파이썬을 활용한 증권 데이터 분석
개요
6장의 포트폴리오 알고리즘을 바탕으로 스플렁크 밖에서 무작위 종목을 골라 시뮬레이션을 돌리고, 그 중에서 가장 좋은 sharpe 값을 가진 종목을 선택하여 스플렁크에 저장하고 종목을 추천
중점
1) 파이썬용 스플렁크 SDK 를 이용해 파이썬 에서 스플렁크 데이터 가져오기
2) HEC 를 이용해서 application 에서 스플렁크로 데이터 입력하기
3) 스플렁크 매크로 이용하기
스플렁크 SDK 활용
$ pip3 install splunk-sdk
OR
$ pip install splunk-sdk난 이미 그 전에 splunklib를 다운받고 복사하면서 함께 설치했음
splunk_data_reader.py 편집
위치 : /opt/splunk/example_stock
$ vi splunk_data_reader.py
# Splunk 에서 데이터를 불러오기위한 라이브러리 import
import splunklib.results as results
import splunklib.client as client
import io, os, sys, types, datetime, time
import pandas as pd
"""
스플렁크에 SPL 을 수행해서 데이터를 가져온다.
@host : 스플렁크 설치 호스트
@port: 스플렁크 REST API 접속 포트 (8089)
@username: 스플렁크 접속 계정
@password: 스플렁크 접속 패스워드
"""
class SplunkDataReader():
def __init__(self, host, port, username, password):
self._host = host
self._port = port
self._username = username
self._password = password
self._service = None
"""
스플렁크에 접속한다.
"""
def connect(self):
self._service = client.connect(host=self._host,
port = self._port,
username = self._username,
password = self._password);
"""
스플렁크에 SPL 을 수행해서 데이터를 읽어서 결과를 리턴한다.
@searchquery_normal: 일반적인 SPL 문
"""
def execute_query(self, searchquery_normal,
kwargs_normalsearch={"exec_mode":"normal"},
kwargs_options={"output_mode":"csv", "count":100000}):
# 스플렁크에 SPL 을 수행하면 해당 job 이 생성된다. 이 Job을 통해 async 하게 데이터를 가져와야 한다.
job = self._service.jobs.create(searchquery_normal, **kwargs_normalsearch)
# 모든 작업이 끝날 때까지 대기하기 위해 Loop 수행 (@TODO 여러 쿼리를 수행해야 하는 경우 Thread 처리해야 함)
while True:
# 작업이 실행 준비 되었는지 체크하고 아니면 계속 모니터링
while not job.is_ready():
pass
# 현재 작업이 수행 중에 있고, 작업의 상태를 모니터링 한다.
stats = {"isDone":job["isDone"], "doneProgress":float(job["doneProgress"]) *100,
"scanCount":int(job["scanCount"]), "eventCount":int(job["eventCount"]),
"resultCount":int(job["resultCount"])}
status = ("\r%(doneProgress)03.1f%% %(scanCount)d scanned"
"%(eventCount)d matched %(resultCount)d results") % stats
# 작업 상태를 사용자를 위해 출력
sys.stdout.write(status)
sys.stdout.flush()
# 작업 상태가 완료가 되었다면 루프를 빠져나감
if stats["isDone"] == "1":
sys.stdout.write("\nDone!")
break;
time.sleep(0.5)
# 작업 결과를 받아오고, 데이터프레임에 저장
csv_results = job.results(**kwargs_options).read()
df = pd.read_csv(io.BytesIO(csv_results), encoding='utf8', sep=',')
# 작업을 제거
job.cancel()
# 결과 리턴
return dfAPI를 통한 스플렁크 접속 설정
sudo vi /opt/splunk/etc/system/local/server.conf
[general]
...
allowRemoteLogin = alwaysmonte_sim.py 생성
위치 : /opt/splunk/example_stock
import pandas as pd
import numpy as np
class MonteCarloSim():
def __init__(self, numiter=5000):
self.counter = numiter
def fit(self, df):
""" Compute the Monte Carlo Simulator """
# df contains all the search results, including hidden fields
# but the requested are saved as self.feature_variables
df.sort_values(by=['date'])
df.set_index('date', inplace=True)
codes = df.columns
days = df.shape[0] / len(codes)
daily_ret = df.pct_change()
annual_ret = daily_ret.mean() * days
daily_cov = daily_ret.cov()
annual_cov = daily_cov * days
port_ret = []
port_risk = []
port_weights = []
port_sharpe = []
for _ in range(self.counter):
weights = np.random.random(len(codes))
weights /= np.sum(weights)
returns = np.dot(weights, annual_ret)
risk = np.sqrt(np.dot(weights.T, np.dot(annual_cov, weights)))
port_ret.append(returns)
port_risk.append(risk)
port_weights.append(weights)
port_sharpe.append(returns/risk)
portfolio = { 'Sharpe': port_sharpe, 'Returns' : port_ret, 'Risk': port_risk }
for i, s in enumerate(codes):
portfolio[s] = [weight[i] for weight in port_weights]
output_df = pd.DataFrame(portfolio)
output_df = output_df[['Sharpe', 'Returns', 'Risk'] + [s for s in codes]]
return output_df메인함수에서 실행될 run_portpolio.py
위치 : /opt/splunk/example_stock
# 방금 만들 파이썬 파일들 import
from splunk_data_reader import SplunkDataReader
from monte_sim import MonteCarloSim
import pandas as pd
import numpy as np
import argparse
from datetime import datetime, timedelta
import json
import os
import sys
from random import seed
from random import randinte
import time
import requests
import urllib3
# kospi_200. csv 파일을 읽기 위한 경로 설정
CONF_PATH=os.path.dirname(os.path.abspath(__file__))
LOG_PATH=CONF_PATH + '/stock'
# kospi_200.csv 에서 주식 종목 리스트를 읽어온다.
def getCodeList():
df = pd.read_csv(CONF_PATH + "/kospi_200.csv", dtype=str)
return df.code.values
seed(datetime.now()) # 랜덤 시드 초기화
"""
kospi 200 목록에서 종목을 선택한다.
@codebook[] : 전체 종목 리스트
@codes[]: 필수적으로 포함시키고 싶은 종목 목록
@ num: 총 선택할 종목 수
"""
def genRandomCode(codebook, codes, num):
random_ranges = len(codebook)
# num=5 이고 필수적으로 포함시켜향 종목의 수가 2 이면 3개의 종목이 랜덤하게 선택된다.
itera = num - len(codes)
ran_code = [ code for code in codes]
for _ in range(itera):
while True:
# 랜덤하게 종목 코드 하나 선택
code = codebook[randint(0, random_ranges-1)] + ".KS"
# 이미 포함 된 코드이면 pass
if code in ran_code:
pass
# 새로운 코드면 추가
else:
ran_code.append(code)
break
return ran_code
"""
스플렁크에서 필요한 데이터를 읽어온다.
@reader: 스플렁크 접속 객체
@codes[]: 주식 종목 리스트
@days: 가져올 데이터의 날 수
"""
def readData(reader, codes, days=180):
#스플렁크 SPL 문
splunk_query="""
search index=kospi {codes} earliest={days}
| rename Date as date
| chart latest(Close) as value by date, code
"""
code_str = " OR ".join(codes)
days_str = "-" + str(days) + "d@"
# SPL을 수행해서 데이터를 가져온다.
df = reader.execute_query(splunk_query.format(codes=code_str, days=days_str))
return df
"""
HEC 를 통해 스플렁크에 결과 데이터를 저장한다.
@host: 스플렁크 접속 서버
@token: 스플렁크에서 발급한 접속 토근
"""
authToken = "XXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX" # @TODO 나의 토큰으로 대체
splunkhost = "localhost" # @TODO 나의 서버 주소로 대체
def splunkHec(host, token, data):
url="https://" + host + ":8088/services/collector/event"
authHeader = {'Authorization': 'Splunk ' + token}
payload = {}
payload.update({"index":"monte"}) # "monte" 라는 인덱스에 저장
payload.update({"sourcetype":"_json"}) # "_json" 소스타입으로 저장
payload.update({"source":"monte_sim.py"}) # "monte_sim.py" 소스로 저장
payload.update({"event": data}) # "저장할 데이터 메시지"
r = requests.post(url, headers=authHeader, json=payload, verify=False) # 스플렁크로 데이터 전송
"""
반복해서 임의의 코드 종목을 선택하여 최상의 종목 조합을 찾음
@ reader: 스플렁크 접속 객체
@ codebook: 주식 종목 리스트
@ required_codes: 반드시 포트폴리오에 포함해야할 코드 목록
@ num: 포트폴리오를 구성할 주식 종목의 수
@ repeat: 반복 횟수
"""
def findBestPortpolio(reader, codebook, required_codes, num, repeat=10000):
# 몬테카를로 시뮬레이터 객체 생성
sim = MonteCarloSim()
# repeat 만큼 반복해서 주식 종목 선택 수행
for idx in range(repeat):
# 랜덤한 주식 종목을 가져온다.
c = genRandomCode(codebook, required_codes, num)
# 선택된 주식 종목에 대해서 스플렁크에서 해당 데이터를 가져온다.
df = readData(reader, c, days)
# 몬테카를로 시뮬레이터를 수행한다.
monte_df = sim.fit(df)
# Sharpe 값이 가장 좋은 항목을 선택한다.
monte_max = monte_df.loc[monte_df['Sharpe'].idxmax()]
# 선택된 데이터에 대해서 스플렁크에 전달할 데이터 모양을 만든다.
dic = {}
codes = []
rates = []
for key in monte_max.keys():
if key not in ['Sharpe', 'Returns', 'Risk']:
codes.append(key)
rates.append(monte_max[key])
else:
dic[key] = monte_max[key]
dic['idx'] = idx
dic["code"] = codes
dic["rate"] = rates
dic["date"] = datetime.now().strftime("%Y-%m-%d")
data = json.dumps(dic)
# 스플렁크로 해당 데이터를 보낸다.
splunkHec(splunkhost, authToken, data)
# 인자로 전달되는 코드의 유효성 체크
def verifyCode(required):
codes = required.split(",")
codes = [ v + ".KS" if len(v)==6 else v for v in codes]
return codes;
if __name__ == "__main__":
# 전달받는 파라미터 설정
parser = argparse.ArgumentParser()
parser.add_argument('--days', help='days help')
parser.add_argument('--num', help='num help')
parser.add_argument('--required', help='required help')
parser.add_argument('--repeat', help='repeat help')
args = parser.parse_args()
if args.days:
days = int(args.days)
else:
days = 180
if args.num:
num = int(args.num)
else:
num = 5
if args.repeat:
repeat = int(args.repeat)
else:
repeat = 1000
codes =[]
if args.required:
codes = verifyCode(args.required);
# 주식 종목 리스트 읽기
codebook = getCodeList()
# 스플렁크 접속 객체 생성 @TODO 나의 접속 정보로 수정
reader = SplunkDataReader("localhost", 8089, "my_account", "my_password")
# 스플렁크에 접속
reader.connect()
# 포트 폴리오 검색 수행
findBestPortpolio(reader, codebook, codes, num, repeat)수행 전 스플렁크에서 해야하는 작업
- "monte" 인덱스 생성
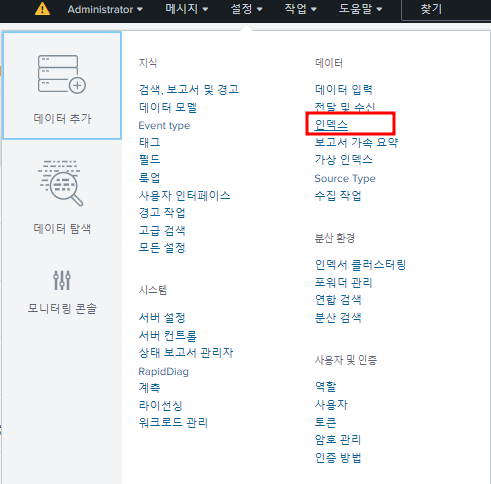
- "HEC" 토큰 생성
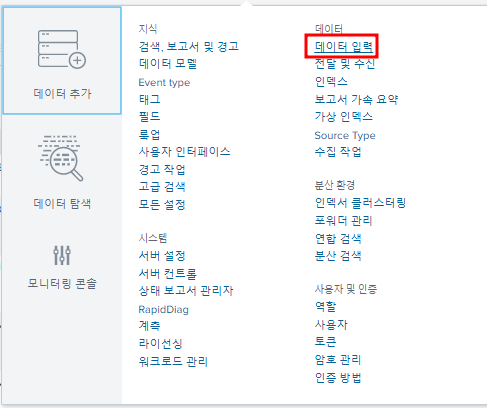
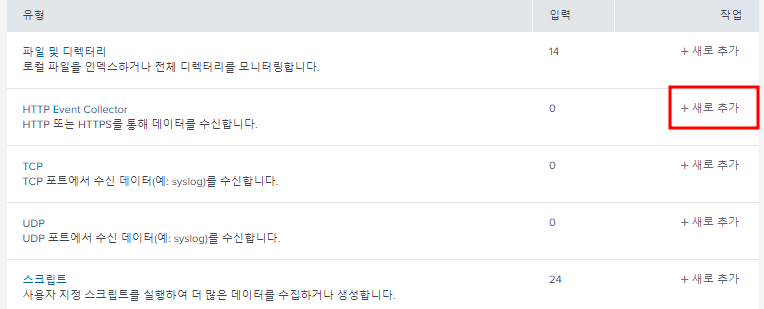
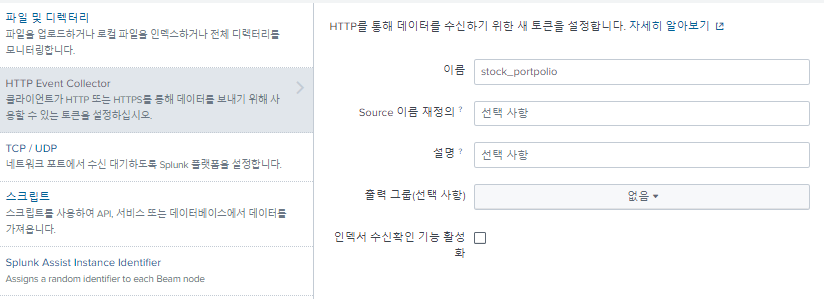
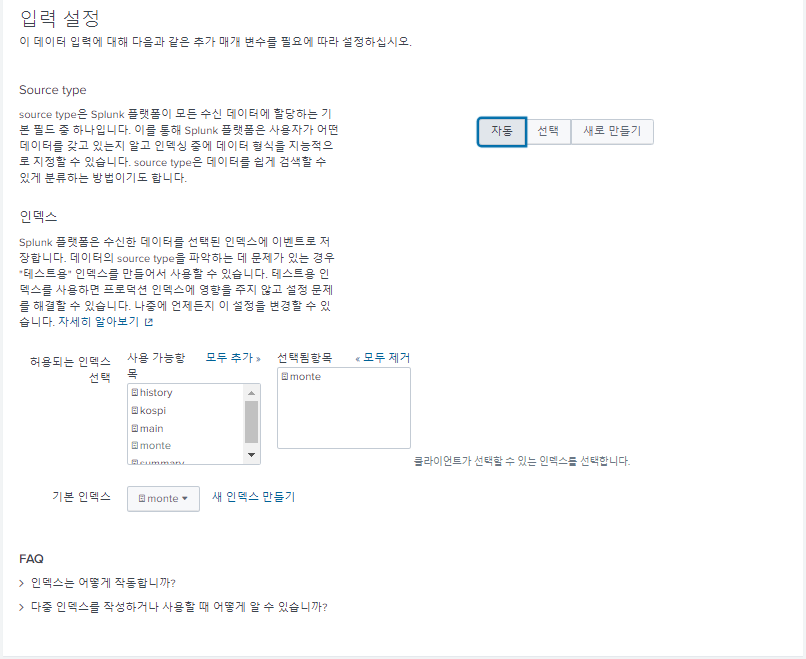
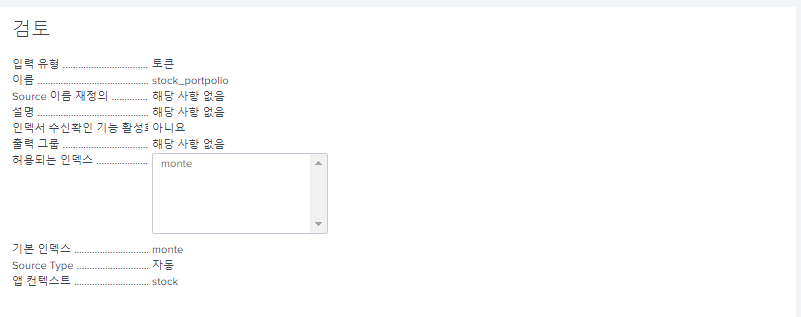
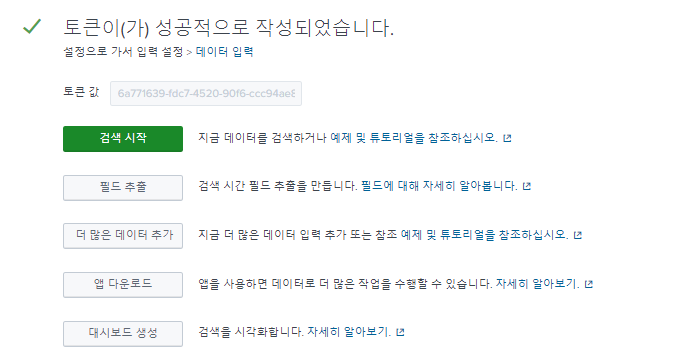
- 토큰 값을 복사하여 파이썬 파일에 붙여넣어 사용
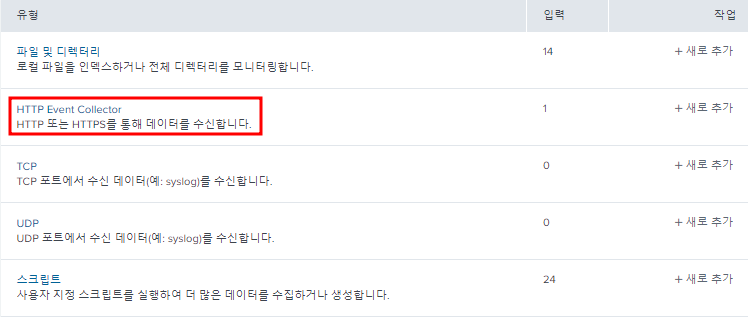
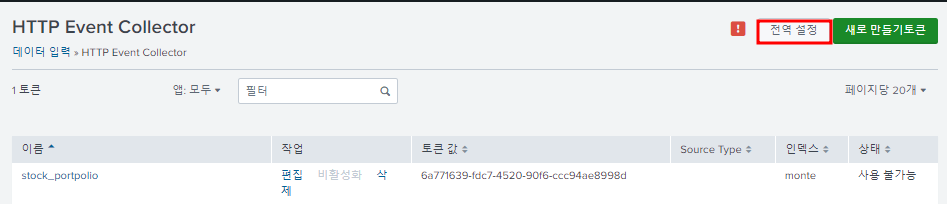
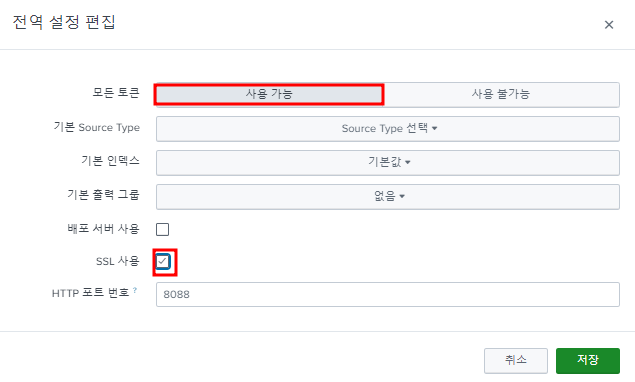
한번도 HEC 토큰을 생성하지 않았으면 HTTP Event Collector에서 다음 "전역 설정"을 해야한다
run_portpolio.py 파일에서
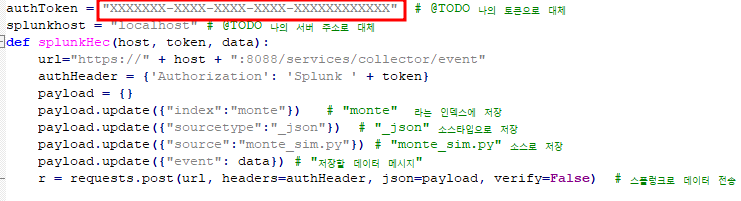
이 부분을 내 토큰 값으로 변경
파이썬 실행
$ python3 run_portpolio.py --days 350 --num 5 --repeat 1000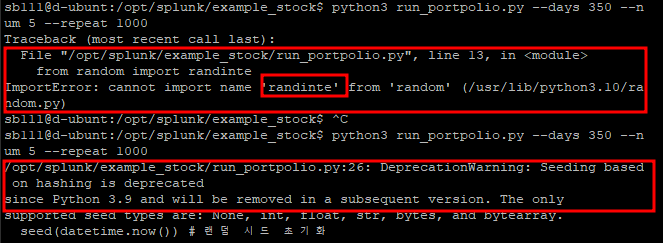
- "randinte" 가 아니라 "randint" 이다
- "seed(datetime.now())" 대신 다른 형태의 데이터가 들어가야함
수정 전
seed(datetime.now()) # 랜덤 시드 초기화
수정 후
curr_dt = datetime.now()
timestamp = int(round(curr_dt.timestamp()))
seed(timestamp) # 랜덤 시드 초기화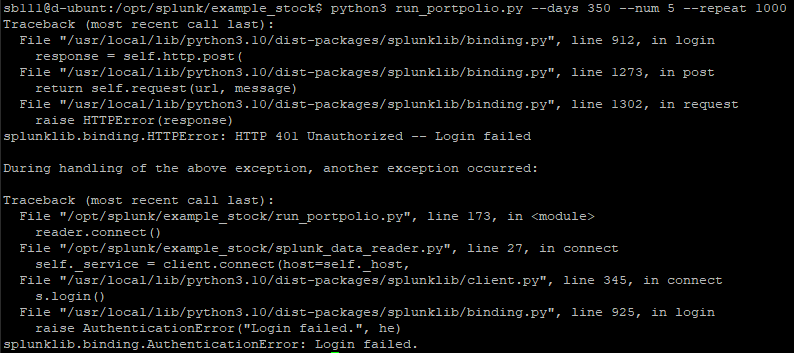
찾아본다
https://github.com/rgerganov/py-air-control/issues/21
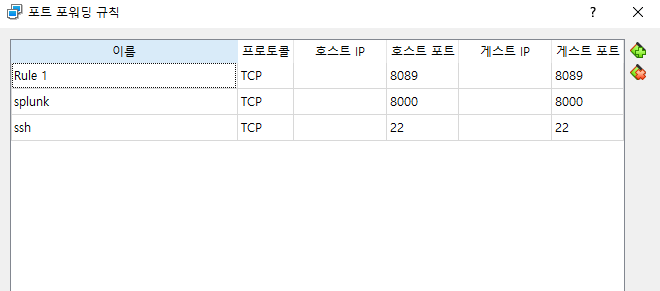
접속거부 당하길래 찾아보니 포트를 연결해주었냐는 답변을 보고 리눅스 서버의 포트포워딩을 추가해주니 달라지긴 했는데 다른 에러 발생
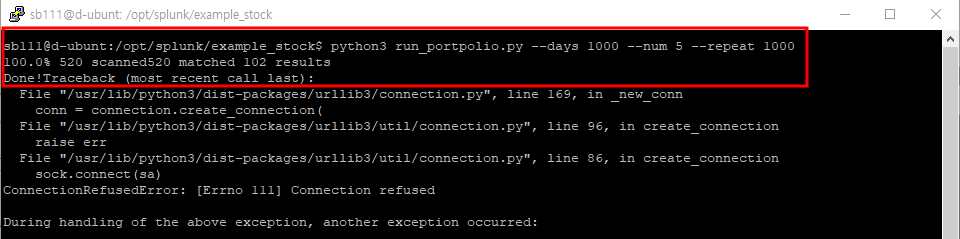
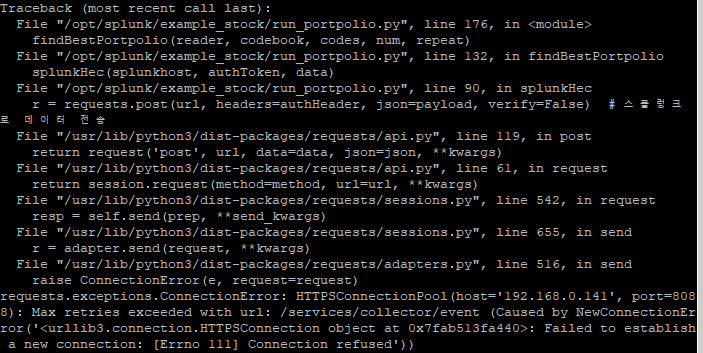
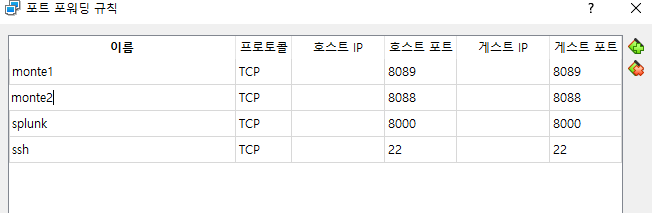
최하단의 에러 메시지를 보고 8088포트를 또 열어봤더니 된다.
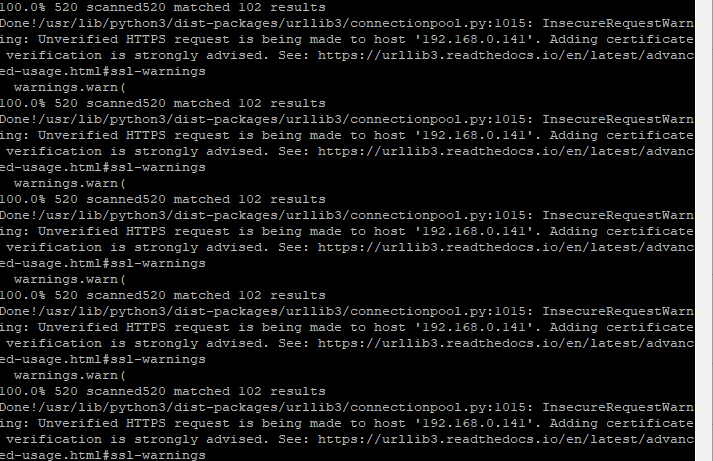
같은 에러 메시지가 반복적으로 나오는데 아마도 1000회 반복 명령 때문에 그런 것 같다. 중간에 멈추고 요청 인증 오류인 것 같아서 해결해본다. --> 그냥 경고 메시지니까 그냥 둔다. 그래도 해결 링크는 걸러둔다
https://sun2day.tistory.com/226
https://www.inflearn.com/questions/120633
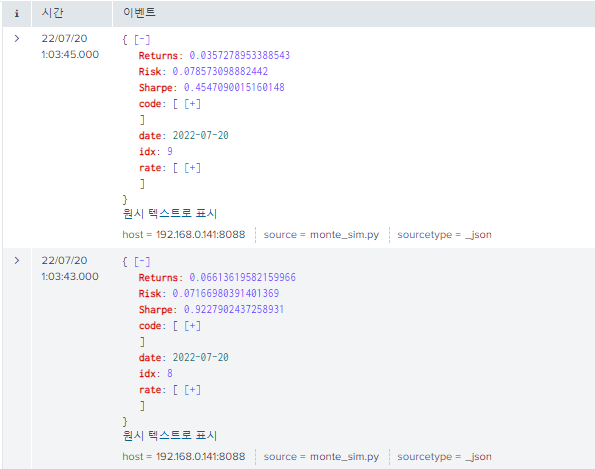
교안과 비교해서 비슷한 결과각 나온 거 같다
index="monte"
| head 1
| mvexpand code{}
| rename code{} as code
| table date, idx, code, Sharpe, Returns, Risk, rate{}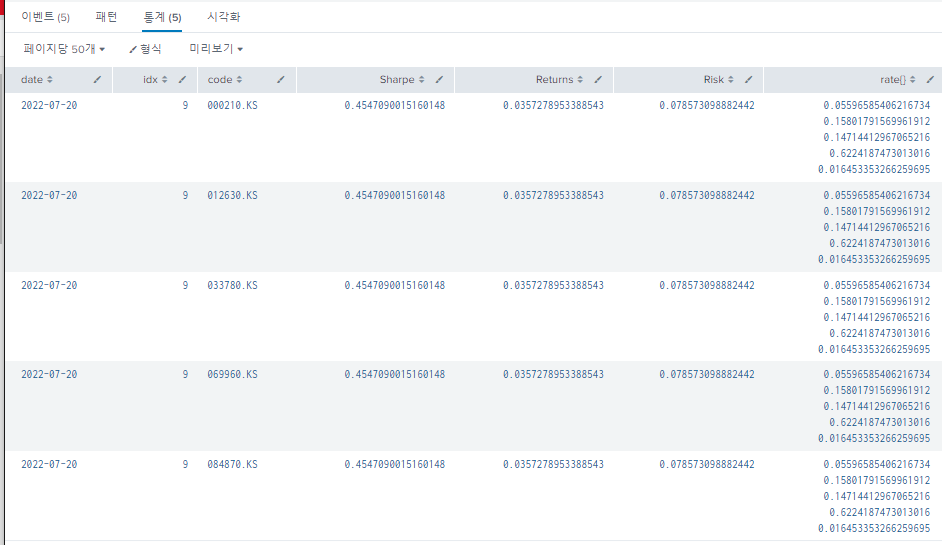
code와 rate를 독립된 열로 펼치기 위해 사용하는 "mvexpand" 명령
rates와 codes의 짝을 맞추어 출력하기 위한 명령어
index="monte"
| head 1
| rename code{} as codes
| rename rate{} as rates
| eval fields_value=mvzip(codes, rates)
| mvexpand fields_value
| eval fields_value = split(fields_value, ",")
| eval code = mvindex(fields_value, 0)
| eval rate = mvindex(fields_value, 1)
| rex field=code "^(?<code>\\d+).KS"
| lookup kospi_200 code OUTPUT name
| table date, idx, code, Sharpe, Returns, Risk, rate- "mvzip"함수로 두 개의 배열을 서로 하나의 배열로 묶어줌
- 묶은 배열을 "mvexpand"로 확장해주면 아래같은 결과가 나오고
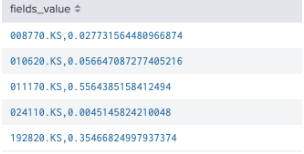
- "split()" 함수를 사용하면 아래의 최종결과가 나옴

위의 과정을 자동으로 설정하는 macro

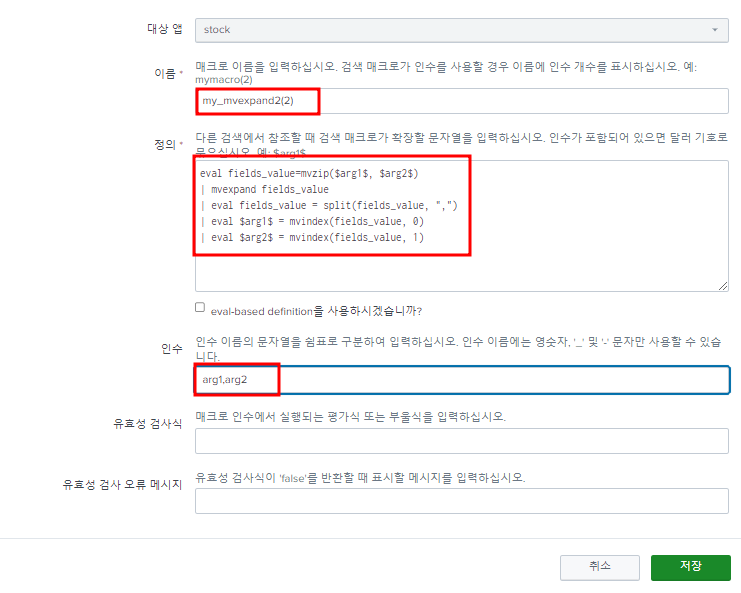
"stock" 앱을 타겟으로 하고 "my_mvexpand2"라는 이름 뒤에 "(2)"는 전달받을 인수의 수를 설정하는 의미인 듯 하다. "codes"를 "arg1" "rates"를 "arg2"로 전달 받을 것이고, 이를 "Arguments" 부분에 정의한다. "codes", "rates" 부분만 전달 받을 변수명을 치환하고 저장
index="monte"
| head 1
| rename code{} as codes
| rename rate{} as rates
| `my_mvexpand2(codes, rates)`
| rex field=code "^(?<code>\\d+).KS"
| lookup kospi_200 code OUTPUT name
| table date, idx, codes, Sharpe, Returns, Risk, rates매크로를 활용한 검색문의 결과

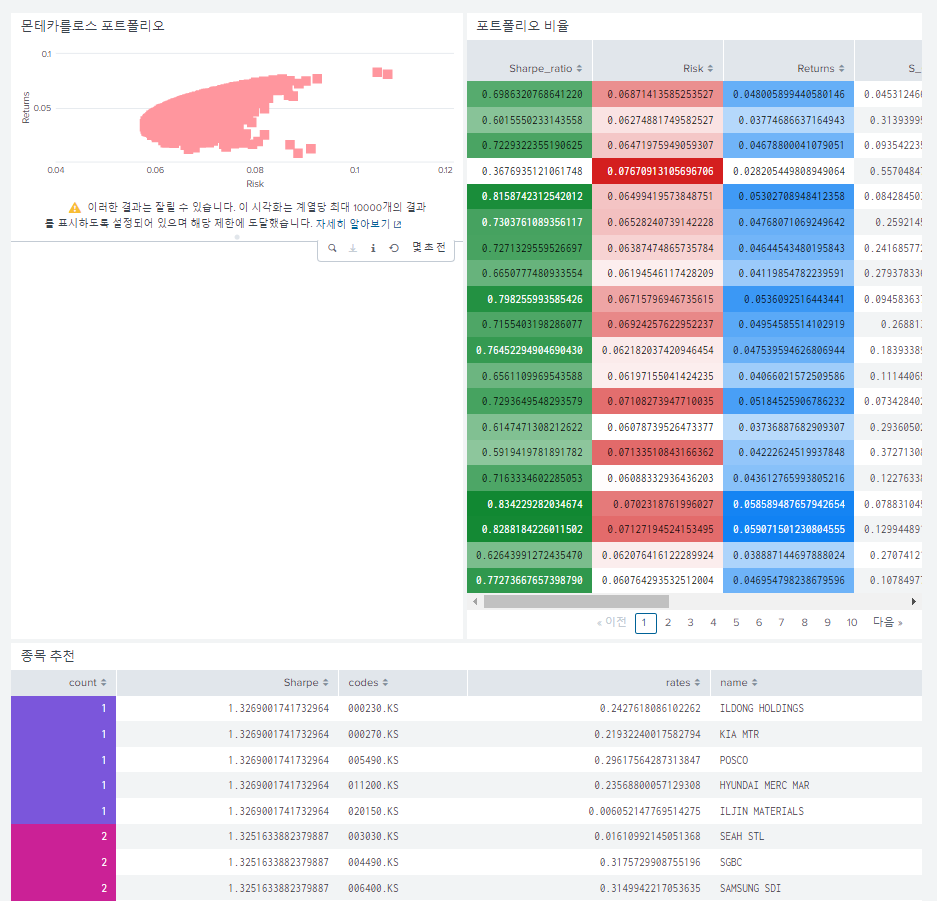
베스트 포트폴리오 추천 종목 만들기
index="monte"
| rename code{} as codes, rate{} as rates
| eventstats latest(date) as latest_date
| where date = latest_date
| table date, Sharpe, codes , rates
| sort -Sharpe limit=5
| streamstats count
| `my_mvexpand2(codes, rates)`
| rex field=codes "^(?<code>\d+).KS"
| lookup kospi_200 code OUTPUT name
| table count, Sharpe, codes, rates, name기존에 만들어둔 주식 포트폴리오에 추가하면 다음과 같은 최종 결과가 출력된다
PS. 리눅스 에러가 발생했다면 가장 처음에 출력되는 에러보다 마지막에 출력된 에러를 해결하는게 먼저인 거 같다.
