A REST Service for Apache Spark
Why Livy?
Spark를 사용하는데에 있어서 많은 방법론들이 존재합니다.
그 중 Livy를 선택하였는데, 왜 Livy를 선택했는지? 먼저 얘기해보고자 합니다.
REST Service
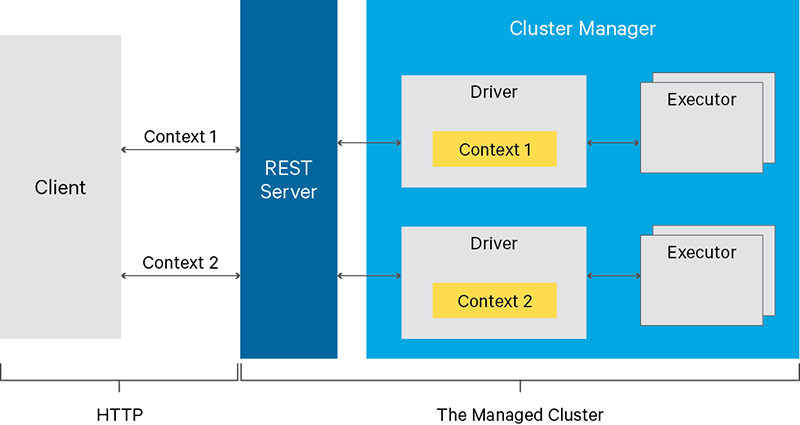
위 그림에서 REST Server에 해당하는 것이 Livy입니다.
현재 제가 사용하고 있는 프로젝트는 Spring Boot 3 + Java 17로 이루어져 있습니다.
하지만 Java 17에서 Spark를 사용하려면 DirectBuffer 에러가 터지므로 JVM Option을 수정해줘야 합니다.
또한 Spring에서 servlet, antlr 라이브러리 관련 문제도 같이 야기되고 log4j2 라이브러리 충돌 등, 이러한 문제점들에 대해서 벗어나고 싶었습니다.
그렇다면 Spark를 위한 서버를 따로 생성해야했는데, 일일이 직접 작성하기보다는 Livy 서버를 사용하게 됐습니다.
StandAlone / Multiple Spark Contexts
우선 저는 Web Application에서 Spark를 사용할 때, StandAlone 방식이 아닌 spark-submit 이후 driver와 executor가 뜨고 Job을 수행하는 방식을 구현하는 방법을 찾지 못했습니다.
저는 k8s 환경에서 Spark를 사용하기 때문에 Spark의 Dockerfile과 [entrypoint.sh] (https://github.com/apache/spark/blob/master/resource-managers/kubernetes/docker/src/main/dockerfiles/spark/entrypoint.sh) 를 본다면 이들을 가지고 driver와 executor를 띄우는 것을 볼 수 있습니다!
하지만, 이를 직접 해보기에는 꽤 골치스럽고 당장 도전적으로 하고 싶지 않았습니다.
Livy를 사용할 때도 몇몇 조금의 수정을 갖는다면 StandAlone으로 띄울지 Multi Contexts로 띄울지 선택할 수 있습니다.
Only one
SparkContextshould be active per JVM.
일반적으로 SparkContext는 JVM당 하나만 실행가능하다고 독스에 써져있습니다.
그렇다면 Spark Context를 여러 개 갖는다면 어떤 이점이 있을까요?
Spark Cluster를 분리함으로써 서로 간섭 없는 작업을 수행할 수 있습니다.
예를 들어 같은 애플리케이션에서 사용자 A가 1번 서버에 대한 권한을, B가 2번 서버에 대한 권한을 가지고 있다면 Multiple Spark Contexts로 Job을 수행시 독립적으로 원하는 서버에 제출할 수 있다는 것입니다!
서버에 제출 시에도 사용자가 원하는 만큼 동적으로 자원을 할당하여 실행 시킬 수도 있습니다.
그리고 StandAlone 방식에서는 일종의 Queue 방식처럼 Job을 순서대로 기다리거나 fair와 같이 스케줄링을 설정할 수 있는데, 단 하나의 잡을 위해 뜨기 때문에 고려해주지 않아도 좋다는 점입니다.
데이터 플랫폼에 있어서 자원 관리를 할 수 있고, 서로 독립적인 Job이 되기 때문에 Multiple Spark Contexts는 큰 장점이 됩니다.
Livy의 단점
BlackBox
많은 기술들을 쓰다보면 느끼는 점이지만, 내부적으로 어떻게 되는지 모르고 쓰는 경우가 많습니다.
물론 직접 파고 드는 것도 실력이지만, 문제에 대해서 빠르게 해결하는 것도 실력이라고 생각합니다. Livy는 많이 알려져 있지 않아, 추후 겪을 수 있는 트러블에 대해서 해결이 어려울 수 있지 않을까 싶네요.
또한 직접 만든 서버가 아니기 때문에 커스텀마이징하기가 어렵다는 점입니다.
예를 들어 스파크 잡 수행 후 Event를 발행하여 알림을 주고 싶지만, 이를 지원하지 않기 때문에 Polling으로 status를 계속 추적해야하는 경우가 있습니다.
Incubating
Apache 에서는 실질적인 프로젝트가 되기 전 Incubator 단계를 갖는데, 현재 Livy가 Incubating 입니다. 최근 github에서 활동을 보았을 때도 빠르게 업데이트가 되는 프로젝트는 아닌 듯 보여, 슬프지만 아마 Attic으로 넘어가지 않을까 싶습니다.
사용 방법
REST API
Livy Server를 띄웠다면 해당 URI로 REST API를 보내 session 생성이 가능하고 해당 session에서 job을 수행할 수 있습니다.
session에서 job을 수행하는 경우에 대해서만 알아보도록 하겠습니다.
POST /sessions/{sessionId}/statementscode: 실행할 코드 (string)kind: spark, pyspark, sparkr, sql
cloudera github에 있는 예시로 보여드리겠습니다.
data = {
'code': textwrap.dedent("""
val NUM_SAMPLES = 100000;
val count = sc.parallelize(1 to NUM_SAMPLES).map { i =>
val x = Math.random();
val y = Math.random();
if (x*x + y*y < 1) 1 else 0
}.reduce(_ + _);
println(\"Pi is roughly \" + 4.0 * count / NUM_SAMPLES)
""")
}
r = requests.post(statements_url, data=json.dumps(data), headers=headers)코드 자체를 정말 string 자체로 넘기는 것을 볼 수 있는데, 어지럽다고도 느껴집니다.
정말 필요한 게 아니라면 일반적으로 저는 sql kind로 job을 제출할 것 같네요.
Programmatic API
우선 서버에 livy-client-http 라이브러리를 추가합니다.
그리고 jar 파일을 만들어야 합니다.
Livy 공식 문서에 있는 예시를 가져와 알아보겠습니다.
public class PiJob implements Job<Double>, Function<Integer, Integer>,
Function2<Integer, Integer, Integer> {
private final int samples;
public PiJob(int samples) {
this.samples = samples;
}
@Override
public Double call(JobContext ctx) throws Exception {
List<Integer> sampleList = new ArrayList<Integer>();
for (int i = 0; i < samples; i++) {
sampleList.add(i + 1);
}
return 4.0d * ctx.sc().parallelize(sampleList).map(this).reduce(this) / samples;
}
@Override
public Integer call(Integer v1) {
double x = Math.random();
double y = Math.random();
return (x*x + y*y < 1) ? 1 : 0;
}
@Override
public Integer call(Integer v1, Integer v2) {
return v1 + v2;
}
}위에서 Job interface 를 implements하여 PiJob을 생성합니다.
이후 서버에서 LivyClient를 통해 서버에서 Livy 서버로 이를 전달하고 Livy가 Spark로 Job을 제출하게 됩니다.
이 때 PiJob을 꼭 jar 파일로 build 하고 Livy에게 jar를 upload 해야 합니다.
spark의 driver와 executor가 이를 찾지 못하기 때문입니다.
이를 해결 하기 위해서 jar를 직접 Livy에게 upload 하는 방법이 있고 Dockerfile를 커스텀해서 Spark가 띄워질 때 jar를 직접 넣어주는 방식도 있습니다.
그리고 스파크가 참조하는 HDFS에 넣어주는 방식도 존재하여 편한 방식을 선택해주시면 될 것 같습니다!
LivyClient client = new LivyClientBuilder()
.setURI(new URI(livyUrl))
.build();
client.uploadJar(new File("path/to/CustomJar")).get();
client.submit(new CustomJob()).get();이후 서버에서 Livy로 Job을 보내 처리하게 됩니다!
하지만 이 방법마저도 하나의 문제가 존재하는데, Spark에서는 직렬화 라이브러리로 Kryo를 씁니다.
livy client 에서 Kryo 라이브러리가 있고 이 또한 Java 17에서 사용하려면 JVM Option을 수정해야하는 문제가 있습니다.
혹시 Livy를 쓰신다면 도움이 되는 글이 됐으면 합니다!
감사합니다 :)
