Intro
CloudNet@ 팀의 스터디에서 진행하는 Kubernetes Advanced Network Study 3기에 참가하게 됐습니다.
해당 페이지는 그 중 1주차에 해당하는 내용을 정리해보고자 합니다.
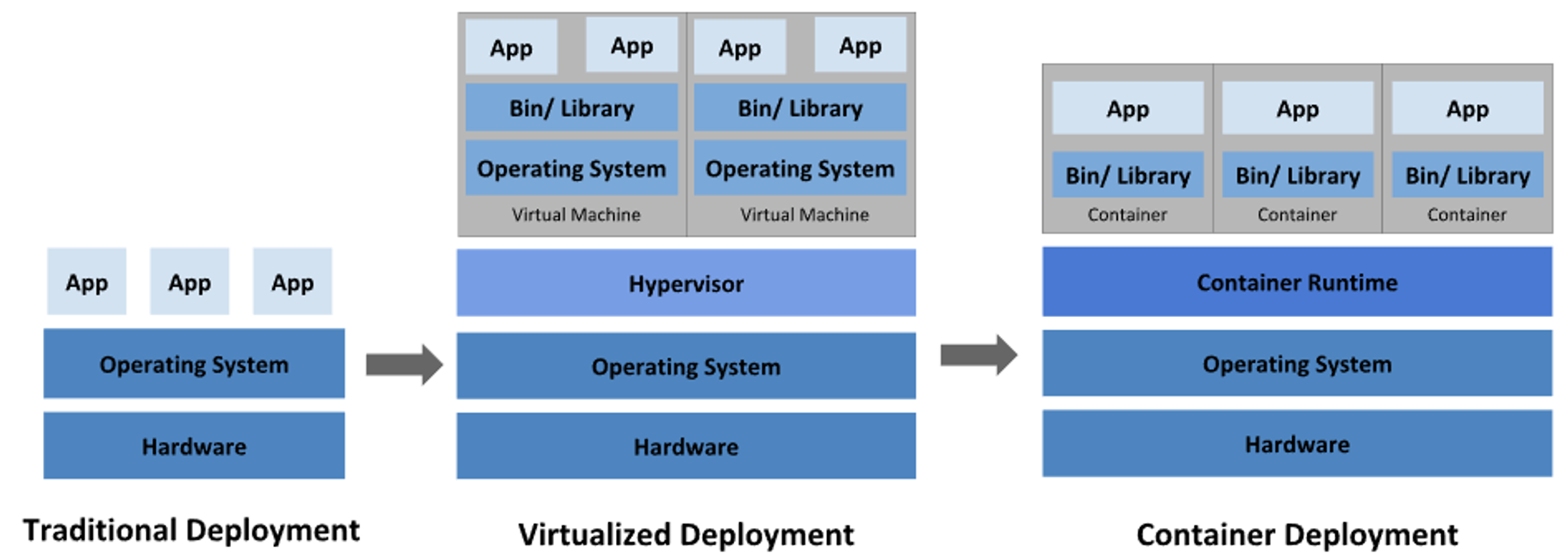
VM vs Docker
https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
VM과 Docker의 가장 큰 차이점부터 알아보겠습니다.
VM - HyperVisor를 설치하고, 그 위에 가상 OS와 패키징한 VM을 만들어 실행하는 방식 ⇒ Hardware Level 가상화
Docker - Linux Kernel 을 공유하는 방식으로 애플리케이션 실행에 필요한 파일들만 패키징 ⇒ OS Level 가상화
이로 인해 VM은 독립된 OS로 도커에 비해 고립성은 좋지만, 오버헤드가 크고 무겁다는 단점을 갖습니다.
컨테이너는 오버헤드를 줄임으로써 더 가볍게 프로세르를 실행할 수 있는 장점을 가집니다.
컨테이너는 Host의 Kernel을 공유한다는 점에서 VM와 가장 큰 차이를 보여주는데, 그렇다면 이러한 단점은 어떻게 커버를 하는 것일까요?
이는 리눅스의 격리 기술을 사용한다는 점입니다.
pivot-root / namespace / cgroup 기능들을 사용하여 Process 단위의 격리 환경을 제공합니다.
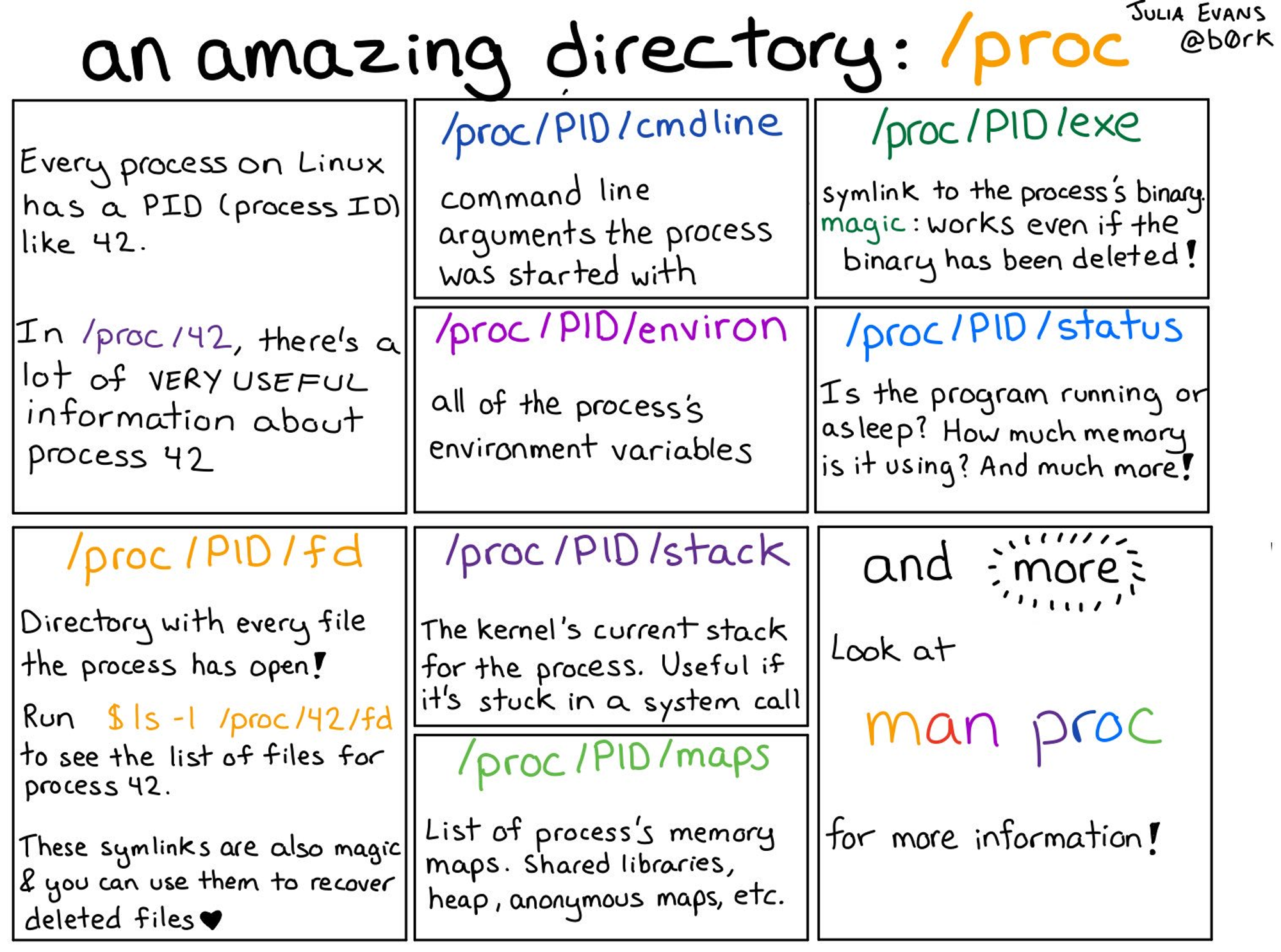
Docker의 격리 역사를 알아보기 전에 proc 에 대해서 먼저 알아보도록 하겠습니다!
https://twitter.com/b0rk/status/981159808832286720/photo/1
Linux에는 proc 이라는 특별한 directory가 존재합니다.
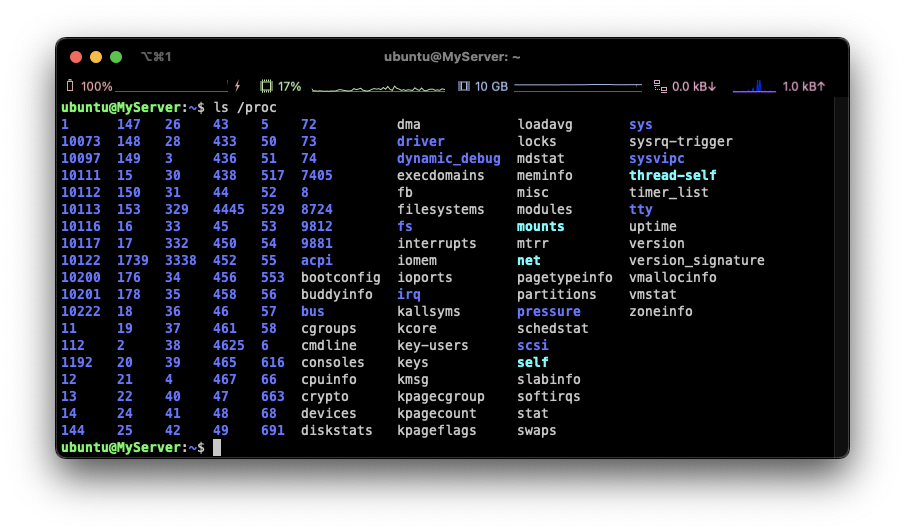
커널이 동적으로 생성하는 정보인 시스템 상태, 프로세스, HW 정보를 실시간으로 제공합니다!
/proc/cpuinfo: CPU에 대한 정보/proc/meminfo: 메모리 사용 현황/proc/uptime: 시스템이 부팅된 후 경과된 시간 (1. 총 가동 시간, 2. 시스템의 유휴 시간)/proc/loadavg: 시스템의 현재 부하 상태를 나타냅니다.
1, 5, 15분간의 시스템 부하 평균 / 현재 실행 중인 프로세스와 총 프로세스 수 / 마지막으로 실행된 PID/proc/version: 커널 버전, GCC 버전 및 컴파일된 날짜, 같은 커널의 빌드 정보/proc/filesystems: 커널이 인식하고 있는 파일 시스템의 목록/proc/partitions: 시스템에서 인식된 파티션 정보를 제공 (디스크 장치와 해당 파티션 크기 등)
위의 사진들을 보면 proc 디렉토리에 엄청 많은 숫자들이 보입니다.
이는 PID에 해당하는 것으로 해당 디렉토리들을 들어가면 다음과 같은 정보들을 얻을 수 있습니다!
/proc/[PID]/cmdline: 해당 프로세스를 실행할 때 사용된 명령어와 인자/proc/[PID]/cwd: 프로세스의 현재 작업 디렉터리에 대한 심볼릭 링크/proc/[PID]/environ: 프로세스의 환경 변수/proc/[PID]/exe: 프로세스가 실행 중인 실행 파일에 대한 심볼릭 링크/proc/[PID]/fd: 프로세스가 열어놓은 모든 파일 디스크립터에 대한 심볼릭 링크를 포함하는 디렉터리
이 파일들은 해당 파일 디스크립터가 가리키는 실제 파일이나 소켓 등을 참조/proc/[PID]/maps: 프로세스의 메모리 맵 (메모리 영역의 시작과 끝 주소, 접근 권한, 매핑된 파일 등)/proc/[PID]/stat: 프로세스의 상태 정보를 포함한 파일 (프로세스의 상태, CPU 사용량, 메모리 사용량, 부모 프로세스 ID, 우선순위 등)/proc/[PID]/status: 프로세스의 상태 정보를 사람이 읽기 쉽게 정리한 파일
(PID, PPID(부모 PID), 메모리 사용량, CPU 사용률, 스레드 수 등)
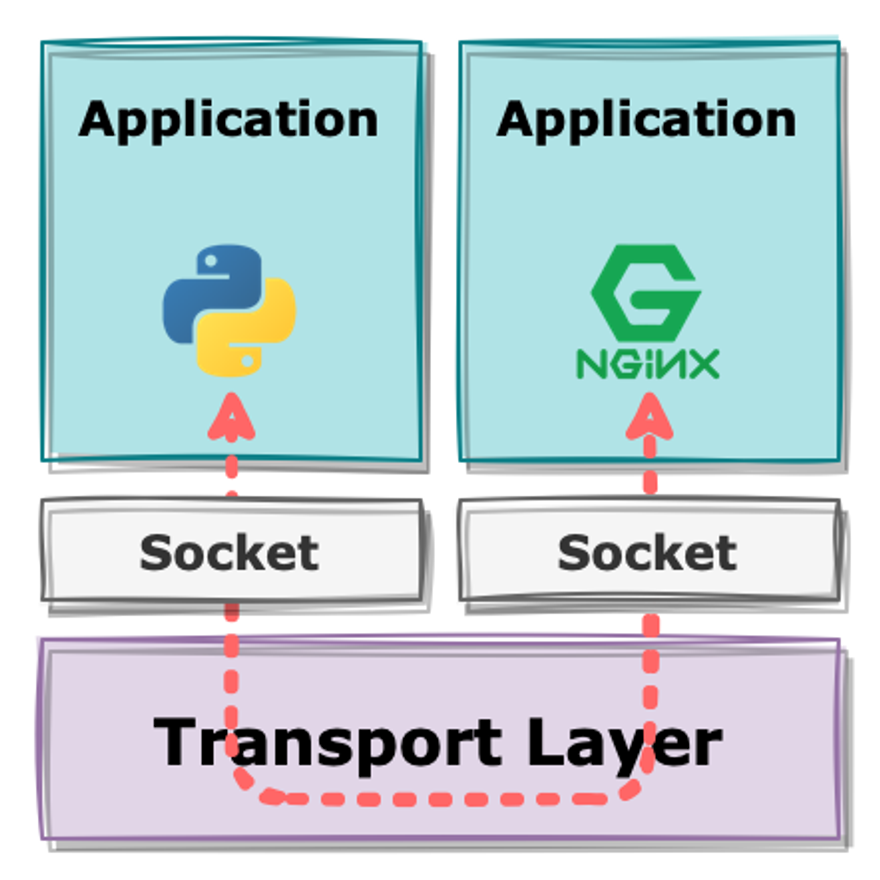
추가적으로, Docker 통신 시에도 TCP port가 아닌 Unix Domain Socket, 파일을 통해 통신한다는 것입니다.
그래서 다음과 같은 차이점을 보이게 됩니다.
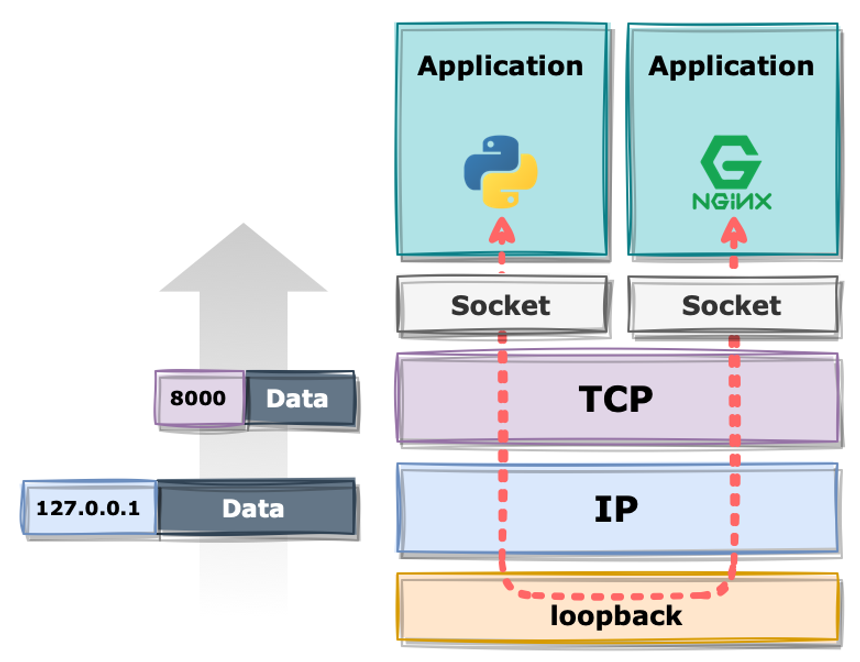
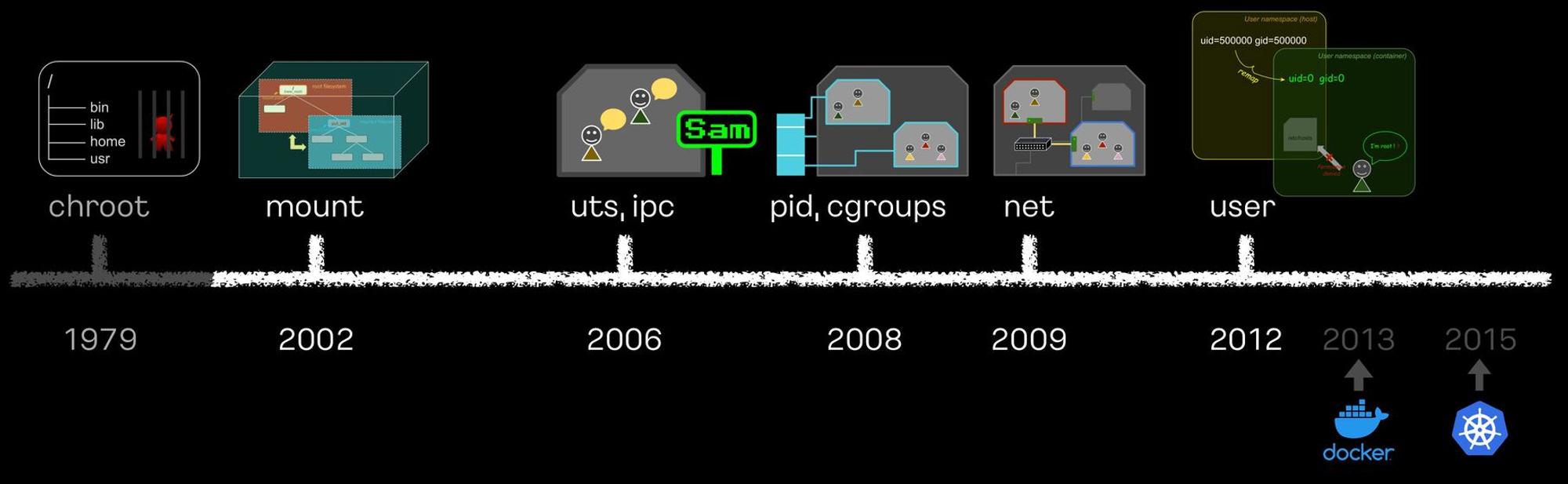
컨테이너 격리 역사
도커 없이 컨테이너 만들기를 참고하여 작성하게 됐습니다.
https://netpple.github.io/docs/make-container-without-docker/ifkakao2022-handson
그렇다면 Container 격리에 사용되는 기술들에 대해서 알아보도록 하겠습니다.
Chroot
user 디렉토리를 user 프로세스에게 root 디렉토리라고 속이는 것입니다!
ubuntu 22.04
sudo su -
cd /tmp
mkdir myroot
# 바이너리 및 라이브러리 파일 복사 (sh)
mkdir -p myroot/bin
cp /usr/bin/sh myroot/bin/
mkdir -p myroot/{lib64,lib/x86_64-linux-gnu}
cp /lib/x86_64-linux-gnu/libc.so.6 myroot/lib/x86_64-linux-gnu/
cp /lib64/ld-linux-x86-64.so.2 myroot/lib64
# 바이너리 및 라이브러리 파일 복사 (ls)
cp /usr/bin/ls myroot/bin/
mkdir -p myroot/bin
cp /lib/x86_64-linux-gnu/{libselinux.so.1,libc.so.6,libpcre2-8.so.0} myroot/lib/x86_64-linux-gnu/
cp /lib64/ld-linux-x86-64.so.2 myroot/lib64
# chroot 실행!
**chroot myroot /bin/sh**위의 스크립트를 요약하면, 사용할 파일들을 디렉토리에 모으고 가두어 격리하는 방법입니다.
실행해보면 다음과 같이 root 디렉토리가 다르게 됩니다!
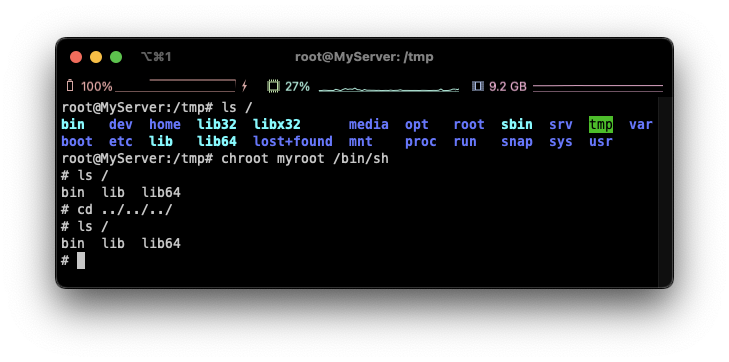
하지만 큰 단점이 있는데, 탈옥이 가능하다는 것입니다.
결국 탈옥을 하여 호스트에 접근이 가능하게 되는 아주 큰 단점이 있습니다.
mount ns + pivot_root
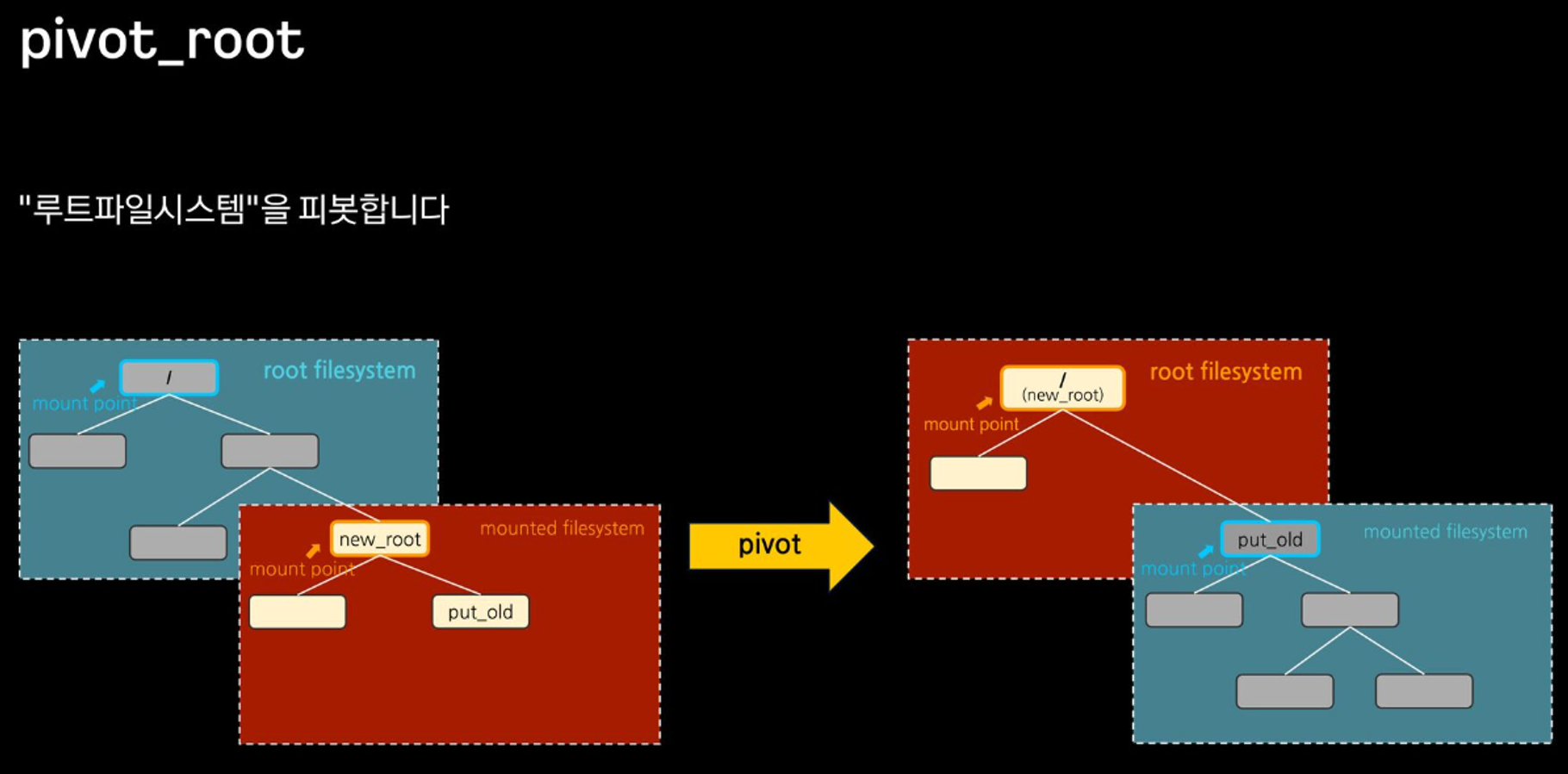
root filesystem을 pivot 했기 때문에 탈옥 불가능!
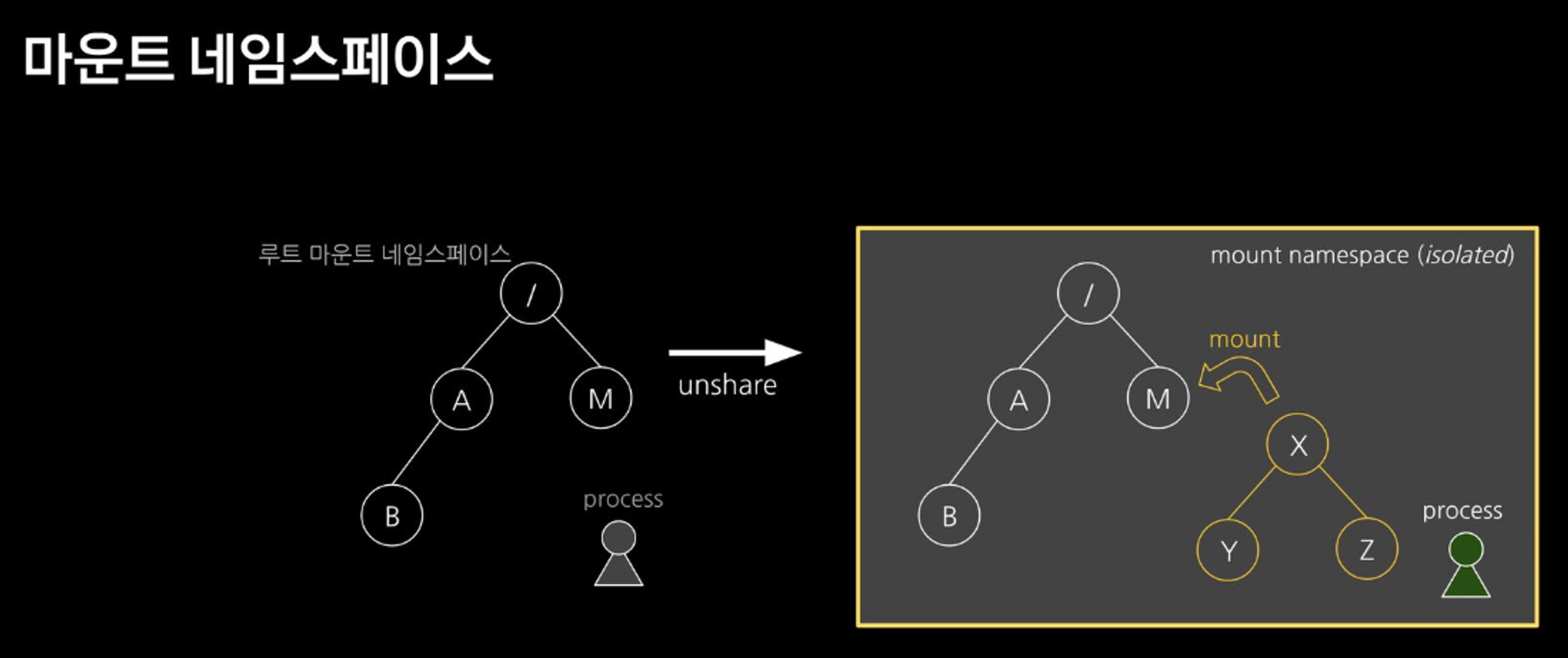
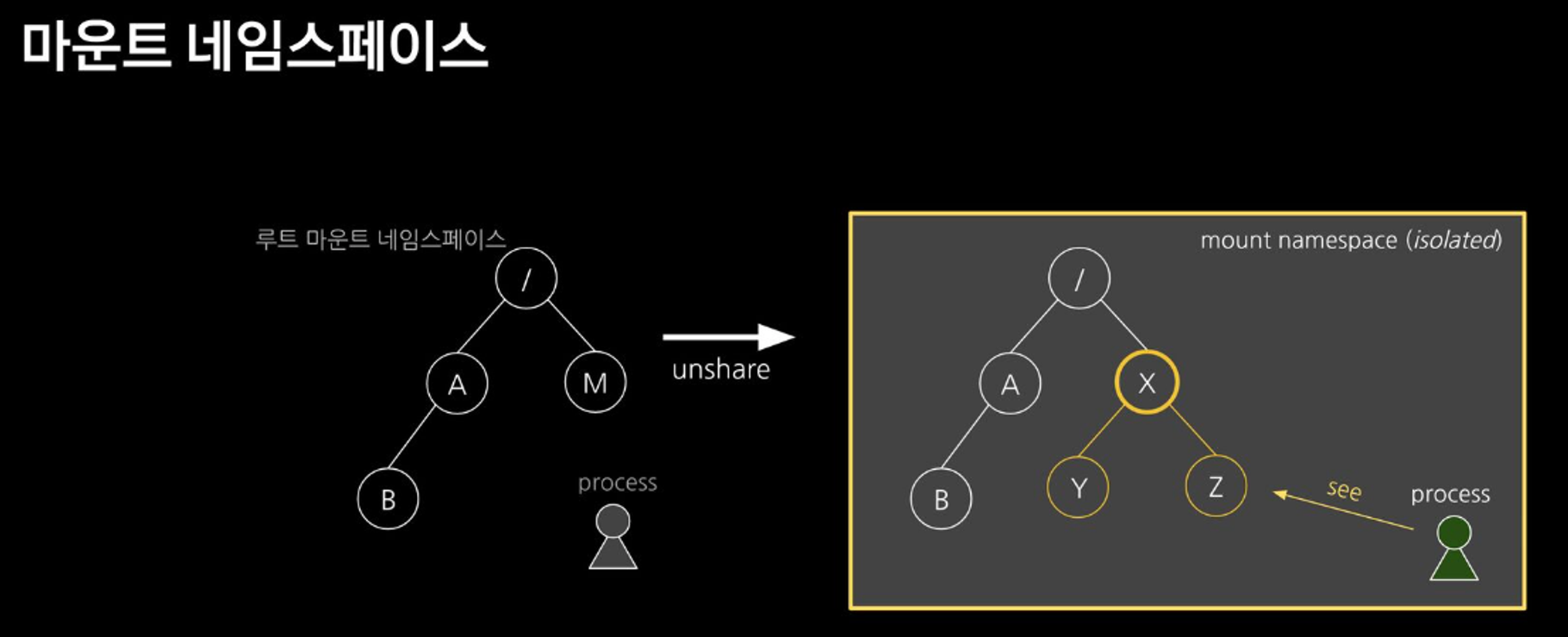
mount namespace를 사용해서 마치 컨테이너처럼 Host와 격리된 환경을 구성
pivot_rootmount: root filesystem tree에 다른 파일 시스템을 붙이는 명령어unshare: 새로운 네임스페이스를 만들고 프로그램을 실행
unshare --mount /bin/sh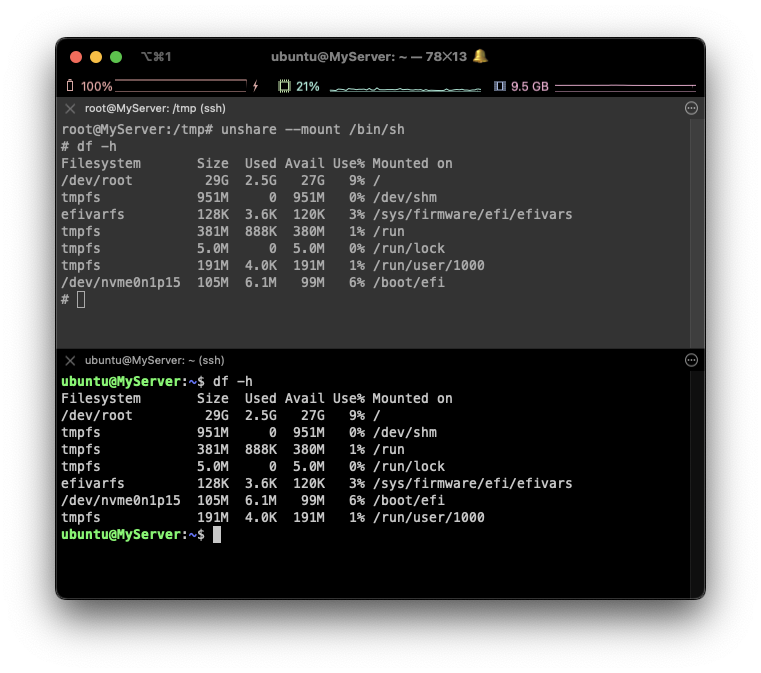
⇒ mount unshare 시 부모 프로세스의 마운트 정보를 복사해서 자식 네임스페이스를 생성하여 처음은 동일
mkdir new_root
mount -t tmpfs none new_root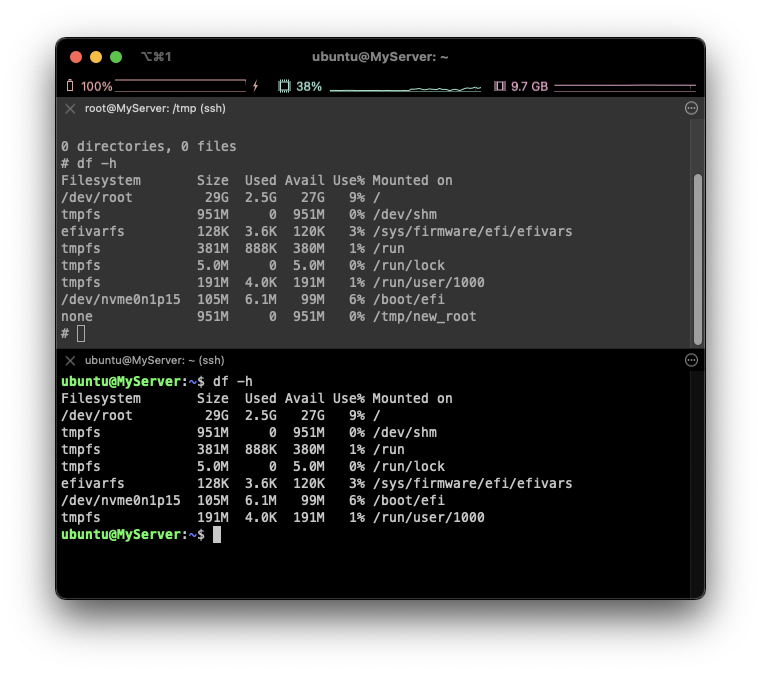
⇒ none Filesystem에 대해서 격리된 모습입니다
# chroot에 사용했던 myroot 파일을 복사!
cp -r myroot/* new_root/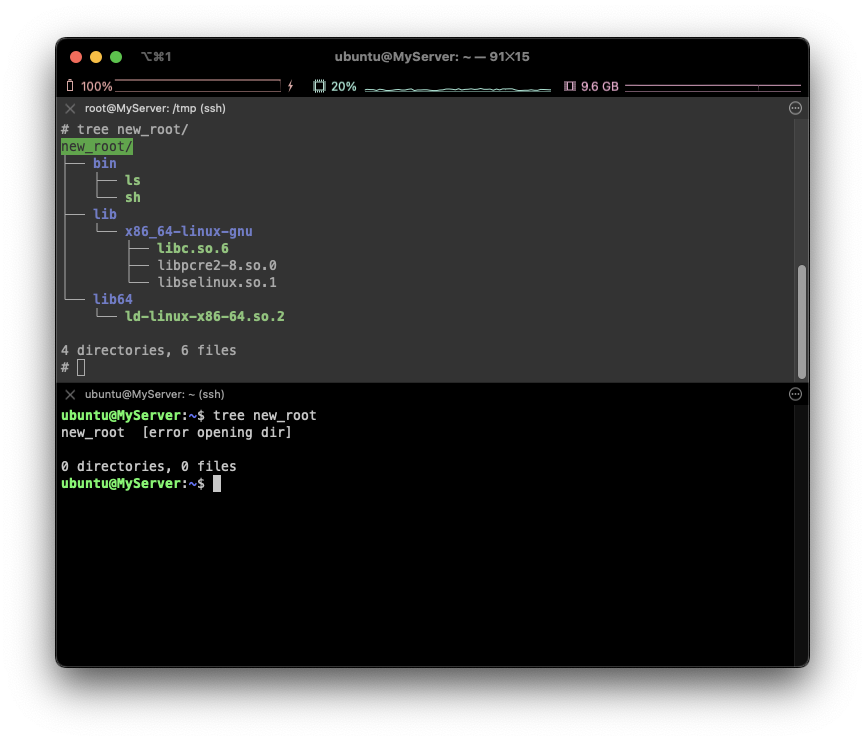
⇒ new_root가 완벽하게 격리된 것을 볼 수 있습니다!
mkdir new_root/put_old
## pivot_root 실행
cd new_root
**pivot_root . put_old** # [신규 루트] [기존 루트]⇒ 탈옥이 불가능한 root로 변경 완료!
격리 Namespace
아직 무슨 문제가 있을까요?
- 컨테이너에서 호스트의 다른 프로세스들이 보인다!
- 컨테이너에서 호스트의 포트를 사용한다.
- 컨테이너에 루트 권한이 존재한다.
프로세스에 격리된 환경을 제공하는 Namespace에 대해서 알아봅시다!
unshare [options] [<program> [<argument>...]]
Options:
-m, --mount[=<file>] unshare mounts namespace
-u, --uts[=<file>] unshare UTS namespace (hostname etc)
-i, --ipc[=<file>] unshare System V IPC namespace
-n, --net[=<file>] unshare network namespace
-p, --pid[=<file>] unshare pid namespace
-U, --user[=<file>] unshare user namespace
-C, --cgroup[=<file>] unshare cgroup namespace
-T, --time[=<file>] unshare time namespace- 네임스페이스와 관련된 프로세스의 특징
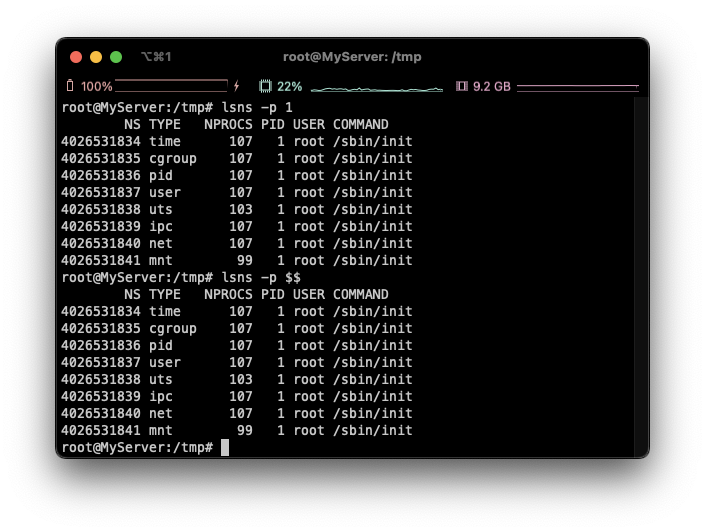
1. 모든 프로세스들은 타입별로 특정 네임스페이스에 속합니다.
2. Child는 Parent의 네임스페이스를 상속합니다.
-
MOUNT : 마운트 포인트 격리
-
UTS : Unix Time Sharing, 호스트명, 도메인명 격리
-
IPC : Inter-Process Communication 격리, 프로세스 간 통신 자원 분리 관리
-
PID : Process ID 격리 (PID 컨테이너 내에서만 유효하게 해 프로세스 독립적 관리)
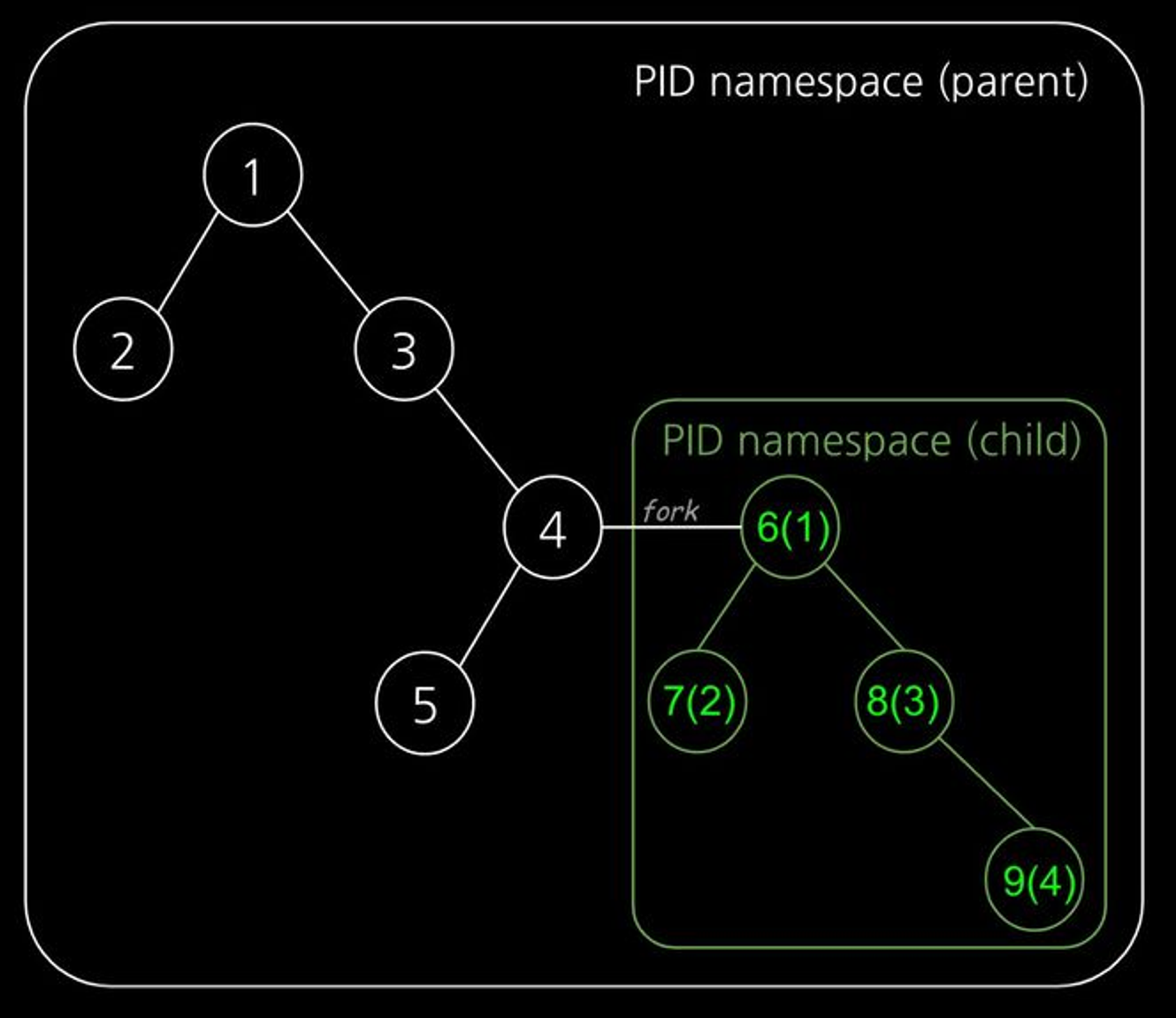
실행하고자 하는 프로세스를 fork를 통해 새로운 네임스페이스로 격리
- NET : 네트워크 스택을 분리하여 각 컨테이너가 고유한 네트워크 환경 구성
컨테이너 네트워크 & IPTables에서 자세히 설명
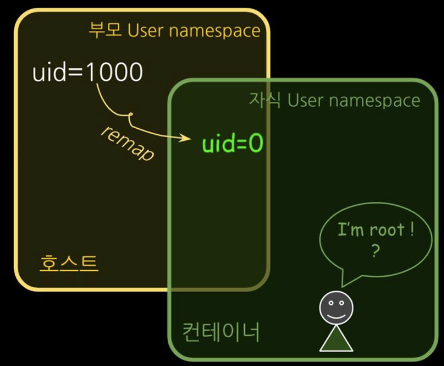
- USER : UID / GID 넘버스페이스 격리
컨테이너의 루트 권한 문제 해결, 부모-자식 네임스페이스의 중첩 구조
-
TIME : 프로세스가 볼 수 있는 시스템 시간 격리 (특정 프로세스에 다른 시간대 설정)
-
CGROUP : 자신이 속한 cgroup 및 하위의 cgroup에 대해서만 접근
자원 관리, cgroups
-
Control Groups : 프로세스들의 자원의 사용을 제한, 격리시키는 리눅스 커널 기능
-
컨테이너 별로 자원을 분배하고 limit 내 운용

-
cgroup v1 : request, limit 두개의 자원설정만이 가능
-
cgroup v2 : memoryQoS 기능 추가, 쉽사리 OOM 나지 않도록 기능 지원 ⇒ Memory High
-
cgroup의 interface는 cgroupfs이라 불리는 pseudo-filesystem을 통해 제공됨
-
cgroupfs의 subdirectory를 생성/삭제/변경하면서 정의됨
-
/proc 와 /sys
- Runtime의 메모리 정보를 파일시스템 폴더에 mount한 pseudo-filesystem
- 커널 2.x 버전까지는 /proc 폴더 하나만 있었지만, 3.x 버전 부터 /sys를 추가로 구분하였음
- /proc, /sys 는 커널이 관리하는 메모리를 마운트했기 때문에 해당 디렉토리에 접근하는 순간 메모리에서 정보를 읽어 오게 됨
-
자원 관리 예제
sudo su -
cd /sys/fs/cgroup
**mkdir test_cgroup_parent && cd test_cgroup_parent
# 자동으로 cgroup filesystem에 해당되는 파일들 생성되는 모습 확인**
**tree**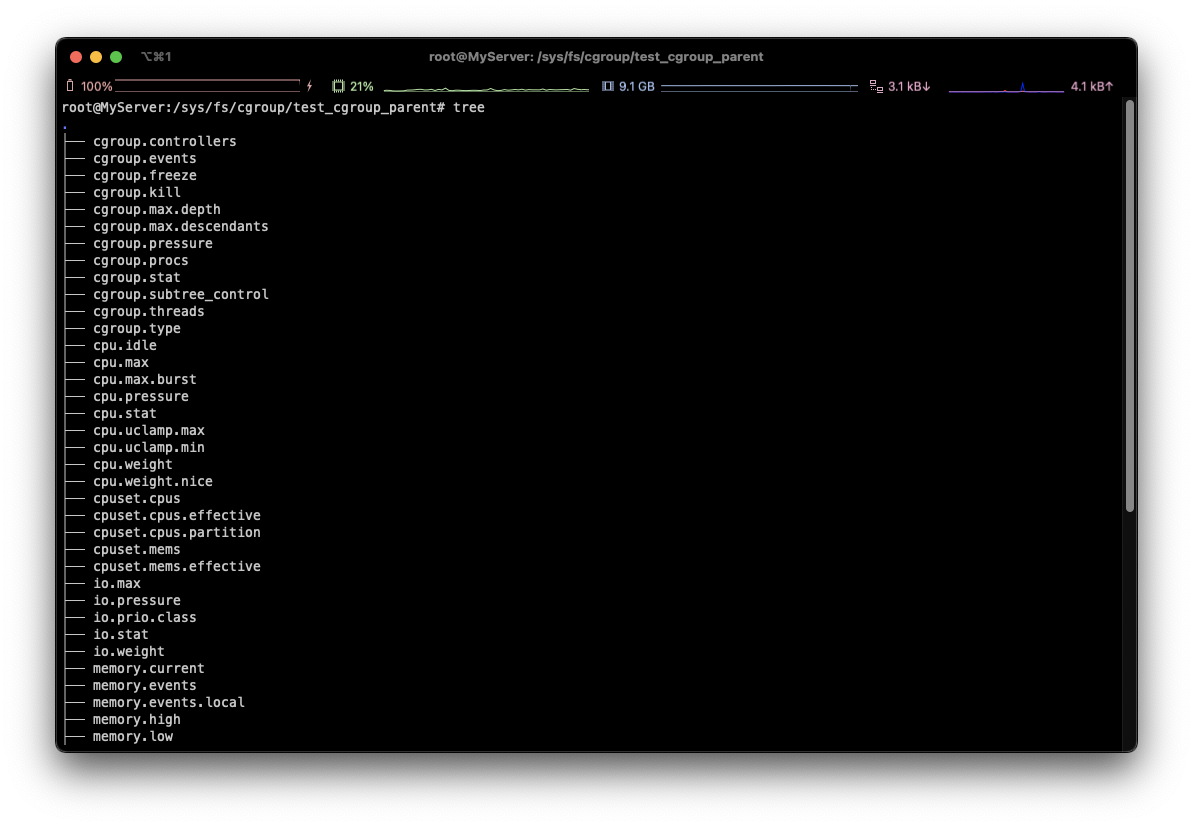
# 제어 가능 항목 확인
cat cgroup.controllers
# cpu를 subtree이 추가하여 컨트롤 할 수 있도록 설정 : +/-(추가/삭제)
echo "+cpu" >> /sys/fs/cgroup/test_cgroup_parent/cgroup.subtree_control
# cpu.max 제한 설정
echo 100000 1000000 > /sys/fs/cgroup/test_cgroup_parent/cpu.max
# test용 자식 디렉토리를 생성하고, pid를 추가하여 제한
mkdir test_cgroup_child && cd test_cgroup_child
echo $$ > /sys/fs/cgroup/test_cgroup_parent/test_cgroup_child/cgroup.procs
cat /sys/fs/cgroup/test_cgroup_parent/test_cgroup_child/cgroup.procs
cat /proc/$$/cgroup
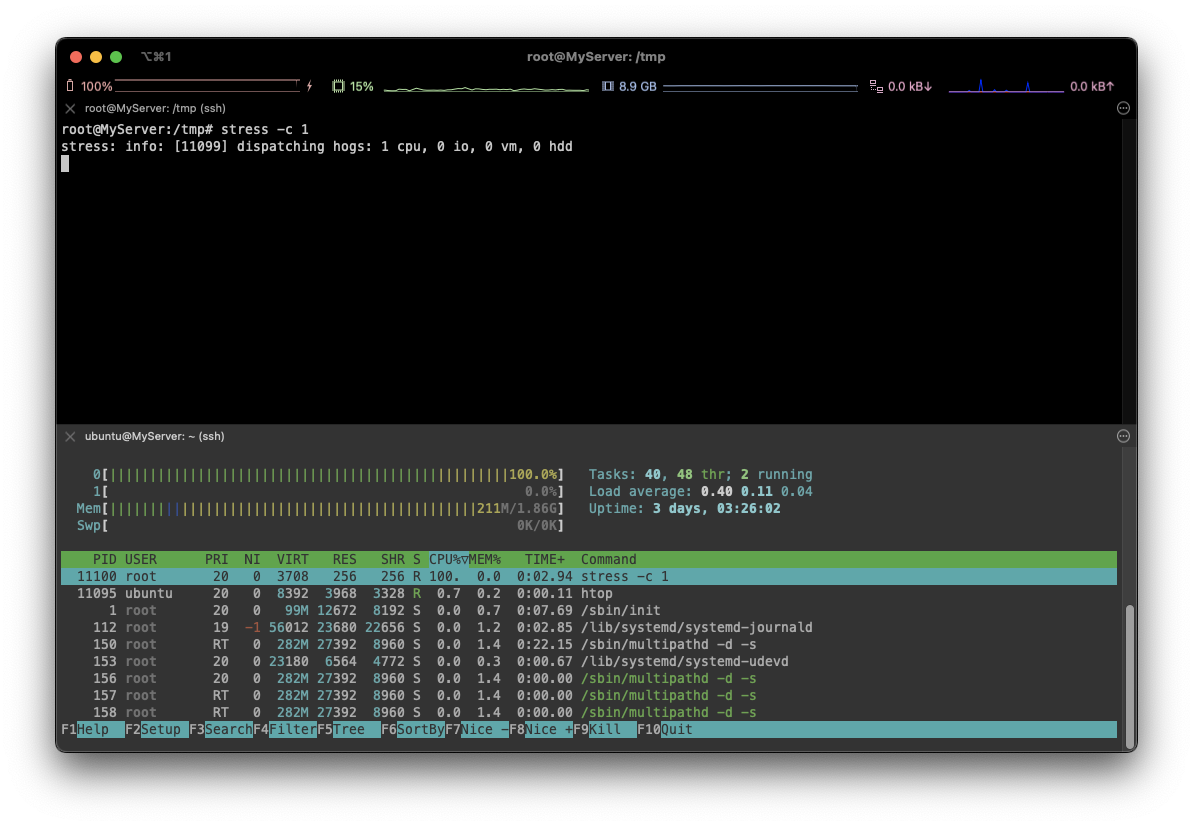
stress -c 1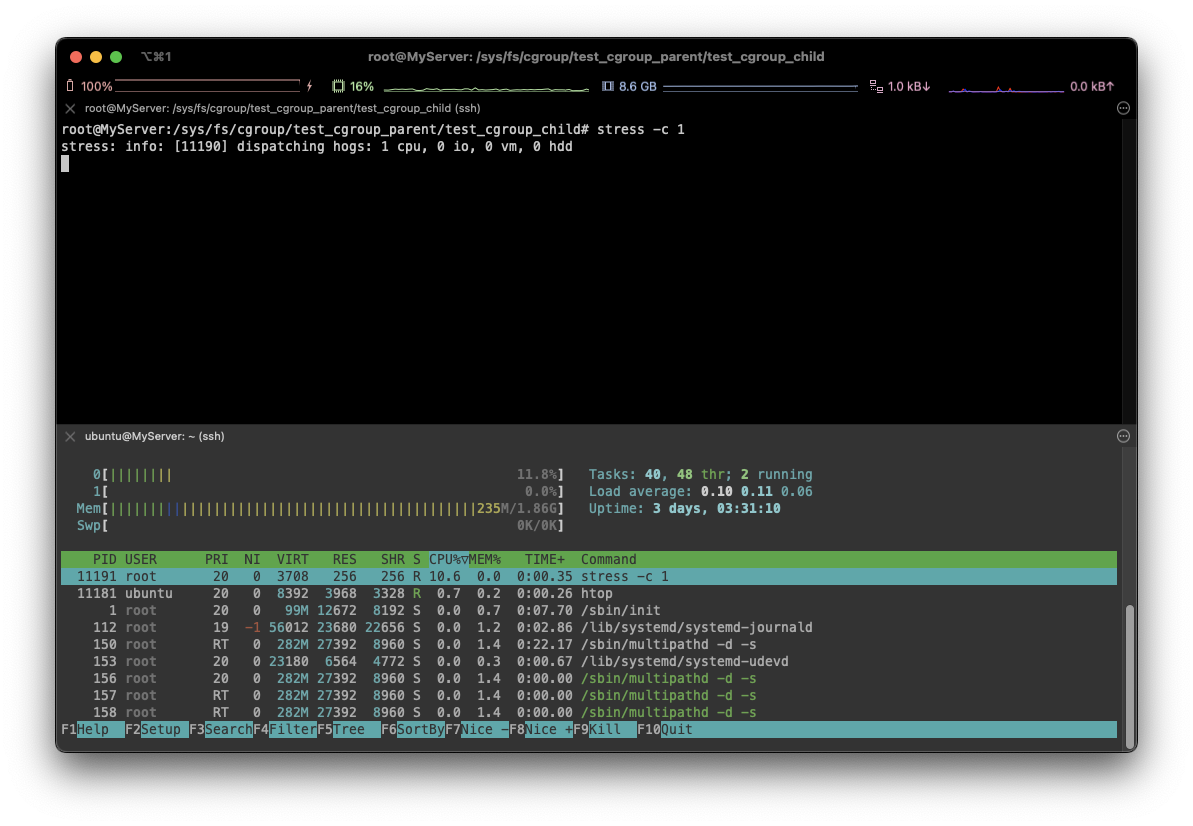
⇒ 처음과 다르게 10% 정도에 해당하는 cpu 부하를 볼 수 있습니다.
컨테이너 네트워크 & IPTables
sudo su -
# veth (가상 이더넷 디바이스) 생성, veth0 와 veth1 peer로 묶는다
ip link add **veth0** type **veth** **peer** name **veth1**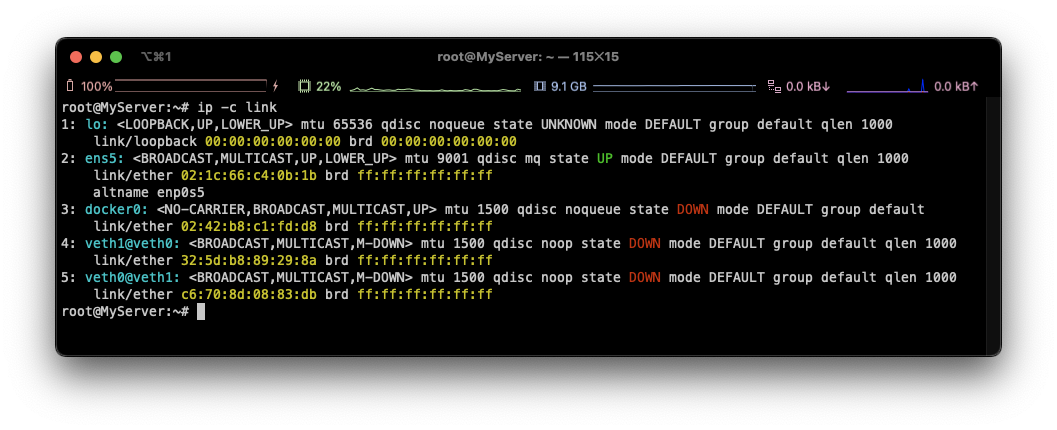
**ip netns add RED
ip netns add BLUE
# veth0 를 RED 네트워크 인터페이스로 설정
ip link set veth0 netns RED**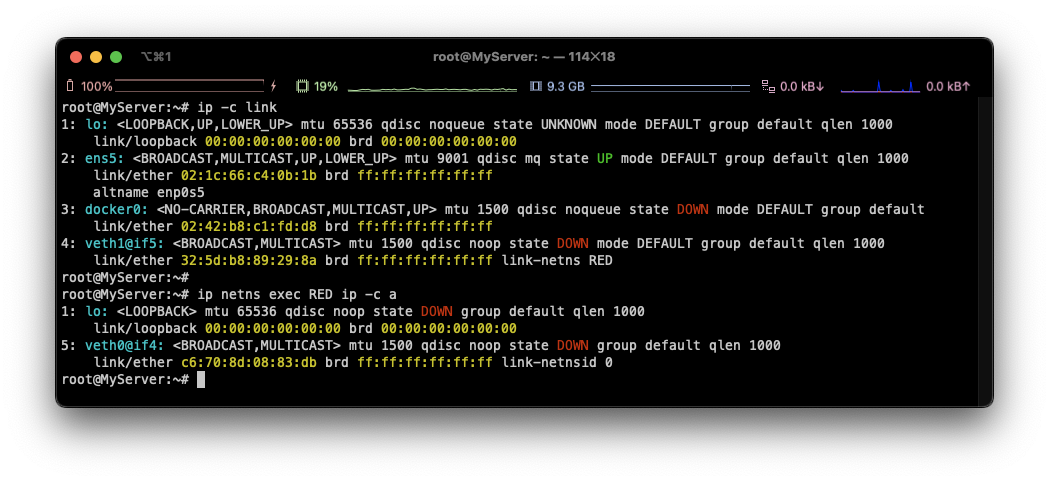
⇒ 4: veth1@if5 와 같이 목록 바뀜, RED로 가서 확인하면 Peer 정보 확인 가능
**ip link set veth1 netns BLUE**
# veth0, veth1 상태 활성화(state UP)
ip netns exec RED ip link set veth0 up
ip netns exec BLUE ip link set veth1 up
# veth0, veth1 에 IP 설정
ip netns exec RED ip addr add 11.11.11.2/24 dev veth0
ip netns exec BLUE ip addr add 11.11.11.3/24 dev veth1nsenter: 네임스페이스에 attach 하여 지정한 프로그램을 실행
**# terminal 1
nsenter --net=/var/run/netns/RED
# terminal 2
nsenter --net=/var/run/netns/BLUE
# 정보 확인**
ip -c a
## neighbour/arp tables management , man ip-neighbour
ip -c neigh
## 라우팅 정보, iptables 정보
ip -c route
iptables -t filter -S
iptables -t nat -S
# terminal 2
tcpdump -i veth1
# terminal 1 (RED)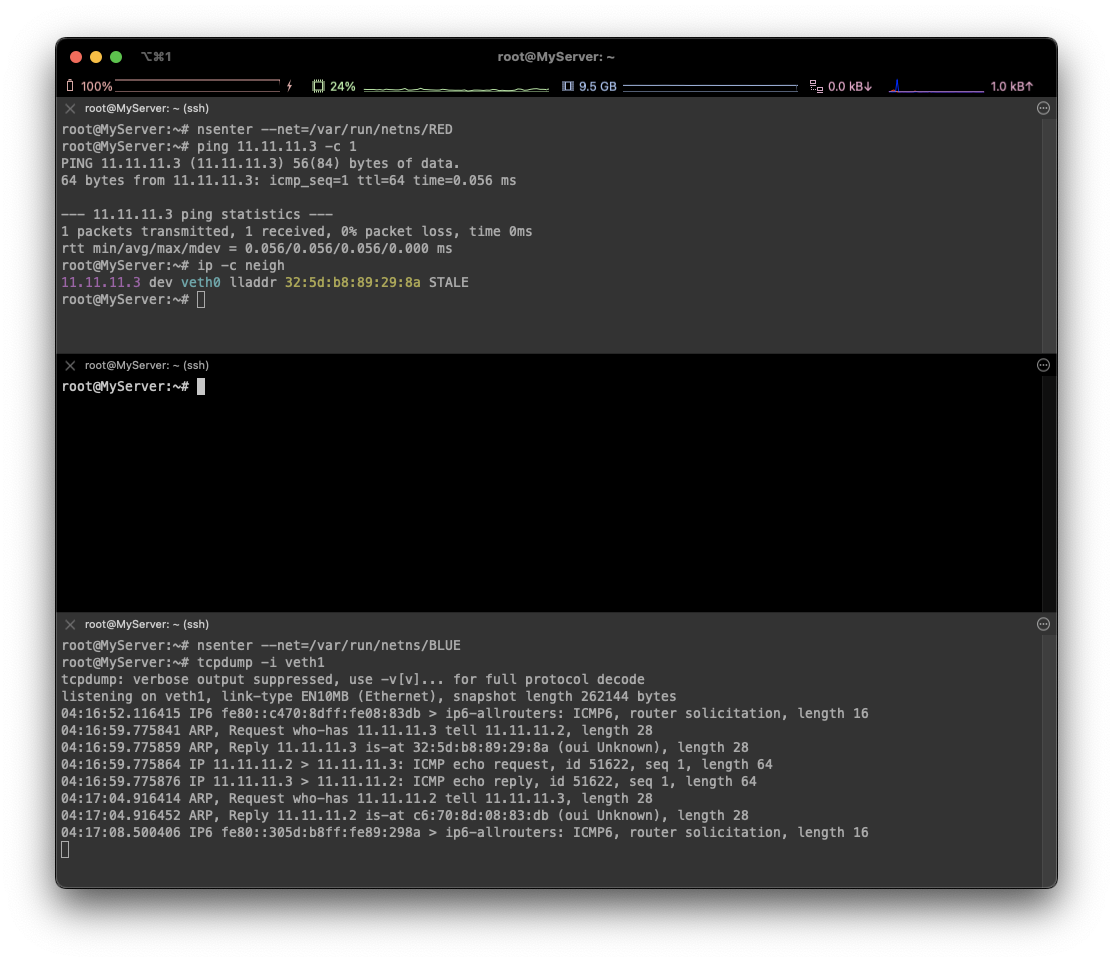
⇒ ARP를 통해 MAC 정보를 가져온 것 확인 가능!
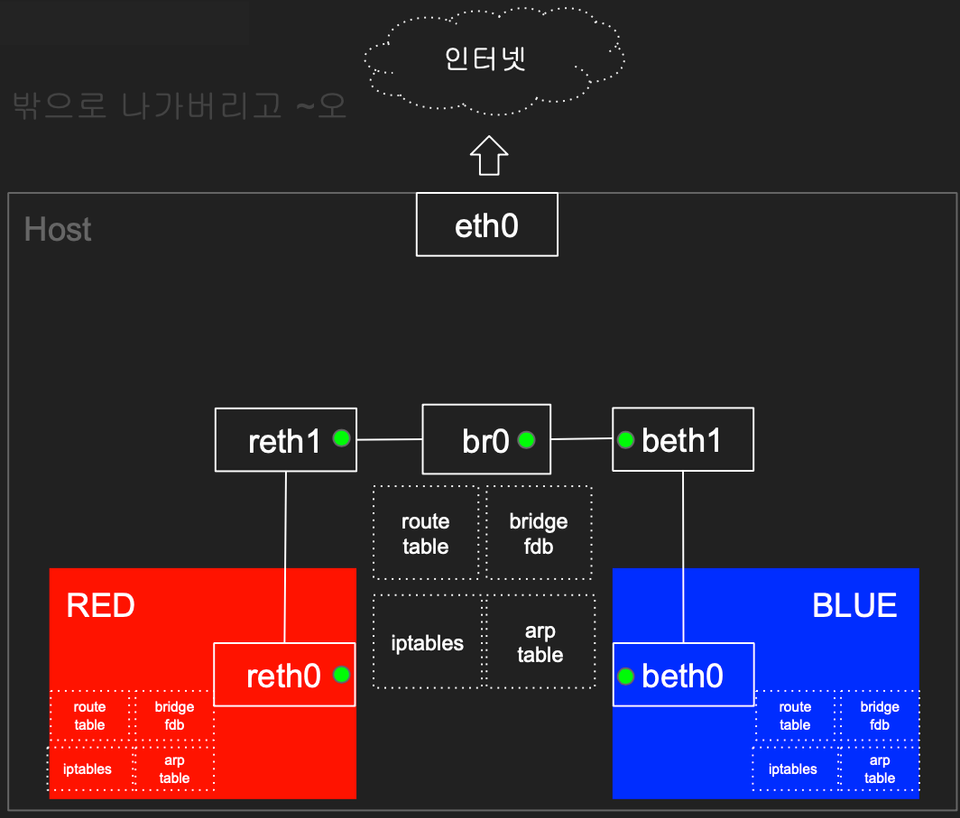
- Bridge : 논리적 스위치를 위치 (peer to peer로 하면 너무 많아지므로)
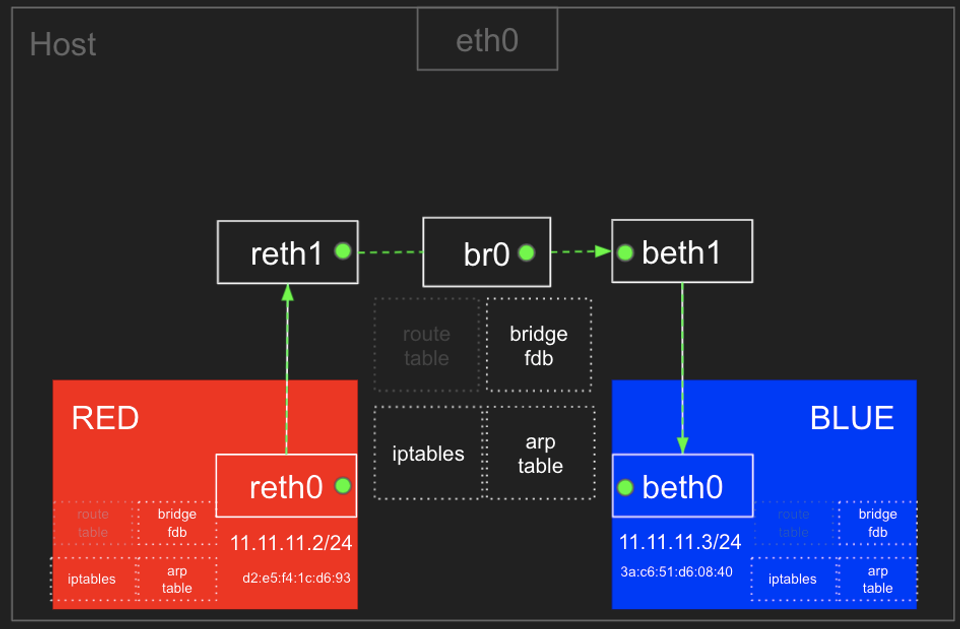
ip netns add RED
ip link add reth0 type veth peer name reth1
ip link set reth0 netns RED
ip netns add BLUE
ip link add beth0 type veth peer name beth1
ip link set beth0 netns BLUE
# 브릿지 정보 확인
brctl show
# br0 브리지 생성
ip link add br0 type bridge
# br0 브리지 정보 확인
brctl show br0
brctl showmacs br0
brctl showstp br0
# reth1 beth1 을 br0 연결
ip link set reth1 master br0
ip link set beth1 master br0
ip -br -c link
# reth0 beth0 에 IP 설정 및 활성화, br0 활성화
ip netns exec RED ip addr add 11.11.11.2/24 dev reth0
ip netns exec BLUE ip addr add 11.11.11.3/24 dev beth0
ip netns exec RED ip link set reth0 up; ip link set reth1 up
ip netns exec BLUE ip link set beth0 up; ip link set beth1 up
ip link set br0 up
ip -br -c addr# 터미널1 (RED 11.11.11.2)
**nsenter --net=/var/run/netns/RED**
# 터미널2 (호스트)
brctl showmacs br0
bridge fdb show
bridge fdb show dev br0
iptables -t filter -S
iptables -t filter -L -n -v
# 터미널3 (BLUE 11.11.11.3)
**nsenter --net=/var/run/netns/BLUE**ip -c a;echo; ip -c route;echo; ip -c neigh
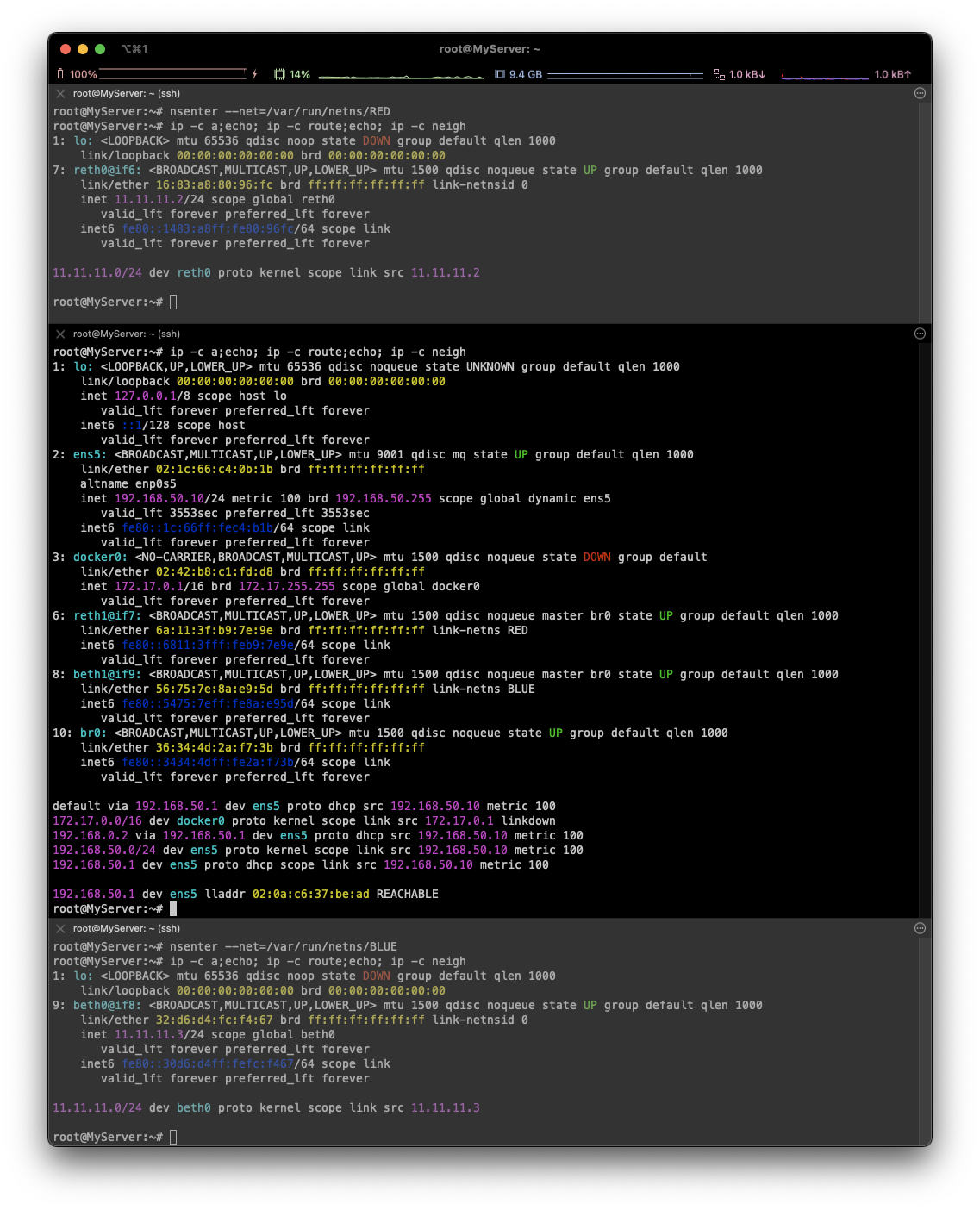
**#**# iptables 정보 확인
iptables -t filter -S | grep '\-P'
-P INPUT ACCEPT
-P FORWARD DROP
-P OUTPUT ACCEPT
## RED - BLUE 통신하려면 HOST의 ROUTE 필요!
## Ubuntu 호스트에서 패킷 라우팅 설정 확인 : 커널의 IP Forwarding (routing) 기능 확인 - 0(off), 1(on)
## echo 1 > /proc/sys/net/ipv4/ip_forward
cat /proc/sys/net/ipv4/ip_forward
# 터미널3 (BLUE 11.11.11.3)
tcpdump -l -i beth0
# 터미널1 (실패!)
ping -c 1 11.11.11.3
# 터미널2 (호스트)
# FORWARD 정책에 의해서 DROP
tcpdump -l -i br0
watch -d 'iptables -v --numeric --table filter --list FORWARD'
watch -d 'iptables -v --numeric --table filter --list FORWARD;echo;iptables -v --numeric --table filter --list DOCKER-USER;echo;iptables -v --numeric --table filter --list DOCKER-ISOLATION-STAGE-1'- IPtables : Basic firewall software
- 네트워크 스택에서 hook을 통해 packet을 필터링
- Netfilter : 네트워크 연산을 핸들러 형태로 처리하는 hook을 제공하는 커널 모듈로 네트워크 패킷을 처리하는 프레임워크
5 hooks : INPUT, OUTPUT, PREROUTING, FORWARD, POSTROUTING
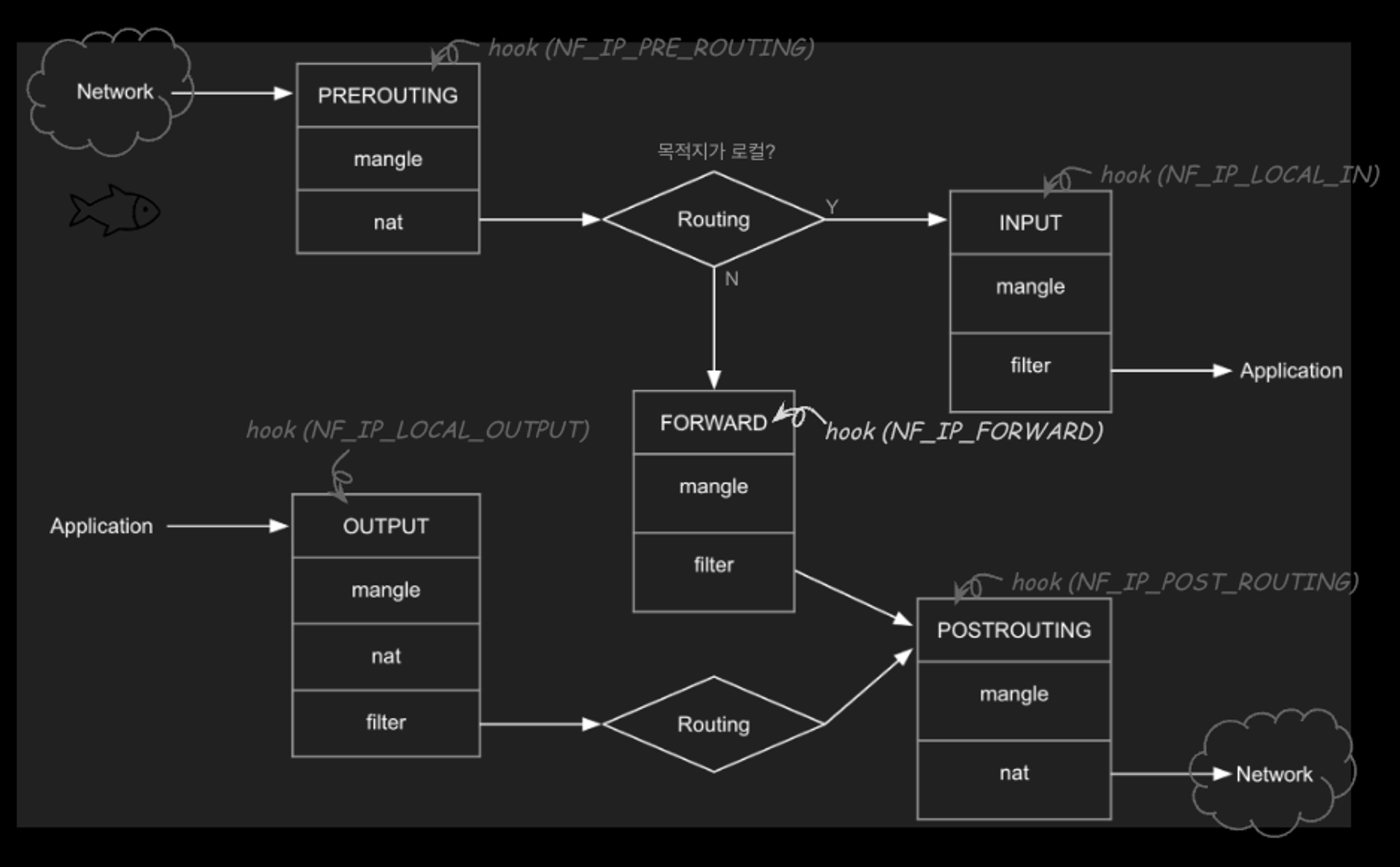
Chain
- INPUT - mangle, filter
- OUTPUT - mangle, nat, filter
- FORWARD - mangle , filter
- PREROUTING - mangle, nat
- POSTROUTING - mangle, nat
Table
- Filter : 필터링. 패킷 전송 여부
- NAT : Network Address Translation. src/dst. 주소의 수정/방법 여부 결정
- Mangle : 헤더 변조 (TTL조정, 홉 수 조정). 추가 처리를 위한 커널 마킹 (Istio)
- Raw : connection tracking을 위한 패킷마킹 메커니즘 제공
- Security : 패킷에 SELinux(보안) context 마킹
Chain Rules
- matching : 조건에 맞으면
- targets(action) : 무슨 행동을 취할 것인지
Connection Tracking 과 State
NAT 기능이 있어서 Connection 정보를 기억해야한다. (⇒ Stateful)
- Stateful Operations : ~ Check packets and Update states , ~ Add a new connection
- States : NEW, ESTABLISHED, RELATED, INVALID, UNTRACKED, SNAT, DNAT
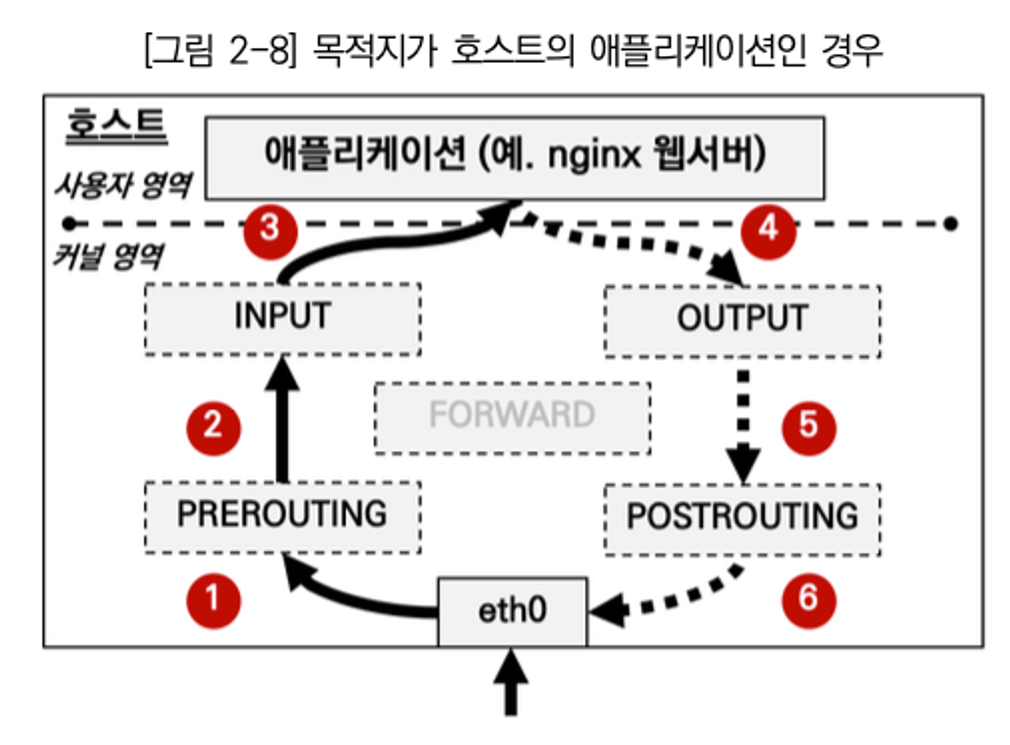
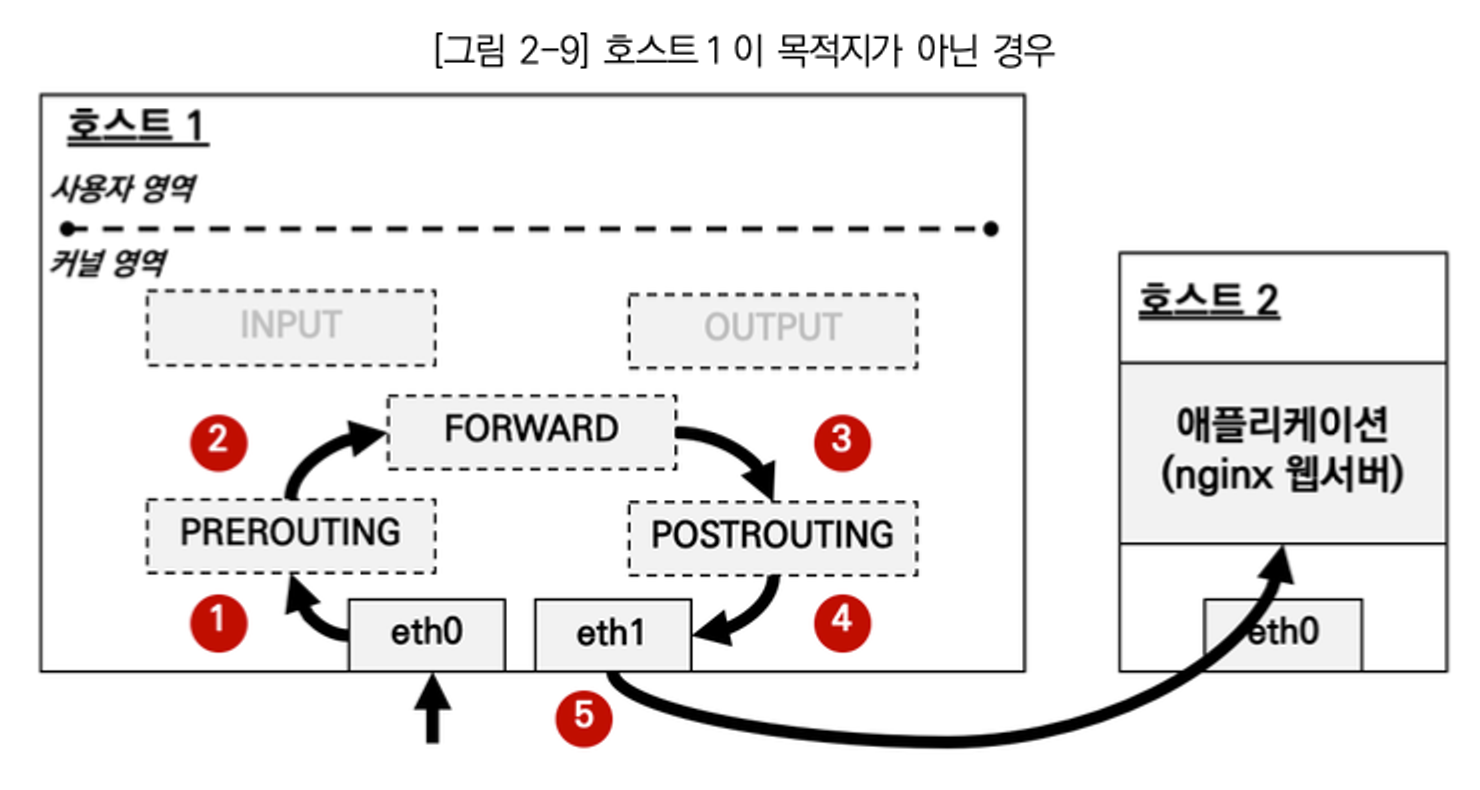
그래서 왜 안 됐을까?!
HOST 입장에서 외부(RED, src) → 외부(BLUE, dst) 패킷이므로 FORWARD 체인의 filter 테이블 룰 확인!!
iptables -t filter -S
iptables -t nat -S | grep '\-P'
# iptables 설정 추가 -t(table), -I(insert chain), -j(jump to - ACCEPT 허용)
**iptables -t filter -I DOCKER-USER -j ACCEPT**
# ping 통신 테스트 => 성공!
# 터미널1 (RED 11.11.11.2)
ping -c 1 11.11.11.3
# 터미널2 (호스트)
watch -d 'iptables -v --numeric --table filter --list FORWARD;echo;iptables -v --numeric --table filter --list DOCKER-USER;echo;iptables -v --numeric --table filter --list DOCKER-ISOLATION-STAGE-1'
tcpdump -l -i br0
## 정보 확인
ip -c neigh
# 터미널3 (BLUE 11.11.11.3)
tcpdump -l -i beth0iptables -t nat -S | grep -P
iptables -t filter -I DOCKER-USER -j ACCEPT
- RED/BLUE → HOST & 외부 통신
# 터미널2 (호스트) >> 호스트에서 RED 로 통신이 안되는 이유가 무엇일까요?
ping -c 1 11.11.11.2
ip -c route
ip -c addr
# br0 에 IP가 없기 때문
# 터미널2 (호스트) >> br0 에 IP 추가(라우팅 정보)
ip addr add 11.11.11.1/24 dev br0
ip -c addr
# 2: ens5: 192.168.50.10 실패.
# 터미널1 (RED)
ping -c 1 192.168.50.10
# => Default Routing 정보가 없으므로 실패
# 터미널2 (호스트)
## POSTROUTING : 라우팅 Outbound or 포워딩 트래픽에 의해 트리거되는 netfilter hook
## POSTROUTING 에서는 SNAT(Source NAT) 설정
iptables -t nat -A POSTROUTING -s 11.11.11.0/24 -j MASQUERADE
# 터미널 2(RED) - Default Routing 추가!
ip route add default via 11.11.11.1NAT 테이블 정보 필요, Stateful 정보
conntrack -L --src-nat
도커 네트워크 모드
Bridge, Host, None + @(macvlan, ipvlan, overlay)
docker network ls
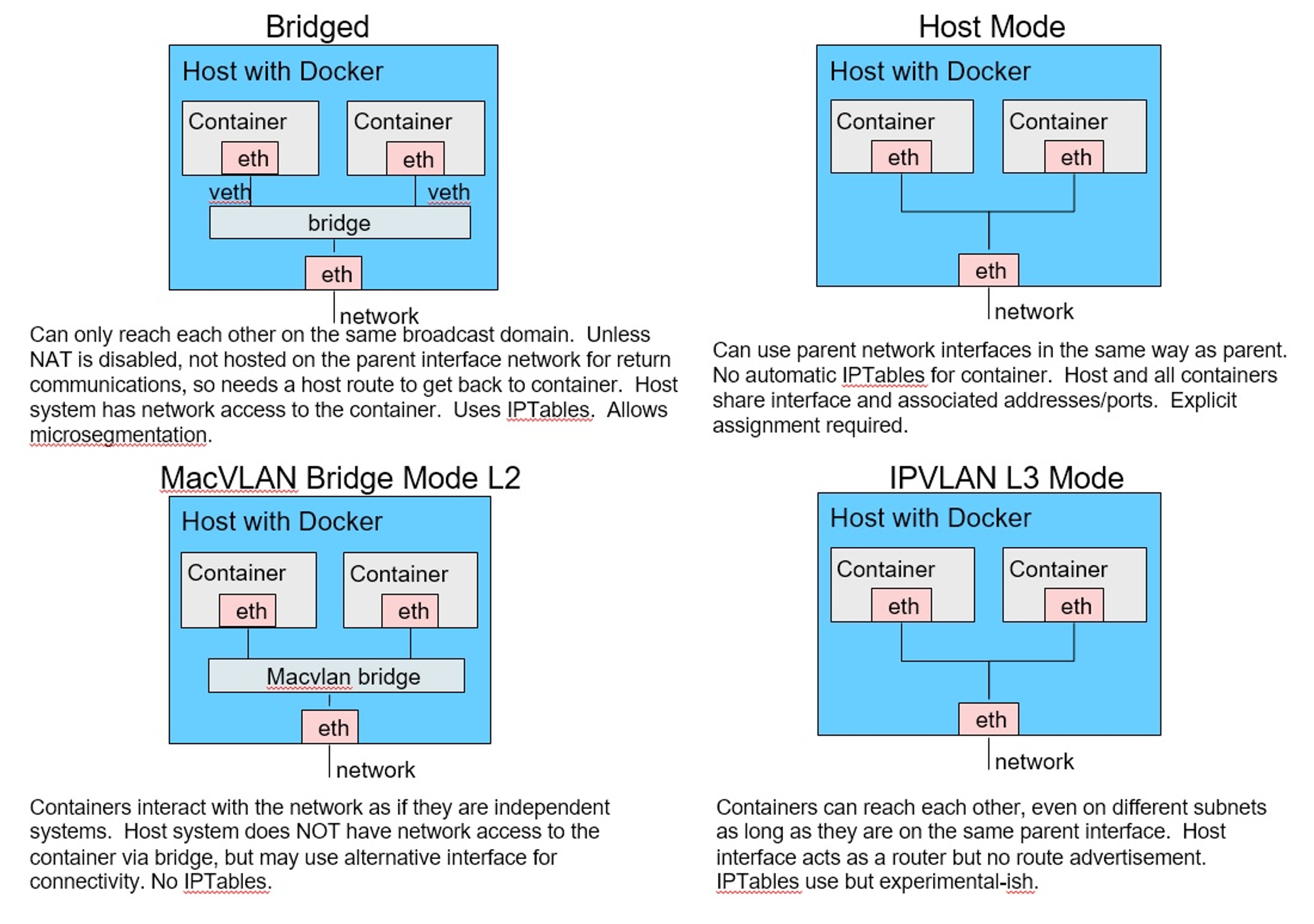
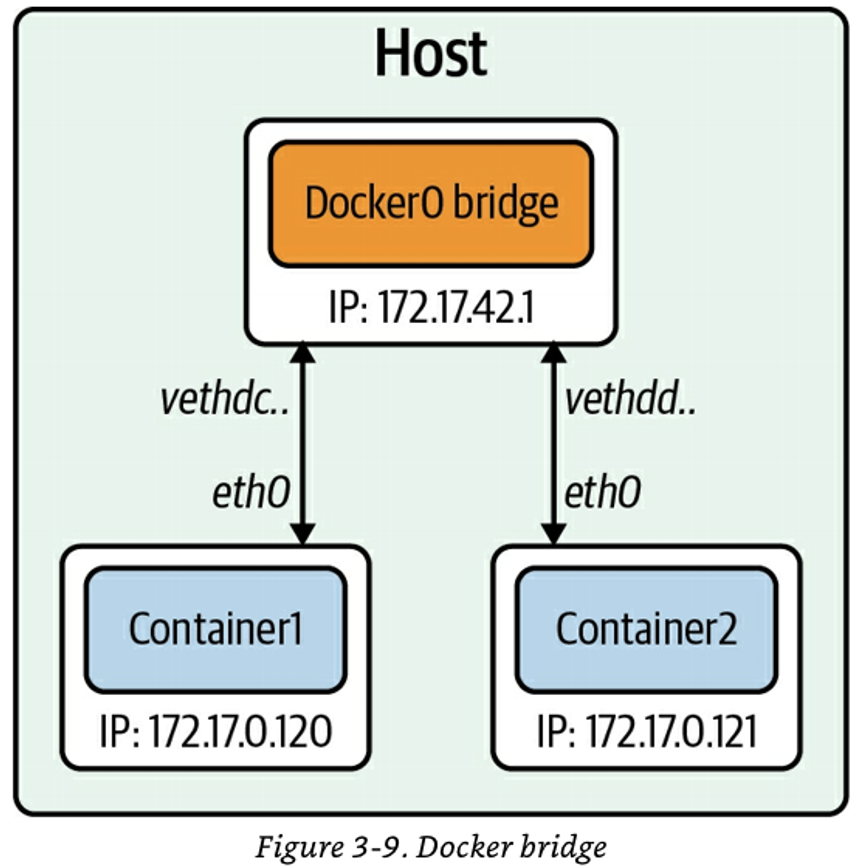
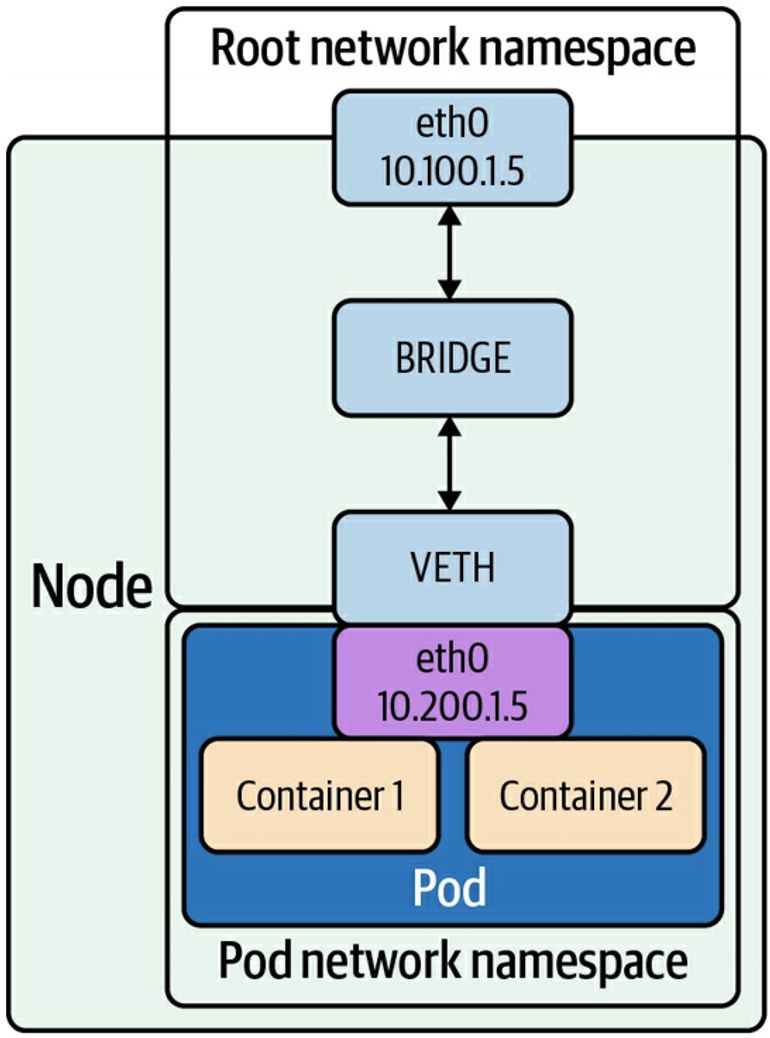
출처) O'REILLY - Networking and Kubernetes 책
후기
백엔드나 데이터 플랫폼 쪽을 개발하여, helm 차트만 만져보던 저에게는 정말 매운맛을 본 것 같습니다.
무지했던 부분들에 대해서 지식을 채워주셔서 CloudNet@ 팀에 감사드립니다 :)
덕에 많은 걸 알게 되고 알면 알 수록, 학부 시절에 CS를 열심히 했어야 했다는 사실을 이제서야 깨닫게 되는 것 같습니다..
