우선순위 큐(Priority Queue)란?
우선순위 큐는 우리가 주로 많이 사용하는 큐와 다르게 들어온 순서에 따라 나가는게 아닌 우선순위에 따라 우선순위가 높은 데이터가 먼저 나오는 큐이다.
일반적인 큐는 FIFO(선입선출)구조로 먼저 들어온 데이터가 먼저 나가지만, 우선순위 큐는 데이터에 우선순위를 매겨 높은 데이터가 먼저 나가게 된다.
기본적인 우선순위는 데이터의 값이 작을수록 높게 설정을 하기에 최소값을 빠르게 꺼내는 자료구조(최소 힙)을 요구한다.
힙(Heap)과 우선순위 큐의 특징
우선순위 큐는 추상 자료구조이고, 이를 구현하는 가장 대표적인 방식이 힙(Heap)이다.
힙의 핵심 특징
- 부모 노드 <= 자식 노드
- 루트에 최소값이 위치
- 최소값을 꺼내는 연산이 빠름
우선순위 큐의 특징
- 우선순위가 높은 데이터를 먼저 꺼내 처리하는 구조
- 내부 요소는 힙으로 구성되어 이진 트리 구조로 이루어져 있음
- 내부 구조가 힙으로 구성되어 있기에 시간 복잡도는 O(logN)
우선순위 큐의 사용법
1) 생성 또는 정렬
import java.util.PriorityQueue; //import
// 낮은 숫자일수록 우선순위가 높음
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
// 높은 숫자일수록 우선순위가 높음
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(Collections.reverseOrder());-
단순 생성인 경우 -> 시간복잡도 O(1)
-
이미 존재하는 리스트에서 정렬을 하는 heapify -> 시간복잡도 O(N)
이렇게 보았을 때 시간복잡도 O(1)이 유리하지 않나?? 라고 생각할 수 있지만, N개의 원소들을 단순 생성한 우선순위 큐에 넣는다면 시간복잡도는 O(NlogN)으로 증가하기에 O(N) vs O(Nlog)은 이미 존재하는 리스트에서 정렬하는 heapify가 더 유리하다.
2) 값 추가 및 삭제
값을 추가할 때는 주로 add() 또는 offer() 메서드를 사용한다.
두 개의 차이는 add()의 경우 삽입에 성공하면 true를 반환하고, 공간에 여유가없는 경우 삽입에 실패하면 IllegalStateException을 발생시키지만,
offer()의 경우 삽입에 성공할 시 true를 반환하는 것은 동일하지만 실패하는 경우 false를 반환하기에 offer() 메서드가 예외처리에 더 유리하기에 add()보다 offer()을 추천한다.
priorityQueue.add(1); // 값 1 추가
priorityQueue.offer(1); // 값 1 추가-> 시간복잡도는 두 메서드 다 O(logN)이다.
3) 조회
최우선 원소를 조회하는 메서드로 peek() 메서드가 존재한다.
이 메서드는 비어있을 경우 null을 반환하고 존재할 경우 가장 최우선 원소를 반환한다.
가장 루트 노드에 존재하는 것을 조회하는 것이기에 시간복잡도는 O(1)이다.
4) 삭제
값을 삭제할 때는 remove()와 poll()이 존재하는데 값 추가와 마찬가지로 remove()는 add()와 비슷한 느낌이며 poll()은 offer()과 비슷한 느낌이다.
poll()은 비어있는 경우 null을 반환하지만, remove()는 NoSuchElementException을 반환하기에 poll() 메서드를 더 추천한다.
priorityQueue.poll();
priorityQueue.remove();두 메서드 모두 시간복잡도는 O(logN)이다.
5) 추가적인 메서드
추가, 조회, 삭제 외에도 자주 사용하는 메서드들이 존재한다.
- 원소의 갯수를 반환해주는 size() -> O(1)
- 큐 원소 전체를 제거하는 clear() -> O(N)
- 비어있는지를 확인하는 isEmpty() -> O(1)
우선순위 큐 적용 예시
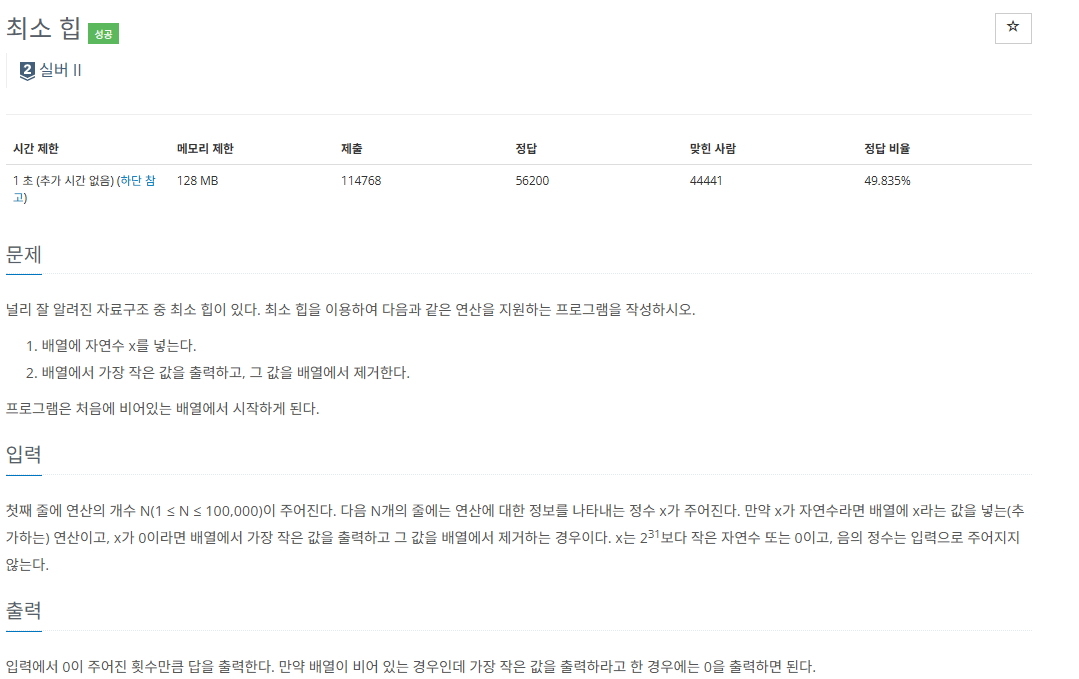
https://www.acmicpc.net/problem/1927
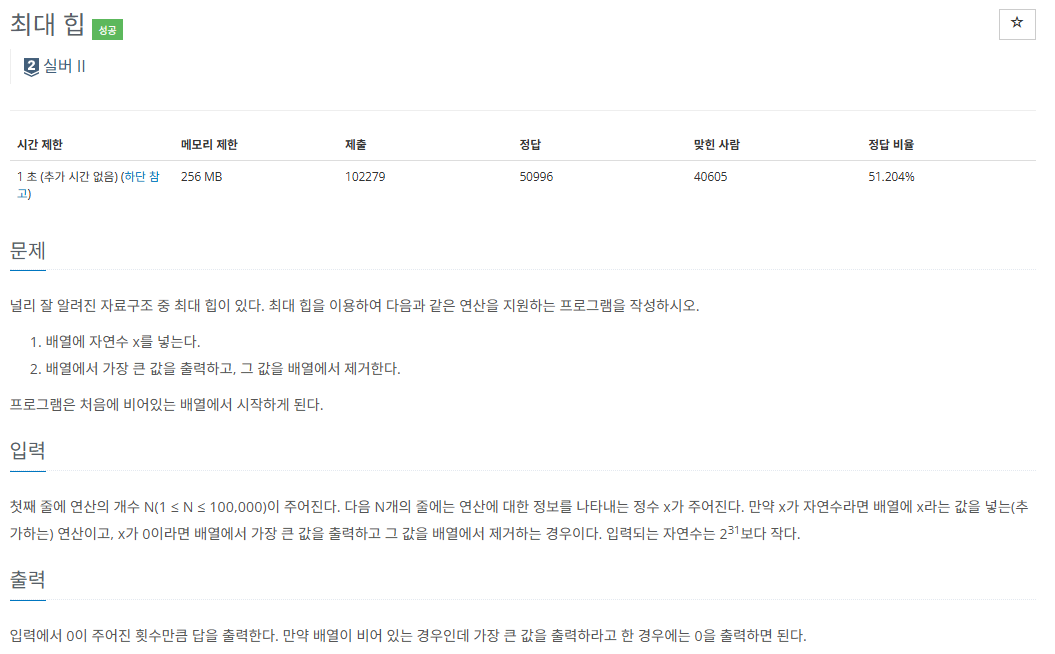
https://www.acmicpc.net/problem/11279
package PQ;
import java.io.IOException;
import java.util.PriorityQueue;
import java.util.Scanner;
public class boj_1927_S2 {
public static void main(String[] args) throws IOException {
Scanner sc = new Scanner(System.in);
PriorityQueue<Integer> pq = new PriorityQueue<>();
// 1 ≤ N ≤ 100,000
int N = sc.nextInt();
// O(NlogN)
for (int i = 0; i < N; i++) {
int temp = sc.nextInt();
if (temp == 0) {
if (pq.isEmpty()) {
System.out.println(0);
}
else System.out.println(pq.poll());
}
else {
// O(logN)
pq.offer(temp);
}
}
}
}
public class boj_11279_S2 {
public static void main(String[] args) throws IOException {
Scanner sc = new Scanner(System.in);
PriorityQueue<Integer> pq = new PriorityQueue<>();
// 1 ≤ N ≤ 100,000
int N = sc.nextInt();
O(NlogN)
for (int i = 0; i < N; i++) {
int temp = sc.nextInt();
if (temp == 0) {
if (pq.isEmpty()) {
System.out.println(0);
}
else System.out.println(-pq.poll());
}
else {
// O(logN)
pq.offer(-temp);
}
}
}
}문제풀이
최소 힙 문제의 경우 단순하게 우선순위 큐를 생성하고 offer(), poll()하면 되고
최대 힙 문제의 경우 앞에서 설명한 것처럼
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(Collections.reverseOrder());로 우선순위 큐를 생성해도 되지만
이 문제에서는 최대 힙을 많이 사용하는 것이 아니기에 원소 값을 받을 때 값에 -를 붙여서 큰 값이 가장 작은 값으로 만들어 큰 값이 우선순위가 높아지게 만들고 출력할 때 다시 -를 붙여 원래 값을 복원하여 출력하였다.
