JPA N+1 문제
JPA의 N+1 문제는 연관관계가 설정된 엔티티를 조회할 때 발생하는 대표적인 성능 이슈입니다. 하나의 쿼리로 N개의 데이터를 가져왔는데, 연관된 데이터를 조회하기 위해 추가로 N번의 쿼리가 더 실행되는 문제를 말합니다.
N+1 문제 발생 원인
JPA의 지연 로딩(Lazy Loading) 전략과 연관관계 매핑에서 발생합니다. 연관된 엔티티가 실제로 사용될 때 개별적으로 조회 쿼리가 실행되기 때문입니다.
구체적인 예시
다음과 같은 엔티티 관계가 있다고 가정해보겠습니다:
java@Entity
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "team", fetch = FetchType.LAZY)
private List<Member> members = new ArrayList<>();}
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
private Team team;}
N+1 문제 발생 상황
java// 1. 모든 팀을 조회 (1개의 쿼리)
List teams = teamRepository.findAll();
// 2. 각 팀의 멤버들을 조회 (N개의 추가 쿼리 발생)
for (Team team : teams) {
System.out.println("팀명: " + team.getName());
System.out.println("멤버 수: " + team.getMembers().size()); // 지연 로딩 발생
}
실행되는 SQL:
sql-- 1개의 쿼리: 모든 팀 조회
SELECT * FROM team;
-- N개의 쿼리: 각 팀별 멤버 조회
SELECT FROM member WHERE team_id = 1;
SELECT FROM member WHERE team_id = 2;
SELECT * FROM member WHERE team_id = 3;
-- ... 팀 개수만큼 반복
만약 팀이 100개라면 총 101개의 쿼리가 실행됩니다.
해결 방안
1. Fetch Join 사용
JPQL에서 JOIN FETCH를 사용하여 연관된 엔티티를 한 번에 조회합니다.
java// Repository
@Query("SELECT t FROM Team t JOIN FETCH t.members")
List findAllWithMembers();
// 사용
List teams = teamRepository.findAllWithMembers();
for (Team team : teams) {
System.out.println("팀명: " + team.getName());
System.out.println("멤버 수: " + team.getMembers().size()); // 추가 쿼리 없음
}
실행되는 SQL:
sqlSELECT t., m.
FROM team t
INNER JOIN member m ON t.id = m.team_id;
2. @EntityGraph 사용
어노테이션 기반으로 페치 전략을 지정할 수 있습니다.
java@Repository
public interface TeamRepository extends JpaRepository<Team, Long> {
@EntityGraph(attributePaths = {"members"})
@Query("SELECT t FROM Team t")
List<Team> findAllWithMembers();
// 또는 메소드명으로
@EntityGraph(attributePaths = {"members"})
List<Team> findAll();}
3. Batch Size 설정
한 번에 여러 개의 연관 엔티티를 조회하도록 배치 크기를 설정합니다.
java@Entity
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "team", fetch = FetchType.LAZY)
@BatchSize(size = 10) // 10개씩 배치로 조회
private List<Member> members = new ArrayList<>();}
또는 글로벌 설정:
properties# application.properties
spring.jpa.properties.hibernate.default_batch_fetch_size=10
실행되는 SQL:
sql-- 첫 번째 쿼리: 모든 팀 조회
SELECT * FROM team;
-- 배치 쿼리: IN 절로 여러 팀의 멤버를 한 번에 조회
SELECT FROM member WHERE team_id IN (1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
SELECT FROM member WHERE team_id IN (11, 12, 13, 14, 15, 16, 17, 18, 19, 20);
4. @Fetch(FetchMode.SUBSELECT) 사용
서브쿼리를 이용해 연관된 모든 데이터를 한 번에 조회합니다.
java@Entity
public class Team {
@OneToMany(mappedBy = "team", fetch = FetchType.LAZY)
@Fetch(FetchMode.SUBSELECT)
private List members = new ArrayList<>();
}
실행되는 SQL:
sql-- 첫 번째 쿼리
SELECT * FROM team;
-- 서브쿼리로 모든 연관 데이터 조회
SELECT * FROM member
WHERE team_id IN (SELECT id FROM team);
5. Projection 사용
필요한 데이터만 조회하는 DTO 프로젝션을 활용합니다.
java// DTO 정의
public class TeamMemberCountDto {
private Long teamId;
private String teamName;
private Long memberCount;
// 생성자, getter/setter}
// Repository
@Query("SELECT new com.example.dto.TeamMemberCountDto(t.id, t.name, COUNT(m.id)) " +
"FROM Team t LEFT JOIN t.members m GROUP BY t.id, t.name")
List findTeamMemberCounts();
-
해결 방안별 비교
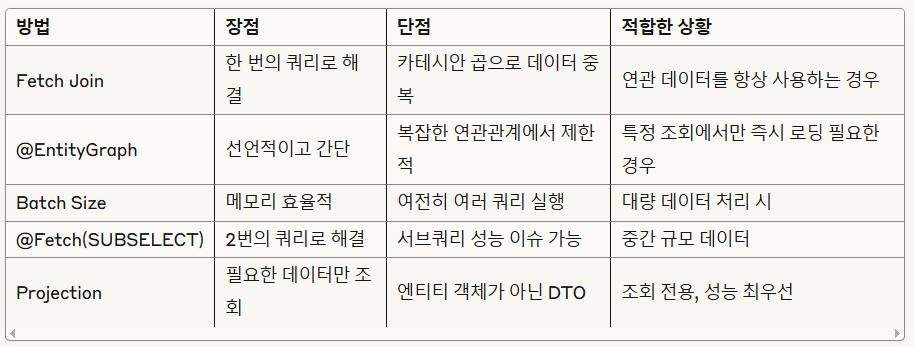
*실무 권장사항
- 기본적으로 지연 로딩 사용: FetchType.LAZY를 기본으로 설정
- 필요한 곳에서만 즉시 로딩: Fetch Join이나 @EntityGraph 활용
- 글로벌 배치 사이즈 설정: hibernate.default_batch_fetch_size=100~1000
- 쿼리 로그 모니터링: 실제 실행되는 쿼리 확인
- 상황별 적절한 전략 선택: 데이터 크기와 사용 패턴에 따라 결정
N+1 문제는 JPA를 사용할 때 반드시 고려해야 할 성능 이슈이므로, 개발 초기부터 적절한 해결 전략을 수립하는 것이 중요합니다.
