산타 할아버지가 솔플이 가능한 이유
????: 무슬림, 힌두교, 기타 종교 아이들 재끼고 크리스찬 아이들만! 우는 아이들 재끼고 웃는 아이들만! 늦게 자는 아이들 재끼고 미라클 모닝 하는 아이들만 필터링하니 몇 명 안남 더군요?...
그렇다 그는 전세계 모든 어린이들에게 선물을 줄 필요가 없었기 때문이다. 바로 "선택도"를 바탕으로 선물을 주는 쿼리를 짜고 실행하셨기 때문이지 후훗;
산타할아버지는 사실 개쩌는 DB엔지니어였다는 거지
그렇다 시작부터 그냥 대충 개소리를 느려놓으며 밀도와 선택도에 대한 이야기와 그 지표로 인덱스를 설정하는 방법에 대해 이야기할 것이다.

1. 밀도(density)
1) 정의
밀도는 테이블의 특정 컬럼이나 인덱스 키 값에 대한 고유 값의 분포를 나타내며, 쿼리 최적화 및 성능 튜닝에 중요한 역할을 합니다.
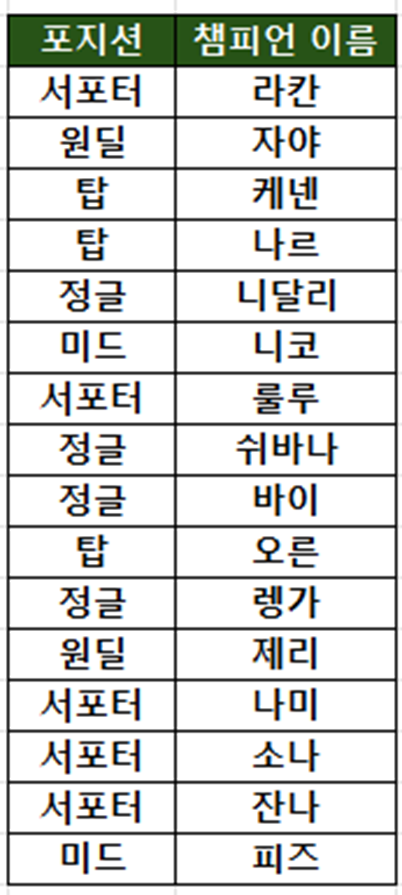
인덱스 키 값의 중복정도를 나타내기 때문에 계산법은 아래와 같다
2) 계산법
1 / 고유 값의 수
예) 탑, 미드, 정글, 원딜, 서포터 5개
포지션에 대한 밀도 1 / 5 = 0.2
이름에 대한 밀도 1 / 16 = 0.0625
밀도가 높을수록 효율이 적고
밀도가 낮을수록 효율이 높음
즉, 인덱스를 설정할 때에 밀도를 고려한다면 위와 같은 테이블은 이름 컬럼에 인덱스를 설정하는 것이 좋다.

2. 선택도(selectivity)
1) 정의
특정 값이 전체 데이터에서 차지하는 비율, 쿼리 조건이 얼마나 선택적인지(즉, 얼마나 적은 수의 행을 반환하는지)를 의미한다. 분포도라고도 불리어 진다.
2) 계산법
위와 같은 테이블을 예시로 하였을 때 아래와 같다.
조건을 만족하는 행의 수 / 전체 행의 수
포지션에 대한 선택도
서포터: 6 / 16 = 0.375
원딜: 2 / 16 = 0.125
탑: 3 / 16 = 0.1875
정글: 4 / 16 = 0.25
미드: 2 / 16 = 0.125
이름에 대한 선택도는 모두
1 / 16 = 0.0625
예시에서 알 수 있듯 컬럼자체가 아닌 쿼리의 조건을 기준으로 계산을 한다는 것이 Point!
선택도가 높을수록(비율은 낮을수록) 효율이 높고
선택도가 낮을수록(비율은 높을수록) 효율이 낮음
즉, 선택도를 고려하더라도 위와 같은 테이블은 이름 컬럼에 인덱스를 설정하는 것이 좋다.
그럼 여기서 드는 의문은 "밀도와 선택도가 다르게 나온다면 그때는 어떤 지표를 따라서 인덱스를 설정하여야 하는가?"
3. 밀도 < 선택도
1) 인덱스와 선택도의 관계
예를 들어 아래와 같은 테이블이 있다고 가정해보자.
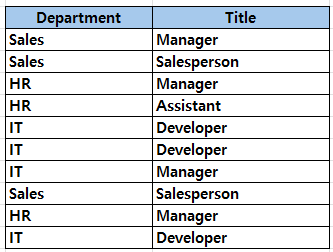
밀도 분석:
Department 열의 밀도: 1 / 고유 값의 수
(Sales, HR, IT) 고유 값의 수 = 3
밀도 = 0.333
Title 열의 밀도: 1 / 고유 값의 수
(Manager, Salesperson, Assistant, Developer) 고유 값의 수 = 4
밀도 = 0.25
선택도 분석:
Department = 'Sales' 쿼리의 선택도: Sales의 행 수 / 전체 행 수
Sales의 행 수 = 3
전체 행 수 = 10
선택도 = 0.3
Title = 'Developer' 쿼리의 선택도: Developer의 행 수 / 전체 행 수
Developer의 행 수 = 4
전체 행 수 = 10
선택도 = 0.4
만일 밀도만을 생각하여 Title 컬럼에 인덱스를 설정하였다면 발생하는 문제점
- Title = 'Developer' 쿼리의 선택도는 0.4, 이는 전체 행의 40%를 차지한다.(물론 Department컬럼에 Sales도 딱히 좋지 못함 0.3이므로) 통상적으로 선택도가 10%가 넘어간다면 인덱스를 통한 방식보다 테이블 스캔이 더 빠르다.
- 쿼리 최적화기라는 쿼리의 효율을 높히기 위해 실행 계획을 세우는 SQL Server 구성 요소가 있는데 이 친구가 해당 인덱스가 비효율적인 것을 인지하지 못하고 잘못된 쿼리를 선택할 수 있다.
결론은 인덱스를 설정할 때는 밀도와 함께 선택도, 쿼리 패턴, 데이터 업데이트 빈도 등을 종합적으로 고려해야 한다.
2) 이상적인 인덱스 컬럼은?
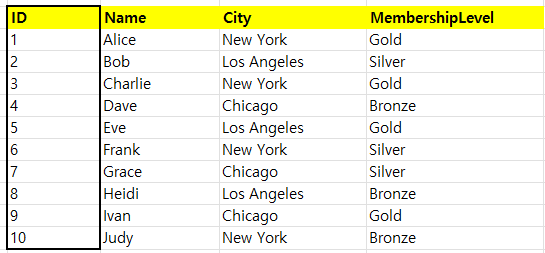
이 과정에서 우리는 한 가지 알 수 있는 것이 생겼다. 인덱스는 다른 어떠한 컬럼과도 아무런 연관이 없는 것이 좋다는 것이다. 그렇지만 이러한 방법 역시 만병통치약은 아니란 것이 앞선 포스트에서 얘기하였듯이 컬럼 하나를 따로 뽑아야 할 것이기 때문에 저장 공간을 차지하기 때문에 별도의 유지비용이 든다. 그리고 다른 컬럼들이 무수히 더 추가되기 시작하면 저 하나의 ID컬럼 만으로는 감당이 안될 수도 있는 괴물 같은 쿼리가 만들어 질 수도 있다.
다시 한번 되새기자.
DB세상에 모두 좋은 것은 없다.
만약 위와 같은 상황들이 생긴다면 DB를 많이 다뤄본 고수님들은 아시겠지만 테이블을 나누어 관리하거나 상황에 맞게 여러가지 대처를 할 것이다. 그래서 정원혁 선생님께서도 뭐 이런 기타 여러가지 대응을 하기 위해서는 비즈니스 로직을 이해하고 공부하는 것이 최우선이라고 하였다!!
이상, 다음 포스트는 인덱스를 설정한 테이블에 DML을 쓰게되면 벌어지는 일에 대해 작성해보겠다!
오늘도 DB 골머리를 앓고 있을 개발자들 파이팅!!!