DFS 알고리즘이란?
그래프(Graph)
그래프(Graph)는 객체들 간의 관계(relationship)를 수학적으로 표현한 모델이며, 객체(objects)와 그 객체들을 연결하는 관계(relationship)를 시각적으로 나타낸다.
G = (V,E)
그래프의 구성요소
그래프는 정점들의 집합인 V와 간선들의 집합인 E로 구성이 되어있다.
- 정점(Vertices): 서로 연결된 객체들 (노드, node)
- 간선(Edges): 두 정점을 연결하는 링크 (link)
그래프의 분류
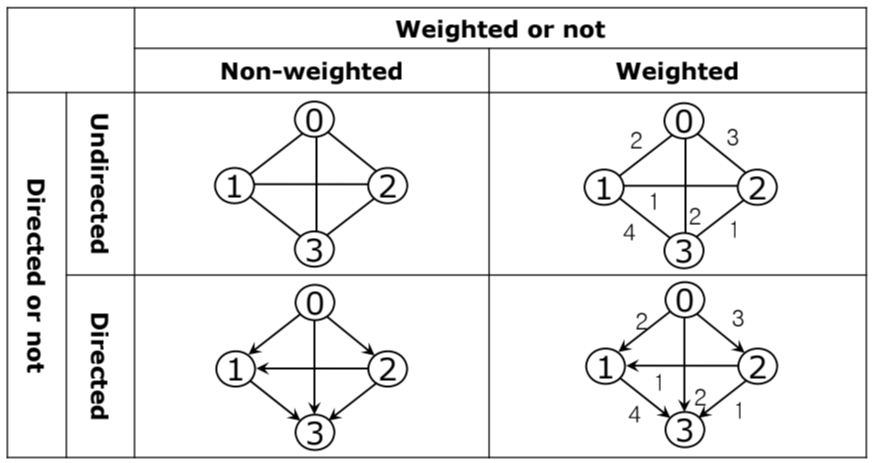
그래프는 크게 방향성(Driected)과 가중치(Weighted)로 분류를 하며
1. 간선이 한쪽 방향으로만 단방향으로 연결이 되는지 또는 양방향으로 연결되는지
2. 간선마다 가중치(weight)가 존재하는지로 분류가 된다.
DFS 알고리즘의 개념
DFS(Depth-First Search) 알고리즘은 깊이 우선 탐색 알고리즘으로 그래프를 탐색할 때 사용하는 알고리즘이다.
한 Node에서 시작하여 이와 인접한 Node들을 재귀적으로 탐색을 하며, 한 Node에서 가능한 깊숙이 들어간 뒤 더 이상 갈 곳이 없으면 이전 Node(Bactracking)로 되돌아오며, 모든 Node를 방문할 때 까지 반복한다.
여기서 중요한 점은 한번 방문한 Node는 재방문하지 않는 것이다.
재방문을 해도 상관없는 경우가 있지만 효율성이 떨어지고 대부분 Cycle이 생길 수 있기 때문에 이미 방문을 했는지를 체크하는 것이 중요하다.
DFS와 같이 자주 언급이 되는 BFS(Breadth-First Search) 알고리즘은 너비 우선 탐색 알고리즘으로 다음 글에서 정리해보겠다.
DFS 탐색은 주로 단순 탐색에서 사용이 되며(단순히 연결이 되어 있는지), 주로 가중치를 이용해서 최소 거리를 계산하는 것은 다익스트라 알고리즘을 사용한다.
DFS가 가중치 그래프에서 사용이 안된다는 것이 아닌 가중치를 무시하고 단순히 탐색만을 한다는 의미다.
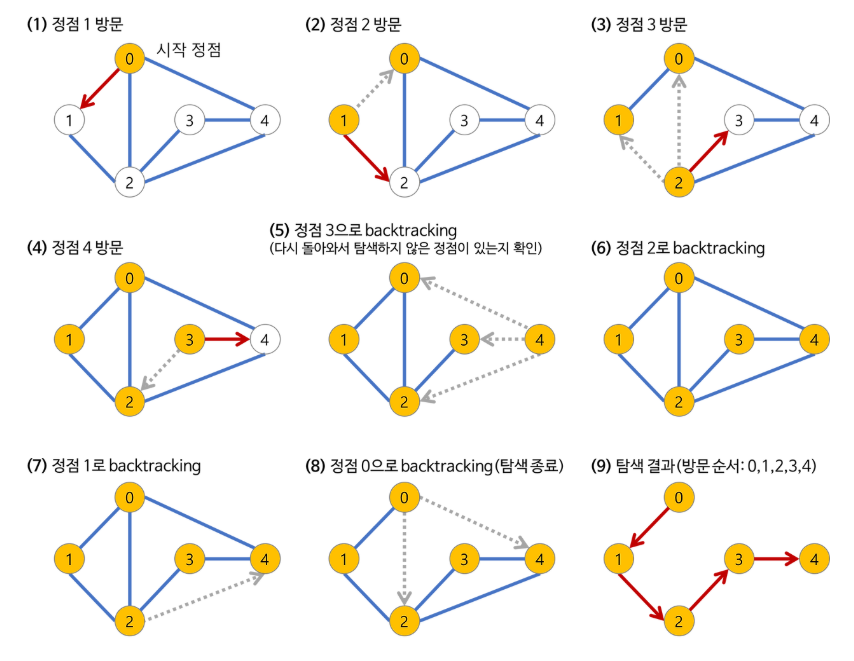
DFS 알고리즘의 동작 원리
-
시작 노드에서 한 방향으로 깊게 들어간다.
-
더 이상 방문할 노드가 없으면 이전 노드로 되돌아(백트래킹)간다.
-
모든 노드를 방문할 때까지 반복한다.
특징
- 모든 경로를 탐색할 때 유리하며, 스택 또는 재귀 호출을 이용해서 구현을 한다.
- Loop나 BackTracking 문제에서 자주 사용을 한다.
- 쉽게 이야기하면 미로에서 한 길로 끝까지 들어갔다가 벽에 막히면 다시 돌아와서 다른 길을 탐색하는 방식이다.
- 최단 거리 탐색의 경우 BFS가 영역, 연결요소, 경로 유무 탐색의 경우에는 DFS를 많이 사용한다.
DFS 알고리즘의 코드 예시
https://www.acmicpc.net/problem/1012

이 문제는 연결 요소 탐색 문제로 배추들이 몇 개의 그룹으로 연결이 되어있는지를 찾는 문제이다.
하나의 좌표에서 시작을 해서 그 좌표와 연결이 된 모든 점들을 Visited로 처리를 하기에 몇 개의 그룹이 있는지 체크를 하기에는 DFS가 유리하기에 대표적인 문제이다.
구현을 할 때에는 Stack 또는 재귀 함수를 이용해서 풀지만 구현의 난이도를 생각하면 개인적으로 Stack보다는 재귀 함수를 이용하는 것이 더 편한 것 같다.
재귀 함수를 이용한 DFS 구현
package DFS_BFS;
import java.io.*;
import java.util.StringTokenizer;
// O(T * N * M)
public class boj_1012_S2 {
static int M, N, K;
static int[][] farm;
static int[] dx = {0, 0, -1, 1};
static int[] dy = {-1, 1, 0, 0};
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
StringBuilder sb = new StringBuilder();
int T = Integer.parseInt(st.nextToken());
for (int i = 0; i < T; i++) {
st = new StringTokenizer(br.readLine());
// 1 <= N, M <= 50, 1 <= K <= 2500
M = Integer.parseInt(st.nextToken());
N = Integer.parseInt(st.nextToken());
K = Integer.parseInt(st.nextToken());
farm = new int[N][M];
int count = 0;
// O(K)
for (int j = 0; j < K; j++) {
st = new StringTokenizer(br.readLine());
int x = Integer.parseInt(st.nextToken());
int y = Integer.parseInt(st.nextToken());
farm[y][x] = 1;
}
// O(N * M)
for (int y = 0; y < N; y++) {
for (int x = 0; x < M; x++) {
if (farm[y][x] == 1) {
count ++;
dfs(x, y);
}
}
}
sb.append(count).append("\n");
}
System.out.println(sb);
br.close();
}
private static void dfs(int x, int y) {
farm[y][x] = -1;
for (int i = 0; i < 4; i++) {
int nx = x + dx[i];
int ny = y + dy[i];
if (nx >= 0 && nx < M && ny >= 0 && ny < N && farm[ny][nx] == 1) {
dfs(nx, ny);
}
}
}
}Stack을 이용한 DFS 구현
package DFS_BFS;
import java.io.*;
import java.util.*;
public class boj_1012_S2_Stack {
static int M, N, K;
static int[][] farm;
static int[] dx = {0, 0, -1, 1};
static int[] dy = {-1, 1, 0, 0};
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st;
StringBuilder sb = new StringBuilder();
int T = Integer.parseInt(br.readLine());
for (int t = 0; t < T; t++) {
st = new StringTokenizer(br.readLine());
M = Integer.parseInt(st.nextToken());
N = Integer.parseInt(st.nextToken());
K = Integer.parseInt(st.nextToken());
farm = new int[N][M];
int count = 0;
for (int i = 0; i < K; i++) {
st = new StringTokenizer(br.readLine());
int x = Integer.parseInt(st.nextToken());
int y = Integer.parseInt(st.nextToken());
farm[y][x] = 1;
}
for (int y = 0; y < N; y++) {
for (int x = 0; x < M; x++) {
if (farm[y][x] == 1) {
count++;
dfsStack(x, y);
}
}
}
sb.append(count).append("\n");
}
System.out.print(sb);
br.close();
}
// DFS 스택 사용
private static void dfsStack(int x, int y) {
Deque<int[]> stack = new ArrayDeque<>();
stack.push(new int[]{x, y});
farm[y][x] = -1;
while (!stack.isEmpty()) {
int[] temp = stack.pop();
int tx = temp[0];
int ty = temp[1];
for (int i = 0; i < 4; i++) {
int nx = tx + dx[i];
int ny = ty + dy[i];
if (nx >= 0 && nx < M && ny >= 0 && ny < N && farm[ny][nx] == 1) {
farm[ny][nx] = -1;
stack.push(new int[]{nx, ny});
}
}
}
}
}이 문제에서의 시간복잡도의 핵심은 이 부분이다.
// O(N * M)
for (int y = 0; y < N; y++) {
for (int x = 0; x < M; x++) {
if (farm[y][x] == 1) {
count ++;
dfs(x, y);
}
}
}이 부분을 보면 시간복잡도는 O(N * M)으로 모든 farm의 좌표들을 탐색하며, 밖의 for문에서 좌표들을 탐색하며 count 수를 증가시켜 그룹의 갯수를 판별하게 된다.
dfs 함수에서는 일단 함수가 실행이 되면 방문을 한 것으로 판별해 -1로 해당 좌표의 값을 바꾸고 그 좌표의 상하좌우를 체크하면서 조건에 맞는 경우 다시 dfs 재귀함수를 실행시킨다.
그 좌표에 조건을 만족하는 상하좌우가 없다면 해당 그룹을 마무리가 되며 다시 바깥의 for문을 통해 새로운 그룹을 찾게 되는 것이다.
cf) 일반적으로 DFS를 사용할 때는 Visisted 좌표도 같이 구현을 하지만 이 문제에서는 한번 방문을 하면 그 뒤로 좌표를 재사용할 일이 없기에 farm 배열 자체에 방문을 하면 -1로 값을 바꾸어 메모리 사용도를 낮춰보았다.
