Attention-based Dropout Layer for WSOL 논문 리뷰
설명 영상


Attention based Dropout Layer
→ self-attention mechanism
- hiding the most discriminative part
- highlighting the informative region for improving the recognition power
Introduction
문제 제시
object detection 에서 이루어지는 많은 track discriminative feature 들은 전부 most discriminative 한 부분만을 고려하게 된다.
그리고 CAM을 이용한 WSOL에서는 classifier가 object를 인식하기 위해서 object region을 인식하는 방법을 이용하였다. 이는 most discriminative 한 부분들을 찾기 때문에, object 전체를 localization 해야하는 WSOL에서는 문제가 되었다.
→ 해당 부분을 해결하기 위해서 많은 방법이 나왔는데, 대부분 training time에 most discriminative 한 부분의 값을 zero로 만드는 방법을 택했다. 이는 특정 노드들을 deativate 하는 dropout과 비슷한 기능을 가지고 있다. 또한 이방법은 most discriminative 한 부분이 아닌 다른 less discriminative 한 부분도 잘 찾아 냈다. (HaS 같은 경우 random으로 삭제했지만 이는 fast하나 효율적으로 지우지 못한다는 문제점이 있었다.)
ACOL, AE와 비슷한 논문들은 HaS의 문제를 해결하기 위해 (효율적으로 삭제하기 위해) 여러개의 classifier를 두는 방법을 선택했지만 이는 큰 computing resource를 차지하게 된다.
해결책
해당 논문에서는 effective and efficient하게 most discriminative 한 부분을 삭제하면서, 이용하는 substantial 한 computing resource를 줄이는 방법인, self-attention mechanism을 이용한 ADL을 이용하게 될 것이다.
원리
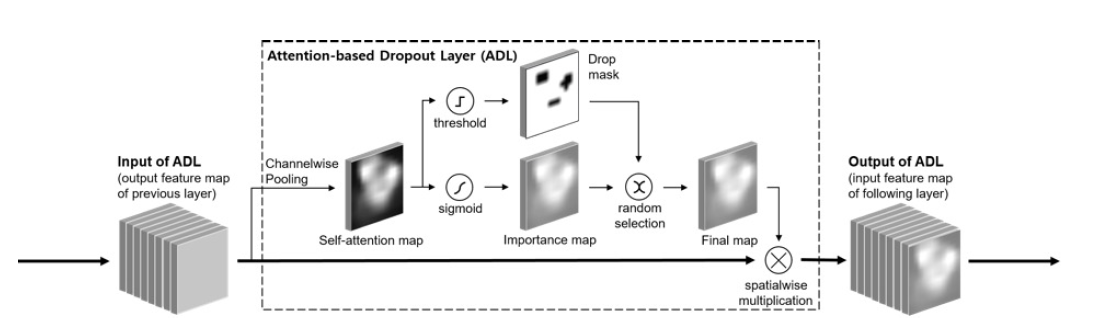
self attention map 은 Channel-wise average pooling을 feature map을 실행시킬 때 얻게 된다. self attention map을 기반으로, ADL의 중요한 점 두가지는 drop mask와 importance map이다.
Drop mask는 most discriminative 한 것을 숨길 때 이용되게 된다. 이는 model이 less discriminative 한 부분을 숨길 때 주로 이용되게 된다. drop mask는 self-attention map을 thresholding 하면서 얻게 된다.
Importance map은 informative region을 강조하여 classification 능력을 향상시킬 수 있도록 해준다. 따라서 more accurate 한 self-attention map이 생성될 수 있도록 한다. 해당 importance map은 sigmoid activation 을 self-attention map에 적용하여 계산해내게 된다.
훈련과정에서는 drop mask와 importance map이 확률적으로 한 epoch 마다 선택이 되고 해당 map은 spatial wise multiplication으로 input feature map에 적용되게 된다.
현재 존재하는 WSOL과 비교하였을 때, computation 과 parameter overhead에서 더 효율적이었다.
→ 이유는 forward-backward를 한 모델에서 한번만 쓰기 때문이다.
ADL은 모델과 관련없이 쉽게 conv feature map이 localization accuracy를 향상시킬 수 있도록 적용이 가능하다. 기존에 존재하는 self-attention 과 비교하면, self-attention map을 추출하기 위해 훈련시켜야 할 param이 없다는 점에서 굉장히 가볍다.
해당 모델은 lightweight, efficent, and excellent accuracy를 가졌다. CUB에서 SOTA, ImageNet에서 SOTA와 비교할만한 accuracy를 가졌고, cam보다 less discriminative한 부분을 잘 찾아낸 다는 것을 알 수 있었다.
Related Work
Dropout
overfitting 을 해결하기 위한 regularization 기술로 hidden node를 randomly zero로 만들어 regularization effect를 얻게 된다. 이는 network가 ensemble 효과를 얻을 수 있다.
그러나 이는 FC layer에서와 다르게 conv feature map에서는 좋지 않은데, 이유는 공간적인 특성을 가진 인접한 픽셀들은 서로 큰 연관성을 가지고 있기 때문이다. 픽셀들은 서로 불필요한 맥락적 특성을 가짐. 그렇기 때문에, 인접한 node까지 다 삭제하지 않는 이상 information을 모두 지울 수는 없음.
그래서 feature map의 partial channel을 같이 랜덤으로 drop하자는 논문이 나옴. 이렇게 되면 기존에 pixel wise 한 dropout의 문제점을 해결할 수 있게 됨. (Channel based dropout)
해당 논문과 ADL의 다른 점은 ADL은 channel을 drop 하는게 아니라, strong activated 한 map을 dropout 하는 것임. (region-based dropout)
이때 MaxDrop 논문이 나왔는데, 이는 maximally activated pixel을 channel wise or spatial wise하게 drop 해버리는 것임. 이와 비슷하게 drop 한다는 의의는 분명하지만, maximally activated part를 찾아낼 때 ADL은 attention을 이용하여 찾아 낸다는 게 다른 점임. → 그리고 추가적으로 ADL은 maximal한 region을 찾아내지, pixel을 찾아내지 않음.
Attention mechanism
사람이 어떤 물체에 대한 의견을 낼 때 중요하게 보는 부분이 있는 것처럼, network도 important data를 집중적으로 보게 된다. 이를 attention mechanism이라고 한다.
만약 해당 query 자체가 input이라면 이를 self-attention이라고 하는 것이다. 이는 각각 해당 task에서 의미있는 표현을 학습하게 된다. → classification 에서는 informative feature를 강조하는 것처럼.
Residual Attention Network와 같은 various method 들이 CNN classification model에서 accuracy를 증가시켰다. RAN은 3D self attention map을 이용해서 accuracy를 높였지만, attention extraction을 위한 raw feaure map (압축안함) 은 parameter overhead를 증가시켰다.
SE는 1D channel self-attention map을 이용해서 classification accuracy를 높였다. self-attention map을 추출하기 위해서 GAP를 거쳐서 2개의 MLP layer를 거치는데, 그렇게 하기 때문에 SE는 parameter를 reduce 할 수 있었다. 그러나 RAN의 10%밖에 쓰지 않는다고 해도, parameter overhead는 무시할 수 없다.
channel, spatial attention
https://blog.lunit.io/2018/08/30/bam-and-cbam-self-attention-modules-for-cnn/
channel attention은 어떤 channel이 중요한지 뽑아 내는 것.
spatial attention은 어떤 공간이 중요한지 뽑아내는 것.
BAM과 CBAM은 1D channel, 2D spatial self attention map을 통해서 accuracy를 높였다. 공간 attention map은 보조 conv layer를 이용해서 계산을 하게 되었다. 그리고 informative region을 잘 볼 수 있도록 self-attention map을 input feature map에 적용하였다.
→ ADL 또한 importance map을 rewarding the informative region을 위해 이용한다는 점에서 비슷하다. 그러나, 확률적으로 drop mask에 의해서 패널티를 받는 다는 것이 다른 점 중 하나이다.
그리고 이 기술들과 다른 점중 하나는, self-attention map을 추출할 때 추가적인 훈련이 필요한 parameter를 필요로 하지 않는다는 점이다.
ADL: Attention-based Dropout Layer
ADL은 self-attention map을 input feature에서 만든 후, drop mask와 importance map을 생성하게 된다. 여기서 이 둘을 같은 self-attention map에서 생성되었지만, 완전 반대의 기능을 가지고 있는데, drop mask는 most discriminative 한 부분을 가려서 전체적인 discriminative 한 부분을 볼 수 있도록 만들어주고, importance map은 classification power를 높여줄 수 있도록 most discriminative 한 부분을 더 높여주는 역할을 하게 된다.
이 두 개의 mask, map은 확률적으로 어떤 것을 선택해서 input feature에 적용할 지 고르게 된다. 그렇게 되면 해당 두 확률 모두 동시다발적으로 얻게 되는 것이다.
ADL의 parameter에는 drop_rate와 threshold가 있는데, drop_rate는 얼마나 자주 drop mask가 적용되는지를 말하는 것이고, threshold는 drop 할 지역의 크기를 조절하게 된다.
ADL 의 input은 F 라는 convolutional feature map이다. 이때 mini batch dimension은 생략하도록 한다.
그리고 F 에 channel wise pooling 을 적용하여 self-attention map을 만들어 낸다. channel wise pooling을 하게 되면 각 discriminative power과 비례하는 pixel의 intensity를 가지는 self-attention map이 만들어진다. (classification model을 훈련시키게 되므로) 그렇게 되면 가장 discriminative 한 part의 공간적 분포를 효과적으로 측정할 수 있게 되는 것이다.
drop mask를 얻기 위해서는 threshold를 이용하게 되는데, 해당 threshold 값을 넘는 region을 drop 하는 즉 0으로 만들어 버린 후에 input feature map에 spatial wise 하게 곱하게 된다. 또한 threshold 값이 낮아질 수록 drop 하는 region은 넓어지게 된다.
그리고 이런 식으로 region 을 drop 하게 되면 most discriminative 한 부분을 hide 하는 것과 마찬가지 이므로, less discriminative 한 부분에서 의미있는 localization을 할 수 있도록 훈련이 될 것이다. 근데, 만약에 계속 most discriminative 한 부분을 drop 하면, 훈련과정에서 계속 그 부분을 찾을 수가 없게 되므로 그렇게 되면 classification accuracy가 떨어지기 때문에 importance map을 추가하게 된다. 이 또한 drop mask와 같이 H*W 만큼의 크기를 갖게 되는데, 이는 기존 self-attention map에 sigmoid function을 적용하여 less discriminative 한 부분은 0으로, most discriminative 한 부분은 1로 만들어서 most discriminative 한 부분이 높은 값을 가질 수 있도록 만든다.
해당 두 개가 확률 적으로 선택되게 되는데, 그 확률은 drop_rate 라는 parameter로 조절할 수 있다. importance map 또한 spatial wise 하게 multiplication 이 이루어지게 되므로 classification accuracy를 높일 수 있다.
해당 method들은 각각의 convolutional feauter map에 독립적으로 적용되므로, 여러 feature map들을 가진 classification model과 쉽게 연결될 수 있고 이는 classification의 accuracy를 높이게 된다. 그리고 이 method를 실행할 때는 훈련할 parameter가 따로 없다. 여러 feature map을 적용하기 위한 parameter overhead가 없다는 의미이다. 게다가 ADL에서는 보조 classifier나 re-training, forward-backward propagation 이 없어도 most discriminative 한 부분을 효과적으로 인식하고 지울 수 있다.
ADL의 해당 보조 module은 training time에만 쓰이고 testing time에는 쓰이지 않는다. testing phase에는 vanilla model과 동일하게 쓰인다는 것이다. 그렇기 때문에, heatmap 추출에 쓰이는 method들이 적용이 가능하다 그리고 다른 dropout-based method들과 같이 training and testing 사이의 다른 분포를 보충하지 않았다.
Relation with other attention extraction methods.
ADL은 훈련할 parameter가 없는 lightweight method인데, 어떻게 meaningful 한 result를 낼 수 있는지 궁금해 할 수 있다. 최근의 연구에서는 transfer learning에서 informative region을 찾아내는 것은 channel wise pooling 을 conv feature map에 적용하면서 인식될 수 있었고, 이는 transfer learning에서 channel wise pooling을 통해 self-attention map을 얻을 수 있다는 것을 의미한다. → 이후에 CBAM이 나오면서 classification accuracy를 높이는 보조적인 conv layer (sigmoid activation 도 이용)가 나왔다.
BAM Auxiliary conv layer
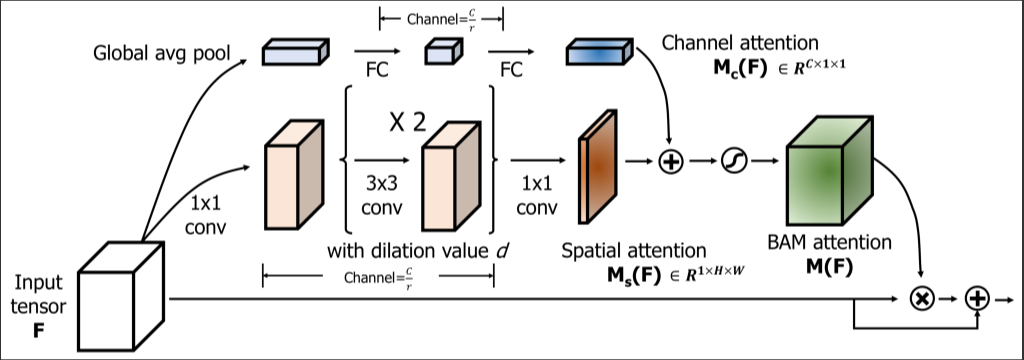
input feature map에 self-attention map을 spatial wise 하게 곱하여 적용할 수 있도록 만들었다. 이러한 보조자 classifier는 classification accuracy를 높여주었다.
그러나, ADL에서는 auxiliary layer를 굳이 추가하여 self-attention map을 만들 필요가 없다고 생각했다. 왜냐하면 이미 존재하는 CNN model에서는 충분히 의미있는 self-attention map을 만들 수 있기 때문이다. 그래서 ADL에서는 기존의 CNN model에서 channel wise pooling으로만 self-attention map을 만들어 내고, 이것에 sigmoid activation 을 적용해서 input feature에 적용할 수 있도록 하였다.
그리고 loss function을 통해서 기존의 CNN layer 들이 업데이트 되고, self-attention map을 적용하기 때문에 의미있는 classification accuracy를 만들 수 있는 것이다.
예를 들어 만약 self-attention map이 object region을 잘 찾아내지 못한다면, 이는 classification accuracy를 낮출 수 있을 것이다. 따라서 존재하는 CNN layer들은 더 정확한 self-attention map을 만들기 위한 방향으로 훈련이 된다. 기존의 CNN layer들은 CBAM에서 보조자 역할을 하는 conv layer과 같은 역할을 수행하고 있는 것이다.
localization task와 classification accuracy의 상관관계에 대한 질문
ACoL 이나 CUTOUT 에서는 less discrimitative 한 부분을 찾으면서 classification accuracy도 높아졌는데, 그러면 region 을 찾는 것과 classification accuracy를 높이는 것은 비례하는 건지?
그러기엔 top 1 accuracy가 gt known과 큰 차이를 보였다는 점에서 두 부분이 상관관계가 큰 건지 잘 모르겠음.
→ 아래에 나옴
다른 연구에서는 이와 비슷하게 FC layer를 GAP layer로 대체하는 시도를 했었다.
ADL method를 이용한 classification accuracy는 CBAM보다는 낮았다. 그러나 ADL은 확실히 meaningful한 결과를 얻을 수 있었다. 실험 결과에서는 ADL의 self-attention map이 classification accuracy를 높였고 most discriminative 한 부분을 잘 찾는 다는 것을 알 수 있었다.
Relation between drop mask and importance map
drop mask는 most discriminative 한 부분에 penalty를 주고, importance map에서는 most discriminative 한 부분을 강조한다. 이렇게 보면 두 부분은 상호 독립적이라고 볼 수도 있지만 실상은 그렇지 않다. 왜냐하면 drop mask가 좋은 most discriminative 한 부분을 drop 하기 위해서는 importance map에서 most discriminative 한 부분을 잘 찾아내 줘야 하기 때문이다. importance map이 classification accuracy를 높여주면 self-attention map에서 most discriminative 한 부분이 더 잘 잡힌다. 따라서 drop mask는 most discriminative 한 부분을 효과적으로 drop 할 수 있게 된다.
Relation between classification and localization.
기존에 존재하던 연구에서는 localization 이 증가하면 trade off 로 classification accuracy는 타협되는 즉, classification accuracy는 조금 낮아지는 현상이 발생한다고 말했었다. 그들은 drop mask를 이용해서 most discriminative 한 부분을 삭제하기 때문에 그렇다고 추측했고 우리 또한 drop mask 때문에 classification과 localization 의 tradeoff 가 있다는 것을 실험에서 볼 수 있다.
그러나 importance map이 있기 때문에, classification power이 다른 기술들에 비해서 accuracy가 크게 낮아지지 않았다는 것을 알 수 있다.
Relation with the current SOTA
ADL이 나올 당시에 SOTA는 ACoL과 SPG가 SOTA 였다. ACoL은 보조자 역할의 classifier를 넣어서discriminative 한 부분을 숨겼다. ADL은 ACoL에 비해서 추가적인 classifier가 필요가 없기 때문에 더 효율적이다. SPG는 foreground와 background의 공간적인 분포를 고려한 새로운 WSOL technique를 만들게 되었다.
classifier는 추가적인 supervision의 분포를 이용한 전체적인 object의 정도를 학습하게 된다. SPG는 discriminative 한 부분을 삭제하지 않았다는 점이 다르고, 추가적인 computing resource기 필요하다는 점에서 ADL과 다르다.
Experimental Results
dataset
CUB dataset과 ImageNet-1k 데이터 셋을 이용하였고 training set으로는 훈련을, validation set으로는 evaluate 를 하게 되었다. → ImageNet은 130만개의 이미지가 들어있고, 그 중에서 1000classes 가 존재한다. 또한 val data는 5만개의 image가 존재한다.
class 의 다양성은 ImageNet 보다 CUB 가 더 적은데, 그 이유는 CUB 가 새만을 인식하기 때문이다. 그래서 CUB 같은 경우 most discriminative 한 부분이 상대적으로 조그맣다.
→ 예를 들어 Common Raven 과 White necked Raven 이라는 새가 있는데, 이 둘은 목의 색깔을 제외하고는 다른 점이 거의 없다. 이것은 most discriminative 한 부분이 목 밖에 없고, 전체사이즈랑 비교했을 때 너무 일부분이다.
결론적으로는 CUB 데이터 셋이 ImageNet 에 비해서 크진 않지만, 그렇기 때문에 오히려 WSOL에서 CUB 데이터를 쓰는 것은 도전적이라고 볼 수 있을 것이다.
Implementation details
VGG, ResNet, MobileNetV1, InceptionV3를 backbone layer 로 지정했다. 이전에 나온 논문과 비슷하게 VGG에서는 마지막 pooling layer와 2개의 fc layer를 삭제하고 GAP 을 넣었다. 그리고 InceptionV3는 SPG와 똑같이 넣었다. 다른 self-attention method와 비교하기 위해 SE block을 ResNet 에 넣게 되었다.
SE block
SENet(Squeeze and excitation networks)
쉽게 SE block을 Resnet이나 Inception block에 붙일 수 있음. 이는 channel의 중요도를 판별하기 위해 GAP 이후 fc layer 및 activation function 을 통해서 channel의 correlation 에 대한 feature 들을 channel length 만큼 재생성하고 channel wise multiplication을 통해 다시 feature map에 붙여준다.
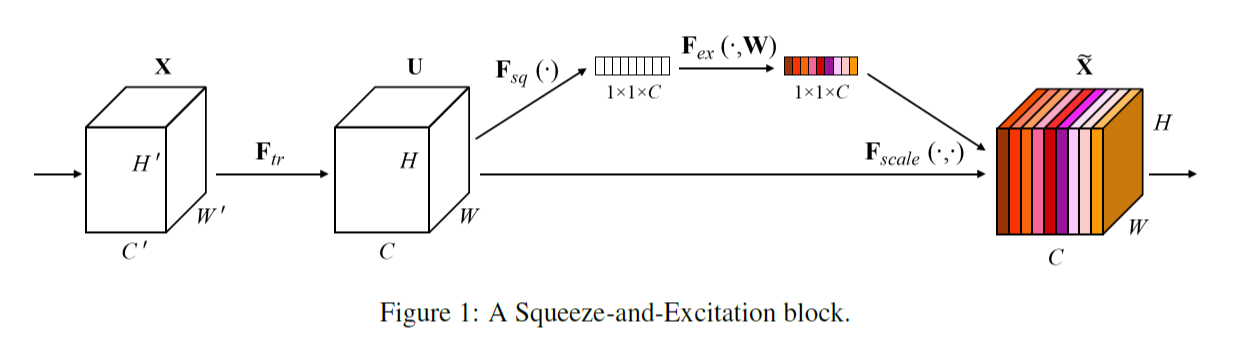
그리고 ResNet과 MobileNetV1 모두 마지막 strided conv 를 1로 설정했는데, 히트맵을 14 * 14 로 확장시키기 위함이다.
ADL 은 CNN 모델의 각각의 feature map에 순차적으로 연결되어 있다. 즉 ADL의 output 이 다음 layer의 input으로 들어간다는 것이다. ADL에서는 ImageNet-1k로 pre-trained 된 model을 이용하였다.
CAM을 이용해서 classification model의 heatmap을 뽑아 냈고 bounding box 또한 heatmap에서 얻어 냈다.
extensive ablation 연구에 의하면, ADL의 중간 layer에 bottleneck part를 넣는 것이 더욱 적절하다는 결론이 나왔다.
hyperparameter도 적절히 설정하였지만, 이는 그저 recommand setting 이므로 다른 parameter를 쓴다면 localization accuracy는 더 improved 될 수도 있을 것이다.
Eval Metrics
ACoL과 같이 Top-1 Clas, Top-1 Loc, GT-known Loc을 이용하였다. IoU는 50%을 이용하였다. Top 1 Loc은 clas, gt-known 모두 만족하는 것이므로 Top 1 Loc을 이용하는 것이 localization performance 를 정하는데 적절하다.
Ablation Study
ablation study
Glossary
Ablation study는 모델이나 알고리즘을 구성하는 다양한 구성요소(component) 중 어떠한 “feature”를 제거할 때, 성능(performance)에 어떠한 영향을 미치는지 파악하는 방법을 말한다. 좀 더 막연한(coarse) 정의로는, 제안한 요소가 모델에 어떠한 영향을 미치는지 확인하고 싶을 때, 이 요소를 포함한 모델과 포함하지 않은 모델을 비교하는 것을 말한다. 이는 딥러닝 연구에서 매우 중요한 의미를 지니는데, 시스템의 인과관계(causality)를 간단히 알아볼 수 있기 때문이다.
VGG-GAP 을 backbone network로 이용하였고, 모든 pooling layer와 conv5-3 layer에 ADL을 연결하였다. 그리고 CUB 를 통해서 model을 fine tune 하게 되었다.
첫번째로, self-attention map과 drop mask를 보여주었다. self-attention map은 lower-level layers (pool1 and pool2)에서 분류를 위한 것이 아닌 일반적인 특징을 포함한다는 것을 보여주었고, high layer에서는 class specific 한 self-attention map이 발생했다. drop mask 또한 high level layer에서 더 most discriminative 한 region 들을 잡아낸다는 것을 보여주었다.
두번째로 drop_rate 와 accuracy의 관계에 대해서도 분석을 했다.
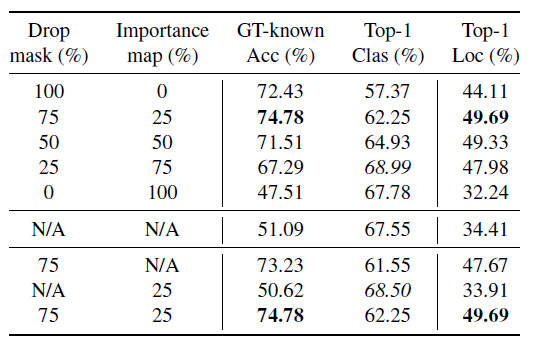
drop_rate가 75일 때 가장 좋은 accuracy가 나온다는 것을 알 수 있었다. 만약 drop_rate가 100일 경우에는 high discriminative 한 region들이 가려지기 때문에 classification 과 관련된 accuracy가 낮아진 다는 것을 알 수 있다. → localization accuracy와 adversely 한 영향을 미침.
즉 매 iteration 마다 100% 가리게 된다면, GT-knowns은 소폭으로 감소하고, Top 1 class와 top 1 Loc이 둘 다 대폭 감소했다는 것으로 보아 classification accuracy의 감소에 큰 영향을 미쳤다는 것을 알 수 있다.
drop_rate가 감소하면 classification accuracy가 오른다는 것을 알 수 있었는데, 반대로 25% 에서 0%로 너무 심하게 감소하게 되면 classification accuracy도 낮아진다는 것을 알 수 있다. 이는 overfitting 때문이라고 생각한다.
drop mask는 dropout을 base로 하며, MaxDrop과 이론상 일치한다. 그렇기 때문에, drop_rate를 조절하는 것은 overfitting을 방지하고 classification accuracy를 증가시킨다. drop mask의 regularization effect 검증은 범위를 넘어서기 때문에 다루지 않지만 추후 연구에서 다뤄볼 예정이다.
세번째로 각각의 component 가 어떤 효과를 발하는지 알기 위해서 drop mask와 importance map을 각각 deactivating 해서 (둘 중에 하나만) accuracy를 알아보게 되었다. 결과는 위 table에서 아래 part의 결과가 나오게 되었는데, 둘 중에 하나라도 deactivate 할 경우 둘 다 activate 한 것들이 더 성능이 좋았다는 것을 알 수 있다. 이는 두 개의 map이 서로 상호 배타적이지 않다는 것을 의미한다.
importance map이 혼자 적용되게 되면 classification accuracy가 오른다는 것을 알 수 있는데, 이는 most discriminative 한 부분에 더욱 집중해서 보기 때문에 accuracy가 높아지는 것이다. 이러한 결과는 ADL이 제안한 lightweight attention method가 효과적으로 classification accuracy를 늘려준다는 것을 알 수 있다.
그리고 drop mask만을 남겨두었을 때는 localization accuracy는 늘어나지만, classification 의 정확도가 낮다는 것을 알 수 있다. 이는 모델이 계속 less discriminative 한 부분을 보게되면서 classification을 할 때에도 해당 부분을 계속 보게 되기 때문이다. drop mask의 결과를 보았을 때, classification과 localization이 tradeoff 관계에 있다는 것을 알 수 있다.
그리고 마지막으로 ADL이 만든 feature map에서 어디에 존재하는 feature map을 고르는 지가 accuracy에 미치는 영향을 분석했다.
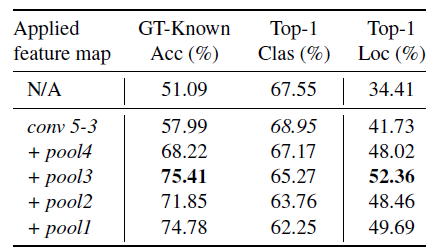
여기서 여러 convolution feature 들에 ADL을 붙이게 되면 Accuracy가 높아진다는 것을 알 수 있었다. ADL을 붙이게 되면 localization과 classification이 높아진 다는 것을 알 수 있었다 다만, classification accuracy는 낮아진다는 것을 알 수 있다.
추가적으로 ADL을 pool2와 pool1과 같은 낮은 layer에도 붙이게 되면 오히려 localization accuracy가 낮아졌는데 이는 lower-level feature에서는 general 한 즉, classification model에서 target discriminative한 부분이 강조되지 않은 feature map을 가지고 있기 때문에, 그렇게 된 것이라고 생각한다. → 즉 lower level feature map에서는 효과적으로 discriminative 한 feature을 애초에 찾기 어렵기 때문에, erase 하기도 힘들고 localization accuracy는 떨어지는 것이다.
Comparison with SOTA Methods
CAM, HaS, ACoL, SPG method들과 비교하였으며, ACoL과 SPG는 SOTA method 이다. accuracy는 기존 논문에 있던 accuracy를 가져왔다. 그러면서도 ACoL과 SPG과 같은 backbone network를 만들어 훈련 시켰다. 그리고 HaS 나 ADL은 해당 backbone network에 적용되었다.
baseline을 CAM으로 설정하고, ADL과 HaS 각각의 accuracy를 평가하였다. parameter overhead 없이 진행했을 때는 HaS가 가장 well performed 되었었다.

해당 결과를 보면 일단 vanilla model인 cam 보다는 ADL이 전체적으로 less discriminative 한 부분을 잘 캐치한다는 것을 알 수 있었다.
그 다음 CUB 데이터 셋에 대해서 질적인 evalutation result는 아래와 같이 나왔다.
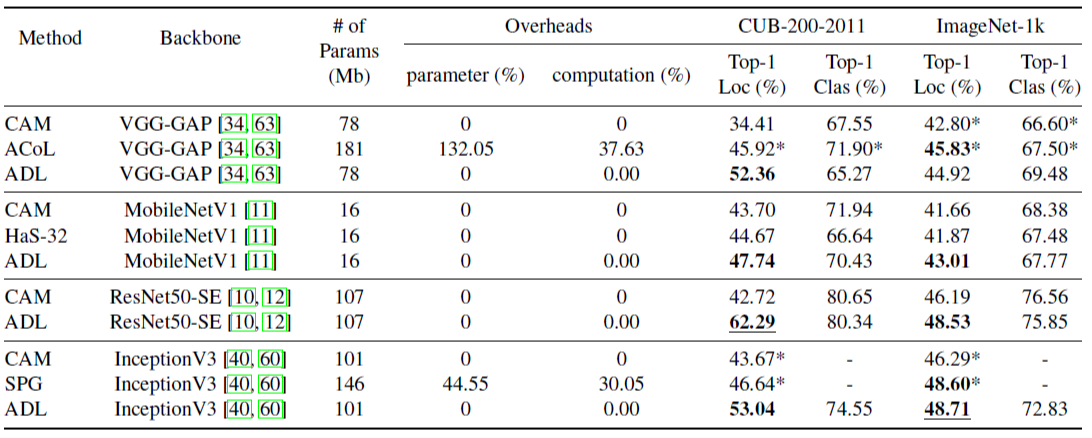
여기레서는 parameter와 computation 양까지 계산하게 되었다. (parameter overhead)
ADL은 추가적인 parameter를 전혀 쓰지 않고, computation 양 또한 0.003%로 거의 존재하지 않았다. 그리고 ACoL과 SPG와도 비교했을 때 parameter과 computation 량을 포함해서 accuracy 까지 더 높았다는 것을 알 수 있다.
그리고 WSOL의 효과를 확실하게 보기 위해 MobileNetV1을 backbone netwrok로 진행하였다. 이는 ACoL과 SPG같은 computation과 parameter 양이 많은 method에 적합하지 않다. 그러나, ADL과 HaS에는 limited resource임에도 불구하고 적용이 가능했다. 결과적으로 ADL은 HaS보다 localization 성능이 더 좋았다. 그리고 추가적으로 HaS는 localization과 classification의 trade-off로 인해서 classification accuracy가 많이 떨어졌는데, ADL은 importance map을 이용하기 때문에 accuracy가 HaS보다는 적게 떨어진다.
위와 같은 결과 덕분에 ADL은 SOTA를 달성하였다. (In CUB dataset) bakbone network가 ResNet-SE 라면 localization accuracy가 SOTA에 비해 15% 증가하였다. 그리고 ACoL과 SPG에 비해서 ResNet50-SE에 이용하는 ADL은 parameter 수도 작다.
ImageNet-1k에서는 VGG-GAP을 이용했을 때 CAM보다 좋았지만 ACoL보다는 낮았다. 그러나 ResNet50-SE를 이용했을 경우에는 localization accuracy가 ADL이 ACoL보다 좋고 SPG랑 비슷했다. (computing resource는 ADL이 훨씬 좋다.) InceptionV3를 backbone으로 이용했을 때는 SPG랑 accuracy가 비슷했다.
즉, ADL은 CUB에서는 큰차이로 SOTA, ImageNet에서는 다른 SOTA Method들과 비슷한 성능을 이끌었다.
Discussion
ADL은 single object detection task에서 SOTA를 찍었지만 WSSS에서도 이용할 수 있다. testing 에서 ADL은 vanilla version의 CAM과 일치하게 evaluation 하기 때문에 semantic segmentation에서도 잘 포함될 수 있을 것이다.
CUB에서는 성공했지만 ImageNet에서는 실패한 accuracy를 볼 수 있었는데, 이는 해당 target object에 많이 나오는 background feature들이 계속 추출되었기 때문이다.

위와 같은 경우 snowmobile class인데, snow 가 계속 보이게 된다. vanilla model은 snow mobile 만 focus 하게 되지만, ADL은 snowmobile만 학습하지 않고 snow와 tree도 학습시키기 때문에, fail 한 것이다. less discriminative 한 feature을 학습시키기 때문에 일어난 현상이라고도 볼 수 있다.
ImageNet-1k는 다양한 classes 들이 있기 때문에 background 가 target object와 함께 포함될 수 있음. 그래서 background 가 어느정도 discriminative한 power을 가지게 되고, 그러면 most discriminative 한 feature region을 drop할 때 background를 discriminative 한 feature로 인식하게 되는 것.
CUB dataset에서는 accuracy가 올라간 이유가 모든 dataset에서 class들이 비슷한 background를 가지고 있기 때문에, background 를 discriminative 한 feature로 보지 않기 때문임. (Sky, Tree else) → 이렇게 되면 most discriminative 한 부분을 가려도 background를 학습하지 않게 됨.
결론적으로 ADL에서는 두 개의 dataset의 accuracy에 대해서 극명히 갈리는 결과를 보게 되었는데, 이는 ADL이 less discriminative 한 부분을 잘 학습시키기 때문이다. 그렇기 때문에 background가 discriminatvie feature가 되지 않는 CUB데이터 셋에서는 accuracy가 높게 나오지만, ImageNet에서는 background 가 discriminative feature가 될 수 있기 때문에 accuracy가 낮게 나온다.
→ 이것은 모든 less discriminative를 학습하는 WSOL method 들에게 큰 문제가 되고, 이는 이후의 연구에서 처리해야할 일로 남는다.
마지막으로, dataset의 크기 차이때문에 accuracy가 낮아진 것은 아니다. 왜냐하면 ADL은 비슷한 background를 가진 class에서만 보통 실패가 이루어졌기 때문이다.
Conclusion
ADL이라는 WSOL method는 CNN classifier를 모든 정도의 object를 학습할 수 있도록 도와준다. 제안한 방법은 기존의 SOTA 모델에 비해 효과적이고 가볍다. 추가적으로 CUB dataset에서 SOTA를 이루어 냈으며, ImageNet에서 SOTA와 비슷한 성능을 보였다.
그리고 localization accuracy를 높이기 위해 여러 CNN classifier들에 쉽게 적용할 수 있다.
미래의 연구에서는 drop mask의 regularization effect에 대해서 분석하고, model이 object 밖의 less discriminative region을 학습한다는 것에 대한 문제를 해결해야 할 것이다.
Pytorch Code Review
class ResNetAdl(nn.Module):
def __init__(self, block, layers, num_classes=1000,
large_feature_map=False, **kwargs):
super(ResNetAdl, self).__init__()
self.stride_l3 = 1 if large_feature_map else 2
self.inplanes = 64
self.adl_drop_rate = kwargs['adl_drop_rate']
self.adl_threshold = kwargs['adl_drop_threshold']
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0],
stride=1,
split=_ADL_POSITION[1])
self.layer2 = self._make_layer(block, 128, layers[1],
stride=2,
split=_ADL_POSITION[2])
self.layer3 = self._make_layer(block, 256, layers[2],
stride=self.stride_l3,
split=_ADL_POSITION[3])
self.layer4 = self._make_layer(block, 512, layers[3],
stride=1,
split=_ADL_POSITION[4])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
initialize_weights(self.modules(), init_mode='xavier')
def forward(self, x, labels=None, return_cam=False):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
pre_logit = self.avgpool(x)
pre_logit = pre_logit.reshape(pre_logit.size(0), -1)
logits = self.fc(pre_logit)
if return_cam:
feature_map = x.detach().clone()
cam_weights = self.fc.weight[labels]
cams = (cam_weights.view(*feature_map.shape[:2], 1, 1) *
feature_map).mean(1, keepdim=False)
return cams
return {'logits': logits}
def _make_layer(self, block, planes, blocks, stride, split=None):
layers = self._layer(block, planes, blocks, stride)
for pos in reversed(split):
layers.insert(pos + 1, ADL(self.adl_drop_rate, self.adl_threshold))
return nn.Sequential(*layers)
def _layer(self, block, planes, blocks, stride):
downsample = get_downsampling_layer(self.inplanes, block, planes,
stride)
layers = [block(self.inplanes, planes, stride, downsample)]
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes))
return layersclass ADL(nn.Module):
def __init__(self, adl_drop_rate=0.75, adl_drop_threshold=0.8):
super(ADL, self).__init__()
if not (0 <= adl_drop_rate <= 1):
raise ValueError("Drop rate must be in range [0, 1].")
if not (0 <= adl_drop_threshold <= 1):
raise ValueError("Drop threshold must be in range [0, 1].")
self.adl_drop_rate = adl_drop_rate
self.adl_drop_threshold = adl_drop_threshold
self.attention = None
self.drop_mask = None
def forward(self, input_):
if not self.training:
return input_
else:
attention = torch.mean(input_, dim=1, keepdim=True)
importance_map = torch.sigmoid(attention)
drop_mask = self._drop_mask(attention)
selected_map = self._select_map(importance_map, drop_mask)
return input_.mul(selected_map)
def _select_map(self, importance_map, drop_mask):
random_tensor = torch.rand([], dtype=torch.float32) + self.adl_drop_rate
binary_tensor = random_tensor.floor()
return (1. - binary_tensor) * importance_map + binary_tensor * drop_mask
def _drop_mask(self, attention):
b_size = attention.size(0)
max_val, _ = torch.max(attention.view(b_size, -1), dim=1, keepdim=True)
thr_val = max_val * self.adl_drop_threshold
thr_val = thr_val.view(b_size, 1, 1, 1)
return (attention < thr_val).float()
def extra_repr(self):
return 'adl_drop_rate={}, adl_drop_threshold={}'.format(
self.adl_drop_rate, self.adl_drop_threshold)