 gpt가 말해주었다.
5. RFM 고객 군집화 실습
고객 세그멘테이션 정의
비지도 학습이 가장 많이 사용되는 곳이 고객관리(CRM)
타겟마케팅을 위해 고객 특성에 맞게 세분화할 수 있다.
RFM
- Recency(R) 가장 최근 구입 일에서 오늘까지의 시간
- Frequency(F): 상품 구매 횟수
- Monetary value(M): 총 구매 금액
- 데이터 불러오기 및 전처리를 위한 확인과정
import pandas as pd
import matplotlib.pyplot
import seaborn as sns
import sklearn
retail_df = pd.read_excel('/Users/sookyeong/Desktop/Online Retail.xlsx')
retail_df.isnull().sum()
retail_df.describe(include = 'all')- 전처리 대상
- customerid , description null값 삭제
- quantity, unitprice (-)값 삭제
- county 영국 대상
con_customer = retail_df['CustomerID'].notnull()
con_quan = retail_df['Quantity'] > 0
con_price = retail_df['UnitPrice'] > 0
con_county = retail_df['Country'] == 'United Kingdom'
retail_df2 = retail_df[con_customer & con_quan & con_price & con_county]- RFM
- R : 최근방문일 : InvoiceDate 컬럼 사용해 가장최근(2011-12-09 + 1)일에서 고객별 최신방문일 빼줌
- F : 방문빈도 : 고객별 방문건수
- M : 구매합계 --> 고객별 amount_monetary
#매출총합
retail_df2['amount_monetary'] = retail_df2['Quantity'] * retail_df2['UnitPrice']
retail_df2['amount_monetary'] = retail_df2['amount_monetary'].astype('int')
#최근방문경과일
import datetime as dt
#2011.12.10일 기준으로 각 날짜를 빼고 + 1
# 추후 customerid 기준으로 period의 최소의 period를 구하면 그것이 recency
retail_df2['Period'] = (dt.datetime(2011, 12, 10) - retail_df2['InvoiceDate']).apply(lambda x : x.days + 1)
retail_df2
#고객별 RFM
rfm_df = retail_df2.groupby('CustomerID').agg({'Period' : 'min',
'InvoiceNo' : 'count',
'amount_monetary' : 'sum'})
rfm_df.columns = ['Recency', 'Frequency', 'Monetary']
rfm_df
- 분포도 확인 및 스케일링
sns.pairplot(rfm_df)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X = rfm_df[['Recency', 'Frequency', 'Monetary']]
X_features = sc.fit_transform(X)
X_features- KMeans 군집화
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
kmeans = KMeans(n_clusters = 3, random_state = 42)
labels = kmeans.fit_predict(X_features)
rfm_df['label'] = labels
silhouette_score(X_features, labels) -- 0.592575402996014- 군집화 그래프를 위한 함수
### 여러개의 클러스터링 갯수를 List로 입력 받아 각각의 실루엣 계수를 면적으로 시각화한 함수 작성
def visualize_silhouette(cluster_lists, X_features):
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
# 입력값으로 클러스터링 갯수들을 리스트로 받아서, 각 갯수별로 클러스터링을 적용하고 실루엣 개수를 구함
n_cols = len(cluster_lists)
# plt.subplots()으로 리스트에 기재된 클러스터링 수만큼의 sub figures를 가지는 axs 생성
fig, axs = plt.subplots(figsize=(4*n_cols, 4), nrows=1, ncols=n_cols)
# 리스트에 기재된 클러스터링 갯수들을 차례로 iteration 수행하면서 실루엣 개수 시각화
for ind, n_cluster in enumerate(cluster_lists):
# KMeans 클러스터링 수행하고, 실루엣 스코어와 개별 데이터의 실루엣 값 계산.
clusterer = KMeans(n_clusters = n_cluster, max_iter=500, random_state=0)
cluster_labels = clusterer.fit_predict(X_features)
sil_avg = silhouette_score(X_features, cluster_labels)
sil_values = silhouette_samples(X_features, cluster_labels)
y_lower = 10
axs[ind].set_title('Number of Cluster : '+ str(n_cluster)+'\n' \
'Silhouette Score :' + str(round(sil_avg,3)) )
axs[ind].set_xlabel("The silhouette coefficient values")
axs[ind].set_ylabel("Cluster label")
axs[ind].set_xlim([-0.1, 1])
axs[ind].set_ylim([0, len(X_features) + (n_cluster + 1) * 10])
axs[ind].set_yticks([]) # Clear the yaxis labels / ticks
axs[ind].set_xticks([0, 0.2, 0.4, 0.6, 0.8, 1])
# 클러스터링 갯수별로 fill_betweenx( )형태의 막대 그래프 표현.
for i in range(n_cluster):
ith_cluster_sil_values = sil_values[cluster_labels==i]
ith_cluster_sil_values.sort()
size_cluster_i = ith_cluster_sil_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i) / n_cluster)
axs[ind].fill_betweenx(np.arange(y_lower, y_upper), 0, ith_cluster_sil_values, \
facecolor=color, edgecolor=color, alpha=0.7)
axs[ind].text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
y_lower = y_upper + 10
axs[ind].axvline(x=sil_avg, color="red", linestyle="--")- 그래프 함수적용1.
visualize_silhouette([2,3,4,5,6], X_features)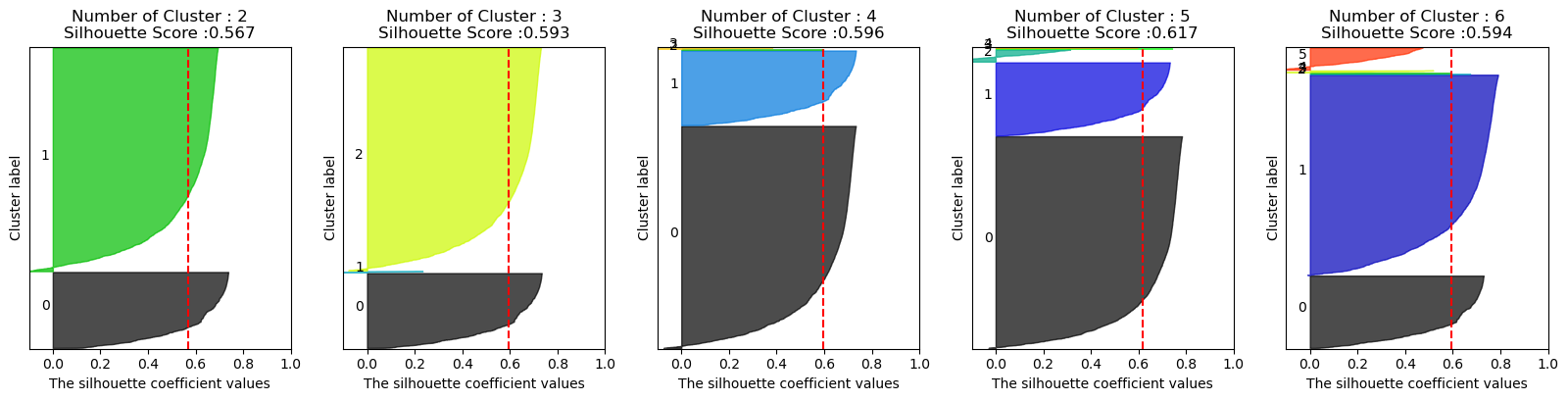
실루엣 스코어는 높은데 군집의 불균형이 너무 심함
-> 로그 스케일 적용
- 그래프 함수적용2. 로그 스케일
#log 스케일을 통한 추가전처리
import numpy as np
rfm_df['Recency_log'] = np.log1p(rfm_df['Recency'])
rfm_df['Frequency_log'] = np.log1p(rfm_df['Frequency'])
rfm_df['Monetary_log'] = np.log1p(rfm_df['Monetary'])
X_features2 = rfm_df[['Recency_log','Frequency_log','Monetary_log']]
sc2 = StandardScaler()
X_features2_sc = sc2.fit_transform(X_features2)
visualize_silhouette([2,3,4,5,6], X_features2_sc)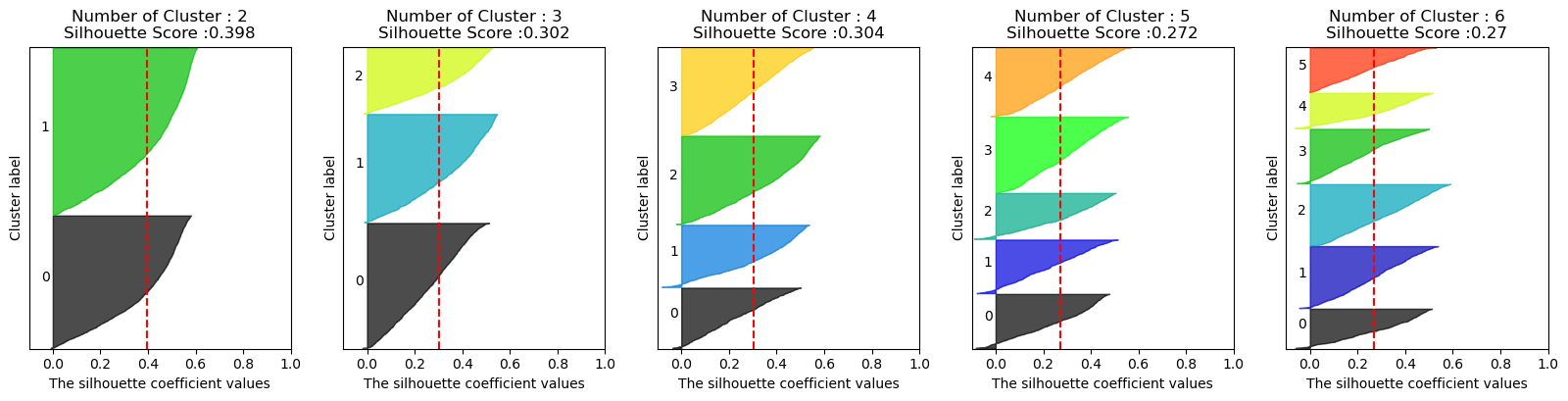
실루엣 스코어는 줄었지만 군집화가 균일하게 잘 적용됨을 확인 할 수 있음.

잘 하고 있는겨?