6. RAG 심화 - Embedding & Vector Store
문서를 벡터로 변환하고 의미 기반 검색을 구현해봅시다!
- Embedding의 개념과 작동 원리 이해
- Ollama Embeddings로 텍스트 벡터화
- Chroma DB로 벡터 저장소 구축
- 유사도 검색으로 관련 문서 찾기
- 실전 사내 지식베이스 검색 시스템 구축
사전 준비
필수 패키지 설치
powershell# 벡터 저장소 패키지
pip install chromadb
# 이미 설치되어 있어야 할 패키지들
pip install langchain langchain-ollama langchain-communityOllama 서버 확인
# Docker로 Ollama 실행 중인지 확인
docker ps | Select-String ollama
# qwen3:1.7b 모델 확인
docker exec -it ollama ollama list

설치 확인 스크립트
# week6_00_check_packages.py
"""Week 6 환경 확인"""
packages = {
"chromadb": "벡터 저장소",
"langchain_ollama": "Ollama 통합",
"langchain_community": "커뮤니티 통합"
}
print("=== Week 6 패키지 확인 ===\n")
all_ok = True
for package, purpose in packages.items():
try:
__import__(package)
print(f"✓ {package}: 설치됨 ({purpose})")
except ImportError:
print(f"✗ {package}: 설치 필요 ({purpose})")
print(f" → pip install {package}")
all_ok = False
if all_ok:
print("\n✅ 모든 패키지가 준비되었습니다!")
else:
print("\n⚠️ 위의 패키지를 설치해주세요.")
# Ollama 연결 테스트
print("\n=== Ollama 연결 확인 ===")
try:
from langchain_ollama import OllamaEmbeddings
embeddings = OllamaEmbeddings(model="qwen3:1.7b")
test_vector = embeddings.embed_query("테스트")
print(f"✓ Ollama 연결 성공 (벡터 차원: {len(test_vector)})")
except Exception as e:
print(f"✗ Ollama 연결 실패: {e}")
print(" → Docker로 Ollama가 실행 중인지 확인하세요")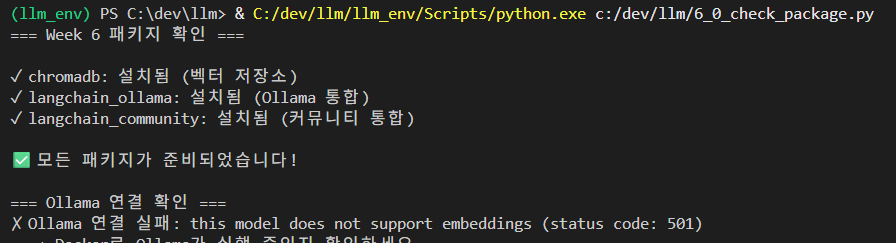
현재 ollama 에 설치된 모델은 qwen3:1.7b 모델로 텍스트를 생성하는 인스트럭트(Instruct) 모델입니다. 하지만 OllamaEmbeddings 클래스는 텍스트를 숫자로 변환하는 임베딩(Embedding) 전용 기능을 호출하려고 시도합니다.
Ollama에서 일반 대화 모델은 임베딩 API를 지원하지 않는 경우가 많아 501(Not Implemented) 에러가 발생하는 것입니다.
-> 해결 방법: 임베딩 전용 모델 추가
- 임베딩용 모델 다운로드
docker exec -it ollama ollama pull mxbai-embed-large임베딩용 모델 다운로드 후,
패키지 확인을 다시 함. 이때 모델명을 수정해 주어야겠지요.
수정 후 다시 실행시키면,
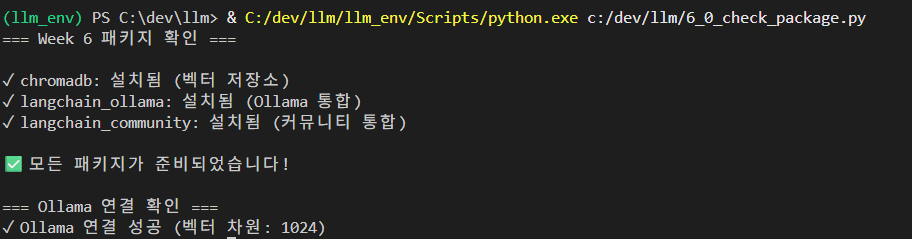
ok! 준비 끝.
1. Embedding이란?
개념 이해
Embedding은 텍스트를 숫자 벡터로 변환하는 과정입니다
# week6_01_embedding_concept.py
from langchain_ollama import OllamaEmbeddings
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
# 텍스트 → 벡터 변환
text = "LangChain은 LLM 프레임워크입니다"
vector = embeddings.embed_query(text)
print(f"원본 텍스트: {text}")
print(f"벡터 차원: {len(vector)}")
print(f"벡터 일부: {vector[:5]}...") # 처음 5개만 출력결과 :

- 왜 Embedding이 필요한가?
# week6_02_why_embedding.py
from langchain_ollama import OllamaEmbeddings
import numpy as np
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
# 의미가 비슷한 문장들
sentences = [
"강아지가 공원에서 뛰어놀고 있어요",
"개가 공원에서 놀고 있습니다",
"고양이가 집에서 자고 있어요",
"파이썬은 프로그래밍 언어입니다"
]
# 각 문장을 벡터로 변환
vectors = [embeddings.embed_query(sent) for sent in sentences]
# 코사인 유사도 계산
def cosine_similarity(vec1, vec2):
dot_product = np.dot(vec1, vec2)
norm1 = np.linalg.norm(vec1)
norm2 = np.linalg.norm(vec2)
return dot_product / (norm1 * norm2)
# 첫 번째 문장과 나머지 문장들의 유사도
print("=== 문장 유사도 ===")
print(f"기준 문장: {sentences[0]}\n")
for i in range(1, len(sentences)):
similarity = cosine_similarity(vectors[0], vectors[i])
print(f"문장 {i+1}: {sentences[i]}")
print(f"유사도: {similarity:.4f}\n")결과 :
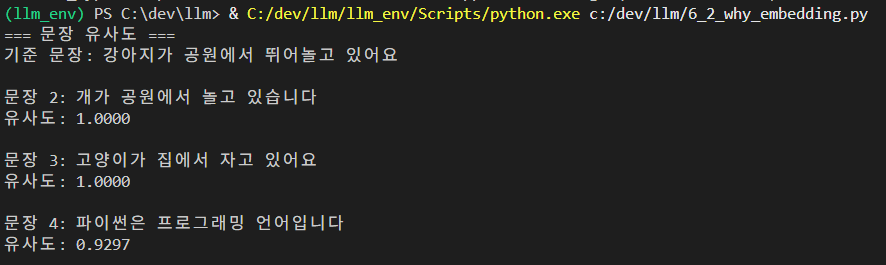
결과의 해석 ->
문장 2 (유사도 높음): 의미가 거의 같음
문장 3 (유사도 중간): 동물이라는 공통점
문장 4 (유사도 낮음): 완전히 다른 주제
2. Chroma DB - 벡터 저장소 구축
예제 1: 기본 벡터 저장소 생성
# week6_03_chroma_basic.py
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
# from langchain_schema import Document
from langchain_core.documents import Document
# Embeddings 초기화
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
# 문서 준비
documents = [
Document(
page_content="LangChain은 LLM 애플리케이션 개발 프레임워크입니다.",
metadata={"source": "docs", "topic": "langchain"}
),
Document(
page_content="Python은 인기 있는 프로그래밍 언어입니다.",
metadata={"source": "docs", "topic": "python"}
),
Document(
page_content="Vector DB는 임베딩을 저장하는 데이터베이스입니다.",
metadata={"source": "docs", "topic": "database"}
),
Document(
page_content="RAG는 검색 기반 생성 기법입니다.",
metadata={"source": "docs", "topic": "rag"}
)
]
# Chroma DB 생성
vectorstore = Chroma.from_documents(
documents=documents,
embedding=embeddings,
collection_name="my_collection",
persist_directory="./chroma_db" # 저장 경로
)
print(f"✓ 벡터 저장소 생성 완료!")
print(f"✓ 저장된 문서 수: {len(documents)}")
print(f"✓ 저장 위치: ./chroma_db")결과 :

예제 2: 저장된 벡터 저장소 불러오기
# week6_04_chroma_load.py
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
# 기존 벡터 저장소 로드
vectorstore = Chroma(
collection_name="my_collection",
embedding_function=embeddings,
persist_directory="./chroma_db"
)
# 저장된 문서 수 확인
collection = vectorstore._collection
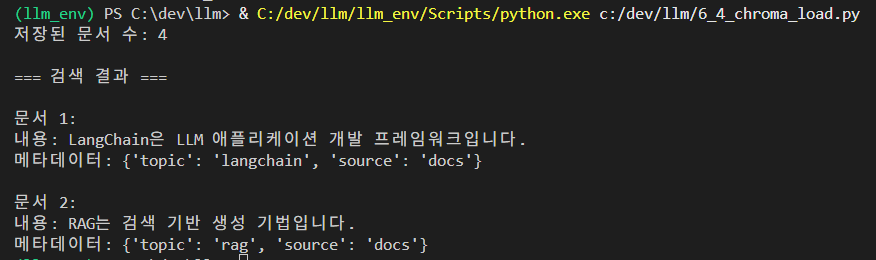
print(f"저장된 문서 수: {collection.count()}")
# 샘플 문서 조회
results = vectorstore.similarity_search("LangChain", k=2)
print("\n=== 검색 결과 ===")
for i, doc in enumerate(results, 1):
print(f"\n문서 {i}:")
print(f"내용: {doc.page_content}")
print(f"메타데이터: {doc.metadata}")결과 :
3. 유사도 검색 (Similarity Search)
예제 3: 기본 유사도 검색
# week6_05_similarity_search.py
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
from langchain_core.documents import Document
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
# 샘플 문서 (회사 정책)
documents = [
Document(
page_content="연차 휴가는 입사 1년 후부터 연 15일이 제공됩니다.",
metadata={"category": "휴가", "department": "인사"}
),
Document(
page_content="재택근무는 주 2회까지 가능하며 사전 승인이 필요합니다.",
metadata={"category": "근무", "department": "인사"}
),
Document(
page_content="점심시간은 12시부터 1시까지이며 자유롭게 사용 가능합니다.",
metadata={"category": "근무", "department": "인사"}
),
Document(
page_content="회사 차량 예약은 전날 오후 5시까지 신청해야 합니다.",
metadata={"category": "차량", "department": "총무"}
),
Document(
page_content="회의실 예약은 사내 시스템을 통해 가능합니다.",
metadata={"category": "시설", "department": "총무"}
)
]
# 벡터 저장소 생성
vectorstore = Chroma.from_documents(
documents=documents,
embedding=embeddings,
collection_name="company_policy"
)
# 유사도 검색
query = "휴가는 어떻게 사용하나요?"
results = vectorstore.similarity_search(query, k=3)
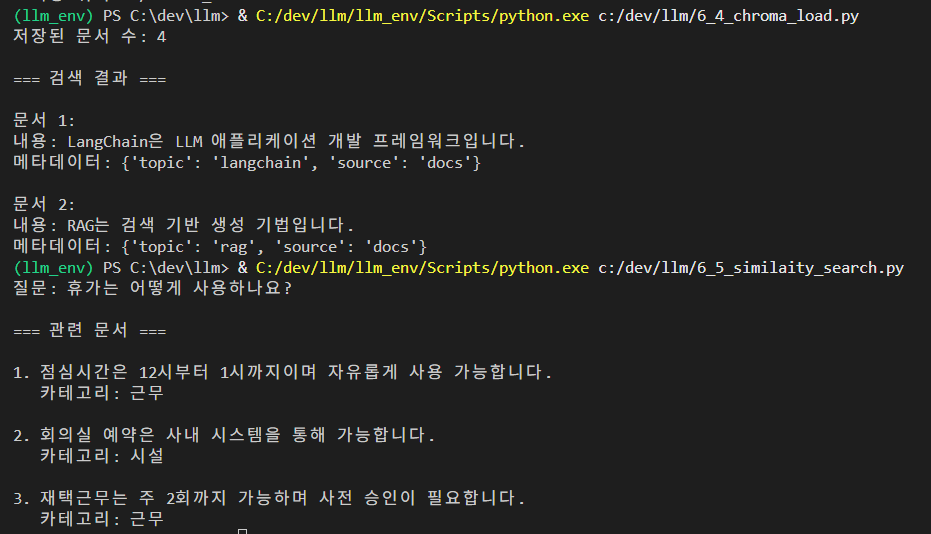
print(f"질문: {query}\n")
print("=== 관련 문서 ===")
for i, doc in enumerate(results, 1):
print(f"\n{i}. {doc.page_content}")
print(f" 카테고리: {doc.metadata['category']}")결과 :
예제 4: 점수 기반 검색
# week6_06_search_with_score.py
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
from langchain_core.documents import Document
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
# 기술 문서
documents = [
Document(page_content="Python은 데이터 분석에 널리 사용됩니다."),
Document(page_content="JavaScript는 웹 개발의 필수 언어입니다."),
Document(page_content="SQL은 데이터베이스 쿼리 언어입니다."),
Document(page_content="Docker는 컨테이너 기술입니다."),
Document(page_content="Git은 버전 관리 시스템입니다.")
]
vectorstore = Chroma.from_documents(
documents=documents,
embedding=embeddings
)
# 점수와 함께 검색
query = "데이터 분석 도구"
results = vectorstore.similarity_search_with_score(query, k=3)
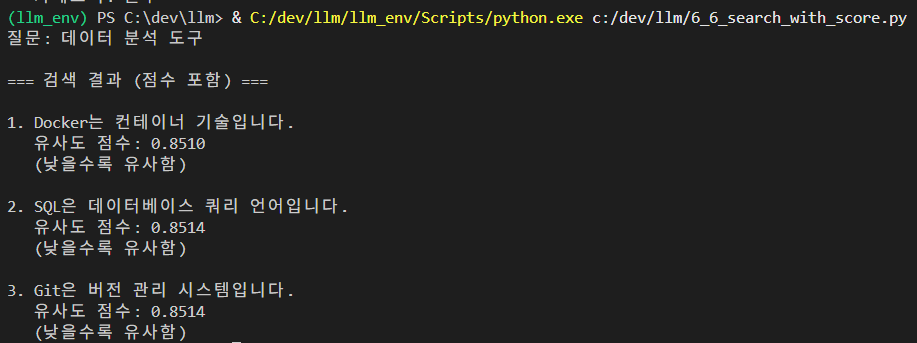
print(f"질문: {query}\n")
print("=== 검색 결과 (점수 포함) ===")
for i, (doc, score) in enumerate(results, 1):
print(f"\n{i}. {doc.page_content}")
print(f" 유사도 점수: {score:.4f}")
print(f" (낮을수록 유사함)")결과 :
예제 5: MMR (Maximum Marginal Relevance) 검색
일반적인 유사도 검색(Similarity Search)은 질문과 가장 닮은 문서들만 순서대로 가져옵니다. 하지만 MMR은 '유사도'와 '다양성' 사이의 균형을 잡는 알고리즘입니다.
목적: 검색 결과가 특정 주제에만 편중되지 않도록, 중복되는 내용은 배제하고 다양한 정보를 제공하는 것.
핵심 원리: 이미 선택된 문서와 너무 비슷한 문서는 다음 순위에서 뒤로 밀어냅니다.
# week6_07_mmr_search.py
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
from langchain_core.documents import Document
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
# 유사한 문서들
documents = [
Document(page_content="Python 프로그래밍 기초 강좌입니다."),
Document(page_content="Python 입문자를 위한 튜토리얼입니다."),
Document(page_content="Python 기본 문법을 배웁니다."),
Document(page_content="JavaScript 웹 개발 강좌입니다."),
Document(page_content="데이터베이스 SQL 기초입니다.")
]
vectorstore = Chroma.from_documents(
documents=documents,
embedding=embeddings
)
query = "Python 학습 자료"
# 일반 유사도 검색 (비슷한 문서만)
print("=== 일반 유사도 검색 ===")
similar_docs = vectorstore.similarity_search(query, k=3)
for i, doc in enumerate(similar_docs, 1):
print(f"{i}. {doc.page_content}")
# MMR 검색 (다양성 고려) - 비슷한 내용만 도배되는 것을 방지하는 필터
print("\n=== MMR 검색 (다양성 고려) ===")
mmr_docs = vectorstore.max_marginal_relevance_search(
query,
k=3, # 최종적으로 사용자에게 보여줄 문서 개수
fetch_k=5 # 후보군으로 먼저 뽑아낼 문서 개수 (유사도 기준)
)
for i, doc in enumerate(mmr_docs, 1):
print(f"{i}. {doc.page_content}")결과 :
4. 메타데이터 필터링
예제 6: 메타데이터 기반 검색
# week6_08_metadata_filter.py
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
from langchain_core.documents import Document
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
# 부서별 문서
documents = [
Document(
page_content="신입사원 온보딩 프로세스입니다.",
metadata={"department": "인사", "year": 2024, "confidential": False}
),
Document(
page_content="급여 정책 및 지급 일정입니다.",
metadata={"department": "인사", "year": 2024, "confidential": True}
),
Document(
page_content="개발 환경 설정 가이드입니다.",
metadata={"department": "개발", "year": 2024, "confidential": False}
),
Document(
page_content="코드 리뷰 체크리스트입니다.",
metadata={"department": "개발", "year": 2024, "confidential": False}
),
Document(
page_content="영업 전략 및 목표입니다.",
metadata={"department": "영업", "year": 2024, "confidential": True}
)
]
vectorstore = Chroma.from_documents(
documents=documents,
embedding=embeddings
)
# 필터 1: 개발팀 문서만
print("=== 개발팀 문서만 검색 ===")
dev_docs = vectorstore.similarity_search(
"설정 방법",
k=3,
filter={"department": "개발"}
)
for doc in dev_docs:
print(f"- {doc.page_content}")
print(f" 부서: {doc.metadata['department']}\n")
# 필터 2: 비공개가 아닌 문서만
print("=== 공개 문서만 검색 ===")
public_docs = vectorstore.similarity_search(
"프로세스",
k=3,
filter={"confidential": False}
)
for doc in public_docs:
print(f"- {doc.page_content}")
print(f" 부서: {doc.metadata['department']}\n")결과 :
- 실전 예제 : 사내 지식베이스 검색 시스템
# week6_09_knowledge_base.py
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from datetime import datetime
import os
class CompanyKnowledgeBase:
"""사내 지식베이스 시스템"""
def __init__(self, persist_directory="./company_kb"):
self.embeddings = OllamaEmbeddings(model="mxbai-embed-large")
self.persist_directory = persist_directory
self.vectorstore = None
def create_from_documents(self, documents):
"""문서로부터 지식베이스 생성"""
# 텍스트 분할
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
split_docs = splitter.split_documents(documents)
# 벡터 저장소 생성
self.vectorstore = Chroma.from_documents(
documents=split_docs,
embedding=self.embeddings,
collection_name="company_knowledge",
persist_directory=self.persist_directory
)
return len(split_docs)
def load_existing(self):
"""기존 지식베이스 로드"""
if os.path.exists(self.persist_directory):
self.vectorstore = Chroma(
collection_name="company_knowledge",
embedding_function=self.embeddings,
persist_directory=self.persist_directory
)
return True
return False
def search(self, query, k=3, filters=None):
"""검색"""
if not self.vectorstore:
raise ValueError("지식베이스가 초기화되지 않았습니다.")
if filters:
results = self.vectorstore.similarity_search(
query, k=k, filter=filters
)
else:
results = self.vectorstore.similarity_search(query, k=k)
return results
def search_with_score(self, query, k=3):
"""점수와 함께 검색"""
if not self.vectorstore:
raise ValueError("지식베이스가 초기화되지 않았습니다.")
return self.vectorstore.similarity_search_with_score(query, k=k)
def add_documents(self, documents):
"""문서 추가"""
if not self.vectorstore:
raise ValueError("지식베이스가 초기화되지 않았습니다.")
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
split_docs = splitter.split_documents(documents)
self.vectorstore.add_documents(split_docs)
return len(split_docs)
def get_stats(self):
"""통계 정보"""
if not self.vectorstore:
return {"status": "not_initialized"}
collection = self.vectorstore._collection
return {
"total_documents": collection.count(),
"persist_directory": self.persist_directory
}
# 샘플 문서 생성
def create_sample_documents():
"""샘플 회사 문서"""
return [
Document(
page_content="""연차 휴가 정책
입사 1년 미만: 월 1개
입사 1년 이상: 연 15개
3년 이상 근속: 2년마다 1개 추가
사용 규정:
- 최소 1일 전 신청
- 부서장 승인 필수
- 연말 미사용 시 소멸""",
metadata={
"title": "연차 휴가 정책",
"category": "인사",
"department": "인사팀",
"created_at": "2024-01-15",
"confidential": False
}
),
Document(
page_content="""재택근무 규정
허용 범위: 주 2회까지
신청 방법: 전날 오후 5시까지 시스템 신청
필수 사항:
- 업무 시작/종료 시 메신저 체크인
- 회의는 화상으로 참여
- 긴급 연락 가능해야 함""",
metadata={
"title": "재택근무 규정",
"category": "근무",
"department": "인사팀",
"created_at": "2024-02-01",
"confidential": False
}
),
Document(
page_content="""개발 환경 설정 가이드
1. Git 설정
- Repository: https://github.com/company/project
- Branch 전략: Git Flow
2. 개발 도구
- IDE: VS Code 권장
- Python: 3.10 이상
- Docker: 필수 설치
3. 코드 리뷰
- PR은 최소 2명 승인 필요
- 테스트 커버리지 80% 이상""",
metadata={
"title": "개발 환경 설정",
"category": "개발",
"department": "개발팀",
"created_at": "2024-01-20",
"confidential": False
}
),
Document(
page_content="""회의실 예약 규정
예약 방법:
- 사내 시스템을 통해 예약
- 최소 1시간 전 예약 필요
회의실 종류:
- 소회의실 (4인): 3개
- 중회의실 (8인): 2개
- 대회의실 (20인): 1개
주의사항:
- 사용 후 정리 필수
- 노쇼 3회 시 예약 제한""",
metadata={
"title": "회의실 예약 규정",
"category": "시설",
"department": "총무팀",
"created_at": "2024-01-10",
"confidential": False
}
)
]
# 실행
print("=== 사내 지식베이스 구축 ===\n")
# 1. 지식베이스 생성
kb = CompanyKnowledgeBase()
documents = create_sample_documents()
chunk_count = kb.create_from_documents(documents)
print(f"✓ 지식베이스 생성 완료")
print(f"✓ 문서 수: {len(documents)}")
print(f"✓ 청크 수: {chunk_count}")
# 2. 통계 확인
stats = kb.get_stats()
print(f"\n=== 통계 ===")
print(f"총 저장 문서: {stats['total_documents']}개")
print(f"저장 위치: {stats['persist_directory']}")
# 3. 검색 테스트
print("\n=== 검색 테스트 ===\n")
queries = [
"휴가는 어떻게 사용하나요?",
"재택근무 가능한가요?",
"개발 환경은 어떻게 설정하나요?",
"회의실을 예약하려면?"
]
for query in queries:
print(f"질문: {query}")
results = kb.search(query, k=2)
for i, doc in enumerate(results, 1):
print(f" {i}. [{doc.metadata['title']}]")
print(f" {doc.page_content[:100]}...")
print()결과 :
(llm_env) PS C:\dev\llm> & C:/dev/llm/llm_env/Scripts/python.exe c:/dev/llm/6_9_knowleage_base.py
=== 사내 지식베이스 구축 ===
✓ 지식베이스 생성 완료
✓ 문서 수: 4
✓ 청크 수: 4
=== 통계 ===
총 저장 문서: 4개
저장 위치: ./company_kb
=== 검색 테스트 ===
질문: 휴가는 어떻게 사용하나요?
1. [회의실 예약 규정]
회의실 예약 규정
예약 방법:
- 사내 시스템을 통해 예약
- 최소 1시간 전 예약 필요
회의실 종류:
- 소회의실 (4인): 3개
- 중회의실 (8인): 2개
- 대회의실 (...
2. [개발 환경 설정]
개발 환경 설정 가이드
1. Git 설정
- Repository: https://github.com/company/project
- Branch 전략: Git Flow
2. 개...
질문: 재택근무 가능한가요?
1. [회의실 예약 규정]
회의실 예약 규정
예약 방법:
- 사내 시스템을 통해 예약
- 최소 1시간 전 예약 필요
회의실 종류:
- 소회의실 (4인): 3개
- 중회의실 (8인): 2개
- 대회의실 (...
2. [개발 환경 설정]
개발 환경 설정 가이드
1. Git 설정
- Repository: https://github.com/company/project
- Branch 전략: Git Flow
2. 개...
질문: 개발 환경은 어떻게 설정하나요?
1. [회의실 예약 규정]
회의실 예약 규정
예약 방법:
- 사내 시스템을 통해 예약
- 최소 1시간 전 예약 필요
회의실 종류:
- 소회의실 (4인): 3개
- 중회의실 (8인): 2개
- 대회의실 (...
2. [개발 환경 설정]
개발 환경 설정 가이드
1. Git 설정
- Repository: https://github.com/company/project
- Branch 전략: Git Flow
2. 개...
질문: 회의실을 예약하려면?
1. [회의실 예약 규정]
회의실 예약 규정
예약 방법:
- 사내 시스템을 통해 예약
- 최소 1시간 전 예약 필요
회의실 종류:
- 소회의실 (4인): 3개
- 중회의실 (8인): 2개
- 대회의실 (...
2. [개발 환경 설정]
개발 환경 설정 가이드
1. Git 설정
- Repository: https://github.com/company/project
- Branch 전략: Git Flow
2. 개...예제 8: QA 시스템 통합
# week6_10_qa_system.py
from langchain_ollama import OllamaEmbeddings, OllamaLLM
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# 지식베이스 구축
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
llm = OllamaLLM(model="qwen3:1.7b", temperature=0.3)
documents = [
Document(
page_content="연차는 입사 1년 후부터 연 15일 제공됩니다. 월 1일씩 사용 가능합니다.",
metadata={"source": "인사 정책"}
),
Document(
page_content="재택근무는 주 2회까지 가능하며, 전날 오후 5시까지 신청해야 합니다.",
metadata={"source": "근무 규정"}
),
Document(
page_content="회의실 예약은 사내 시스템에서 최소 1시간 전에 해야 합니다.",
metadata={"source": "시설 관리"}
)
]
vectorstore = Chroma.from_documents(
documents=documents,
embedding=embeddings
)
# Retriever 생성
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# QA 프롬프트
template = """다음 문서를 참고하여 질문에 답변하세요.
문서:
{context}
질문: {question}
답변: 문서 내용을 바탕으로 정확하고 간결하게 답변하세요."""
prompt = ChatPromptTemplate.from_template(template)
# RAG 체인
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 질문 테스트
questions = [
"연차는 언제부터 사용할 수 있나요?",
"재택근무 신청은 언제까지 해야 하나요?",
"회의실을 급하게 예약하려면 어떻게 하나요?"
]
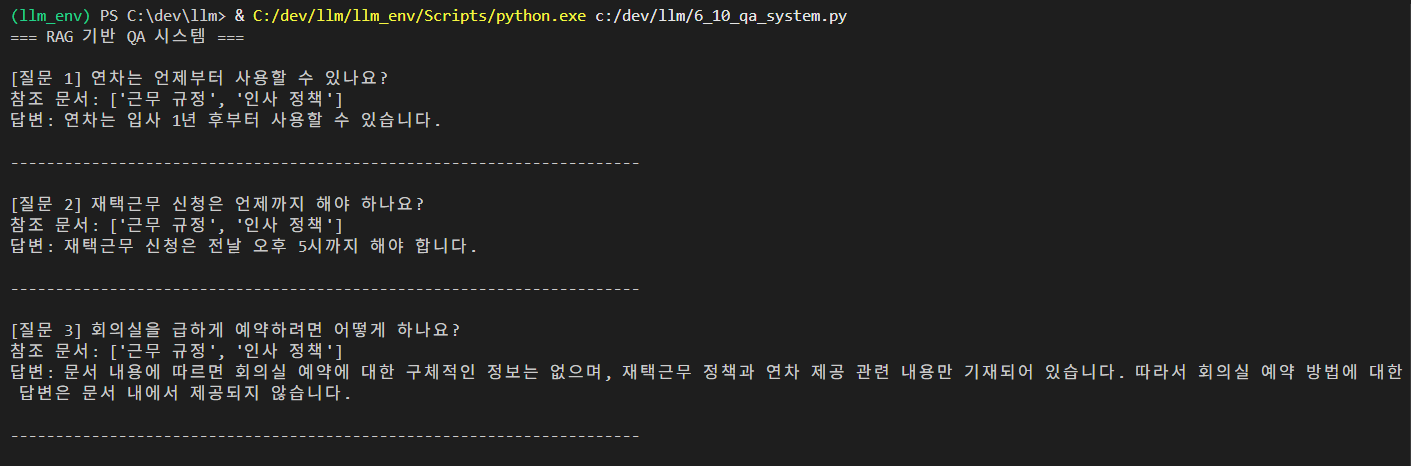
print("=== RAG 기반 QA 시스템 ===\n")
for i, question in enumerate(questions, 1):
print(f"[질문 {i}] {question}")
# 관련 문서 확인
docs = retriever.invoke(question)
print(f"참조 문서: {[doc.metadata['source'] for doc in docs]}")
# 답변 생성
answer = rag_chain.invoke(question)
print(f"답변: {answer}\n")
print("-" * 70 + "\n")결과 :