1. 해시 함수의 정의와 속성
1.1 다양한 해시 알고리즘의 용도
- 해시(hash)는 컴퓨터 공학에서 매우 근본이 되는 알고리즘 중 하나
- 이미 여러 번 본 해시 알고리즘의 용도
- 해시 테이블에서 데이터를 저장할 위치를 찾기 위해
- 길이가 긴 데이터 둘을 빨리 비교하기 위해(단, 다른 경우만 빨리 비교 가능)
- 누출되면 곤란한 데이터의 원본을 저장하지 않기 위해 - 용도에 따라 해시 알고리즘의 요구사항이 조금씩 달라질 수 있음
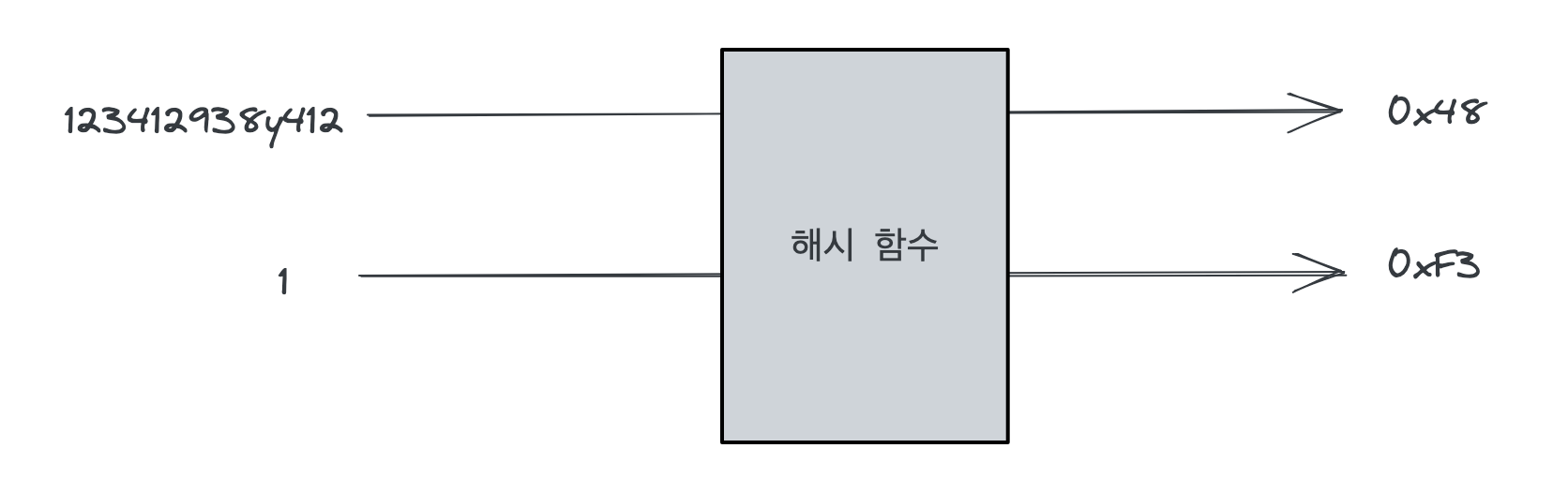
1.2 해시 함수의 정의
- 임의의 크기를 가진 값을 고정 크기의 값에 대응시키는 함수
- 여전히 함수이므로 수학에서의 함수의 정의도 만족해야함
- 입력값이 같으면 언제나 출력값도 같아야 함 (결정론적 작동)
2. 해시 알고리즘 분류
흔히 말하는 해시
- (비암호학적) 해시 함수
- 암호학적 해시 함수
해시 함수 응용방법 (비암호학적 해시 함수로 분류)
- 체크섬(검사합, checksum)
- 순환 중복 검사(cyclic redundancy check, CRC)
이 모두 해시 함수의 필수요건을 충족
2.1 모든 해시 알고리즘의 속성
- 효율성(efficiency)
- 균일성(uniformity)
- ex..
2.1.1 균일성
- 해시 함수의 출력값이 고르게 분포될수록 균일성이 높음
- 입력값으로 기대하는 값에 대해 (예: 모든 정수값, 사전에 있는 단어) - 흔히 훌륭한 해시 함수는 균일성이 높아야 한다고함
- 즉, 출력 범위 안의 모든 값들이 동일한 확률로 나와야 함 (균등 분포)
- 이러면 해시 충돌이 적어 O(1) 해시 테이블을 기대할 수 있음 - 완벽한(perfect) 해시 함수: 해시 충돌이 전혀 없는 함수
- 입력값이 매우 제한적일 경우에만 가능
- 이유: 나중에 생일 문제(birthday problem)에서 설명
균일성의 측정
- 카이제곱 검정 (chi-squared test)을 이용
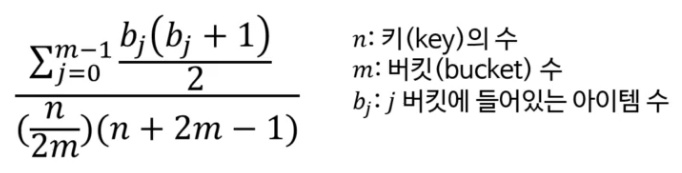
- 결과가 0.95 ~ 1.05 사이면 균일한 분포를 가진 해시 함수라 봄
현실적으로 위의 측정방법을 잘 쓰지는 않음..
균일성을 높일 수 있는 실용적인 방법
- 해시값이 덜 중복되게 버킷 수를 정할 것 (소수를 사용)
- 완벽한 '눈사태'가 나도록 해시 함수를 설계할 것
눈사태 효과(avalanche effect)
- 입력값이 약간만 바뀌어도 출력값이 굉장히 많이 바뀌는 것
- 보통 암호학적 알고리즘이 매우 선호하는 효과
- 알고리즘의 규칙을 쉽게 유추할 수 없음 - 엄격한 눈사태 기준(strict avalanche criteion, SAC)
- 입력값에서 1비트를 뒤집으면 출력값의 각 비트가 뒤집힐 확률이 50%
- 이 기준을 충족하는 해시 함수는 분포가 균일할 가능성이 매우 높음
지역 민감 해시(locality-sensitive hashing)
- 해시 충돌의 최소화 대신 최대화를 목표로 하는 알고리즘
- 비슷한 내용을 가진 데이터끼리 충돌해야 함
- 엄청나게 많은 데이터에서 비슷한 것들을 찾는 용도
- 스팸 메일 찾기
- 웹 검색 엔진에서 비슷한 문서 추천하기
- 음원, 사진 등의 저작권 침해 검사
- etc
2.1.2 효율성
- 보통 빠른 해시 함수를 선호함
- 공간을 더 낭비해도 빠른 접근 속도를 선호
- 저장된 데이터를 빨리 찾는 용도로 사용하는 해시함수 - 충돌이 좀 더 나더라도 더 빠른 함수를 선호
- 어차피 해시 충돌은 드문 일
- 몇 개 난다고 O(1)에서 크게 느려지지 않음 - 하지만 하드웨어 가속이 어려운 해시를 선호하는 경우도 있음
- 여전히 소프트웨어에서는 빨리 실행되는 걸 선호
- 뒤에 암호학적 해시 알고리즘에서 설명
2.2 비암호학적 해시 함수
- 암호학적으로 사용하기에 안전하지 않은 해시 함수들
- 보안적으로 문제없는 용도에 주로 사용
- 데이터 저장 및 찾기 (예: 해시 테이블)
- 저장/전송 중에 생긴 데이터 오류 탐지
- 고유한 ID 생성
- etc
절대 반지는 없다!
- 모든 데이터에 대해 최고의 결과를 보장하는 해시 함수는 존재하지 않음
- 입력값에 따라 다른 해시 함수를 사용하는 확률적 알고리즘은 존재(ex. 유니버설 해싱(universal hashing))
- 용도에 맞는 해시 함수를 사용하는게 중요 (Java에서 hashCode() 구현을 각 클래스에 맡긴 이유)
- 심지어 비트 패킹 (bit-packing)도 해시 함수로 사용 가능(단, 균일성이 높지 않을 수는 있음)
3. 올바른 해시 함수를 고르는법
- 제한된 데이터를 사용하는 경우 정도만 직접 발명
- 그 외의 경우에는 보통 이미 존재하는 해시 알고리즘을 사용
- 우리가 집중해야 할 부분
- 어떤 연산들이 좋은 해시 함수들을 만드는가?
- 어디에 어떤 해시 함수를 사용해야 하는가?
- 실제로 가지고 있는 데이터로 테스트하면서 측정을 한다
- 속도
- 해시 충돌 수
- 메모리 (보통 크게 중요하지 않음)
- 균일성 측정 (실무에서는 잘 안함)
- 구글링 한다 (내 데이터들이 일반적인 데이터인 경우)
4. 체크섬(checksum)
- 여러 데이터로부터 도출한 작은 크기의 데이터 하나
- 보통 데이터에 있는 모든 바이트를 어떤 방식으로든 합함 - 해시 함수랑 매우 비슷한 개념
- 출력값의 크기가 고정되어 있으면 해시 함수 - 용도: 저장 혹은 전송 중에 발생한 오류를 찾아냄
- 처음 데이터를 저장할 때 체크섬을 계산해 그것도 저장
- 나중에 데이터를 읽을 때 다시 체크섬을 계산
- 처음에 저장해둔 체크섬과 다르면 오류가 난 것
4.1 체크섬이 보장하는 것
4.1.1 체크섬 알고리즘은 매우 간단
- 보통 간단한 산술 연산
- 계산이 빠르고 추가 메모리가 거의 불필요
- 네트워크 프로토콜에서 사용
- 하드웨어로도 구현하기 쉬움 - 단, 모든 오류를 찾지는 못함
- xor8은 'AB'와 'BA'의 체크섬이 같음- 위치까지 고려한 다른 알고리즘도 존재 (예: Adler-32, CRC)
4.1.2 체크섬은 데이터가 바뀐지만 확인
- 보통 복구는 씬경 쓰지 않음
- 따라서 체크섬이 일치하지 않으면?
- 데이터 전송의 경우라면 재전송 요청- 저장 중인 데이터라면? 바이바이...
- 데이터 복구를 지원하는 것도 있음
- 오류 정정 코드(error-correcting code, ECC) 등- 보통 어느 정도까지만 복구 가능
4.2.3 체크섬과 미러 사이트
- 웹사이트에서 유용한 프로그램을 배포할 경우 미러를 사용하기도 함
- 유용한 프로그램이라 매우 많은 사람들이 다운로드- 한 웹사이트에서 트래픽 감당이 안 됨
- 다른 웹사이트에서 대신 파일을 호스팅
- 그런데 미러 사이트에서 내 프로그램에 스파이웨어를 넣으면?
- 그걸 알아낼 수 있도록 내 웹사이트에 체크섬 값을 공개해 놓음- 사용자는 미러 사이트에서 받은 파일에 체크섬 알고리즘을 돌림
- 그 둘이 일치하지 않으면 누군가 변조한 프로그램
- 주의: 미러 사이트에 공개해 놓은 체크섬 값과 비교하는건 도움 안 됨
5. 패리티 비트 (parity bit)
- 이진수로 저장된 데이터에 추가하는 1비트짜리 체크섬
- 보통 1바이트 단위로 많이 사용 (7비트 데이터 + 1비트 패리티)
- 짝수 패리티와 홀수 패리티로 나뉨
- 패리티까지 포함한 모든 비트를 더하면 그 결과가 짝수 또는 홀수가 되어야 함
6. 순환 중복 검사(cyclic redundancy check)
- 체크섬 알고리즘 중 하나
- 다항식의 나머지 연산을 이용하여 검사값을 만듦
- 검사값은 보통 고정된 길이
- 따라서 CRC 함수를 해시 함수로 사용하기도 함 - 역시 이진수 하드웨어에서 구현하기 쉬움
- 심지어 최신 CPU는 CRC-32C 명령어를 탑재! - 다항식의 최고차항에 따라 CRC에 사용하는 비트 수가 달라짐
- 각 항의 계수는 1 아니면 0
- 최고차항의 계수는 언제나1
참고 자료

백엔드 개발자 입니다