혼공학습단
1주차
마켓과 머신러닝
- 구글에서 제공하는 코랩 실습
구글 계정을 생성하고 'https://colab.research.google.com/' 이 주소로 이동하면 자신의 가상 주피터 노트북을 생성할 수 있다. - 파일 > 새 노트 를 클릭하여 코드를 입력할 수 있고 만들어진 노트는 구글 드라이브에 생성된다.
-
노트의 제목을 변경하면 구글 드라이브의 노트 제목도 같이 변경된다.
-
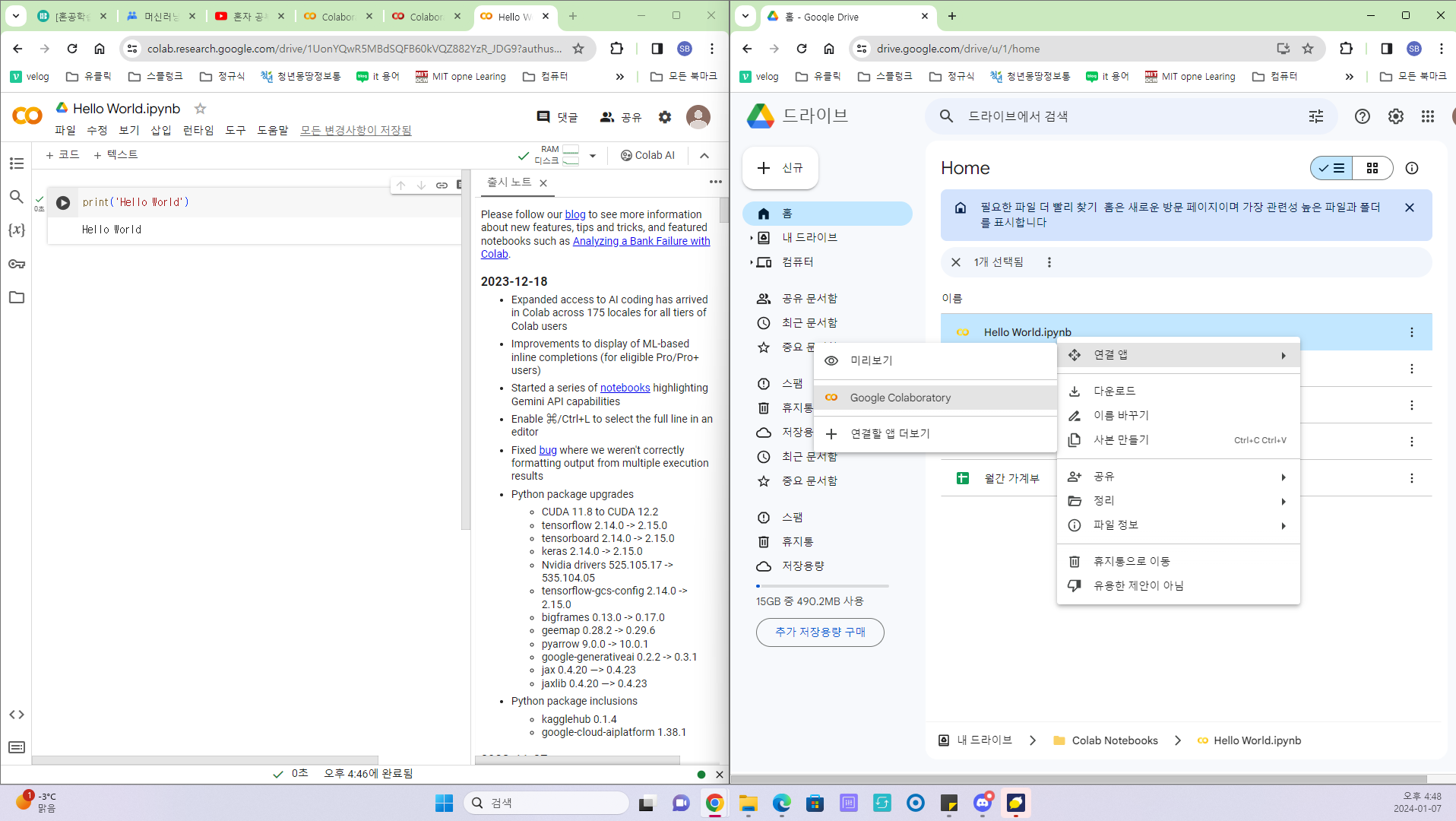
구글 드라이브에서 노트를 우클릭하여 연결앱을 이미지처럼 클릭한다면 코랩으로 이동할 수 있다.
k-최근접 이웃 알고리즘을 활용한 도미와 빙어 머신러닝 실습
- 도미, 빙어 데이터를 만들어서 산점도로 표현해 보았다
각 데이터는 아래의 url에서 가져왔다.
https://gist.github.com/rickiepark/b37d04a95a42ef6757e4a99214d61697
https://gist.github.com/rickiepark/1e89fe2a9d4ad92bc9f073163c9a37a7
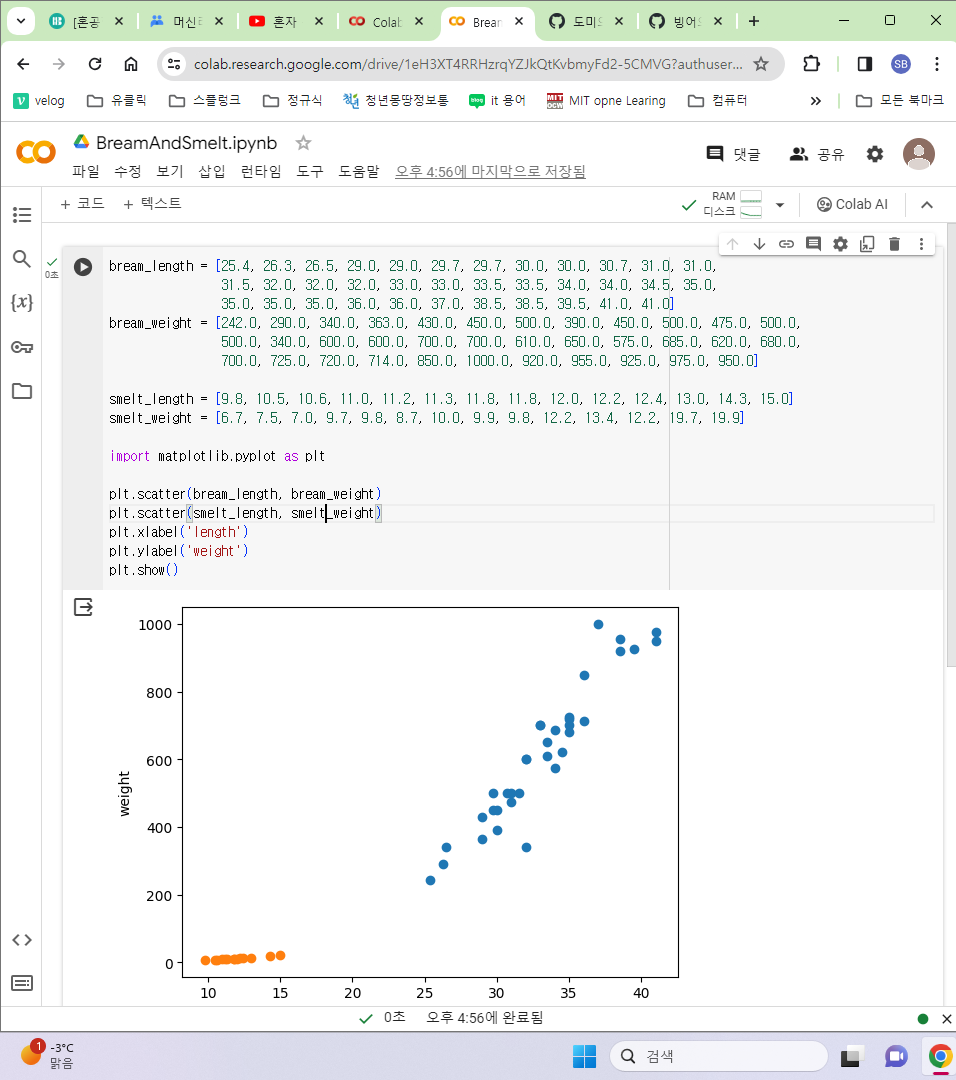
-
도미, 빙어 데이터를 하나의 리스트로 합친 후에, 도미는 1, 빙어는 0으로 표현하는 fish_target 변수를 생성하여 모델에 학습시켰다. 그 이후 학습 시킨 모델이 데이터에 따라 잘 분류했음을 확인
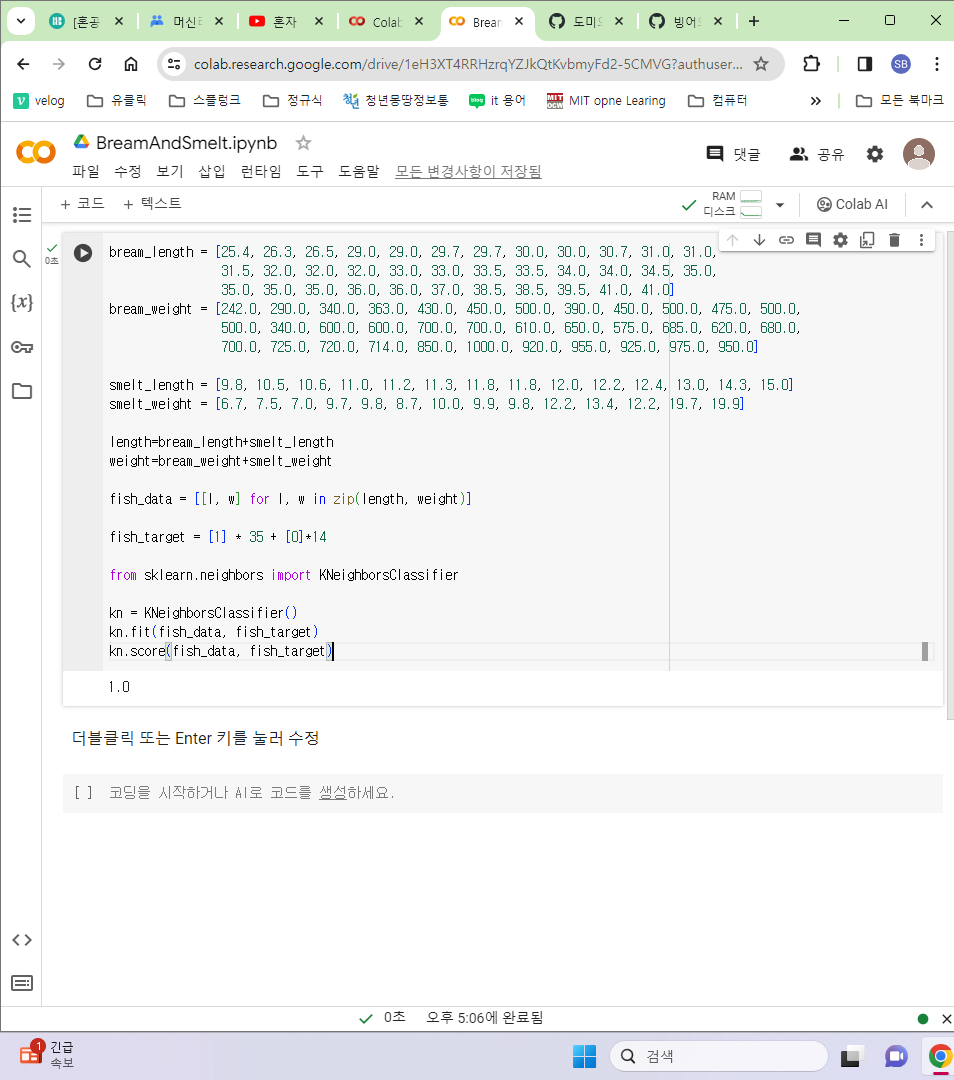
-
길이와 무게가 각각 30, 600 인 생성이 도미/빙어 중 어떤 종류(class)로 분류되는 지 확인하였다(도미)
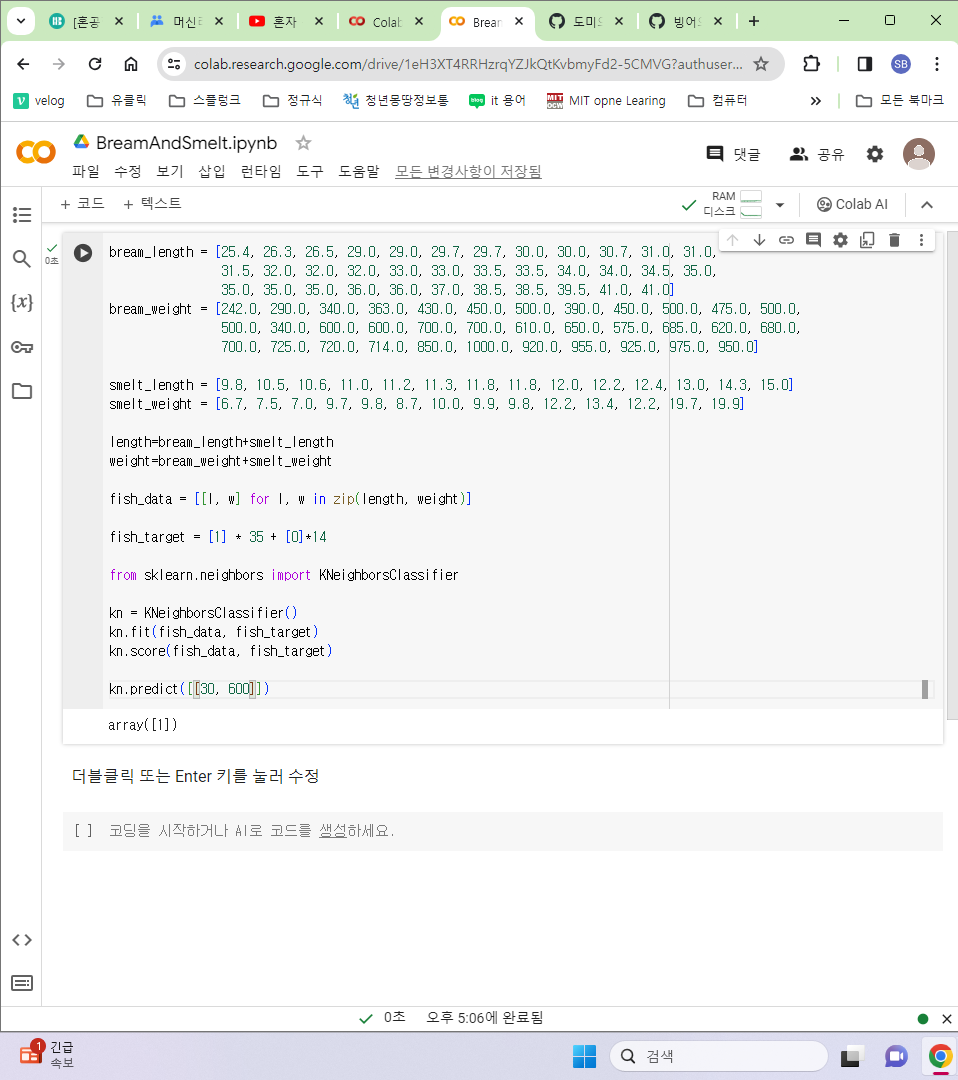
-
학습시킨 모델의 데이터와 타겟 값을 확인
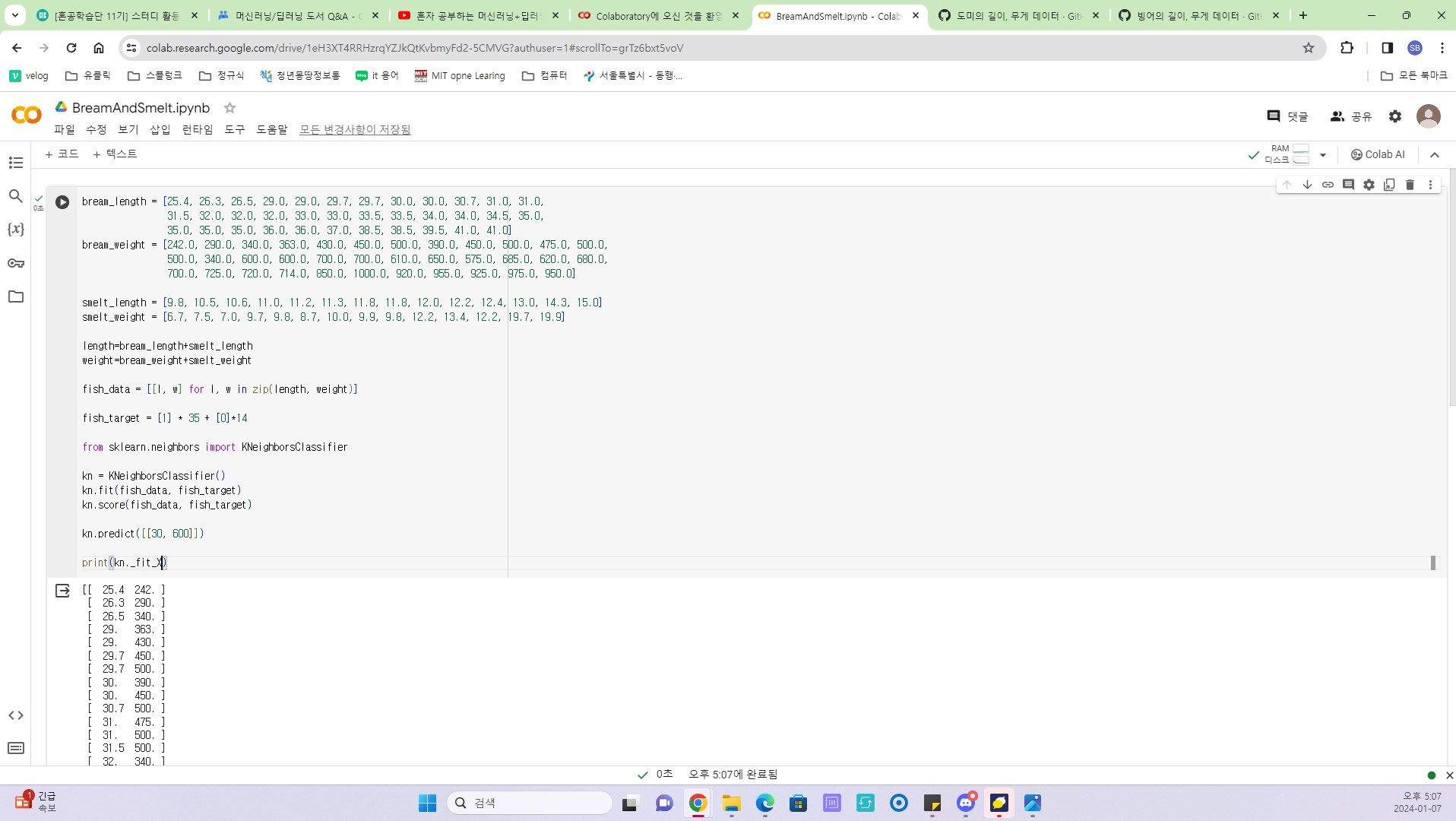
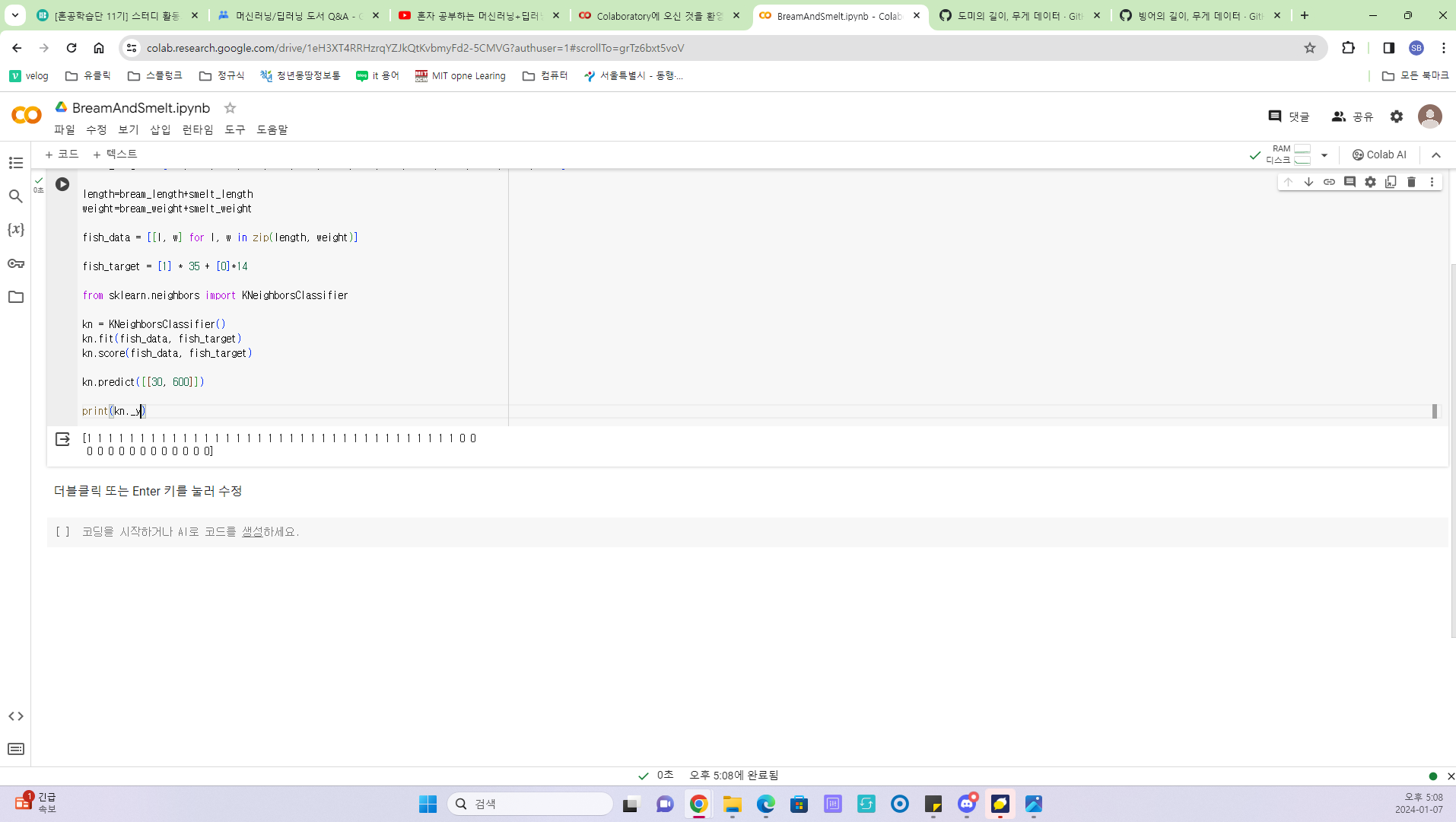
- 머신러닝에서 매개변수의 기본값은 5이다. 이 매개변수를 49로 설정하면 최근 49개의 데이터를 참조하게 되는데 현재, 49개의 데이터 중 도미의 데이터 35개를 차지하고 있으므로 어떤 데이터를 넣어도 무조건 도미로 예측할 것이다. 따라서 매개변수의 값을 5를 유지하도록 한다.
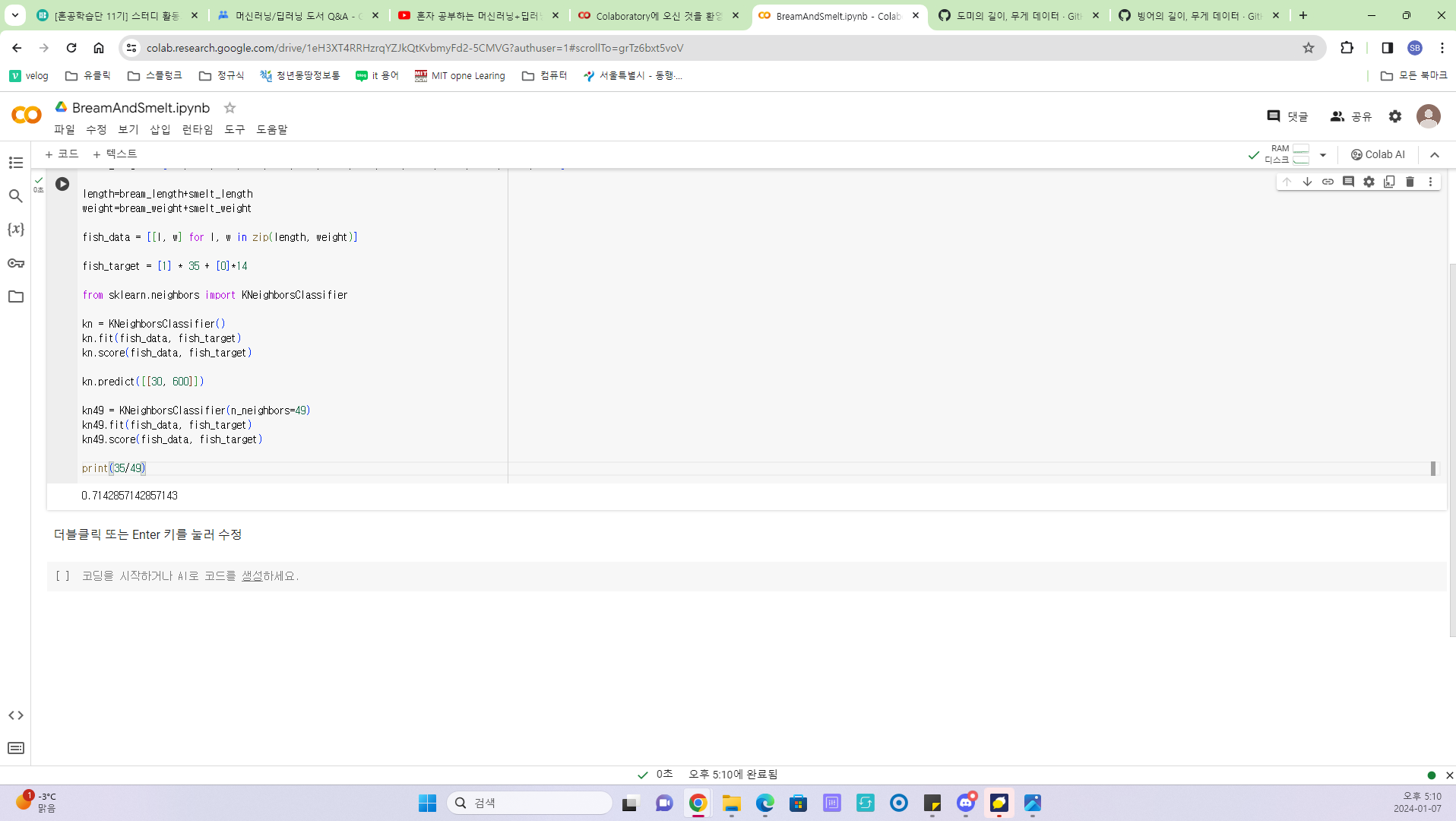
Q. 도미 데이터가 대다수를 차지하고 있어 어느 데이터를 넣어도 도미로 예측할 것이다??
A. 새로운 데이터를 넣었을 때, 그 데이터를 중심으로 가장 가까운 클래스(분류) + 다수의 데이터 클래스(분류)가 무엇인지에 따라 새로운 데이터가 어느 클래스로 분류될지 정해진다.
예시, 데이터 (가)를 넣었을 때, (가)를 기준으로 가장 가까운 데이터 49개가 선택된다. 5개의 데이터의 클래스(분류)를 확인(도미35, 빙어14) 했을 때, (가)는 도미로 분류될 것이다. 비록 가장 가까운 데이터가 빙어일지라도 49개의 데이터 중에서 도미클래스가 35개라서 (가)는 도미로 분류되는 것이다. 그리고 매개변수는 클래스르 분류하는 기준이기 때문에 짝수로 지정하여 클래스 비교가 동률이면 분류를 할 수 없으니 홀수로 설정한다.
요약 : 따라서 적절한 매개변수 값을 잘 지정해야 한다.
출처 : https://ko.wikipedia.org/wiki/K-%EC%B5%9C%EA%B7%BC%EC%A0%91_%EC%9D%B4%EC%9B%83_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98
훈련/테스트 데이터 분류
모델의 학습결과를 검증하기 위한 과정
-
모든 데이터의 분류 결과를 알고 있는 모델로 학습한 결과는 정확도 100가 나올 수 밖에 없음 따라서 훈련데이터와 테스트 데이터를 비율로 분류하여 훈련데이터로 모델을 만들고 만들어진 모델에 테스트 데이터를 확인하여 모델의 훈련 상태를 확인한다.
-
훈련/테스트 데이터를 구분하기 위해 데이터 샘플을 랜덤으로 섞어 분류한다.
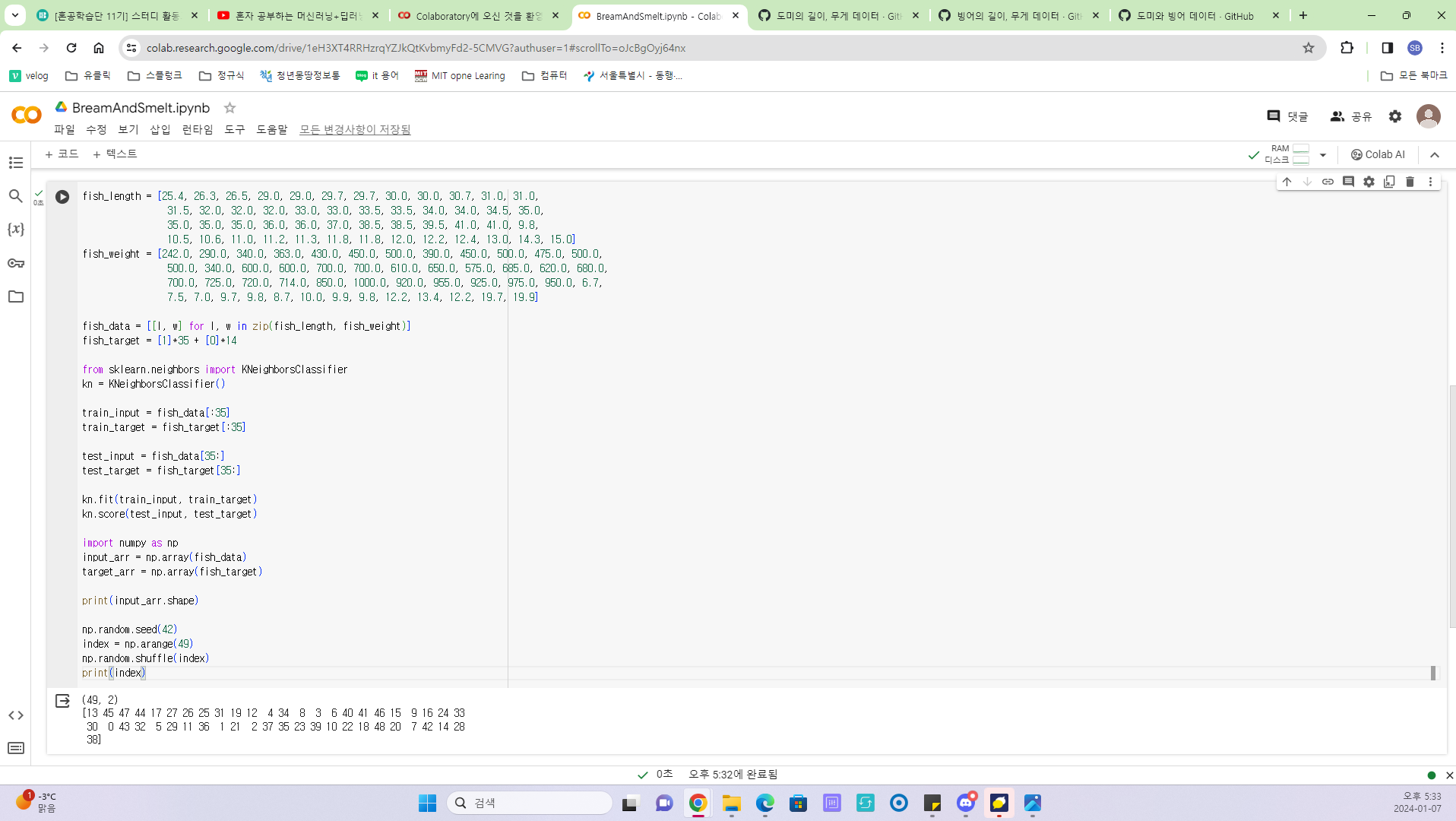
-
훈련/테스트 데이터로 분류되는 데이터(도미, 빙어)의 비율을 샘플의 비율에 맞춰서 조정해주어야 학습결과의 정확성을 높일 수 있다.
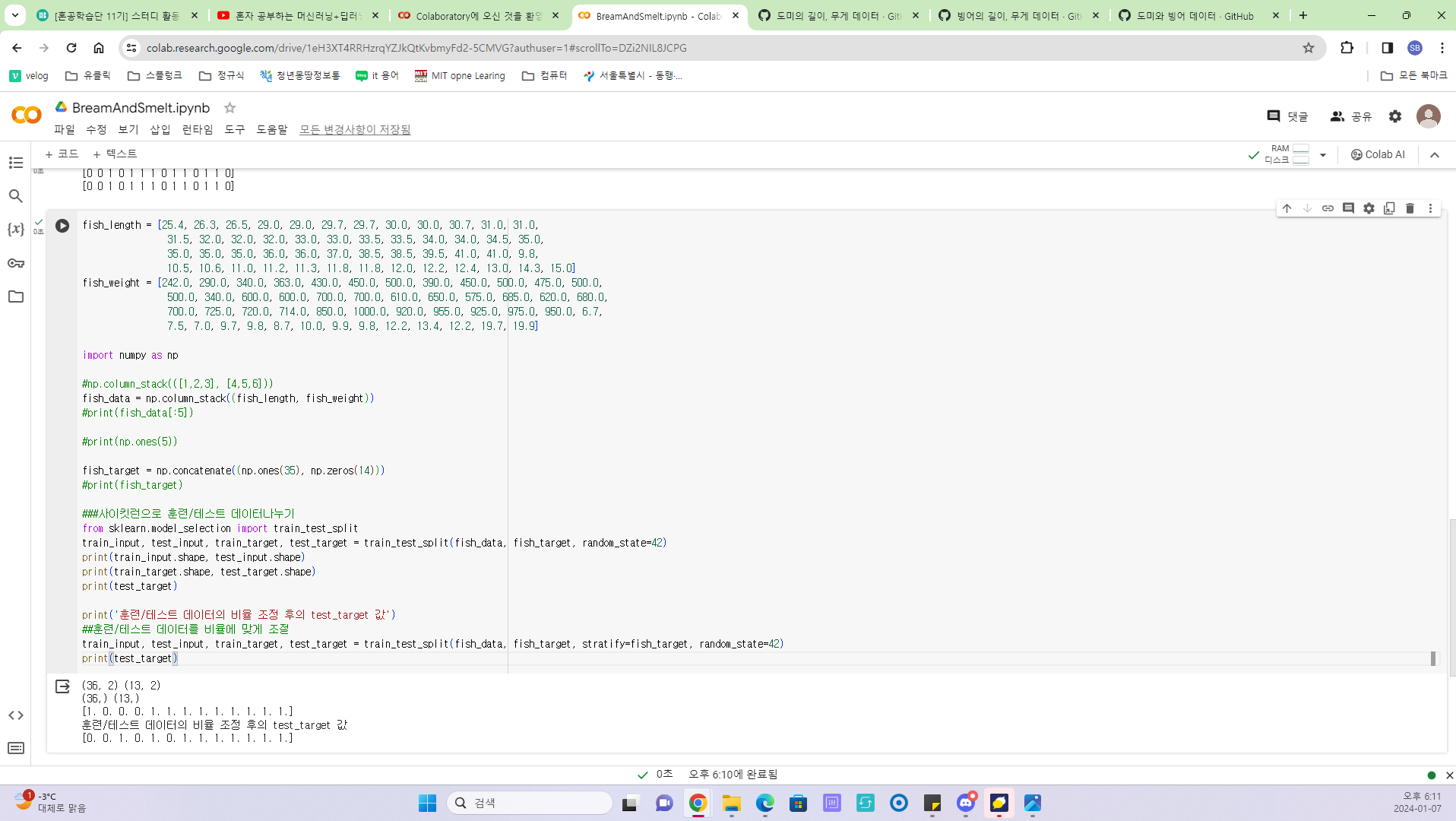
-
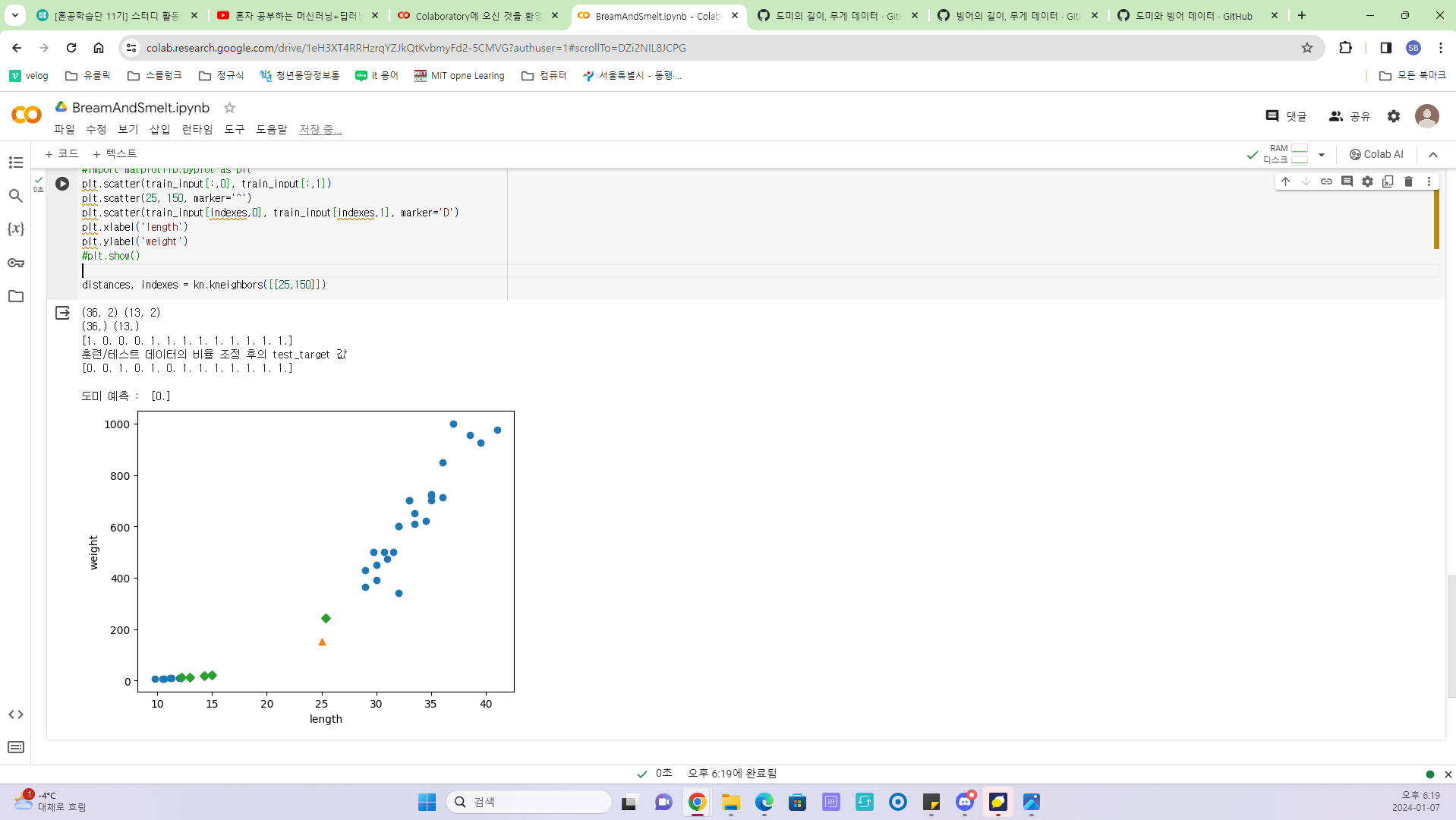
길이 25, 무게 150의 생선을 도미/빙어 중에 분류해보니 빙어로 분류하였다. 이는 데이터의 표준화가 이뤄지지 않았기 때문이다. k-최근접 이웃 알고리즘이 클래스(도미, 빙어 그룹) 간의 거리를 기준으로 어떤 클래스인지 분류하는 것인데 샘플 데이터의 단위에 따라 학습 모델의 정확성이 왜곡될 수 있음을 의미한다. 즉, 샘플 데이터의 단위가 학습에 영향을 주지 않도록 표준화 작업이 이뤄져야 한다.
-
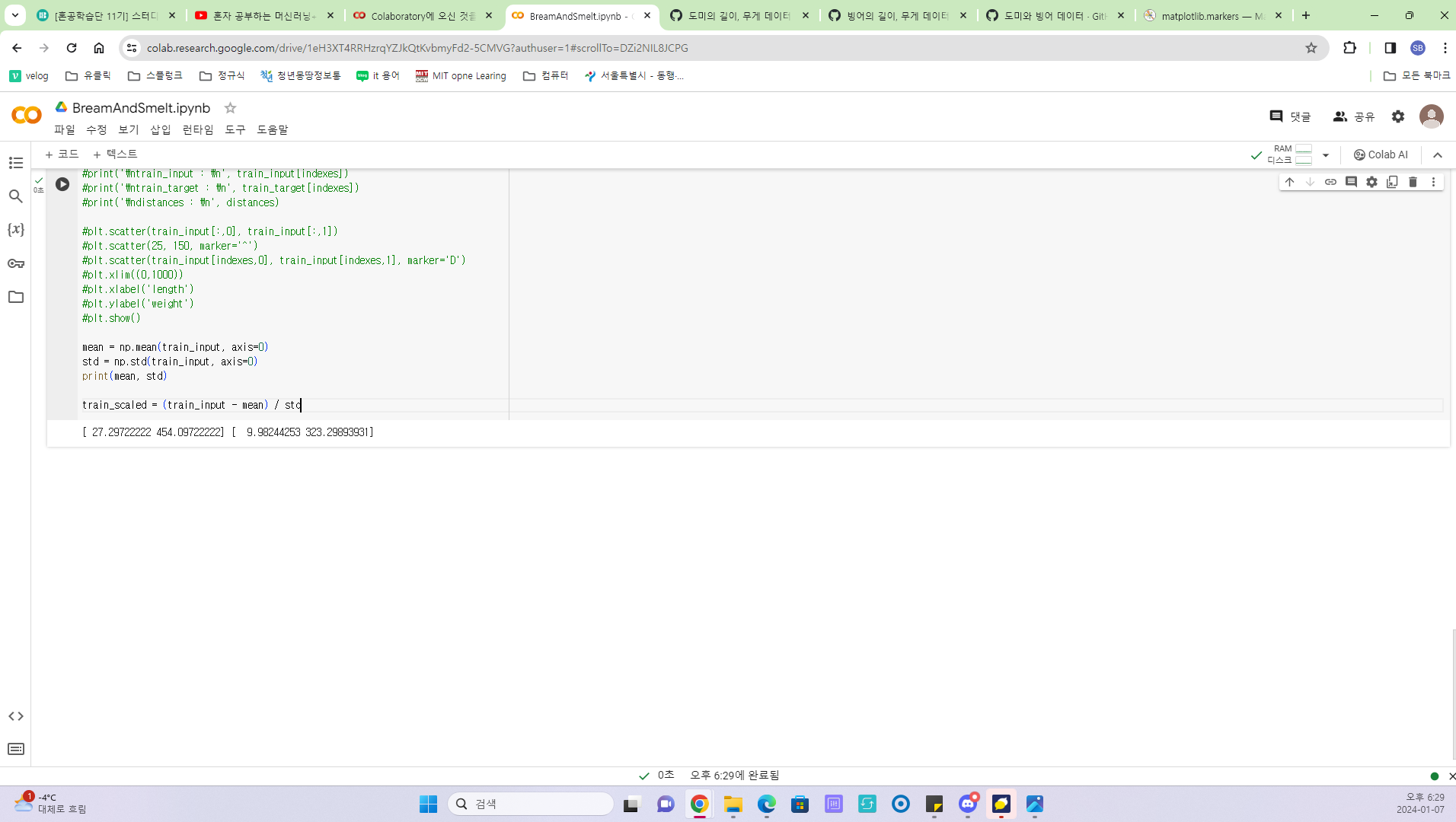
흔히 평균과 편차를 활용한 표준화를 통해 작업을 진행한다.
-
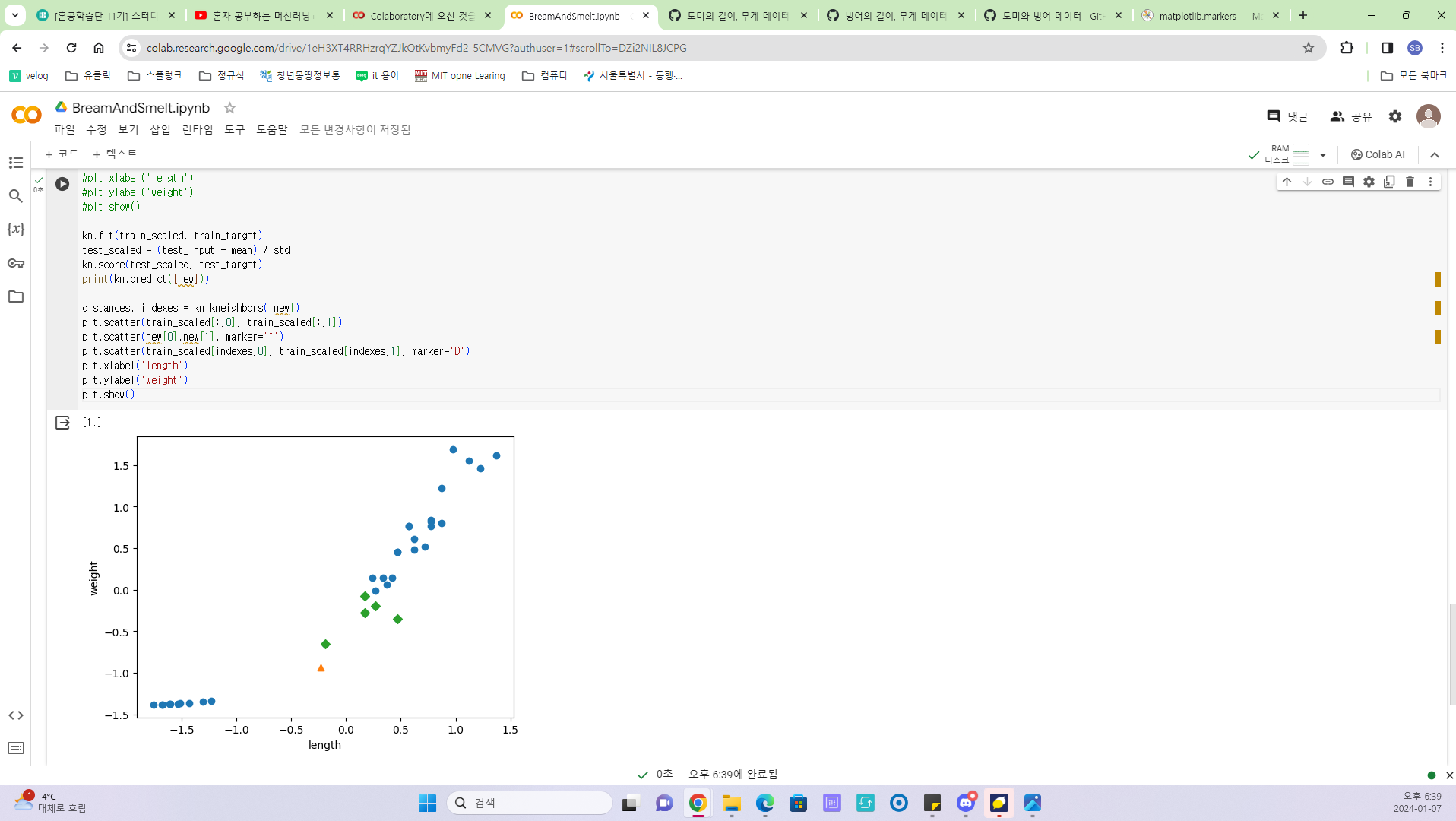
학습 데이터를 표준화하여 단위 영향력을 없앤 것 처럼 새로운 데이터도 학습데이터의 평균, 표준편차를 가지고 표준화 과정을 거친 이후에 모델에서 분석을 해야한다.
요약)
1. 학습 모델의 적절한 매개변수 설정
2. 훈련/테스트 데이터를 샘플의 클래스(분류)에 맞게 분배
3. 데이터의 표준화 작업(= 데이터 전처리)
