1. 분류 알고리즘의 종류
1.1. k-최근접 이웃 분류기
1.1.1. 데이터 수집
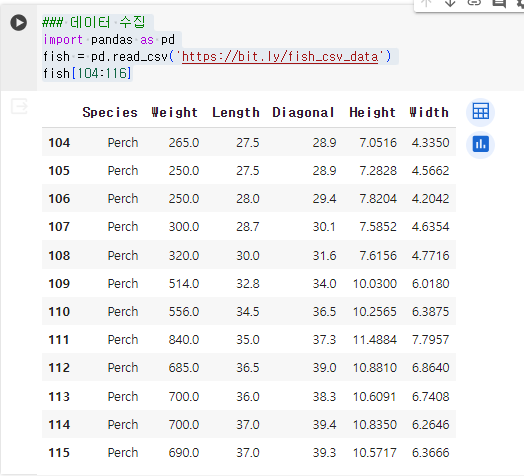
1.1.2. 생선의 종류 확인

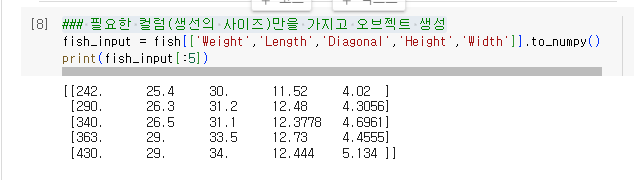
1.1.3. 필요한 컬럼(생선의 사이즈)만을 가지고 오브젝트 생성
1.1.4. 생선 종류를 가지고 생성

1.1.5. 생선 데이터 학습

1.1.6. 생선 데이터 표준화 - 데이터 단위에 따른 분석 결과의 영향력을 제거

1.1.7. k-최근접 이웃 분류기의 확률 예측

1.1.8. 클래스 데이터 확인
- 두 개 이상의 클래스가 포함된 문제를 다중 분류라고 한다.
- 사이킷런에서는 문자열로 된 값을 그대로 다중 분류의 타깃값으로 사용할 수 있지만 이를 그대로 전달하면 알바펫순으로 순서가 정해진다.
- 따라서 pd.unique(fish['Species'])로 출력했던 순서와 다름
- kn.classes_ : KNeighborsClassifier에서 정렬한 타깃 값을 출력하는 함수

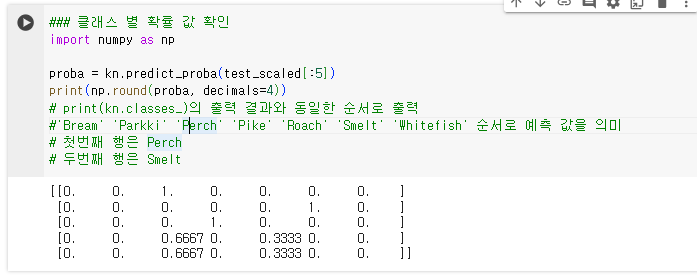
1.1.9. 클래스 별 확률 값 확인
- kn.predict_proba : 클래스 별 확률 값을 반환
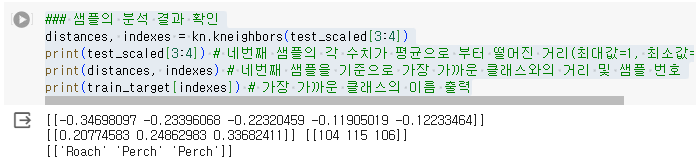
1.1.10. 샘플의 분석 결과 확인
- kn.kneighbors(test_scaled[3:4]) : 네번째 샘플의 각 수치가 평균으로 부터 떨어진 거리(최대값=1, 최소값=-1)
- print(distances, indexes) : 네번째 샘플을 기준으로 가장 가까운 클래스와의 거리 및 샘플 번호
- print(train_target[indexes]) : 가장 가까운 클래스의 이름 출력
1.2. 로지스틱 회귀
- 회귀이지만 분류 모델
- 선형 회귀와 동일한 선형 방정식을 학습
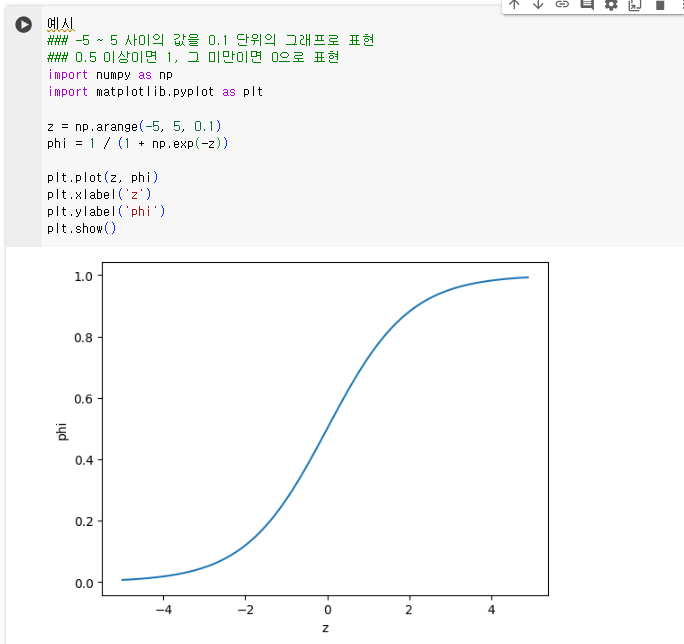
- 식 : z = a(weight) + b(length) + c(diaonal) + d(height) + e*(width) + f
각 a~d까지는 계수 또는 가중치, f는 상수 - 로지스틱 회귀는 분류 모델이기 때문에 참/거짓, 1/0으로 표현되어야 한다.
- 따라서 시그모이드 함수(로지스틱 함수)를 적용하여 값을 0~1 사이의 값으로 변환한다
1.2.1. 시그모이드 함수 예시
1.2.2. 불리언 인덱싱
- 참/거짓 값을 전달하여 행을 선택

1.2.3. 빙어와 도미 데이터를 활용한 이진분류
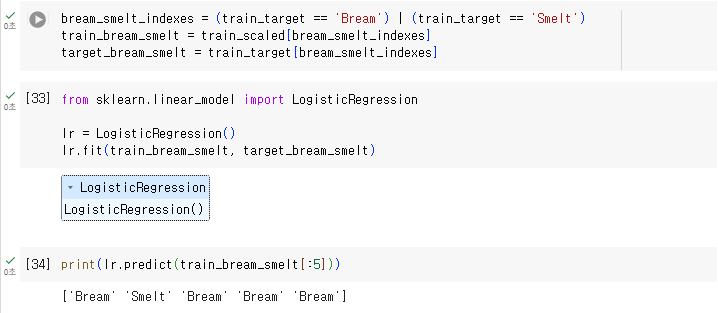
1.2.4. 빙어/도미에 속할 확률 출력

1.2.5. 로지스틱 회귀의 계산 식과 결과
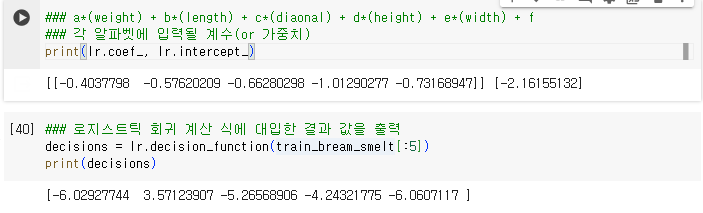
1.2.6. 시그모이드 함수
- 로지스틱 회귀 결과를 시그모이드 함수에 적용하여 0 ~ 1 사이의 값으로 변환

1.2.7. 참조
- predict_proba() 메서드 : 음성 클래스와 양성 클래스에 대한 확률 출력
- decision_function() 메서드 : 양성 클래스에 대한 z값을 계산
- coef, intercept : 로지스틱 모델이 학습한 선형 방정식의 계수
1.3. 로지스틱 회귀로 다중 분류
- 반복 알고리즘을 사용
- 릿지 회귀처럼 계수의 제곱을 규제(L2 규제)
- 릿지 회귀는 alpha와 규제가 비례,
- 로지스틱 회귀는 c와 규제가 반비례, c의 기본값=1
1.3.1. 로지스틱 회귀 설정 값 변경 및 값 확인
- c의 값을 변경, 반복 회수 = 1000으로 변경

1.3.2. 각 클래스에 대한 회귀 값 및 확률 값 확인
- 첫 5개의 샘플 데이터의 예측 결과 확인
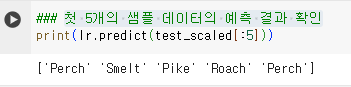
- 5개의 샘플이 7개의 클래스 각각에 속할 확률
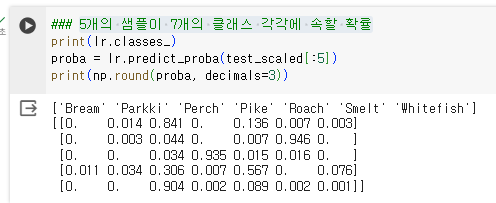
- 각 샘플의 클래스 별 로지스틱 회귀 값을 확인
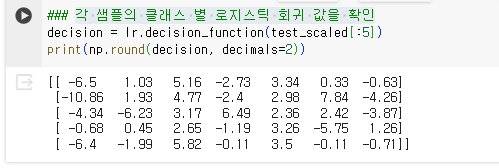
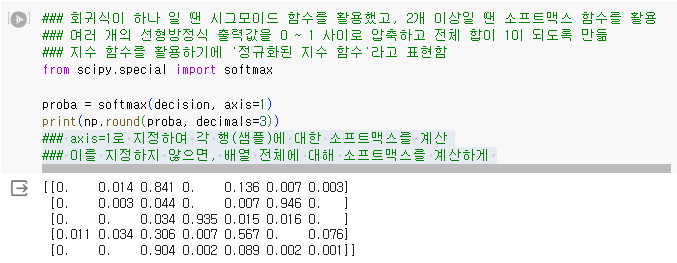
1.3.3. 소프트맥스
- 회귀식이 하나 일 땐 시그모이드 함수를 활용했고, 2개 이상일 땐 소프트맥스 함수를 활용
- 여러 개의 선형방정식 출력값을 0 ~ 1 사이로 압축하고 전체 합이 1이 되도록 만듦
- 지수 함수를 활용하기에 '정규화된 지수 함수'라고 표현함
- axis=1로 지정하여 각 행(샘플)에 대한 소프트맥스를 계산
- 이를 지정하지 않으면, 배열 전체에 대해 소프트맥스를 계산하게 됨
1.3.4. 확인문제
- 로지스틱 회귀가 이진 분류에서 확률을 출력하기위해 사용하는 함수 : 시그모이드 함수
1.4. 확률적 경사 하강법
1.4.1. 점진적인 학습
- 머신러닝 모델 개발 시 학습을 위한 데이터가 부족하지만, 지속적으로 데이터가 공급될 때 적용할 수 있는 방법
- 주어진 데이터로 훈련 모델을 생성하고 추가적인 데이터를 통해 새로 학습하여 기존의 학습 모델을 폐기함
- 점진적인 학습의 필요성
- 분석을 위한 데이터가 누적되기 까지의 시간 소요
- 서버가 보관할 수 있는 데이터 양의 한계
1.4.1.1. 확률적 경사하강법
- 점진적으로 학습 모델의 정확성을 높여가는 방법
- 훈련 세트에서 하나의 샘플을 무작위로 고르는 방법
- 다음 훈련 세트에서 무작위 샘플을 골라 훈련
- 에포크 : 확률적 경사 하강법에서 훈련 세트를 한 번 모두 사용하는 과정
1.4.1.2. 미니배치 경사 하강법
- 여러 개의 샘플을 선택하는 경사 하강법
1.4.1.3. 배치 경사 하강법
- 전체 샘플을 사용하는 방법
- 가장 높은 정확성을 보이지만 컴퓨터의 리소스 소모량이 많음
1.4.2. 손실 함수(Loss Function)
- 머신러닝의 알고리즘의 부정확성을 측정하는 기준
- 하나의 샘플에 대한 손실을 정의
1.4.2.1. 비용함수
- 훈련 세트에 있는 모든 샘플에 대한 손실 함수의 합
- 손실함수와 비용함수를 굳이 구분하지 않음
1.4.2.2. 손실의 기준
- 예측이 틀린 경우
1.4.2.3. 로지스틱 순실 함수(이진 크로스엔트로피 손실 함수)
- 0(음성클래스), 1(양성클래스) 일 때, 각각 손실함수를 구하는 기준이 다름
- 결과값=1일 때, 예측값=0.9인 경우 손실함수=-0.9
- 결과값=0일 때, 예측값=0.2인 경우 손실함수=-0.8
- 식 : (1-0.2) * (-1) = -0.8
- 손실함수가 -1에 가까울수록 모델의 정확도가 좋은 것
- 양성클래스 일 때 손실은 -log(예측확률), 확률이 1에서 멀이질수록 손실은 큰 양수가 됨
- 음성클래스 일 때 손실은 -log(1-예측확률), 예측확률이 0에서 멀어질 수록 손실은 아주 큰 양수가 됨
- 이진 분류는 로지스틱 손실 함수, 다중 분류는 크로스엔트로피 손실 함수
- 회귀의 손실함수는 평균 제곱 오차(Mean Squared Error - MSE)를 사용
1.4.3. SGDClassifier(Stochastic Gradient Descent)
- 확률적 경사 하강법을 이용한 선형 모델
- loss : 확률적 경사 하강법으로 최적화할 손실 함수 지정, 기본값(hinge)
- 기본값 : hingeg
- log_loss : 로지스틱 회귀용
- penalty : 규제의 용도 지정
- 기본값 : L2 규제
- l1 : L1 규제 사용
- alpah : 규제 강도를 설정
- 기본값 : 0.0001
- tol : 반복을 멈출 조건
- 기본값 : 0.001
- n_iter_no_change : 지정한 에포크 동안 손실이 tol 만큼 줄어들지 않으면 알고리즘 중단
- 기본값 : 5
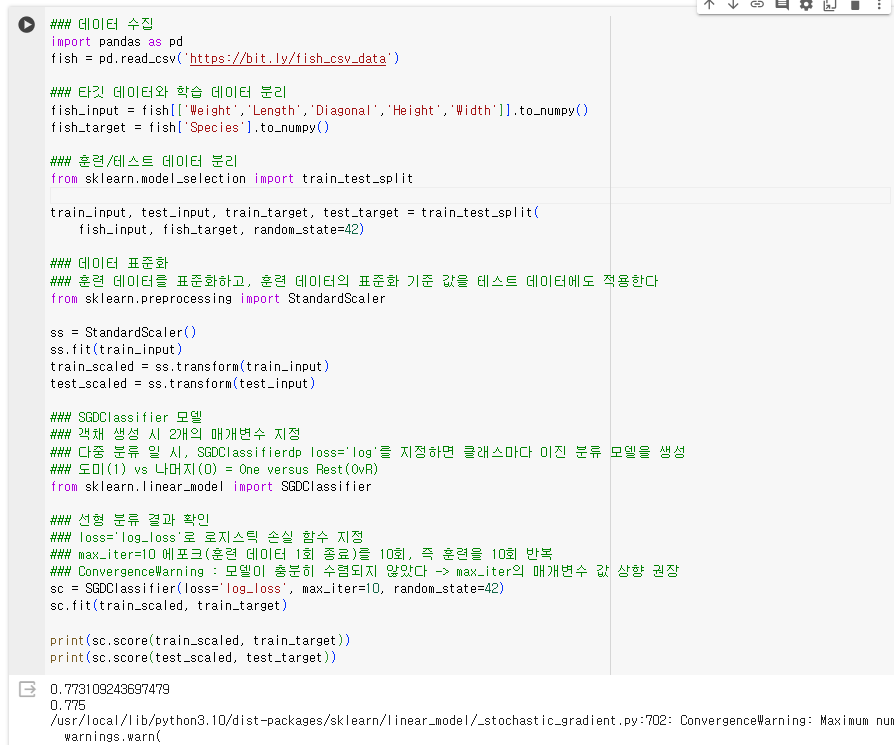
1.4.3.1. SGDClassifier 실습
-
데이터 수집
-
타깃/입력 데이터 분리
-
데이터 전처리
- 훈련 데이터를 표준화하고, 훈련 데이터의 표준화 기준 값을 테스트 데이터에도 적용
-
SGDClassifier 모델 생성
- 객채 생성 시 2개의 매개변수 지정
- 다중 분류 일 시, SGDClassifierdp loss='log'를 지정하면 클래스마다 이진 분류 모델을 생성
- 도미(1) vs 나머지(0) = One versus Rest(OvR)
-
학습 결과 및 검증
- loss='log_loss'로 로지스틱 손실 함수 지정
- max_iter=10 에포크(훈련 데이터 1회 종료)를 10회, 즉 훈련을 10회 반복
- ConvergenceWarning : 모델이 충분히 수렴되지 않았다 -> max_iter의 매개변수 값 상향 권장
-
점진적인 학습 진행
- partial_fit 메서드 활용
- 1에포크 씩 훈련을 추가한다
- SGDClassifier 객체에 한 번에 훈련세트를 전달하였으나 이 알고리즘은 훈련 세트를 1개씩 샘플로 꺼내어 경사 하강법 단계를 수행
- 미니배치 경사하강법, 배치 하강법 지원하지 않음

1.4.3.2. 에포크와 과대/과소 적합
-
적은 에포크 = 과소 적합
-
과한 에포크 = 과대 적합
-
조기 종료 : 과대 적합이 발생하기 전에 훈련 종료
-
다중분류 실시
-
7개의 생선
-
반복 학습 100 즈음 훈련 점수와 테스트 점수의 변화가 사라지며 오히려 점수의 격차가 벌어진다.

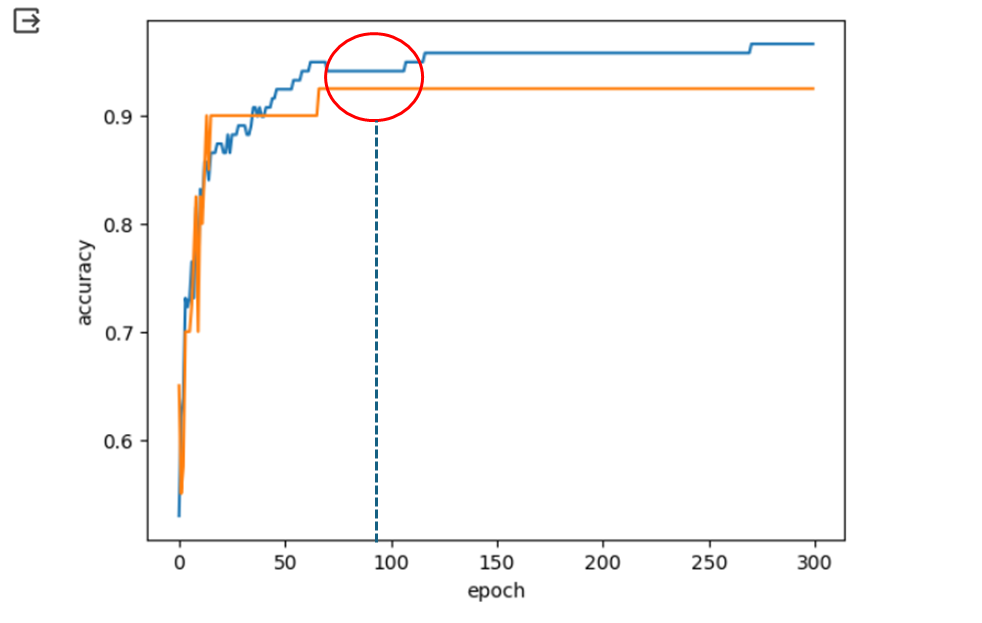
-
최적의 에포크 값 설정
위의 그래프를 기준으로 약 100회쯤이 훈련 세트와 테스트 세트의 정확성을 고려하여 최적의 결과를 나타낸다.

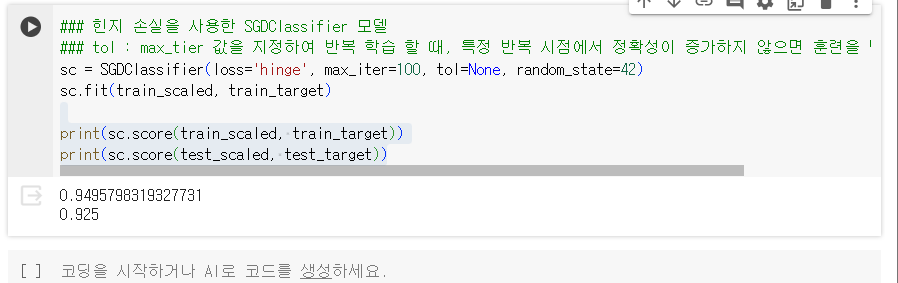
1.4.3.3. 힌지 손실(hinge loss)
- 서포트 벡터 머신이라는 머신러닝 알고리즘을 위한 손실 함수
- 힌지 손실 적용 결과
- tol : max_tier 값을 지정하여 반복 학습 할 때, 특정 반복 시점에서 정확성이 증가하지 않으면 훈련을 멈추는 설정
1.4.4. SGDRegressor
- 확률적 경사 하강법을 사용한 회귀 모델
- los : 손실 함수 지정
- 기본값 : squared_loss
- SGDClassifier 에서 사용한 옵션 모두 동일

배운 건 써 먹자