데이터 분석 실무를 하다보면 날짜 배열을 만들어야 할 때가 있다.
이 글에서는 날짜 배열 만드는 법을 설명하면서 빅쿼리의 중첩 필드가 무엇인지 설명하고 이를 풀어내는 UNNEST와 CROSS JOIN 기법에 대해서도 알아본다. 다른 작업에서 중첩 필드를 다룰 때 참고가 될 것이다.
기본적인 SQL 문법을 알고 있다고 생각하고 설명하겠다.
중첩 필드
날짜 배열 생성 함수를 설명하기에 앞서 함수의 출력값인 중첩 필드에 대해 이야기 하고 넘어가려 한다.
빅쿼리의 중첩 필드는 Array와 Struct로 구분된다. Array는 데이터 유형이 동일한 값으로 구성된 말 그대로 배열이다. Struct는 파이썬의 Dictionary와 유사하며 (키, 값) 쌍을 갖는다.
중첩 구조는 RDB에서는 볼 수 없었던 비정형 구조다. Array나 Struct와 같은 구조가 필요하면 정규화해서 여러개의 테이블로 분산해서 관리한다. 하지만 빅쿼리와 같은 DW의 경우는 중복 데이터를 일부 허용하더라도JOIN을 줄여 집계 연산 효율을 높이는 쪽에 초첨이 맞춰져 있다.
구글에서는 쿼리 최적화를 위해 중첩 필드를 사용하는 것을 권장하고 있다. 관련 문서를 참고하자!
정리하면,
- 중첩 필드는 Array, Struct 두 종류로 구분
- Array: 파이썬의 list와 유사한 배열
- Struct: 파이썬의 Dictionary와 유사한 (키, 값) 쌍 자료구조
이 정도만 알아도 쿼리를 작성하는데는 무리가 없다. 이제 날짜 배열을 만들어보자.
날짜 배열 생성 함수
GENERATE_DATE_DATEARAY 함수
빅쿼리에는 GENERATE_DATE_ARRAY라는 날짜 배열 생성 함수가 있다. 함수 이름과 같이 ARRAY를 반환한다.
GENERATE_DATE_ARRAY(start_date, end_date[, INTERVAL INT64_expr date_part])
start_date: 시작 날짜.DATE포맷이어야 함end_date: 종료 날짜.DATE포맷이어야 함INTERVAL INT64_expr date_part:INT64_expr는 간격,date_part는DAY,WEEK,MONTH,QUARTER,YEAR중 하나. 예를 들면INTERVAL 30 DAY와 같이 사용한다. 입력하지 않으면 기본값은INTERVAL 1 DAY.
사용 예시
SELECT
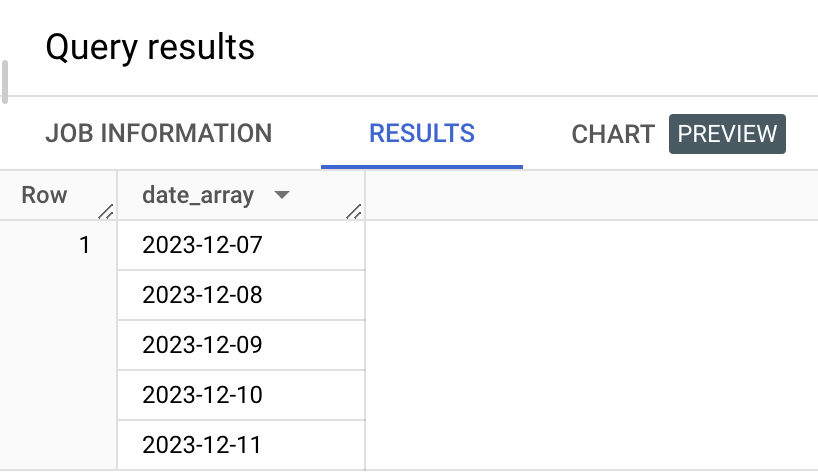
GENERATE_DATE_ARRAY('2023-12-07', '2023-12-11') AS date_array이 쿼리는 2023년 12월 7일 부터 12월 11일까지 날짜들을 1일 간격으로 생성한다. 세번째 파라미터를 넣지 않았기 때문에 기본값인 INTERVAL 1 DAY가 적용된 상태임에 유의하자.
유연하게 사용하기
위 예시에서는 시작 날짜와 종료 날짜를 '하드코딩' 했다. 몇 가지 함수를 조합하면 더 유연하게 사용할 수 있다. 포스팅을 최초 작성한 2023년 12월 7일 현재 CURRENT_DATE, DATE_ADD를 조합해 같은 결과를 출력하는 예시 코드를 작성해봤다.
SELECT
GENERATE_DATE_ARRAY(CURRENT_DATE(), DATE_ADD(CURRENT_DATE(), INTERVAL 4 DAY)) AS date_array2023년 12월 7일 현재 위에서 사용된 각 함수는 아래와 같이 맵핑된다.
CURRENT_DATE(): '2023-12-07'DATE_ADD(CURRENT_DATE(), INTERVAL 4 DAY)): '2023-12-11'
INTERVAL 4 DAY는 종료 날짜를 계산하기 위해 사용한 DATE_ADD 함수의 파라미터라는 점에 유의하자.
이미지를 자세히 보자. 이 배열이 'Row 1'에 묶여 있는 것을 볼 수 있다. Array로 묶여 하나의 레코드로 취급되고 있는 것이다. 중첩구조를 풀어 배열값들을 하나하나 레코드로 풀어내보자.
중첩 구조 풀기
중첩 구조를 푸는데 사용할 수 있는 방법은 두가지가 있다.
UNNEST함수 사용CROSS JOIN활용
UNNEST
이름 그대로 중첩(nested) 구조를 풀어내는 함수다.
SELECT *
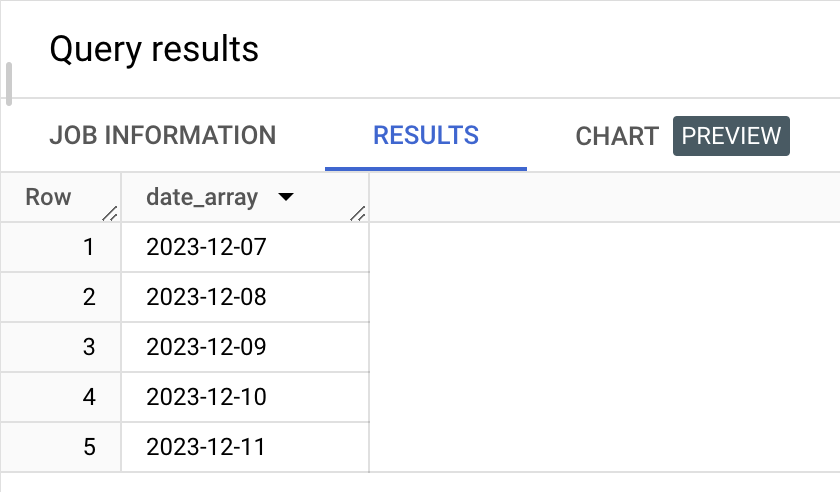
FROM UNNEST(GENERATE_DATE_ARRAY(CURRENT_DATE(), DATE_ADD(CURRENT_DATE(), INTERVAL 4 DAY))) AS date_array아래와 같은 결과를 반환한다. 각각 하나의 행으로 구분 된 것을 볼 수 있다.
여러개의 배열 한번에 풀기
여러개 필드 중 하나가 Array 인 경우엔 다른 방법을 사용해야 한다. 가령 달 명칭에 Array가 하나씩 묶여 있는 날짜 관련 테이블이 있다고 생각해보자.
WITH Sequences AS
(
SELECT 'DEC' AS month, GENERATE_DATE_ARRAY('2023-12-01', DATE_ADD('2023-12-01', INTERVAL 10 DAY)) AS date_array
UNION ALL SELECT 'JAN' AS month, GENERATE_DATE_ARRAY('2024-01-01', DATE_ADD('2024-01-01', INTERVAL 5 DAY)) AS date_array
UNION ALL SELECT 'FEB' AS month, GENERATE_DATE_ARRAY('2024-02-11', DATE_ADD('2024-02-11', INTERVAL 3 DAY)) AS date_array
)
SELECT *
FROM Sequences위 쿼리는 아래와 같은 결과를 반환한다.
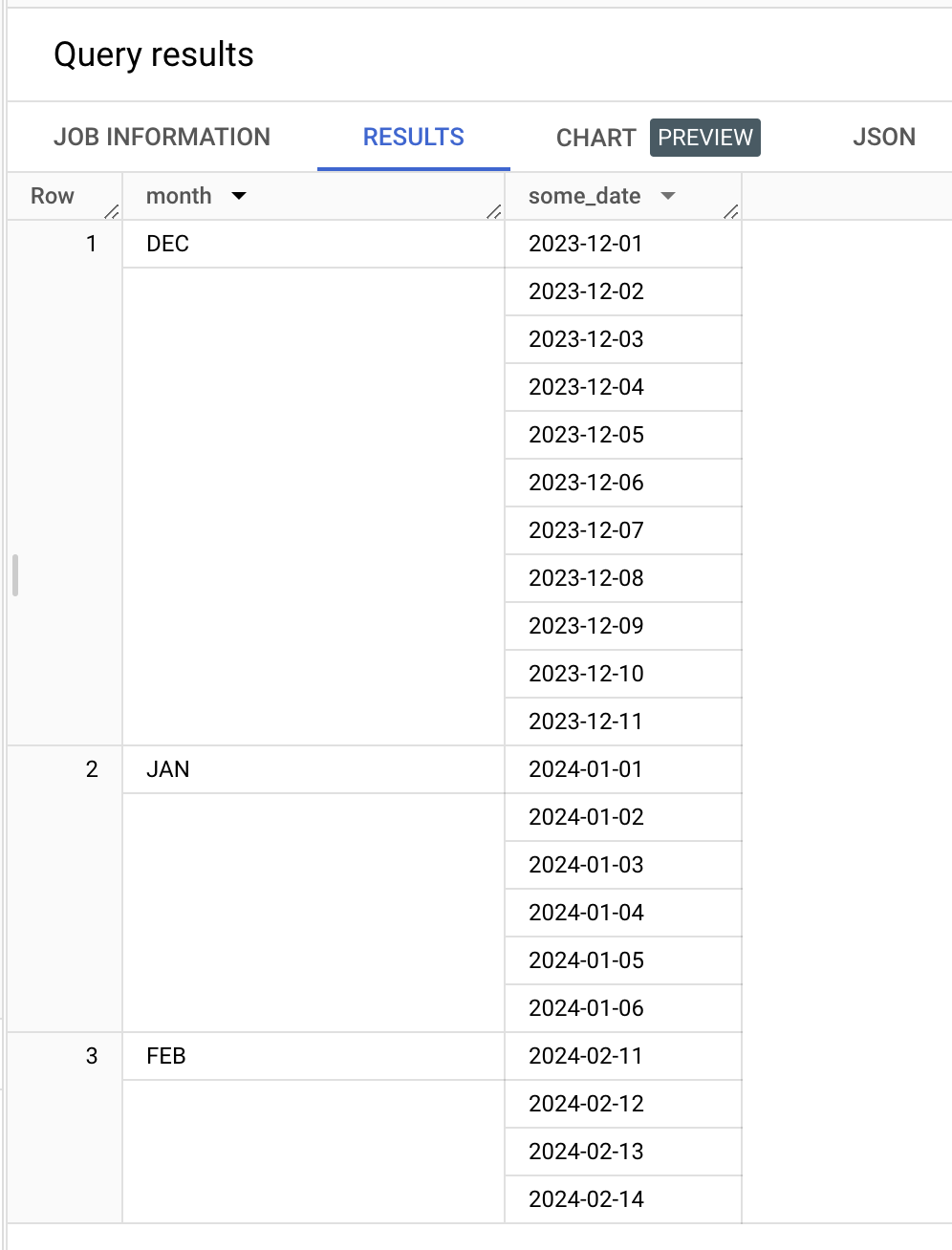
Array가 테이블 안에 있기 때문에 첫번째 쿼리처럼 평탄화 하기는 힘들다. 이럴땐 먼저 Sequences 테이블을 불러온 후 date_array를 UNNEST 해줘야 한다.
CROSS JOIN
WITH Sequences AS
(
SELECT 'DEC' AS month, GENERATE_DATE_ARRAY('2023-12-01', DATE_ADD('2023-12-01', INTERVAL 10 DAY)) AS date_array
UNION ALL SELECT 'JAN' AS month, GENERATE_DATE_ARRAY('2024-01-01', DATE_ADD('2024-01-01', INTERVAL 5 DAY)) AS date_array
UNION ALL SELECT 'FEB' AS month, GENERATE_DATE_ARRAY('2024-02-11', DATE_ADD('2024-02-11', INTERVAL 3 DAY)) AS date_array
)
SELECT *
FROM Sequences s
CROSS JOIN UNNEST(s.date_array)코드에서 UNNEST한 결과를 CROSS JOIN 한 것을 볼 수 있다. 처음 UNNEST 한 쿼리 결과를 보면 중첩 필드를 UNNEST 하면 테이블이 반환되기 때문에 조인이 가능하다.
여기서 CROSS JOIN은 모든 요소끼리가 아니라 아니라 묶여 있는 것들끼리의 데카르트 곱(Cartesian Product)을 반환한다. 아래 결과를 보면 쉽게 이해 될 것이다.
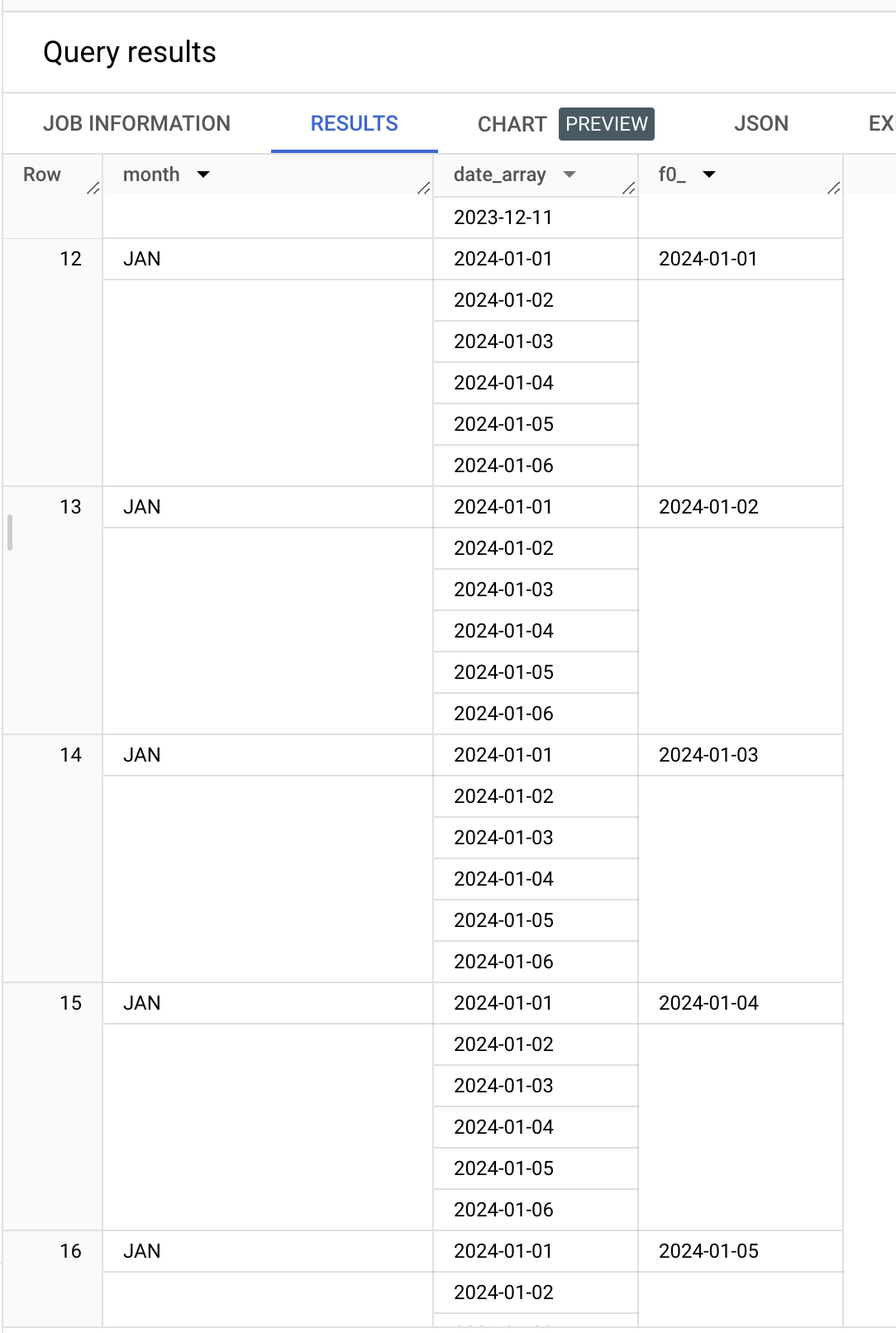
이제 month와 f0_ 이라고 된 행만 추려내면 평탄화가 완료된다. 편의상 행에 이름을 붙여서 쿼리해봤다.
WITH Sequences AS
(
SELECT 'DEC' AS month, GENERATE_DATE_ARRAY('2023-12-01', DATE_ADD('2023-12-01', INTERVAL 10 DAY)) AS date_array
UNION ALL SELECT 'JAN' AS month, GENERATE_DATE_ARRAY('2024-01-01', DATE_ADD('2024-01-01', INTERVAL 5 DAY)) AS date_array
UNION ALL SELECT 'FEB' AS month, GENERATE_DATE_ARRAY('2024-02-11', DATE_ADD('2024-02-11', INTERVAL 3 DAY)) AS date_array
)
SELECT month, da
FROM Sequences
CROSS JOIN UNNEST(date_array) as da;
간결하게 만들기
CROSS JOIN은 쉼표로 더 간결하게 수행할 수 있다.
WITH Sequences AS
(
SELECT 'DEC' AS month, GENERATE_DATE_ARRAY('2023-12-01', DATE_ADD('2023-12-01', INTERVAL 10 DAY)) AS date_array
UNION ALL SELECT 'JAN' AS month, GENERATE_DATE_ARRAY('2024-01-01', DATE_ADD('2024-01-01', INTERVAL 5 DAY)) AS date_array
UNION ALL SELECT 'FEB' AS month, GENERATE_DATE_ARRAY('2024-02-11', DATE_ADD('2024-02-11', INTERVAL 3 DAY)) AS date_array
)
SELECT month, da
FROM Sequences, UNNEST(date_array) as da;이 코드에서 UNNEST를 생략할 수도 있다. 이때는 조회하려는 테이블에 aliases 붙여줘야 충돌이 일어나지 않는다.
최종 솔루션
아래 마지막 코드는 간결하고 열 이름을 따로 지정할 필요도 없기 때문에 간편하기도 하다.
WITH Sequences AS
(
SELECT 'DEC' AS month, GENERATE_DATE_ARRAY('2023-12-01', DATE_ADD('2023-12-01', INTERVAL 10 DAY)) AS date_array
UNION ALL SELECT 'JAN' AS month, GENERATE_DATE_ARRAY('2024-01-01', DATE_ADD('2024-01-01', INTERVAL 5 DAY)) AS date_array
UNION ALL SELECT 'FEB' AS month, GENERATE_DATE_ARRAY('2024-02-11', DATE_ADD('2024-02-11', INTERVAL 3 DAY)) AS date_array
)
SELECT month, date_array
FROM Sequences AS T, T.date_array;(C) 2023. 돌아와고래. All rights reserved.
