회귀 알고리즘과 모델 규제
농어의 무게 예측
지도학습 알고리즘의 종류
분류와 회귀
- 분류 : 샘플을 몇 개의 클래스 중 하나로 구분하는 것
- 회귀 : 임의의 어떤 숫자를 예측하는 것 - 두 변수 사이의 상관관계를 분석하는 방법
예시) 크기와 사이즈를 판단하여 생선의 종류를 구분하는 것이 분류, 생선의 종류, 나이, 수온, 먹이분포 등을 수치화하여 생선의 최대 크기나 무게 등을 예측하는 것이 회귀
농어 회귀 분석
K-최근접 이웃 회귀
- 예측하려는 샘플에 가장 가까운 샘플 k개를 선택하고 선택한 샘플의 수치의 평균을 도출.
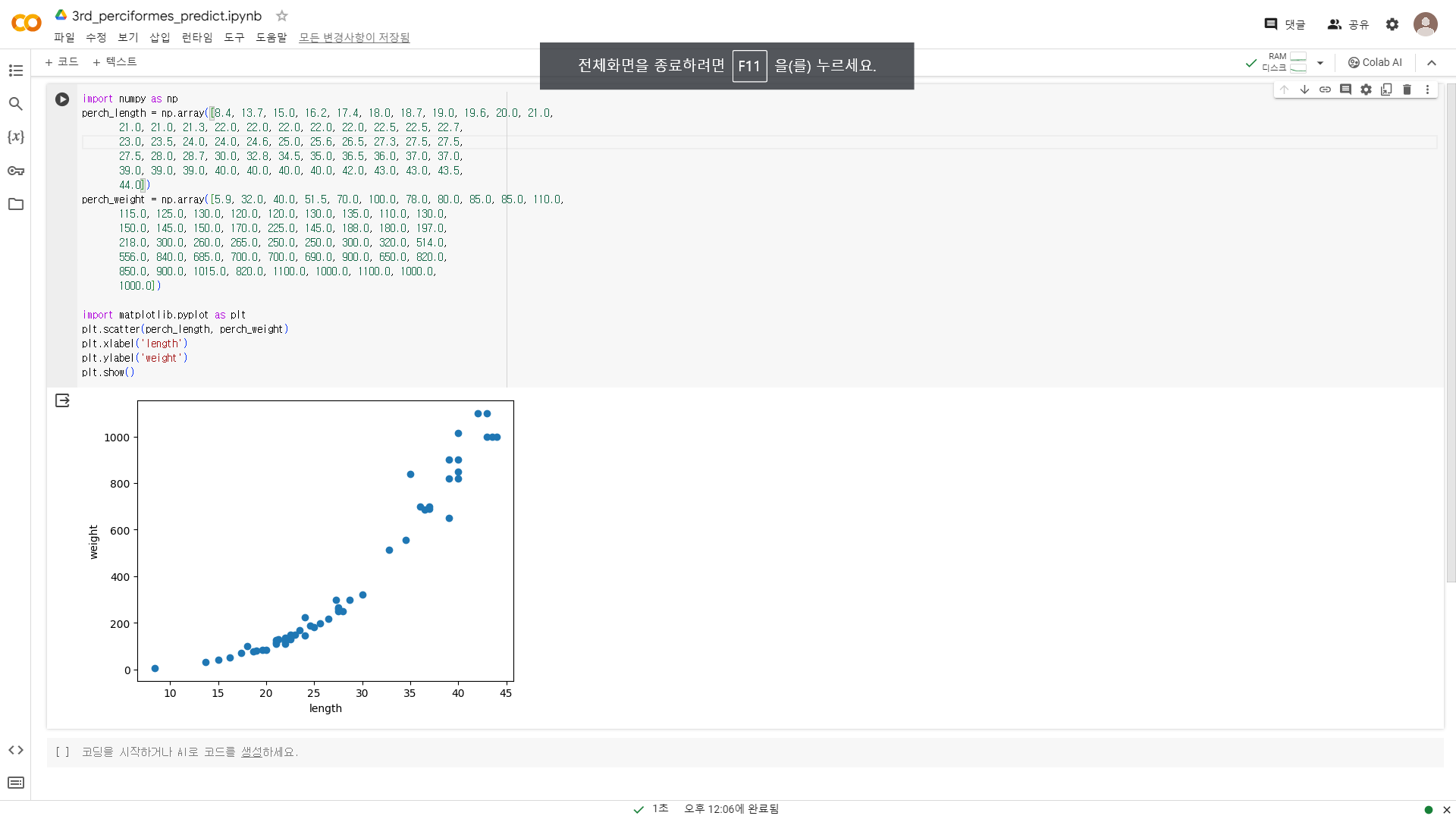
농어 데이터 확인
- 길이와 무게가 비례하는 과정 확인, 분석에 앞서 데이터의 분포 등을 통해 데이터의 특성을 파악하는 과정이 선행되어야 한다.
데이터 배열 변경
- 데이터 분석을 위해서는 2차원 배열로 변경하는 작업이 필요하다.
reshape() 함수를 활용하여 1차원 배열을 2차원으로 변환한다.
결정계수
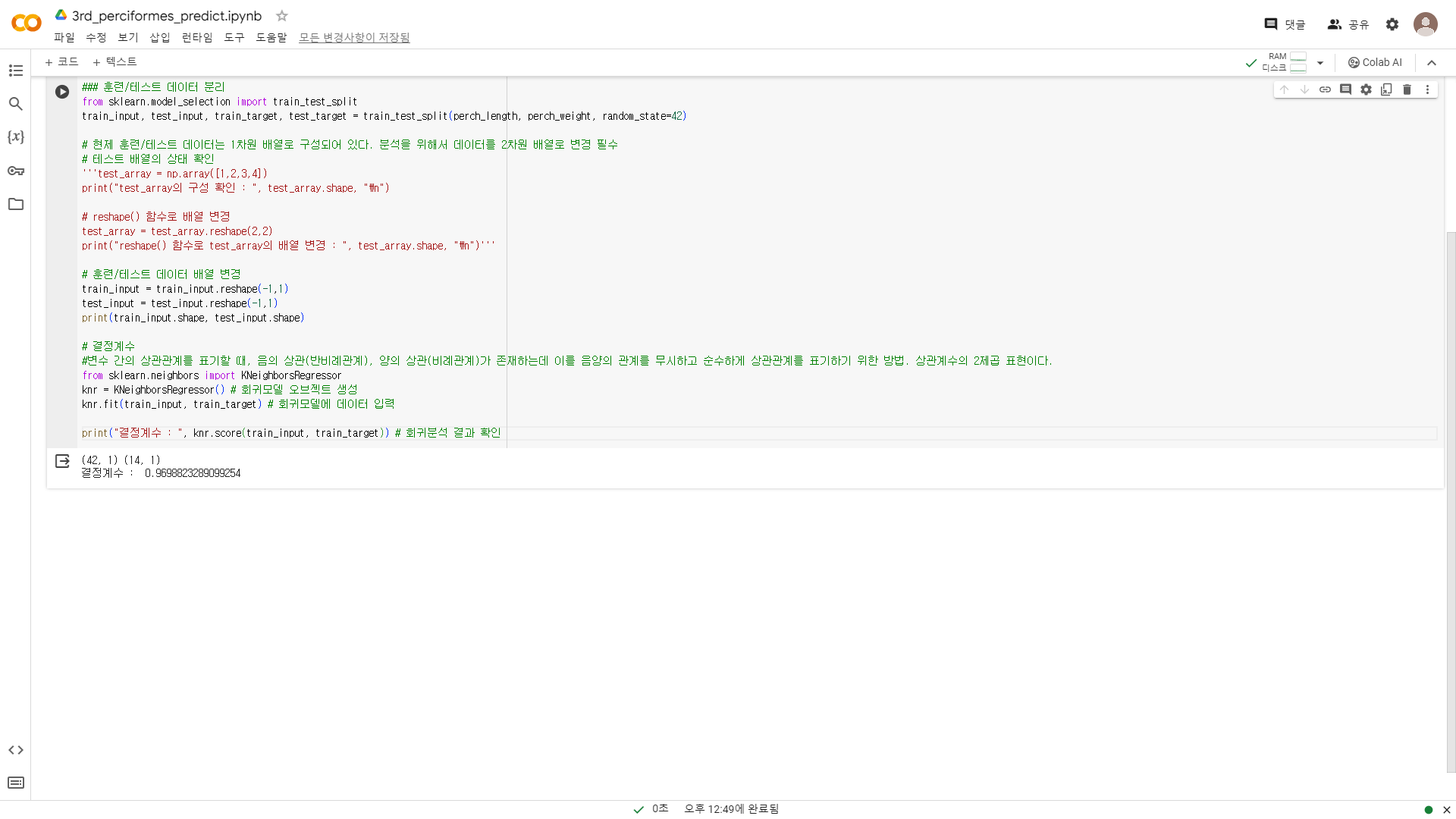
- 변수 간의 상관관계를 표기할 때, 음의 상관(반비례관계), 양의 상관(비례관계)가 존재하는데 이를 음양의 관계를 무시하고 순수하게 상관관계를 표기하기 위한 방법. 상관계수의 2제곱 표현이다.
- 결정계수가 1에 가까울수록 변수 간의 영향이 큰 것으로 본다.
- 결정계수(R^2) = 1-(〖(타깃- 예측)〗^2 의 합)/(〖(타깃- 평균)〗^2 의 합)
평균 절댓값 오차
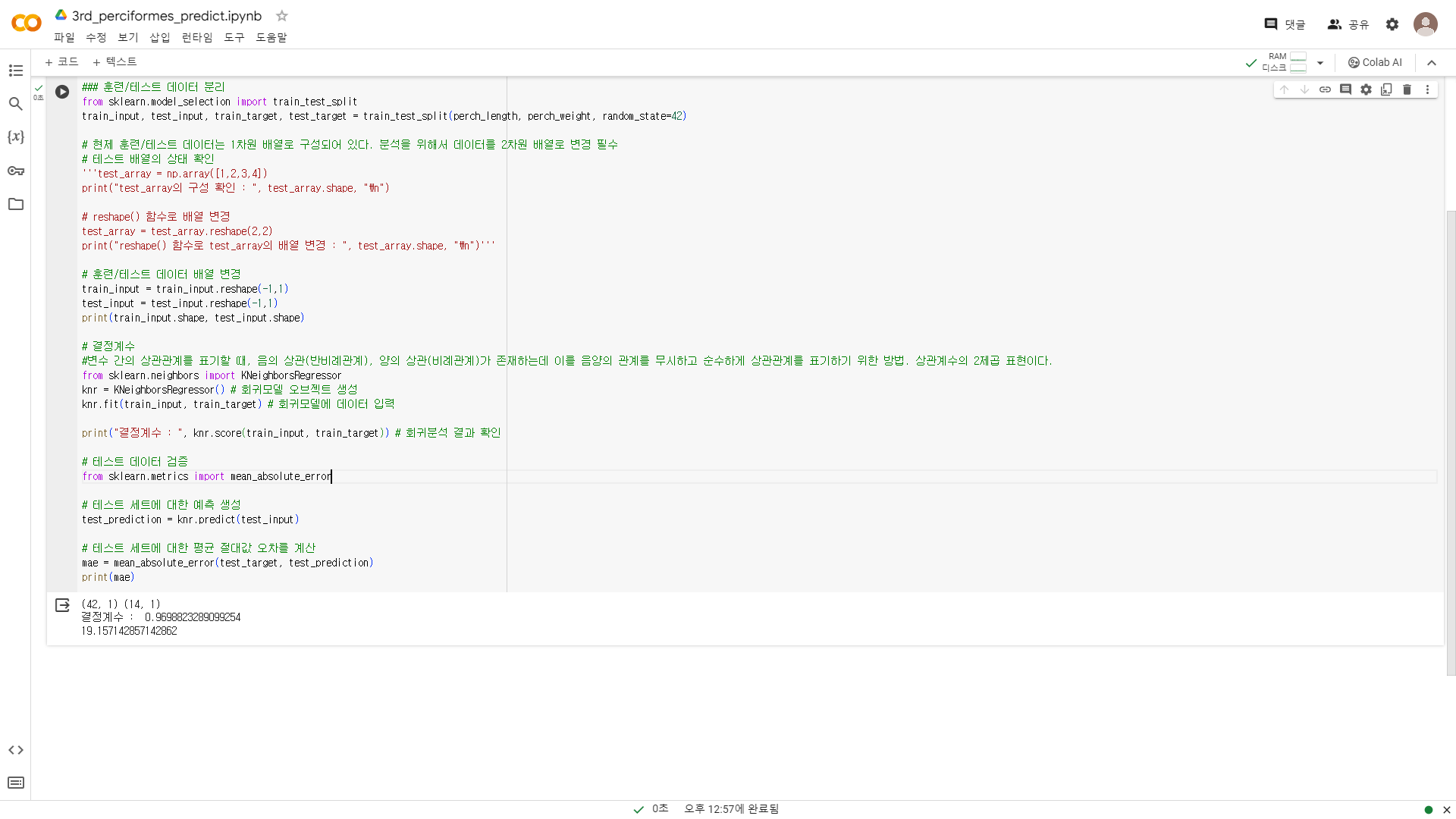
- 각 샘플과 평균의 차에서 절댓값으로 바꾸고 그 평균을 구하면 예측값과 실제 값의 평균을 구한 것이 된다.
- 예시에서는 19g 정도의 오차가 발생
과대적합 vs 과소적합
- 과대적합 : 훈련데이터에서는 결정계수/정확도가 높게 나오나 테스트 데이터에서 결정계수/정확도가 나쁜 경우 -> 새로운 데이터가 들어왔을 때 예측 정확도가 떨어짐.
- 과소적합 : 훈련/테스트 데이터 모두 결정계수/정확도가 낮거나 훈련 데이터 보다 테스트 데이터의 결정계수/정확도가 더 높은 경우 -> 데이터가 적어서 모델의 훈련이 부족한 경우가 일반적이다. 모델을 복잡하게 만들면 개선 가능
- 일반적으로 훈련데이터의 결정계수/정확도가 테스트 데이터의 결정계수/정확도 보다 높다. 훈련데이터로 학습했기 때문.
- 예시에서는 이웃 개수 k를 변경한다. 5->3
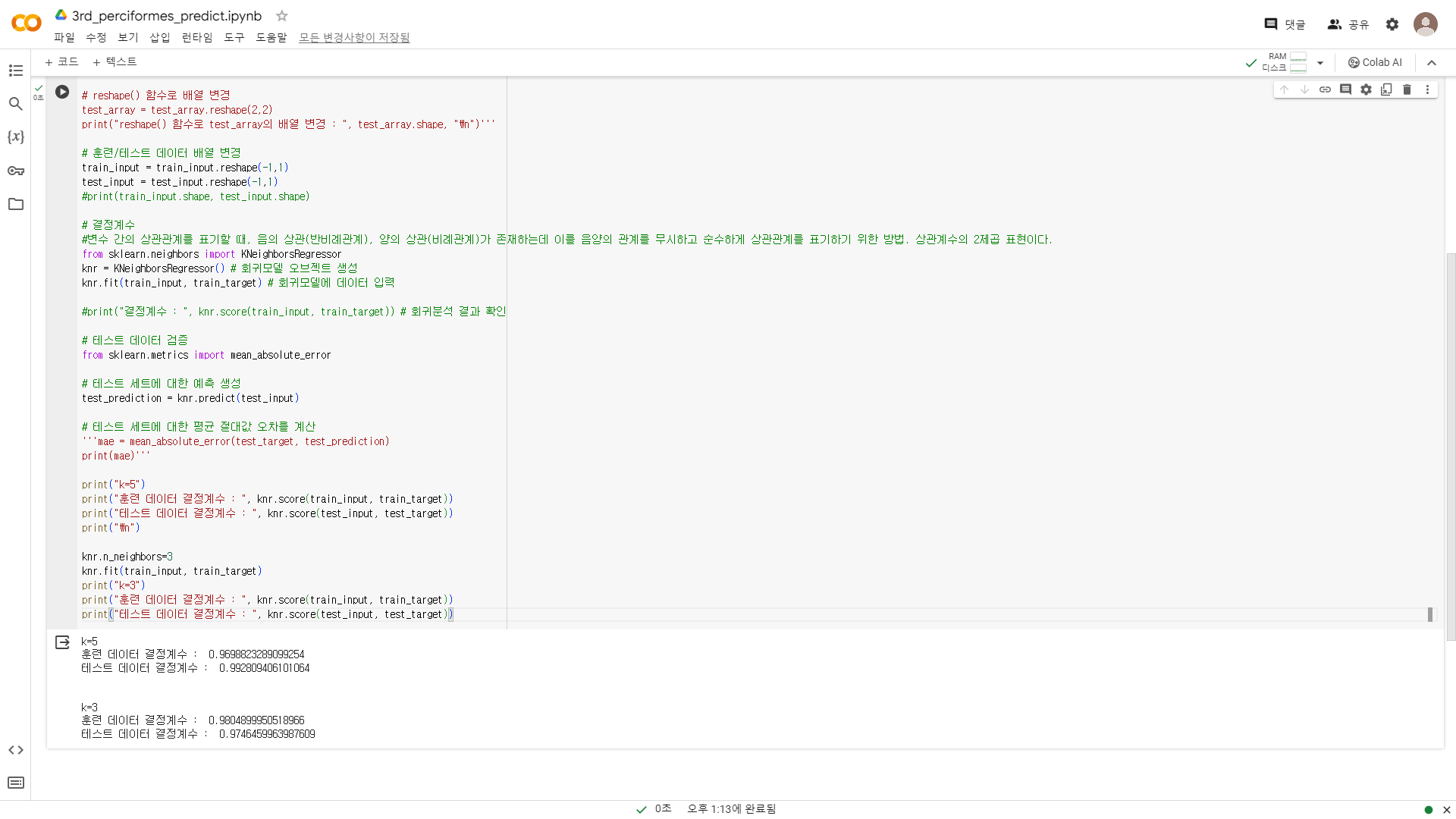
확인문제 2
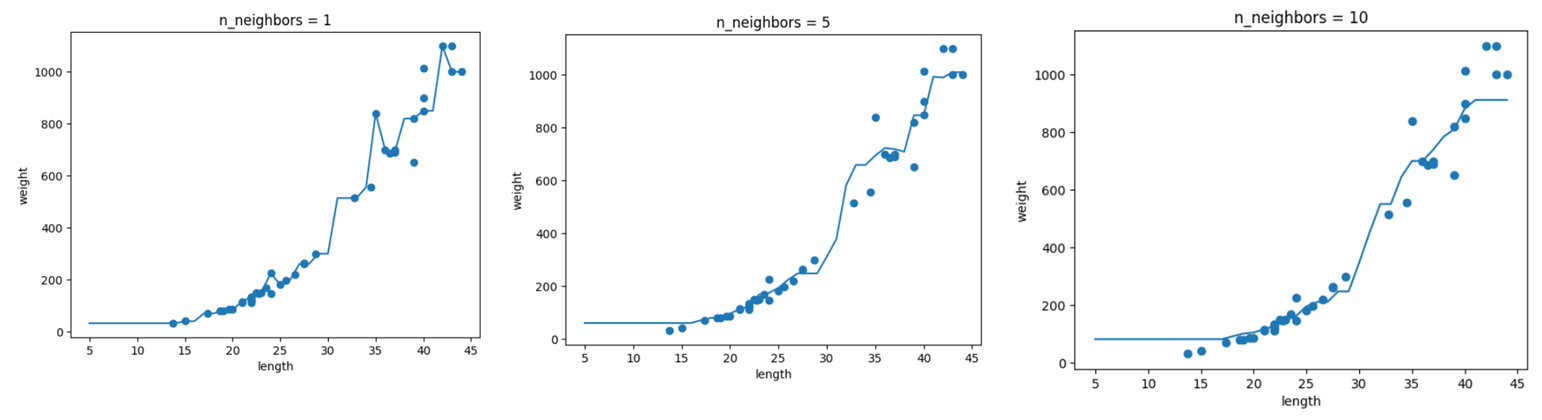
- n_neighbors(k개수)가 커지면 모델이 단순해 진다. 테스트 데이터에서 가장 가까운 샘플의 수(k개수)의 평균을 가지고 예측값을 구한다.
- 즉, n_neighbors=1이면 테스트 데이터와 가장 가까운 1개의 훈련데이터의 평균 값이 예측값이 되고, n_neighbors=5이면 테스트 데이터와 가장 가까운 5개의 훈련데이터 값의 평균이 예측값이된다.
- 단순한 모델은 과소적합에 가까워지고 복잡한 모델은 과대적합에 가까워진다.

배운 건 써 먹자