DISTINCT (중복 제거하기)
DISTINCT 란?
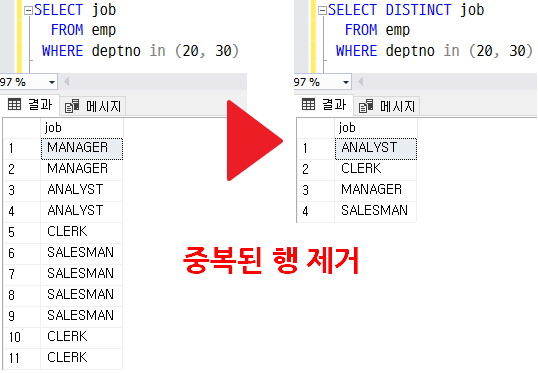
중복된 값을 갖고있는 행을 제거하고 한 번만 표시해준다.
사용방법
SELECT DISTINCT [컬럼명] FROM [테이블명]
해당 컬럼을 기준으로 같은 값을 갖고있는 행이 제거되고 하나만 남긴다.
(참고링크)
'GROUP BY' 절을 사용해서 중복을 제거할수도 있다.
'GROUP BY [컬럼명]' 으로 중복되는 값을 그룹화 할 수 있다.
하지만 COUNT 를 사용할때는 실제 중복 값이 제거되어 출력된게 아니기 때문에 애매해진다.
이때는 FROM 을 2중으로 세팅해준다.
(예시)
SELECT COUNT(A.[컬럼명])
FROM (SELECT [컬럼명]
FROM [테이블명]
GROUP BY [컬럼명]) AS A이러면 그룹으로 묶여 중복을 제외하게 된 컬럼명만 카운트하게 된다.

아무거나 공부한거 올리기