주식포트폴리오 작성
추신 : /home/sb111 에 있던 example_stock 을 /opt/splunk 로 옮겼다. 거기에 스플렁크 인덱스 및 데이터 입력 경로도 바꿈
참고 : https://cafe.naver.com/splunker?iframe_url_utf8=%2FArticleRead.nhn%253Fclubid%3D26625693%2526articleid%3D443
몬테카를로 시뮬레이션
실험 방식
수익률과 리스크를 샤프(sharp) 지수를 구하고 이를 몬테 카를로 시뮬레이션을 반복한 후, 샤프지수가 가장 높은 값으로 종목을 선택했다고 하는데 뭔진 따로 공부하는 걸로
1. 대시보드 추가
새로 대시보드 생성, 입력추가 클릭, 다중선택 클릭, 다음과 같이 채움
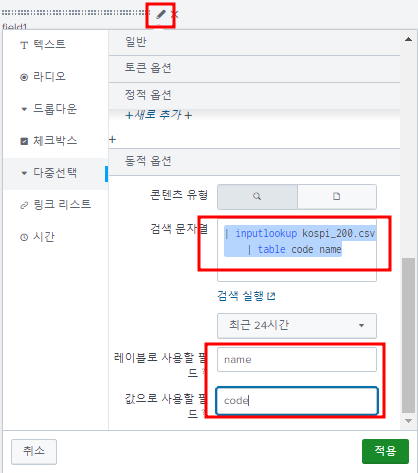
연필버튼 누르면 편집창 뜨고, 스크롤 내리면 동적옵션에서 검색열 입력한다. 검색 실행은 "전체 시간"으로 한다. 실습 날짜와 데이터의 차이가 큼
- 검색열
| inputlookup kospi_200.csv | table code name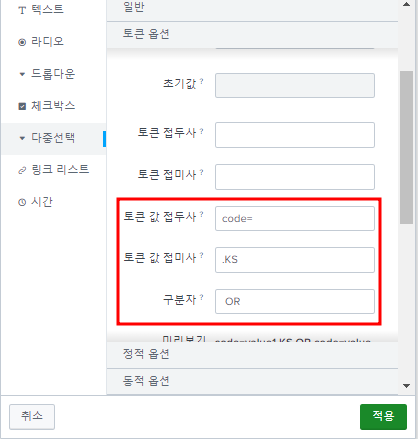
스크롤을 올려 토큰 옵션 탭을 다음과 같이 채우고 적용
stock 앱에서 MLTK 앱을 검색 활용하도록 설정
리눅스 편집
vi /opt/splunk/etc/apps/Splunk_ML_Toolkit/local/algos.conf해당 경로까지 없으면 만들어서 파일을 생성한 후
[MonteCarloSim]를 입력하자
vi /opt/splunk/etc/apps/Splunk_ML_Toolkit/bin/algos/MonteCarloSim.py여기서 파일을 편집
- 알고리즘
#!/usr/bin/env python
import pandas as pd
import numpy as np
from base import BaseAlgo, TransformerMixin
from codec import codecs_manager
from util.param_util import convert_params
class MonteCarloSim(BaseAlgo):
def __init__(self, options):
feature_variables = options.get('feature_variables', {})
target_variable = options.get('target_variable', {})
if len(feature_variables) == 0:
raise RuntimeError('You must spply one or more fields')
if len(target_variable) > 0:
raise RuntimeError('MonteCarloSim does not support the from clause')
# Check to see if parameters exist
params = options.get('params', {})
# Check if method is in parameters in search
if 'counter' in params:
self.counter = int(params['counter'])
else:
self.counter = 5000
# Check for bad parameters
if len(params) > 1:
raise RuntimeError('The only valid parameter is counter.')
def fit(self, df, options):
""" Compute the Monte Carlo Simulator """
# df contains all the search results, including hidden fields
# but the requested are saved as self.feature_variables
input_df = df[self.feature_variables]
input_df.sort_values(by=['date'])
input_df.set_index('date', inplace=True)
codes = input_df.columns
days = input_df.shape[0]/len(codes)
daily_ret = input_df.pct_change()
annual_ret = daily_ret.mean() * days
daily_cov = daily_ret.cov()
annual_cov = daily_cov * days
port_ret = []
port_risk = []
port_weights = []
for _ in range(self.counter):
weights = np.random.random(len(codes))
weights /= np.sum(weights)
returns = np.dot(weights, annual_ret)
risk = np.sqrt(np.dot(weights.T, np.dot(annual_cov, weights)))
port_ret.append(returns)
port_risk.append(risk)
port_weights.append(weights)
portfolio = { 'Returns' : port_ret, 'Risk': port_risk }
for i, s in enumerate(codes):
portfolio[s] = [weight[i] for weight in port_weights]
output_df = pd.DataFrame(portfolio)
output_df = output_df[['Returns', 'Risk'] + [s for s in codes]]
return output_df알고리즘을 입력.
알고리즘 설명
- 알고리즘을 새로 생성하기 위해서는 MLTK의 BaseAlgo 를 상속받아서 필요한 함수들을 구현해 주어야 한다.
class MonteCarloSim(BaseAlgo):- 이 실습에선 실제 모델을 생성하는 알고리즘이 아니기 때문에 init 과 fit 함수 필요. 학습 모델을 만들기 위해서는 스플렁크의 다음 메뉴얼을 참조
https://docs.splunk.com/Documentation/MLApp/5.2.0/API/SupportVectorRegressor
- init 함수, 이는 SPL에서 오는 옵션들을 파싱해서 유효성을 검사하고 변수로 가지고 있는 부분을 처리
def __init__(self, options):
feature_variables = options.get('feature_variables', {}) # 알고리즘에 사용할 컬럼들
target_variable = options.get('target_variable', {}) # 알고리즘의 from절에 사용하는 필드로 여기에서는 사용하지 않음
if len(feature_variables) == 0: # 컬럼이 정의되지 않으면 에러 발생
raise RuntimeError('You must spply one or more fields')
if len(target_variable) > 0: # 타겟 필드가 있으면 에러 발생
raise RuntimeError('MonteCarloSim does not support the from clause')
# 알고리즘에 있는 옵션들
params = options.get('params', {})
# 시뮬레이션을 할 개수를 설정하고 설정되어 있지 않으면 5,000번을 수행한다.
if 'counter' in params:
self.counter = int(params['counter'])
else:
self.counter = 5000
# 1개 이상의 파라미터가 존재하면 에러 발생
if len(params) > 1:
raise RuntimeError('The only valid parameter is counter.')- 알고리즘을 수행하는 부분인 fit 함수
def fit(self, df, options):
""" Compute the Monte Carlo Simulator """
# df는 숨겨진 필드들을 포함해서 전달이 되는데,
# 알고리즘에서 필요한 필드들은 self.feature_variables 에 포함되어 있기 때문에
# 필요한 필드들만 선택한다.
input_df = df[self.feature_variables]
##### 이후에는 필요한 알고리즘을 DataFrame을 이용해 필요한 알고리즘을 수행하는 부분이다.
...
# 수행한 만들어진 DataFrame 을 리턴하면 splunk 에 다시 전달된다.
return output_df검색어
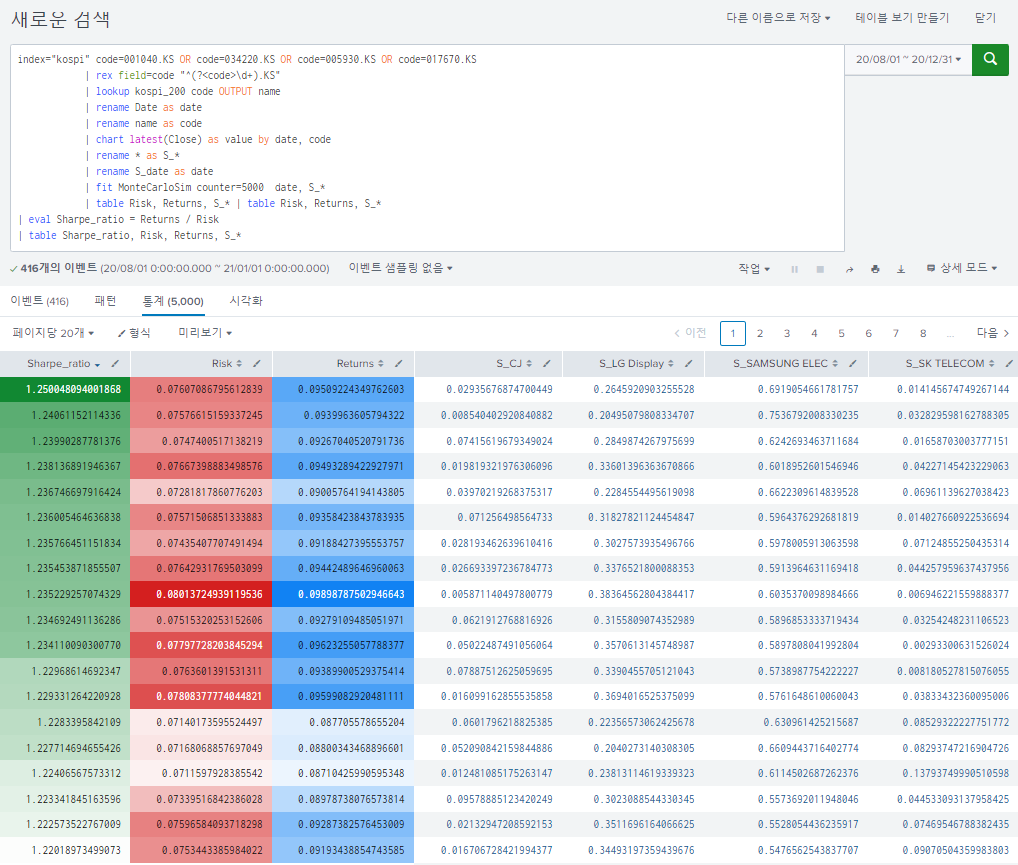
설정 - MonteCarloSim 검색해서 있는지 확인 후
index="kospi" code=001040.KS OR code=034220.KS OR code=005930.KS OR code=017670.KS
| rex field=code "^(?<code>\d+).KS"
| lookup kospi_200 code OUTPUT name
| rename Date as date
| rename name as code
| chart latest(Close) as value by date, code
| rename * as S_*
| rename S_date as date
| fit MonteCarloSim counter=5000 date, S_*
| table Risk, Returns, S_* | table Risk, Returns, S_*
| eval Sharpe_ratio = Returns / Risk
| table Sharpe_ratio, Risk, Returns, S_*"fit" 명령은 MLTK 명령의 학습을 수행하는 명령이고 ,그 다음 "MoteCarloSim" 은 알고리즘 이름이다. 이 후에 옵션 "counter=10000"은 시뮬레이션 수행 횟수 이고 그 이후에는 학습에 필요한 컬럼들이 되겠다. 하지만 불행하게도 MLTK 에는 몬테 카를로스 시뮬레이션 알고리즘을 가지고 있지 않다. 그리고 스플렁크에서 10,000 번의 연산의 반복을 수행하는 것도 그렇게 바람직해보이지 않는다.
그래서 MLTK에 이 시뮬레이션을 알고리즘으로 추가해 보겠다.
대시보드에 입력
각 필드의 붓 버튼 클릭해서 그라데이션 이펙트 삽입
기존 대시보드에 입력하고 원본 편집
<label>포트폴리오 분석</label>
<search id="monte">
<query>
index="kospi" $codes$
| rex field=code "^(?<code>\d+).KS"
| lookup kospi_200 code OUTPUT name
| rename Date as date
| rename name as code
| chart latest(Close) as value by date, code
| rename * as S_*
| rename S_date as date
| fit MonteCarloSim counter=10000 date, S_*
| table Risk, Returns, S_*
</query>
<earliest>0</earliest>
<latest></latest>
<sampleRatio>1</sampleRatio>
</search>
<description>주식분석</description>
<fieldset submitButton="true">
<input type="multiselect" token="codes">
<label>주식종목</label>
... 생략
<row>
<panel>
<title>몬테카를로스 포트폴리오</title>
<chart>
<search base="monte">
<query>table Risk, Returns</query>
</search>
... 생략
<row>
<panel>
<title>포트폴리오 비율</title>
<table>
<search base="monte">
<query>table Risk, Returns, S_* | table Risk, Returns, S_*
| eval Sharpe_ratio = Returns / Risk
| table Sharpe_ratio, Risk, Returns, S_*</query>
</search>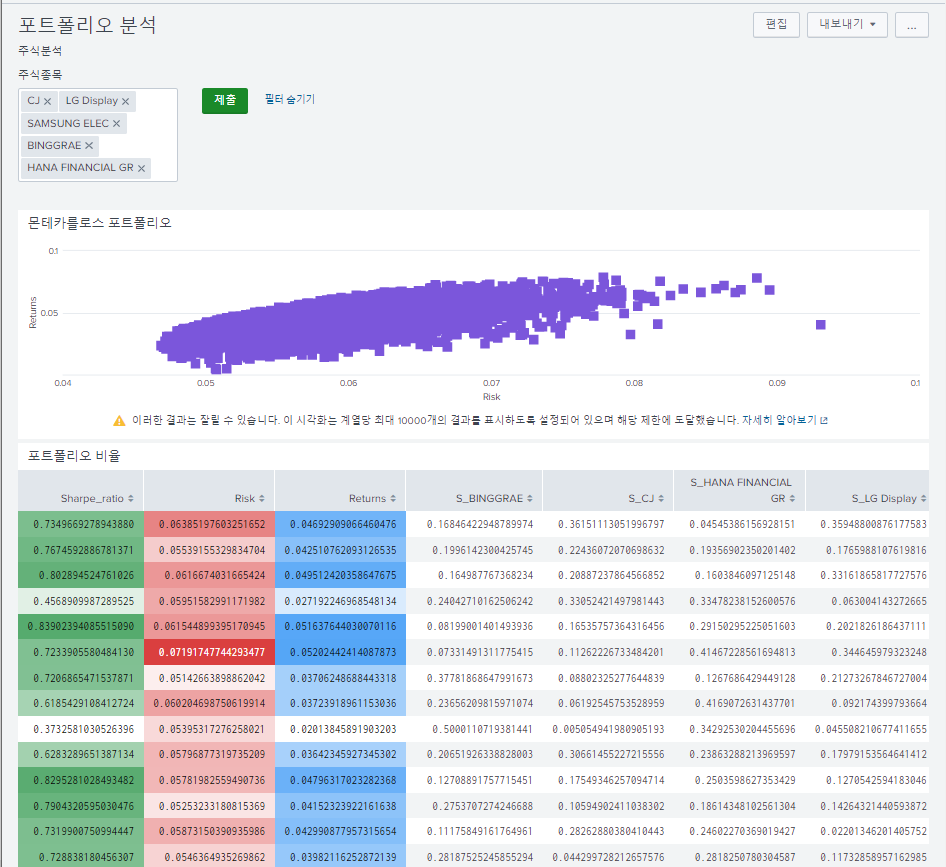

배운 건 써 먹자