
최신 RAG 기법으로 검색 품질을 한 단계 업그레이드해봅시다!
- 다양한 Retriever 패턴 이해 및 활용
- Hybrid Search로 키워드와 벡터 검색 결합
- Re-ranking으로 검색 정확도 향상
- Multi-Query Retriever로 다각도 검색
- Contextual Compression으로 노이즈 제거
- 최신 RAG 기법 (RAG-Fusion, HyDE) 구현
- 사전 준비
필수 패키지 설치
# 기본 패키지
pip install langchain langchain-ollama langchain-community chromadb
# Hybrid Search용 (BM25)
pip install rank-bm25
# 선택 패키지 (고급 기능)
pip install sentence-transformers # Re-ranking용- 환경확인
# week7_00_check_environment.py
"""Week 7 환경 확인"""
packages = {
"chromadb": "벡터 저장소",
"langchain_ollama": "Ollama 통합",
"rank_bm25": "키워드 검색 (BM25)"
}
print("=== Week 7 패키지 확인 ===\n")
for package, purpose in packages.items():
try:
__import__(package)
print(f"✓ {package}: 설치됨 ({purpose})")
except ImportError:
print(f"✗ {package}: 설치 필요 ({purpose})")
# Ollama 연결 테스트
try:
from langchain_ollama import OllamaEmbeddings
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
test_vector = embeddings.embed_query("테스트")
print(f"\n✓ Ollama 연결 성공 (벡터 차원: {len(test_vector)})")
except Exception as e:
print(f"\n✗ Ollama 연결 실패: {e}")
1. 다양한 Retriever 패턴
예제 1: 기본 Vector Store Retriever
# week7_01_basic_retriever.py
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
from langchain_core.documents import Document
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
# 샘플 문서
documents = [
Document(
page_content="Python은 1991년 귀도 반 로섬이 개발한 프로그래밍 언어입니다.",
metadata={"language": "Python", "year": 1991, "topic": "역사"}
),
Document(
page_content="Python은 데이터 분석, 웹 개발, AI 개발에 널리 사용됩니다.",
metadata={"language": "Python", "topic": "활용"}
),
Document(
page_content="JavaScript는 1995년 브렌단 아이크가 개발한 언어입니다.",
metadata={"language": "JavaScript", "year": 1995, "topic": "역사"}
),
Document(
page_content="JavaScript는 웹 브라우저에서 동작하는 프로그래밍 언어입니다.",
metadata={"language": "JavaScript", "topic": "활용"}
)
]
# 벡터 저장소
vectorstore = Chroma.from_documents(documents, embeddings)
# Retriever 생성
retriever = vectorstore.as_retriever(
search_type="similarity", # 유사도 검색
search_kwargs={"k": 2} # 상위 2개
)
# 검색
query = "데이터 분석에 사용하는 언어"
results = retriever.invoke(query)
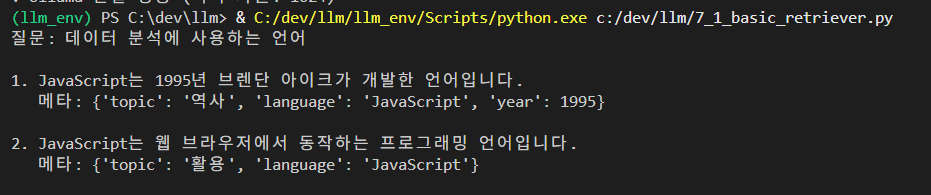
print(f"질문: {query}\n")
for i, doc in enumerate(results, 1):
print(f"{i}. {doc.page_content}")
print(f" 메타: {doc.metadata}\n")결과 :
?? 예상밖 결과..왜?
원인 1: 문장 구조의 유사성 (Syntactic Similarity)
현재 샘플 데이터를 보면 두 문장의 구조가 데칼코마니처럼 닮아 있습니다.
문서 A: "Python은 데이터 분석, 웹 개발, AI 개발에 널리 사용됩니다."
문서 B: "JavaScript는 웹 브라우저에서 동작하는 프로그래밍 언어입니다."
임베딩 모델은 단어 그 자체뿐만 아니라 문맥과 문장 구조도 수치화(Vectorize)합니다. 질문인 "데이터 분석에 사용하는 언어"라는 문구는 "Python은 ~ 언어입니다" 혹은 "JavaScript는 ~ 언어입니다"라는 구조적 유사성 때문에 두 문서 모두와 높은 점수를 가질 확률이 높습니다.
원인 2: 데이터 부족과 변별력 상실
현재 k=2로 설정되어 있습니다. 벡터 공간에서 질문과 가장 가까운 점 2개를 찍었을 때, 데이터가 단 4개뿐인 상황에서는 '데이터 분석'이라는 키워드 하나가 주는 가중치보다 '언어', '개발', '사용' 같은 공통 단어들이 주는 영향력이 더 커질 수 있습니다.
-> 해결 방법: 메타데이터 필터링 (Self-Querying)
소스 부분 변경 :
# Retriever 생성
retriever = vectorstore.as_retriever(
search_type="similarity", # 유사도 검색
search_kwargs={
"k": 2,
"filter": {
"language": "Python" # 언어 필터
}
} # 상위 2개
)
예제 2: Self-Query Retriever (메타데이터 자동 필터링)
# week7_02_self_query_retriever.py
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
from langchain_core.documents import Document
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
# 문서 (다양한 메타데이터)
documents = [
Document(
page_content="LangChain 1.0 릴리즈 노트입니다.",
metadata={"year": 2024, "category": "release", "importance": "high"}
),
Document(
page_content="LangChain 프롬프트 엔지니어링 가이드입니다.",
metadata={"year": 2023, "category": "tutorial", "importance": "medium"}
),
Document(
page_content="LangChain RAG 구현 예제입니다.",
metadata={"year": 2024, "category": "tutorial", "importance": "high"}
),
Document(
page_content="LangChain 0.x에서 1.0 마이그레이션 가이드입니다.",
metadata={"year": 2024, "category": "migration", "importance": "high"}
)
]
vectorstore = Chroma.from_documents(documents, embeddings)
# 메타데이터 필터를 사용한 검색
print("=== 메타데이터 필터 검색 ===\n")
# 2024년 문서만
query = "LangChain 튜토리얼"
results = vectorstore.similarity_search(
query,
k=3,
filter={"year": 2024}
)
print(f"질문: {query} (2024년만)\n")
for i, doc in enumerate(results, 1):
print(f"{i}. {doc.page_content}")
print(f" 연도: {doc.metadata['year']}, 카테고리: {doc.metadata['category']}\n")
# 중요도가 high인 문서만
results2 = vectorstore.similarity_search(
query,
k=3,
filter={"importance": "high"}
)
print(f"\n질문: {query} (중요도 high만)\n")
for i, doc in enumerate(results2, 1):
print(f"{i}. {doc.page_content}")
print(f" 중요도: {doc.metadata['importance']}\n")결과 :
질문: 데이터 분석 에 사용하는 언어
1. Python은 1991년 귀도 반 로섬이 개발한 프로그래밍 언어입니다.
메타: {'language': 'Python', 'topic': '역사', 'year': 1991}
2. Python은 데이터 분석, 웹 개발, AI 개발에 널리 사용됩니다.
메타: {'topic': '활용', 'language': 'Python'}
(llm_env) PS C:\dev\llm> & C:/dev/llm/llm_env/Scripts/python.exe c:/dev/llm/7_2_self_query_retriever.py
=== 메타데이터 필터 검색 ===
질문: LangChain 튜토리얼 (2024년만)
1. LangChain 1.0 릴리즈 노트입니다.
연도: 2024, 카테고리: release
2. LangChain 0.x에서 1.0 마이그레이션 가이드입니다.
연도: 2024, 카테고리: migration
3. LangChain RAG 구현 예제입니다.
연도: 2024, 카테고리: tutorial
질문: LangChain 튜토리얼 (중요도 high만)
1. LangChain 1.0 릴리즈 노트입니다.
중요도: high
2. LangChain 0.x에서 1.0 마이그레이션 가이드입니다.
중요도: high
3. LangChain RAG 구현 예제입니다.
중요도: high예제 3: Parent Document Retriever (부모-자식 구조)
# week7_03_parent_document_retriever.py
# 1. 최신 표준 Import 경로
# from langchain_community.retrievers import ParentDocumentRetriever
# ✅ LangChain 1.2 기준 정확한 경로
from langchain_classic.retrievers import ParentDocumentRetriever
from langchain_core.stores import InMemoryStore
from langchain_chroma import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_ollama import OllamaEmbeddings
from langchain_core.documents import Document
# 2. 임베딩 모델 설정
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
# 3. 샘플 긴 문서 (부모 문서)
parent_documents = [
Document(
page_content="""LangChain 소개
LangChain은 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발 프레임워크입니다.
주요 기능:
1. 프롬프트 관리: 재사용 가능한 템플릿
2. 체인 구성: 복잡한 워크플로우 구축
3. 메모리 관리: 대화 컨텍스트 유지
4. RAG 구현: 문서 기반 질의응답
LangChain을 사용하면 AI 애플리케이션을 빠르게 개발할 수 있습니다.""",
metadata={"source": "langchain_intro.md"}
)
]
# 4. 문서 분할기 설정
# 자식 청크: 100자 단위 (검색용, 벡터DB에 들어감)
child_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=50)
# 부모 청크: 400자 단위 (맥락 제공용, 메모리에 들어감)
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=50)
# 5. 저장소 준비
# VectorStore는 검색을 위해 자식 청크의 벡터(숫자)를 저장합니다.
vectorstore = Chroma(
collection_name="split_parents",
embedding_function=embeddings
)
# InMemoryStore는 답변을 위해 부모 청크(원본 텍스트)를 저장합니다.
store = InMemoryStore()
# 6. 리트리버 결합
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
# 7. 문서 추가 (이 과정에서 자동으로 자식/부모가 쪼개져서 각 저장소에 들어갑니다)
retriever.add_documents(parent_documents)
# 8. 검색 테스트
query = "프롬프트 관리"
results = retriever.invoke(query)
# 9. 결과 출력
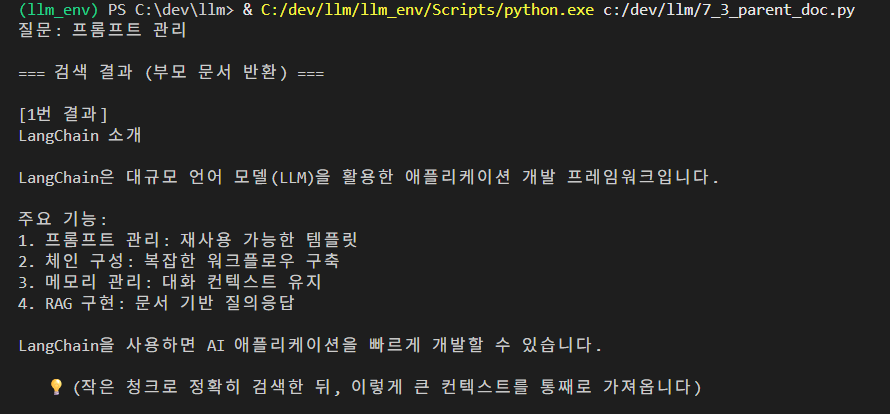
print(f"질문: {query}\n")
print("=== 검색 결과 (부모 문서 반환) ===\n")
for i, doc in enumerate(results, 1):
print(f"[{i}번 결과]")
print(f"{doc.page_content}\n")
print(f" 💡 (작은 청크로 정확히 검색한 뒤, 이렇게 큰 컨텍스트를 통째로 가져옵니다)\n")결과 :
- Hybrid Search (키워드 + 벡터)
예제 4: BM25 + Vector Ensemble
# week7_04_hybrid_search.py
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_classic.retrievers import BM25Retriever, EnsembleRetriever
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
# 문서
documents = [
Document(page_content="Python은 프로그래밍 언어입니다."),
Document(page_content="Python은 데이터 분석에 사용됩니다."),
Document(page_content="머신러닝은 Python으로 많이 개발합니다."),
Document(page_content="JavaScript는 웹 개발 언어입니다."),
Document(page_content="웹 프론트엔드는 JavaScript로 만듭니다."),
]
# 1. BM25 Retriever (키워드 기반)
bm25_retriever = BM25Retriever.from_documents(documents)
bm25_retriever.k = 2
# 2. Vector Retriever (의미 기반)
vectorstore = Chroma.from_documents(documents, embeddings)
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# 3. Ensemble Retriever (하이브리드)
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.5, 0.5] # 동일한 가중치
)
# 테스트
query = "Python 데이터 분석"
print("=== BM25 검색 (키워드) ===")
bm25_results = bm25_retriever.invoke(query)
for doc in bm25_results:
print(f"- {doc.page_content}")
print("\n=== Vector 검색 (의미) ===")
vector_results = vector_retriever.invoke(query)
for doc in vector_results:
print(f"- {doc.page_content}")
print("\n=== Hybrid 검색 (BM25 + Vector) ===")
hybrid_results = ensemble_retriever.invoke(query)
for doc in hybrid_results:
print(f"- {doc.page_content}")결과 :
c:\dev\llm\7_4_hybrid_search.py:5: LangChainDeprecationWarning: Importing BM25Retriever from langchain_classic.retrievers is deprecated. Please replace deprecated imports:
>> from langchain_classic.retrievers import BM25Retriever
with new imports of:
>> from langchain_community.retrievers import BM25Retriever
You can use the langchain cli to **automatically** upgrade many imports. Please see documentation here <https://python.langchain.com/docs/versions/v0_2/>
from langchain_classic.retrievers import BM25Retriever, EnsembleRetriever
=== BM25 검색 (키워드) ===
- Python은 데이터 분석에 사용됩니다.
- 웹 프론트엔드는 JavaScript로 만듭니다.
=== Vector 검색 (의미) ===
- Python은 프로그래밍 언어입니다.
- 웹 프론트엔드는 JavaScript로 만듭니다.
=== Hybrid 검색 (BM25 + Vector) ===
- 웹 프론트엔드는 JavaScript로 만듭니다.
- Python은 데이터 분석에 사용됩니다.
- Python은 프로그래밍 언어입니다.예제 5: 가중치 조정 실험
# week7_05_weight_tuning.py
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_classic.retrievers import BM25Retriever, EnsembleRetriever
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
documents = [
Document(page_content="연차 휴가는 입사 1년 후 15일 제공됩니다."),
Document(page_content="병가는 연 10일까지 사용 가능합니다."),
Document(page_content="재택근무는 주 2회까지 허용됩니다."),
Document(page_content="휴가 신청은 최소 1일 전에 해야 합니다."),
]
bm25 = BM25Retriever.from_documents(documents)
bm25.k = 3
vectorstore = Chroma.from_documents(documents, embeddings)
vector = vectorstore.as_retriever(search_kwargs={"k": 3})
# 다양한 가중치 조합 테스트
weight_combinations = [
(0.7, 0.3, "키워드 중심"),
(0.5, 0.5, "균형"),
(0.3, 0.7, "의미 중심")
]
query = "휴가 사용"
for bm25_weight, vector_weight, description in weight_combinations:
ensemble = EnsembleRetriever(
retrievers=[bm25, vector],
weights=[bm25_weight, vector_weight]
)
results = ensemble.invoke(query)
print(f"\n=== {description} (BM25:{bm25_weight}, Vector:{vector_weight}) ===")
for i, doc in enumerate(results[:2], 1):
print(f"{i}. {doc.page_content}")결과 :

3. Re-ranking으로 정확도 향상
예제 6: 간단한 Re-ranking
# week7_06_simple_reranking.py
from langchain_ollama import OllamaEmbeddings, OllamaLLM
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_core.prompts import ChatPromptTemplate
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
llm = OllamaLLM(model="qwen3:1.7b", temperature=0)
# 문서
documents = [
Document(page_content="LangChain은 LLM 애플리케이션 프레임워크입니다."),
Document(page_content="LangChain 1.0에서는 LCEL이 도입되었습니다."),
Document(page_content="RAG는 검색 기반 생성 기법입니다."),
Document(page_content="벡터 데이터베이스는 임베딩을 저장합니다."),
Document(page_content="Python은 AI 개발에 인기 있는 언어입니다."),
]
vectorstore = Chroma.from_documents(documents, embeddings)
query = "LangChain의 주요 기능"
# 1단계: 초기 검색 (많이 가져오기)
initial_results = vectorstore.similarity_search(query, k=5)
print("=== 1단계: 초기 검색 결과 ===")
for i, doc in enumerate(initial_results, 1):
print(f"{i}. {doc.page_content}")
# 2단계: LLM으로 Re-ranking
rerank_prompt = ChatPromptTemplate.from_template("""다음 문서들을 질문과의 관련도 순으로 정렬하세요.
질문: {query}
문서들:
{documents}
관련도가 높은 순서대로 번호만 출력하세요 (예: 1,3,2,5,4)
순서:""")
docs_text = "\n".join([f"{i+1}. {doc.page_content}" for i, doc in enumerate(initial_results)])
chain = rerank_prompt | llm
ranking = chain.invoke({"query": query, "documents": docs_text})
print(f"\n=== 2단계: Re-ranking 결과 ===")
print(f"순서: {ranking}")
# 순서대로 재정렬
try:
order = [int(x.strip())-1 for x in ranking.strip().split(',')]
reranked_results = [initial_results[i] for i in order if i < len(initial_results)]
print("\n=== 최종 Re-ranked 결과 ===")
for i, doc in enumerate(reranked_results[:3], 1):
print(f"{i}. {doc.page_content}")
except:
print("Re-ranking 파싱 실패, 원본 순서 유지")결과 :
예제 7: 점수 기반 Re-ranking
# week7_07_score_reranking.py
from langchain_ollama import OllamaEmbeddings, OllamaLLM
from langchain_chroma import Chroma
from langchain_core.documents import Document
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
llm = OllamaLLM(model="qwen3:1.7b", temperature=0)
documents = [
Document(page_content="연차는 입사 1년 후 15일입니다."),
Document(page_content="병가는 10일 제공됩니다."),
Document(page_content="재택근무는 주 2회 가능합니다."),
Document(page_content="회의실 예약은 1시간 전까지입니다."),
]
vectorstore = Chroma.from_documents(documents, embeddings)
query = "휴가 정책"
# 점수와 함께 검색
results_with_scores = vectorstore.similarity_search_with_score(query, k=4)
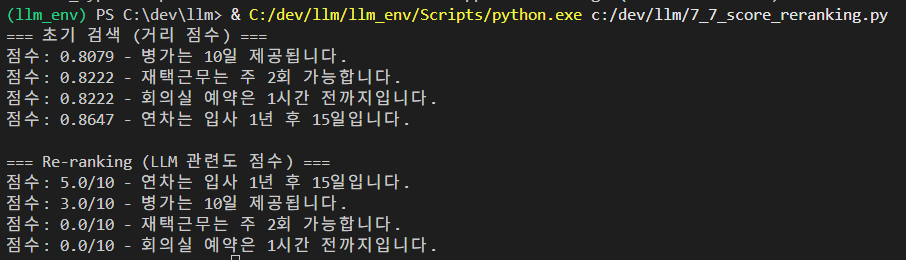
print("=== 초기 검색 (거리 점수) ===")
for doc, score in results_with_scores:
print(f"점수: {score:.4f} - {doc.page_content}")
# 관련도 계산 (LLM 활용)
def calculate_relevance(query, doc_content):
"""LLM으로 관련도 점수 계산 (0-10)"""
prompt = f"""질문과 문서의 관련도를 0-10 점수로 평가하세요.
10: 매우 관련 있음
5: 보통
0: 전혀 관련 없음
질문: {query}
문서: {doc_content}
점수만 숫자로 출력하세요:"""
try:
score = llm.invoke(prompt).strip()
return float(score)
except:
return 5.0
# Re-ranking
print("\n=== Re-ranking (LLM 관련도 점수) ===")
scored_docs = []
for doc, _ in results_with_scores:
relevance = calculate_relevance(query, doc.page_content)
scored_docs.append((doc, relevance))
# 점수 순 정렬
scored_docs.sort(key=lambda x: x[1], reverse=True)
for doc, score in scored_docs:
print(f"점수: {score:.1f}/10 - {doc.page_content}")결과 :

4. Multi-Query Retriever
예제 8: 질문 다각화
# week7_08_multi_query.py
from langchain_classic.retrievers import MultiQueryRetriever
from langchain_ollama import OllamaEmbeddings, OllamaLLM
from langchain_chroma import Chroma
from langchain_core.documents import Document
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
llm = OllamaLLM(model="qwen3:1.7b", temperature=0.7)
# 문서
documents = [
Document(page_content="Python은 간단하고 읽기 쉬운 문법을 가진 언어입니다."),
Document(page_content="Python은 다양한 라이브러리를 제공합니다."),
Document(page_content="Python은 데이터 과학 분야에서 인기가 많습니다."),
Document(page_content="JavaScript는 웹 개발의 표준 언어입니다."),
]
vectorstore = Chroma.from_documents(documents, embeddings)
base_retriever = vectorstore.as_retriever()
# Multi-Query Retriever
multi_query_retriever = MultiQueryRetriever.from_llm(
retriever=base_retriever,
llm=llm
)
query = "Python의 장점"
# 검색
print(f"원본 질문: {query}\n")
# 내부적으로 생성된 다양한 질문들로 검색
results = multi_query_retriever.invoke(query)
print("=== Multi-Query 검색 결과 ===")
for i, doc in enumerate(results, 1):
print(f"{i}. {doc.page_content}")
# 수동으로 다각화 (설명용)
print("\n=== 질문 다각화 예시 ===")
alternative_queries = [
"Python이 다른 언어보다 나은 점은?",
"Python을 사용하면 어떤 이점이 있나요?",
"Python의 강점을 알려주세요"
]
all_results = set()
for alt_query in alternative_queries:
results = vectorstore.similarity_search(alt_query, k=2)
for doc in results:
all_results.add(doc.page_content)
print("다각화된 질문들로 검색한 고유 결과:")
for i, content in enumerate(all_results, 1):
print(f"{i}. {content}")결과 :
예제 9: 커스텀 Query Generator
# week7_09_custom_query_generator.py
from langchain_ollama import OllamaEmbeddings, OllamaLLM
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_core.prompts import ChatPromptTemplate
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
llm = OllamaLLM(model="qwen3:1.7b", temperature=0.7)
documents = [
Document(page_content="재택근무는 주 2회까지 가능합니다."),
Document(page_content="재택근무 시 업무 시작/종료를 메신저로 체크인해야 합니다."),
Document(page_content="재택근무 신청은 전날 오후 5시까지 해야 합니다."),
Document(page_content="긴급 상황 시 재택근무도 사무실 출근 요청 가능합니다."),
]
vectorstore = Chroma.from_documents(documents, embeddings)
# 커스텀 쿼리 생성 프롬프트
query_generator_prompt = ChatPromptTemplate.from_template("""다음 질문을 3가지 다른 방식으로 재표현하세요.
원본 질문: {original_query}
재표현된 질문들 (한 줄씩):
1.""")
def generate_multi_queries(original_query):
"""질문을 여러 방식으로 생성"""
chain = query_generator_prompt | llm
response = chain.invoke({"original_query": original_query})
# 응답 파싱
queries = [original_query] # 원본 포함
lines = response.strip().split('\n')
for line in lines:
cleaned = line.strip()
# 숫자와 점 제거
if cleaned and cleaned[0].isdigit():
query_text = cleaned.split('.', 1)[-1].strip()
if query_text:
queries.append(query_text)
return queries[:4] # 최대 4개
# 실행
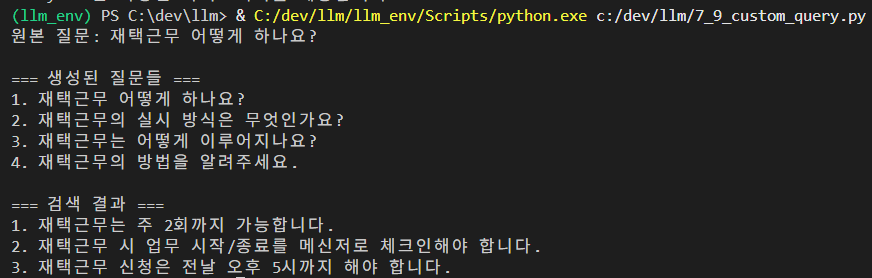
original_query = "재택근무 어떻게 하나요?"
print(f"원본 질문: {original_query}\n")
# 질문 생성
multi_queries = generate_multi_queries(original_query)
print("=== 생성된 질문들 ===")
for i, q in enumerate(multi_queries, 1):
print(f"{i}. {q}")
# 각 질문으로 검색
print("\n=== 검색 결과 ===")
all_docs = []
seen = set()
for query in multi_queries:
results = vectorstore.similarity_search(query, k=2)
for doc in results:
if doc.page_content not in seen:
all_docs.append(doc)
seen.add(doc.page_content)
for i, doc in enumerate(all_docs, 1):
print(f"{i}. {doc.page_content}")결과 :
5. Contextual Compression
예제 10: 기본 압축
# week7_10_contextual_compression.py
from langchain_classic.retrievers import ContextualCompressionRetriever
from langchain_classic.retrievers.document_compressors import LLMChainExtractor
from langchain_ollama import OllamaEmbeddings, OllamaLLM
from langchain_chroma import Chroma
from langchain_core.documents import Document
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
llm = OllamaLLM(model="qwen3:1.7b", temperature=0)
# 긴 문서
documents = [
Document(
page_content="""회사 휴가 정책 안내
1. 연차 휴가
- 입사 1년 미만: 월 1개
- 입사 1년 이상: 연 15개
- 3년 이상 근속: 2년마다 1개 추가
2. 병가
- 연 10일 제공
- 진단서 필수
3. 경조사 휴가
- 본인 결혼: 5일
- 가족 경조사: 3일
휴가 신청은 최소 1일 전까지 해야 하며, 부서장 승인이 필요합니다."""
),
Document(
page_content="""재택근무 안내
허용 범위: 주 2회
신청 방법: 전날 오후 5시까지
필수 사항:
- 업무 시작/종료 체크인
- 회의는 화상 참여
- 긴급 연락 가능해야 함
재택근무 시에도 정규 근무시간(9-6시)을 준수해야 합니다."""
)
]
vectorstore = Chroma.from_documents(documents, embeddings)
base_retriever = vectorstore.as_retriever()
# Compressor 설정
compressor = LLMChainExtractor.from_llm(llm)
# Contextual Compression Retriever
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=base_retriever
)
query = "연차는 몇 개인가요?"
# 기본 검색
print("=== 기본 검색 (압축 전) ===")
base_results = base_retriever.invoke(query)
for doc in base_results:
print(f"\n{doc.page_content}\n")
print(f"길이: {len(doc.page_content)} 문자")
# 압축된 검색
print("\n=== 압축된 검색 (관련 부분만) ===")
compressed_results = compression_retriever.invoke(query)
for doc in compressed_results:
print(f"\n{doc.page_content}\n")
print(f"길이: {len(doc.page_content)} 문자")결과 :
(llm_env) PS C:\dev\llm> & C:/dev/llm/llm_env/Scripts/python.exe c:/dev/llm/7_10_contexual_compression.py
=== 기본 검색 (압축 전) ===
회사 휴가 정책 안내
1. 연차 휴가
- 입사 1년 미만: 월 1개
- 입사 1년 이상: 연 15개
- 3년 이상 근속: 2년마다 1개 추가
2. 병가
- 연 10일 제공
- 진단서 필수
3. 경조사 휴가
- 본인 결혼: 5일
- 가족 경조사: 3일
휴가 신청은 최소 1일 전까지 해야 하며, 부서장 승인이 필요합니다.
길이: 182 문자
재택근무 안내
허용 범위: 주 2회
신청 방법: 전날 오후 5시까지
필수 사항:
- 업무 시작/종료 체크인
- 회의는 화상 참여
- 긴급 연락 가능해야 함
재택근무 시에도 정규 근무시간(9-6시)을 준수해야 합니다.
길이: 122 문자
=== 압축된 검색 (관련 부분만) ===
Extracted relevant parts: 연 15개
길이: 31 문자
Extracted relevant parts: 허용 범위: 주 2회
길이: 37 문자예제 11: Embedding Filter
# week7_11_embedding_filter.py
from langchain_classic.retrievers.document_compressors import EmbeddingsFilter
from langchain_classic.retrievers import ContextualCompressionRetriever
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
from langchain_core.documents import Document
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
# 문서 (일부는 관련 없음)
documents = [
Document(page_content="Python은 프로그래밍 언어입니다."),
Document(page_content="Python은 데이터 분석에 좋습니다."),
Document(page_content="날씨가 좋습니다."), # 관련 없음
Document(page_content="Python 라이브러리는 풍부합니다."),
Document(page_content="점심 메뉴는 파스타입니다."), # 관련 없음
]
vectorstore = Chroma.from_documents(documents, embeddings)
base_retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
# Embedding 기반 필터 (유사도 임계값)
embeddings_filter = EmbeddingsFilter(
embeddings=embeddings,
similarity_threshold=0.7 # 임계값 이하는 제거
)
compression_retriever = ContextualCompressionRetriever(
base_compressor=embeddings_filter,
base_retriever=base_retriever
)
query = "Python 프로그래밍"
print("=== 기본 검색 (필터 전) ===")
base_results = base_retriever.invoke(query)
for i, doc in enumerate(base_results, 1):
print(f"{i}. {doc.page_content}")
print("\n=== 필터된 검색 (관련도 높은 것만) ===")
filtered_results = compression_retriever.invoke(query)
for i, doc in enumerate(filtered_results, 1):
print(f"{i}. {doc.page_content}")결과 :
6. 최신 RAG 기법
예제 12: RAG-Fusion
# week7_12_rag_fusion.py
from langchain_ollama import OllamaEmbeddings, OllamaLLM
from langchain_chroma import Chroma
from langchain_core.documents import Document
from collections import defaultdict
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
llm = OllamaLLM(model="qwen3:1.7b", temperature=0.7)
documents = [
Document(page_content="LangChain은 LLM 애플리케이션 프레임워크입니다."),
Document(page_content="LangChain은 프롬프트, 체인, 메모리를 관리합니다."),
Document(page_content="RAG는 검색 기반 생성입니다."),
Document(page_content="벡터 데이터베이스는 임베딩 저장소입니다."),
]
vectorstore = Chroma.from_documents(documents, embeddings)
def generate_queries(original_query, num_queries=3):
"""원본 질문을 여러 관점으로 변환"""
prompt = f"""다음 질문을 {num_queries}가지 다른 관점으로 재작성하세요.
원본: {original_query}
재작성 (각 줄에 하나씩):
1."""
response = llm.invoke(prompt)
queries = [original_query]
for line in response.split('\n'):
clean = line.strip()
if clean and clean[0].isdigit():
query = clean.split('.', 1)[-1].strip()
if query:
queries.append(query)
return queries[:num_queries+1]
def reciprocal_rank_fusion(results_list, k=60):
"""Reciprocal Rank Fusion으로 결과 통합"""
scores = defaultdict(float)
for results in results_list:
for rank, doc in enumerate(results):
# RRF 점수 계산
scores[doc.page_content] += 1 / (rank + k)
# 점수 순 정렬
sorted_docs = sorted(scores.items(), key=lambda x: x[1], reverse=True)
return sorted_docs
# RAG-Fusion 실행
original_query = "LangChain의 주요 기능"
print(f"원본 질문: {original_query}\n")
# 1. 다양한 질문 생성
queries = generate_queries(original_query, num_queries=3)
print("=== 생성된 질문들 ===")
for i, q in enumerate(queries, 1):
print(f"{i}. {q}")
# 2. 각 질문으로 검색
print("\n=== 각 질문별 검색 결과 ===")
all_results = []
for i, query in enumerate(queries, 1):
results = vectorstore.similarity_search(query, k=3)
all_results.append(results)
print(f"\n질문 {i}: {query}")
for j, doc in enumerate(results, 1):
print(f" {j}. {doc.page_content}")
# 3. RRF로 통합
print("\n=== RAG-Fusion 최종 결과 (RRF) ===")
fused_results = reciprocal_rank_fusion(all_results)
for i, (content, score) in enumerate(fused_results, 1):
print(f"{i}. [점수: {score:.3f}] {content}")결과:
(llm_env) PS C:\dev\llm> & C:/dev/llm/llm_env/Scripts/python.exe c:/dev/llm/7_12_rag_fusion.py
원본 질문: LangChain의 주요 기능
=== 생성된 질문들 ===
1. LangChain의 주요 기능
2. **프로젝트 목적 및 기능**
3. **사용자 경험 및 효율성**
4. **기술적 기능 및 확장성**
=== 각 질문별 검색 결과 ===
질문 1: LangChain의 주요 기능
1. RAG는 검색 기반 생성입니다.
2. 벡터 데이터베이스는 임베딩 저장소입니다.
3. LangChain은 프롬프트, 체인, 메모리를 관리합니다.
질문 2: **프로젝트 목적 및 기능**
1. RAG는 검색 기반 생성입니다.
2. 벡터 데이터베이스는 임베딩 저장소입니다.
3. LangChain은 프롬프트, 체인, 메모리를 관리합니다.
질문 3: **사용자 경험 및 효율성**
1. RAG는 검색 기반 생성입니다.
2. 벡터 데이터베이스는 임베딩 저장소입니다.
3. LangChain은 프롬프트, 체인, 메모리를 관리합니다.
질문 4: **기술적 기능 및 확장성**
1. RAG는 검색 기반 생성입니다.
2. 벡터 데이터베이스는 임베딩 저장소입니다.
3. LangChain은 프롬프트, 체인, 메모리를 관리합니다.
=== RAG-Fusion 최종 결과 (RRF) ===
1. [점수: 0.067] RAG는 검색 기반 생성입니다.
2. [점수: 0.066] 벡터 데이터베이스는 임베딩 저장소입니다.
3. [점수: 0.065] LangChain은 프롬프트, 체인, 메모리를 관리합니다.예제 13: HyDE (Hypothetical Document Embeddings)
# week7_13_hyde.py
from langchain_ollama import OllamaEmbeddings, OllamaLLM
from langchain_chroma import Chroma
from langchain_core.documents import Document
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
llm = OllamaLLM(model="qwen3:1.7b", temperature=0.7)
# 실제 문서
documents = [
Document(page_content="연차는 입사 1년 후 연 15일 제공됩니다."),
Document(page_content="병가는 연 10일 제공되며 진단서가 필요합니다."),
Document(page_content="재택근무는 주 2회까지 가능합니다."),
]
vectorstore = Chroma.from_documents(documents, embeddings)
def generate_hypothetical_document(query):
"""질문에 대한 가상의 답변 문서 생성"""
prompt = f"""다음 질문에 대한 답변을 문서 형식으로 작성하세요.
실제 정보가 아닌, 있을 법한 답변을 작성하세요.
질문: {query}
답변 문서:"""
return llm.invoke(prompt)
# 일반 검색 vs HyDE
query = "휴가를 얼마나 쓸 수 있나요?"
print(f"질문: {query}\n")
# 1. 일반 검색 (질문으로 직접 검색)
print("=== 일반 검색 ===")
normal_results = vectorstore.similarity_search(query, k=2)
for i, doc in enumerate(normal_results, 1):
print(f"{i}. {doc.page_content}")
# 2. HyDE (가상 문서 생성 후 검색)
print("\n=== HyDE ===")
hypothetical_doc = generate_hypothetical_document(query)
print(f"생성된 가상 문서:\n{hypothetical_doc}\n")
hyde_results = vectorstore.similarity_search(hypothetical_doc, k=2)
print("검색 결과:")
for i, doc in enumerate(hyde_results, 1):
print(f"{i}. {doc.page_content}")결과 :
(llm_env) PS C:\dev\llm> & C:/dev/llm/llm_env/Scripts/python.exe c:/dev/llm/7_12_rag_fusion.py
원본 질문: LangChain의 주요 기능
=== 생성된 질문들 ===
1. LangChain의 주요 기능
2. **프로젝트 목적 및 기능**
3. **사용자 경험 및 효율성**
4. **기술적 기능 및 확장성**
=== 각 질문별 검색 결과 ===
질문 1: LangChain의 주요 기능
1. RAG는 검색 기반 생성입니다.
2. 벡터 데이터베이스는 임베딩 저장소입니다.
3. LangChain은 프롬프트, 체인, 메모리를 관리합니다.
질문 2: **프로젝트 목적 및 기능**
1. RAG는 검색 기반 생성입니다.
2. 벡터 데이터베이스는 임베딩 저장소입니다.
3. LangChain은 프롬프트, 체인, 메모리를 관리합니다.
질문 3: **사용자 경험 및 효율성**
1. RAG는 검색 기반 생성입니다.
2. 벡터 데이터베이스는 임베딩 저장소입니다.
3. LangChain은 프롬프트, 체인, 메모리를 관리합니다.
질문 4: **기술적 기능 및 확장성**
질문 3: **사용자 경험 및 효율성**
1. RAG는 검색 기반 생성입니다.
2. 벡터 데이터베이스는 임베딩 저장소입니다.
3. LangChain은 프롬프트, 체인, 메모리를 관리합니다.
질문 3: **사용자 경험 및 효율성**
1. RAG는 검색 기반 생성입니다.
2. 벡터 데이터베이스는 임베딩 저장소입니다.
3. LangChain은 프롬프트, 체인, 메모리를 관리합니다.
질문 3: **사용자 경험 및 효율성**
1. RAG는 검색 기반 생성입니다.
1. RAG는 검색 기반 생성입니다.
2. 벡터 데이터베이스는 임베딩 저장소입니다.
3. LangChain은 프롬프트, 체인, 메모리를 관리합니다.
질문 4: **기술적 기능 및 확장성**
1. RAG는 검색 기반 생성입니다.
2. 벡터 데이터베이스는 임베딩 저장소입니다.
3. LangChain은 프롬프트, 체인, 메모리를 관리합니다.
=== RAG-Fusion 최종 결과 (RRF) ===
1. [점수: 0.067] RAG는 검색 기반 생성입니다.
2. [점수: 0.066] 벡터 데이터베이스는 임베딩 저장소입니다.
3. [점수: 0.065] LangChain은 프롬프트, 체인, 메모리를 관리합니다.
(llm_env) PS C:\dev\llm> & C:/dev/llm/llm_env/Scripts/python.exe c:/dev/llm/7_13_hyde.py
질문: 휴가를 얼마나 쓸 수 있나요?
=== 일반 검색 ===
1. 재택근무는 주 2회까지 가능합니다.
2. 병가는 연 10일 제공되며 진단서가 필요합니다.
=== HyDE ===
생성된 가상 문서:
**휴가 일수 제한 정책서**
**제1장 개요**
본 정책서는 사내 휴가 일수 제한을 규정하고, 휴가 일수 결정 요소를 설명하며, 실제 사례를 기반으로 작성되었습니다.
**제2장 휴가 일수 정책**
회사 내 휴가 일수는 직업별, 근무 기간, 성과에 따라 달라집니다. 일반적으로 20~30일의 휴가를 제공하며, 업무 수행 상황, 업무량, 개인 상황을 고려하여 조정될 수 있습니다.
**제3장 휴가 일수 결정 요소**
1. **직업 및 업무 성과**: 고급 직무나 업무량이 많은 직원에게는 더 많은 휴가를 제공합니다.
2. **근무 기간**: 5년 이상 근무한 직원에게는 추가 휴가를 부여합니다.
3. **개인 상황**: 휴식 필요성, 건강 상태, 가족 상황 등을 고려하여 휴가 일수를 조정합니다.
**제4장 예시**
- **직업별 휴가 일수**:
- 팀 리더: 25일
- 일반 직원: 20일
- 5년 이상 근무자: 22일
- **휴가 일수 조정 사례**:
- 업무량이 많은 직원: 30일 휴가 제공
- 건강 상황이 악화한 직원: 휴가 일수 10일 감소
**제5장 결론**
휴가 일수는 업무 상황과 개인 상황에 따라 유동적으로 조정되며, 사내 정책은 휴가 일수의 균형과 직원의 만족도를 유지하는 데 중요한 역할을 합니다.
*참고: 본 정책서는 사례를 기반으로 작성되었으며, 실제 기업의 정책과 다를 수 있습니다.*
검색 결과:
1. 재택근무는 주 2회까지 가능합니다.
2. 병가는 연 10일 제공되며 진단서가 필요합니다.7. 실전: 고급 RAG 시스템 통합
예제 14: 전체 통합 시스템
# week7_14_advanced_rag_system.py
from langchain_ollama import OllamaEmbeddings, OllamaLLM
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_classic.retrievers import BM25Retriever, EnsembleRetriever
from langchain_classic.retrievers import ContextualCompressionRetriever
from langchain_classic.retrievers.document_compressors import LLMChainExtractor
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
class AdvancedRAGSystem:
"""고급 RAG 시스템"""
def __init__(self):
self.embeddings = OllamaEmbeddings(model="mxbai-embed-large")
self.llm = OllamaLLM(model="qwen3:1.7b", temperature=0.3)
self.vectorstore = None
self.retriever = None
def build_knowledge_base(self, documents):
"""지식베이스 구축"""
# 1. Vector Store
self.vectorstore = Chroma.from_documents(
documents,
self.embeddings
)
# 2. Hybrid Retriever (BM25 + Vector)
bm25_retriever = BM25Retriever.from_documents(documents)
bm25_retriever.k = 5
vector_retriever = self.vectorstore.as_retriever(
search_kwargs={"k": 5}
)
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.4, 0.6] # Vector에 더 높은 가중치
)
# 3. Contextual Compression
compressor = LLMChainExtractor.from_llm(self.llm)
self.retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=ensemble_retriever
)
def multi_query_search(self, query, num_variations=2):
"""Multi-Query 검색"""
# 질문 변형 생성
prompt = f"""다음 질문을 {num_variations}가지 방식으로 재표현하세요.
원본: {query}
재표현 (각 줄에 하나씩):
1."""
response = self.llm.invoke(prompt)
queries = [query]
for line in response.split('\n'):
clean = line.strip()
if clean and clean[0].isdigit():
q = clean.split('.', 1)[-1].strip()
if q:
queries.append(q)
# 각 질문으로 검색
all_docs = []
seen = set()
for q in queries[:num_variations+1]:
results = self.retriever.invoke(q)
for doc in results:
if doc.page_content not in seen:
all_docs.append(doc)
seen.add(doc.page_content)
return all_docs[:5] # 최대 5개
def answer_question(self, query):
"""질문에 답변"""
# 문서 검색
docs = self.multi_query_search(query)
if not docs:
return "관련 문서를 찾을 수 없습니다."
# 컨텍스트 생성
context = "\n\n".join([
f"문서 {i+1}: {doc.page_content}"
for i, doc in enumerate(docs)
])
# 답변 생성
template = """다음 문서들을 참고하여 질문에 답변하세요.
{context}
질문: {question}
답변 (정확하고 간결하게):"""
prompt = ChatPromptTemplate.from_template(template)
chain = prompt | self.llm | StrOutputParser()
answer = chain.invoke({
"context": context,
"question": query
})
return {
"answer": answer,
"sources": docs,
"num_sources": len(docs)
}
# 테스트
print("=== 고급 RAG 시스템 구축 ===\n")
# 샘플 문서
documents = [
Document(
page_content="연차 휴가는 입사 1년 후부터 연 15일이 제공됩니다. 3년 이상 근속 시 2년마다 1일씩 추가됩니다.",
metadata={"category": "휴가", "doc_id": "policy_001"}
),
Document(
page_content="재택근무는 주 2회까지 가능하며, 전날 오후 5시까지 신청해야 합니다.",
metadata={"category": "근무", "doc_id": "policy_002"}
),
Document(
page_content="병가는 연 10일까지 사용 가능하며, 진단서 제출이 필요합니다.",
metadata={"category": "휴가", "doc_id": "policy_003"}
),
Document(
page_content="회의실 예약은 사내 시스템에서 최소 1시간 전까지 해야 합니다.",
metadata={"category": "시설", "doc_id": "policy_004"}
),
]
# 시스템 초기화
rag_system = AdvancedRAGSystem()
rag_system.build_knowledge_base(documents)
print("✓ 지식베이스 구축 완료\n")
# 질문 테스트
questions = [
"휴가는 몇 일 쓸 수 있나요?",
"재택근무 규정이 어떻게 되나요?",
"회의실을 예약하려면?"
]
for i, question in enumerate(questions, 1):
print(f"{'='*70}")
print(f"질문 {i}: {question}")
print(f"{'='*70}\n")
result = rag_system.answer_question(question)
print(f"답변:\n{result['answer']}\n")
print(f"참조 문서 ({result['num_sources']}개):")
for j, doc in enumerate(result['sources'], 1):
print(f" {j}. {doc.page_content[:80]}...")
print()결과 :
=== 고급 RAG 시스템 구축 ===
✓ 지식베이스 구축 완료
======================================================================
질문 1: 휴가는 몇 일 쓸 수 있나요?
======================================================================
답변:
휴가는 입사 1년 후부터 연 15일이 제공되며, 3년 이상 근속 시 추가됩니다.
**답변:** 연 15일입니다.
참조 문서 (5개):
1. 10일...
2. Extracted relevant parts:
"연차 휴가는 입사 1년 후부터 연 15일이 제공됩니다. 3년 이상 근속 시 2년마다 1일씩 ...
3. Extracted relevant part: 병가는 연 10일까지 사용 가능하며, 진단서 제출이 필요합니다....
4. /병가는 연 10일까지 사용 가능하며, 진단서 제출이 필요합니다./...
5. Extracted relevant parts: 연차 휴가는 입사 1년 후부터 연 15일이 제공됩니다. 3년 이상 근속 시 2년마다 1일씩 추가됩...
======================================================================
질문 2: 재택근무 규정이 어떻게 되나요?
======================================================================
답변:
재택근무는 주 2회까지 가능하며, 전날 오후 5시까지 신청해야 합니다.
참조 문서 (3개):
1. 재택근무는 주 2회까지 가능하며, 전날 오후 5시까지 신청해야 합니다....
2. 회의실 예약은 사내 시스템에서 최소 1시간 전까지 해야 합니다....
3. Extracted relevant parts:
연차 휴가는 입사 1년 후부터 연 15일이 제공됩니다. 3년 이상 근속 시 2년마다 1일씩 추...
======================================================================
질문 3: 회의실을 예약하려면?
======================================================================
답변:
회의실을 예약하려면 사내 시스템을 통해 최소 1시간 전까지 예약해야 합니다.
참조 문서 (1개):
1. 회의실 예약은 사내 시스템에서 최소 1시간 전까지 해야 합니다....
- RAG 기법 비교
| 기법 | 장점 | 단점 | 사용 시나리오 |
|---|---|---|---|
| Basic Vector Search | 간단, 빠름 | 정확도 제한 | 프로토타입, 간단한 QA |
| Hybrid Search | 키워드+의미 통합 | 복잡도 증가 | 전문 용어 많은 도메인 |
| Re-ranking | 정확도 향상 | 속도 느림 | 높은 정확도 필요 시 |
| Multi-Query | 다각도 검색 | LLM 비용 증가 | 애매한 질문 처리 |
| Compression | 노이즈 제거 | 정보 손실 가능 | 긴 문서 처리 |
| RAG-Fusion | 최고 정확도 | 가장 복잡 | 프로덕션 시스템 |
- 최신 RAG 트렌드
- Self-RAG
- 검색 결과를 자체 평가
- 필요 시 재검색
- Corrective RAG (CRAG)
- 검색 품질 자동 검증
- 웹 검색으로 보완
- Adaptive RAG
- 질문 유형에 따라 전략 변경
- 간단한 질문은 검색 스킵
- Graph RAG
- 지식 그래프 활용
- 엔티티 관계 고려
- FAQ
Q: Hybrid Search가 항상 더 좋나요?
A: 아닙니다. 도메인에 따라 다릅니다. 전문 용어가 많으면 BM25가, 의미 중심이면 Vector가 유리합니다.
Q: Re-ranking은 언제 사용하나요?
A: 초기 검색 결과가 많고(k>10), 정확도가 중요할 때 사용하세요.
Q: Multi-Query는 비용이 많이 들지 않나요?
A: 네, LLM 호출이 많아 비용이 증가합니다. 중요한 쿼리에만 선택적으로 사용하세요.
Q: 어떤 기법을 조합해야 하나요?
A: Hybrid Search + Compression이 가성비가 좋습니다. 프로덕션에서는 여기에 Re-ranking 추가를 고려하세요.
