HTTP
HTTP(HyperText Transfer Protocol)는 TCP/IP 모델의 응용 계층에서의 다양한 프로토콜 중 하나이다.
HTTP는 리소스를 가져올 수 있게 해주는 프로토콜이다. HTTP는 웹에서 이루어지는 모든 데이터 교환의 기초이며, 클라이언트-서버 프로토콜이기도 하다.
⇒ HTTP는 웹(www) 상에서 정보를 주고 받기 위해 만들어진 프로토콜이므로 HTTP method들(GET, POST, PUT, DELETE)이 존재한다. 웹 서비스에서 백엔드와 프론트엔드가 보통은 HTTP를 가지고 api를 만들어서 통신한다.
⇒ WWW(World Wide Web)은 웹을 의미한다. 주로 HTML, URL, HTTP로 구성된다고 볼 수 있다. 인터넷 상에서 특정 주소를 갖는 데이터가 있고, 이 데이터에 접근하기 위해 특정 주소(URL)를 특정 방법으로(HTTP를 사용해서) 접근하고 특정 데이터(HTML 기반의 데이터)를 읽어낸다.
즉, 웹(WWW) 구성 요소 3가지
- HTML(Hypertext Markup Language) : 웹 페이지의 구조, 구성 및 콘텐츠를 정의한다. (마크업 언어, hypertext와 hyperlink로 구성되어 있다)
- HTTP(Hypertext Transfer Protocol) : 브라우저와 서버의 통신을 지정한다.
- URL(Uniform Resource Locator) : 웹 리소스에 대한 시스템 역할을 한다.
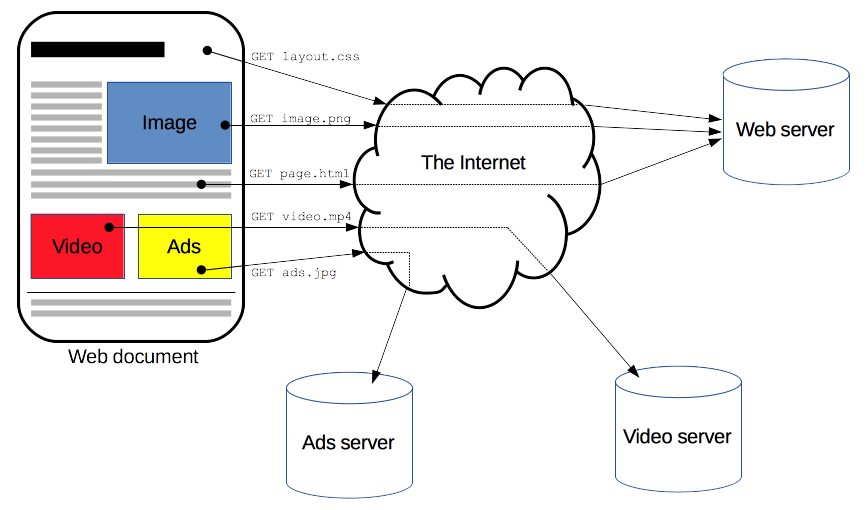
클라이언트와 서버는 데이터 스트림과 대조적으로 개별적인 메시지 교환(requests와 responses, 요청과 응답)을 한다. 요청은 하나의 개체, 사용자 에이전트(웹 브라우저) 또는 그것을 대신하는 프록시에 의해 전송된다.
⇒ HTTP는 서버-클라이언트 모델을 가정한다. 서버에 무언가를 요청(requests)하면 서버가 응답(responses)하는 모습을 가정하고 만든 프로토콜이 HTTP인 것이다. 그러다 보니 HTTP는 기본적으로 일회성에서 전제로 시작했다(HTTP는 기본적으로 connectionless한 프로토콜이다. 요청과 응답이 1회성에 그친다.). 요청하고 응답 받으면 끝인 것이다. 이게 문제가 되는 지점이 로그인 기능. 로그인한 상태가 지속되어야 하는데 일회성이 문제가 되므로 이를 보완하기 위한 기능들이 추가되기 시작한 것이다.
요청과 응답 사이에는 다양한 작업을 수행하는 게이트웨이 또는 캐시 역할을 하는 프록시 등이 존재한다. 실제로 브라우저와 서버 사이에 더 많은 컴퓨터(라우터, 모뎀)가 존재하지만 웹의 계층적인 설계(논리적으로는 OSI 7 layer, 실제로는 TCP/IP model) 덕분에, 이들은 네트워크와 전송 계층 내부로 숨겨진다. HTTP는 응용계층의 최상위에 존재한다.
⇒ 일반적으로 HTTP는 전송계층에서는 TCP를, 네트워크계층에서는 IP를 쓴다. (TCP/IP socket을 사용해서 연결한다)
1990년대 초에 설계된 HTTP는 거듭하여 진화해온 프로토콜이다. 앞서 언급했듯이, HTTP는 TCP/IP 모델에서 응용 계층의 프로토콜이다. 그래서 이론상으론 무엇이든 사용할 수 있으나 주로 TCP 혹은 암호화된 TCP 연결인 TLS를 통해 전송된다. HTTP의 확장성 덕분에 오늘날 하이퍼텍스트 문서 뿐만 아니라 이미지, 비디오, 혹은 HTML form의 결과와 같은 내용을 서버로 POST하기 위해서도 사용된다. 또한 HTTP는 필요할 때마다 웹페이지를 갱신하기 위해 문서의 일부를 가져오는 데 사용할 수도 있다. 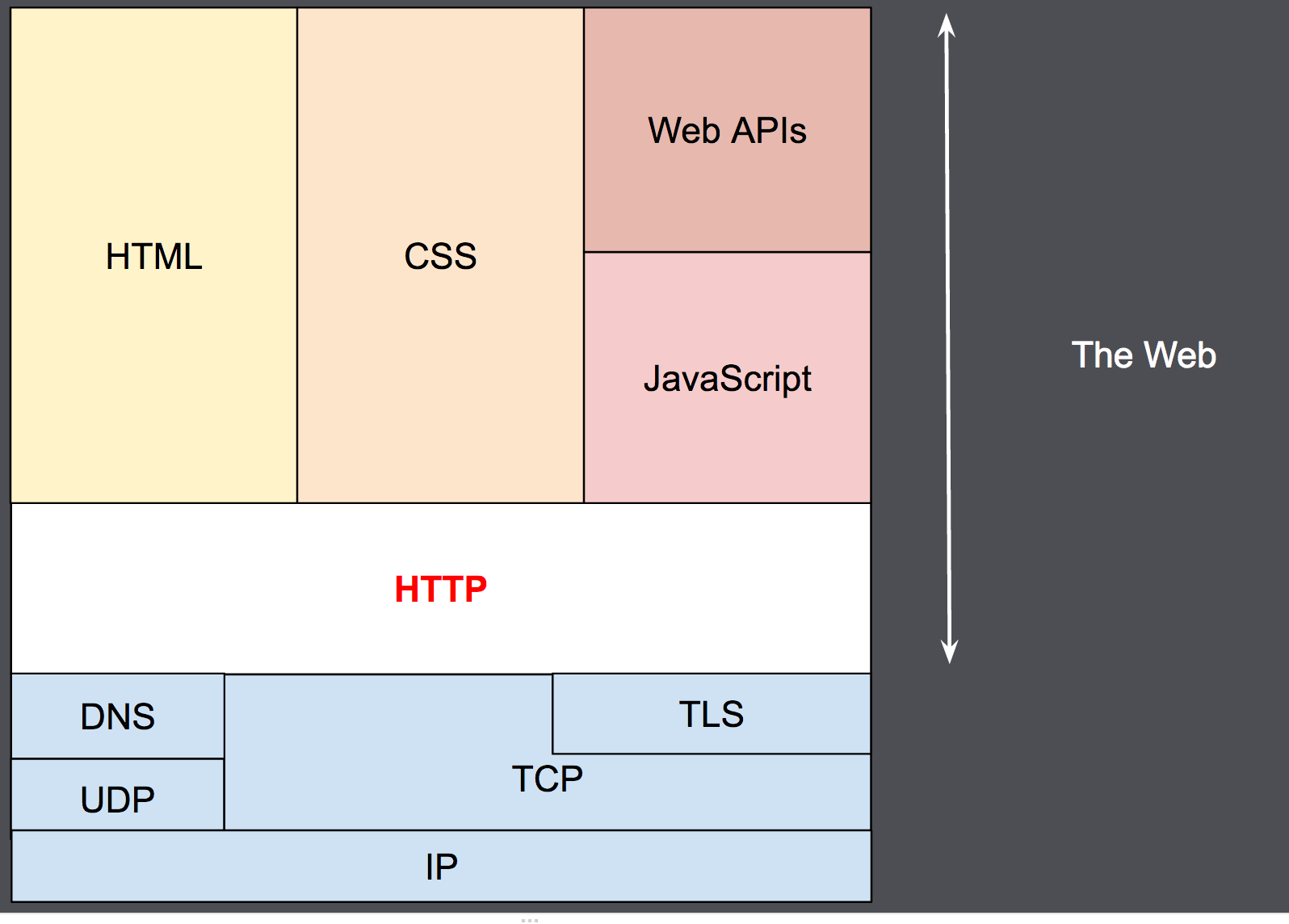
클라이언트 : 사용자 에이전트
사용자 에이전트는 사용자를 대신해 동작하는 모든 도구이며, 이 역할은 주로 브라우저에 의해 수행된다. 브라우저는 항상 요청하는 객체이다.
웹 페이지를 표시하기 위해
- 브라우저는 페이지의 HTML 문서 요청을 전송한다.
- 파일을 구문분석한 뒤,
실행해야 할 스크립트(JS), 페이지에 포함된 하위 리소스(비디오, 이미지 등), 레이아웃 정보(CSS) 등에 대응하는 추가 요청을 가져온다. - 그리고 나서 브라우저는 웹 페이지를 표시하기 위해 이 리소스들을 혼합한다.
- 브라우저에 의해 실행된 스크립트는 이후 단계에서 더 많은 리소스를 가져올 수 있고, 브라우저는 그에 따라 웹 페이지를 갱신하게 된다.
웹 페이지란,
하이퍼텍스트 문서로서 표시된 텍스트의 일부가 사용자가 사용자 에이전트를 제어하고 웹을 돌아다닐 수 있도록 실행될 수 있는 링크임을 의미한다. 브라우저는 HTTP 요청 내에 이런 지시사항들을 변환하고 HTTP 응답을 해석해 사용자에게 명확한 응답을 표시한다.
웹 서버
통신 채널의 반대편에는 클라이언트에 의한 요청에 대한 문서를 제공하는 서버가 존재한다. 서버는 사실상 논리적으로 단일 기계이다. 로드(로드 밸런싱) 혹은 그때그때 다른 컴퓨터(캐시, DB서버, e-커머스 서버 등과 같은)들의 정보를 얻고 혹은 부분적으로(혹은 완전히) 문서를 생성하는 소프트웨어의 복잡한 부분을 공유하는 서버의 집합일 수도 있기 때문이다.
서버는 단일 머신일 필요는 없지만, 여러 개의 서버를 동일한 머신 위에 호스팅할 수 있다.
프록시
웹 브라우저와 서버 사이에는 수많은 컴퓨터와 머신이 HTTP 메시지를 주고 받는다. 여러 계층으로 이루어진 웹 스택 구조에서 이러한 컴퓨터/머신들은 대부분 전송, 네트워크 혹은 물리 계층에서 동작하며, 성능에 상당히 큰 영향을 주지만 HTTP 계층에서는 이들이 어떻게 동작하는지 눈에 보이지 않는다. 이러한 컴퓨터/머신 중에서도 어플리케이션 계층에서 동작하는 것들을 일반적으로 프록시라고 한다. 프록시는 눈에 보이지 않거나 그렇지 않을 수도 있으며(프록시를 통해 요청이 변경되거나 변경되지 않는 경우) 다양한 기능을 수행한다.
- 캐싱 (캐시는 공개 또는 비공개 될 수 있다. 브라우저 캐시)
- 필터링 (바이러스 백신 스캔, 유해 콘텐츠 차단 기능)
- 로드 밸런싱 (여러 서버들이 서로 다른 요청을 처리하도록 허용)
- 인증 (다양한 리소스들에 대한 접근 제어)
- 로깅 (이력 정보 저장)
기본적인 HTTP
HTTP는 사람이 읽을 수 있으며 간단하게 고안되었다.
HTTP/2가 다소 복잡해졌지만 여전히 HTTP 메시지를 프레임 별로 캡슐화하여 간결함을 유지했다.
HTTP는 상태는 없지만 세션은 존재한다.
HTTP는 상태를 저장하지 않는다(Stateless). 동일한 연결 상에서 연속하여 전달된 2개의 요청 사이에는 연결고리가 없다. 이는 일관된 방식으로 회원이 페이지와 상호작용할 때 문제가 생긴다. 이때 HTTP 쿠키는 상태가 있는 세션을 만들도록 해준다. 헤더 확장성을 사용해, 동일한 컨텍스트 또는 동일한 상태를 공유하기 위해 각각의 요청들에 대한 세션을 만들도록 HTTP 쿠키가 추가된다.
HTTP의 연결
HTTP 연결은 전송 계층에서 제어되므로 근본적으로 HTTP 영역 밖이다. 다만 그저 신뢰할 수 있거나 메시지 손실이 없는 (최소한의 오류는 표시할 수 있는) 연결을 요구할 뿐이다. 그래서 HTTP는 연결이 필수가 아니지만 연결 기반의 TCP 표준에 의존한다.
클라이언트와 서버가 HTTP를 요청/응답으로 교환하기 전에 여러 왕복이 필요한 프로세스인 TCP 연결을 설정해야 한다. HTTP/1.0의 기본 동작은 각 요청/응답에 대해 별도의 TCP 연결을 여는 것이었다. 이 동작은 여러 요청을 보낼 경우 단일 TCP 연결을 공유하는 것보다 비효율적이었다.
이러한 결함을 개선하기 위해, HTTP/1.1은 파이프라이닝 개념과 지속적인 연결 개념을 도입했다. 기본적인 TCP 연결은 Connection 헤더를 사용해 부분적으로 제어할 수 있다. HTTP/2는 연결을 더 지속적이고 효율적으로 유지하는 데 도움이 되도록 단일 연결 상에서 메시지를 다중 전송하여 한 걸음 더 나아갔다.
HTTP 흐름
클라이언트가 서버와 통신하고자 할 때, 최종 서버가 됐든 중간 프록시가 됐든, 다음 단계의 과정을 수행한다.
-
TCP 연결을 연다
: TCP 연결은 요청을 보내거나(혹은 여러개의 요청) 응답을 받는데 사용된다. 클라이언트는 새 연결을 열거나, 기존 연결을 재사용하거나, 서버에 대한 여러 TCP 연결을 열 수 있다. -
HTTP 메시지를 전송한다
: HTTP 메시지(HTTP/2 이전의)는 인간이 읽을 수 있다. HTTP/2에서는 이런 간단한 메시지가 프레임 속으로 캡슐화되어, 직접 읽는게 불가능하지만 원칙은 동일하다.
GET / HTTP/1.1
Host: developer.mozilla.org
Accept-Language: fr
Copy to Clipboard- 서버에 의해 전송된 응답을 읽어들인다
HTTP/1.1 200 OK
Date: Sat, 09 Oct 2010 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: "51142bc1-7449-479b075b2891b"
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
<!DOCTYPE html... (here comes the 29769 bytes of the requested web page)
Copy to Clipboard- 연결을 닫거나 다른 요청들을 위해 재사용한다.
HTTP 파이프라이닝이 활성화되면, 첫번째 응답을 완전히 수신할 때까지 기다리지 않고 여러 요청을 보낼 수 있다. HTTP 파이프라이닝은 오래된 소프트웨어와 최신 버전이 공존하고 있는, 기존의 네트워크 상에서 구현하기 어렵다는게 입증되었으며, 프레임안에서 보다 활발한 다중 요청을 보내는 HTTP/2로 교체되고 있다.
HTTP 메시지
HTTP/1.1와 초기 HTTP 메시지는 사람이 읽을 수 있다. HTTP/2에서, 이 메시지들은 새로운 이진 구조인 프레임 안으로 임베드되어, 헤더의 압축과 다중화와 같은 최적화를 가능케 한다. 본래의 HTTP 메시지의 일부분만이 이 버전의 HTTP 내에서 전송된다고 할지라도, 각 메시지의 의미들은 변화하지 않으며 클라이언트는 본래의 HTTP/1.1 요청을 (가상으로) 재구성한다. 그러므로 HTTP/1.1 포맷 내에서 HTTP/2를 이해하는 것은 여전히 유용하다.
HTTP 기반 API
HTTP 기반으로 가장 일반적으로 사용된 API는 user agent와 서버간에 데이터를 교환하는데 사용될 수 있는 XMLHttpRequest API 이다. 최신 Fetch API는 보다 강력하고 유연한 기능을 제공한다.
또 다른 API인 Server-sent events는 서버가 전송 메커니즘으로 HTTP를 사용하여, 클라이언트로 이벤트를 보낼 수 있도록 하는 단방향 서비스이다. 클라이언트는 EventSource 인터페이스를 사용하여, 연결을 맺고 이벤트 핸들러를 설정한다. 클라이언트 브라우저는 HTTP 스트림으로 도착한 메시지를 적절한 Event 객체로 자동 변환하여, 알려진 경우 해당 이벤트 type에 대해 등록된 이벤트 핸들러로 전달하거나 또는 특정 유형의 이벤트가 설정되지 않은 경우에는 onmessage (en-US) 이벤트 핸들러로 전달한다.
참고
